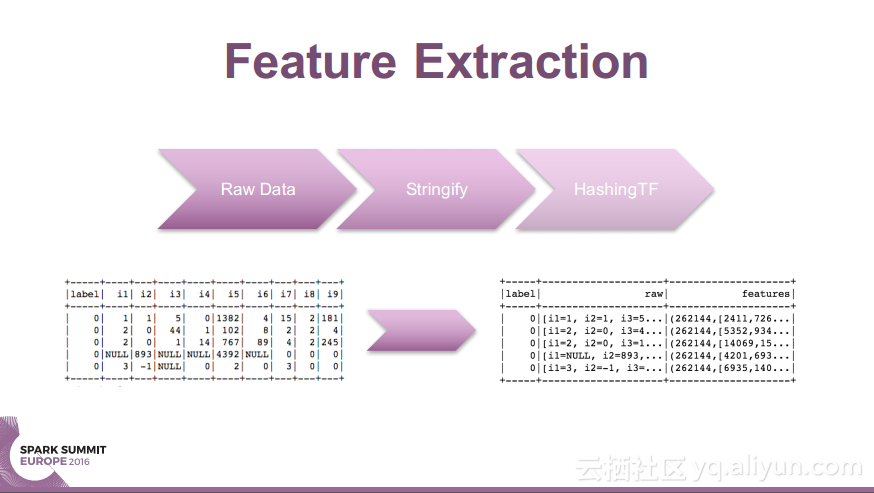
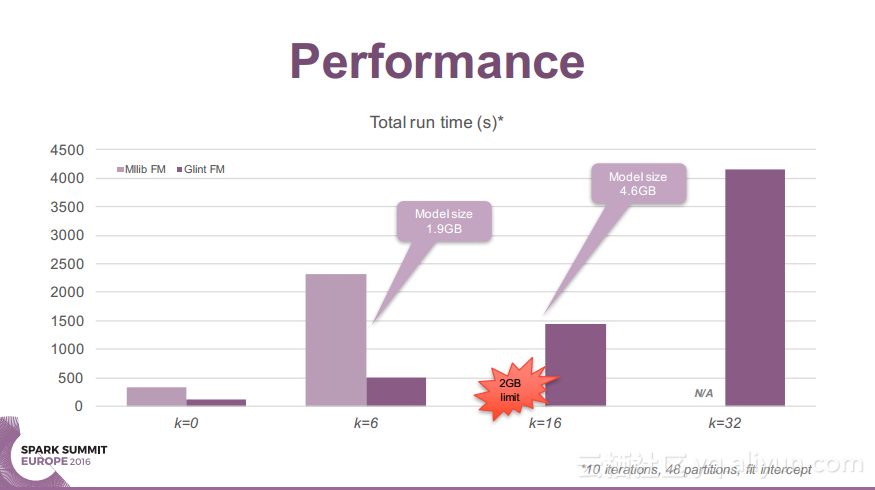
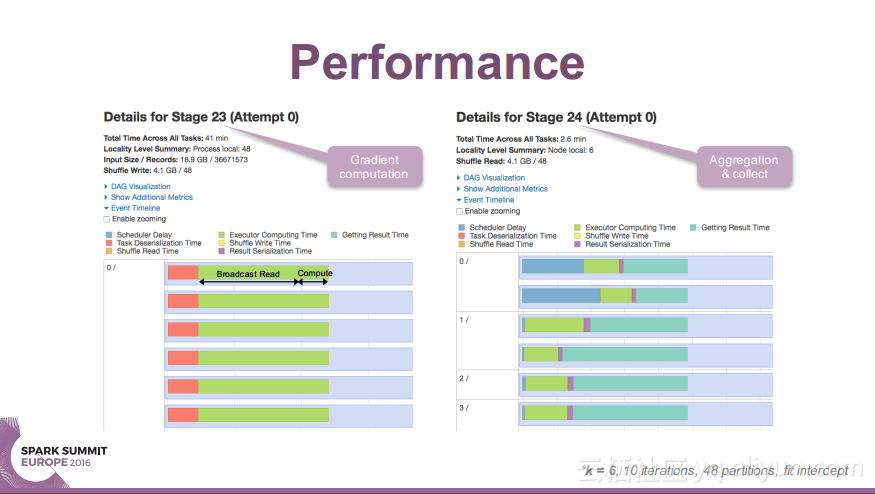
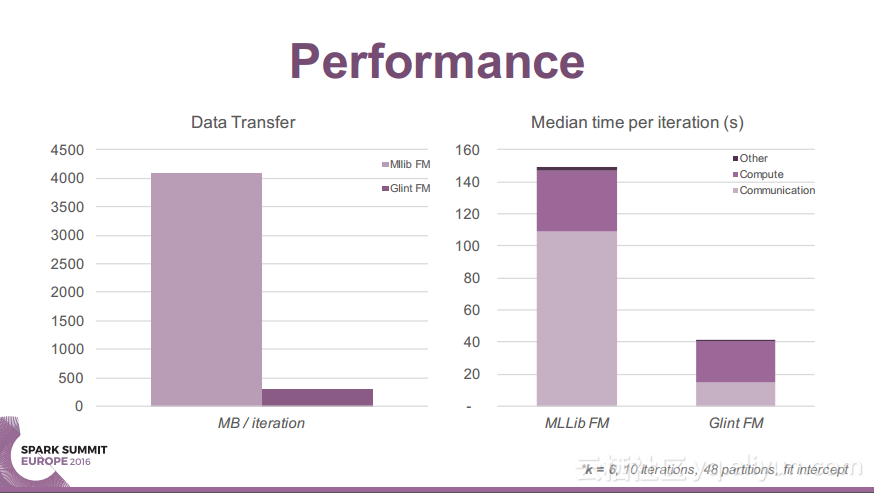
