更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
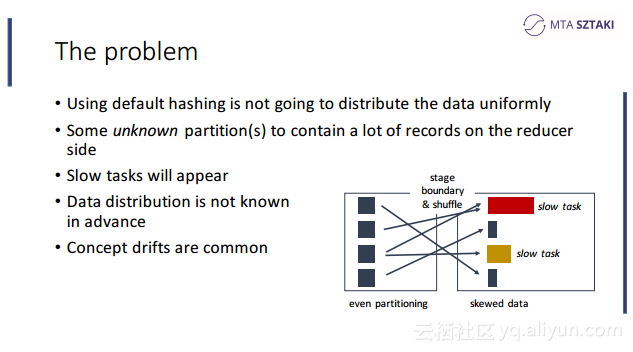
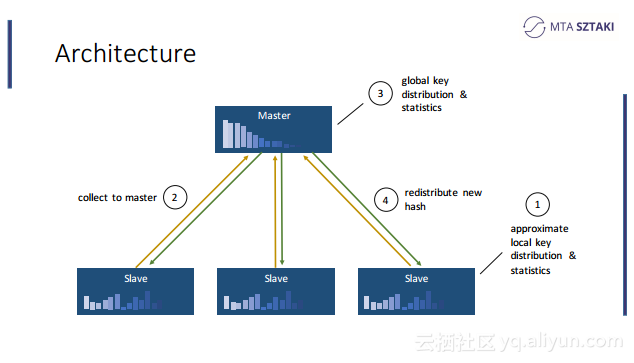
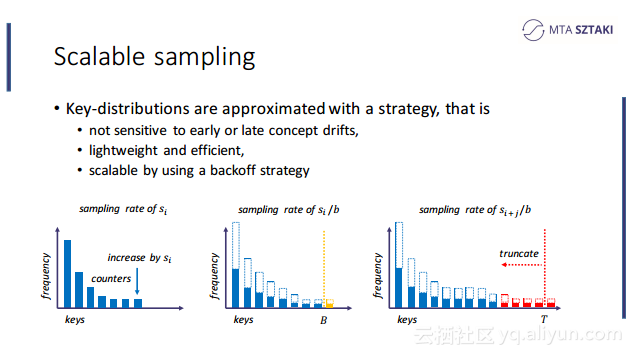
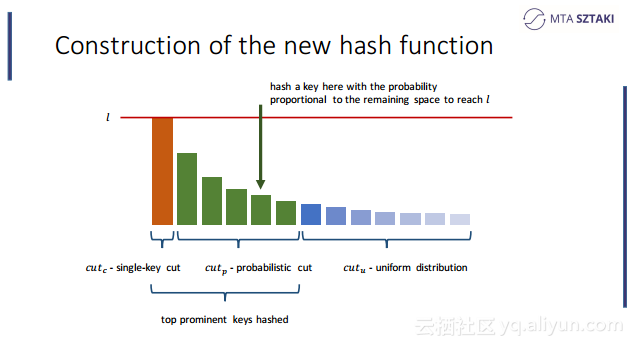
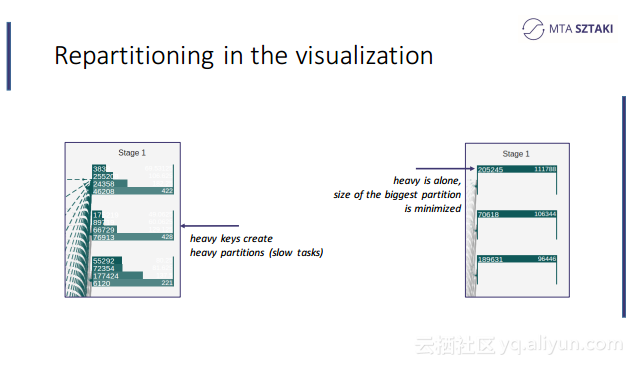
本讲义出自Zoltan Zvara在Spark Summit EU 2016上的演讲,聚合了物联网、社交网络和电信数据的应用在“玩具”数据集上运行的非常好,但是将应用部署到真实的数据集上时就没有看上去那么合适了,事实上可能变得令人惊讶的缓慢甚至会崩溃,这就是所谓的数据倾斜(data-skew),为了应对这一问题,Zoltan Zvara与他的团队致力于实现基于Spark的数据感知分布式数据处理框架。本讲义就介绍了这个基于Spark的数据感知分布式数据处理框架的技术细节。