更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
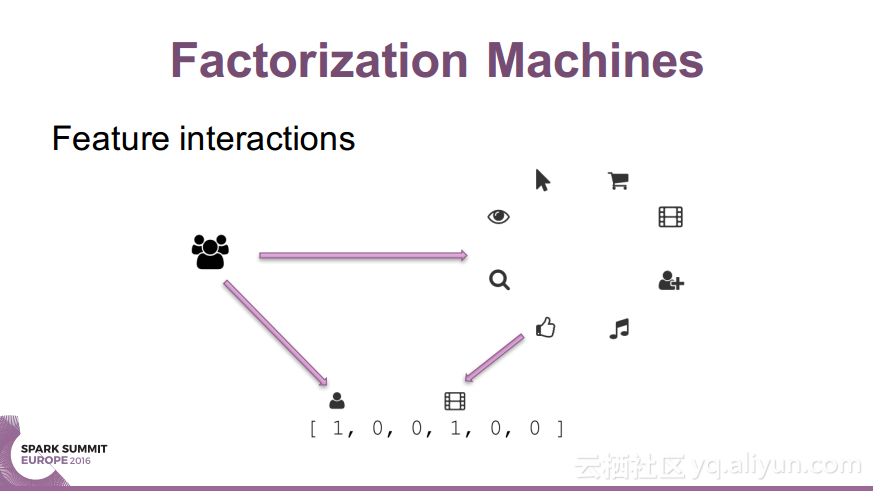
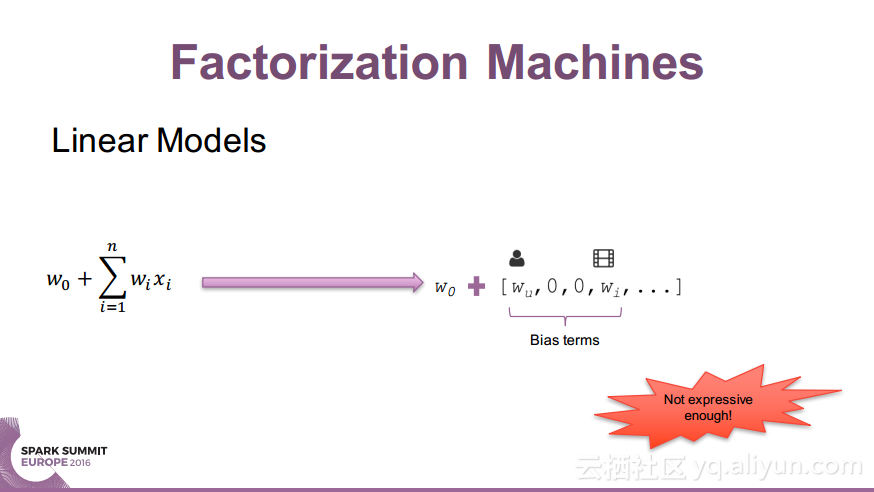
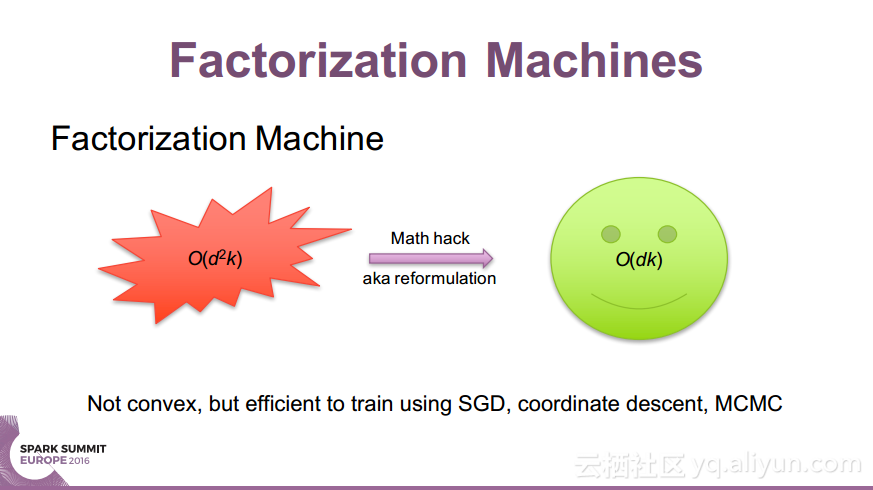
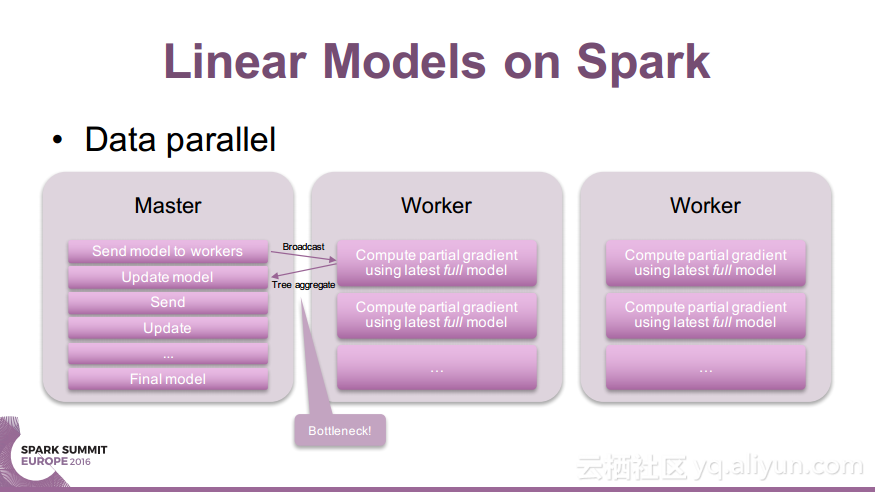
本讲义出自Nick Pentreath在Spark Summit EU 2016上的演讲,主要介绍了什么是因式分解机(Factorization Machines)以及使用Spark和Glint构建的分布式因式分解机过程中使用到的Spark线性模型、参数服务器以及分布式因式分解机等内容,除此之外讲义中还介绍了目前的研究成果以及面对的挑战和未来的研究发展方向。