更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
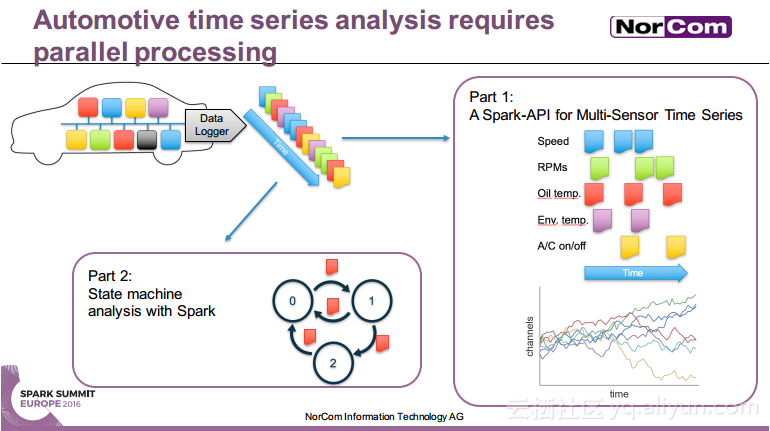
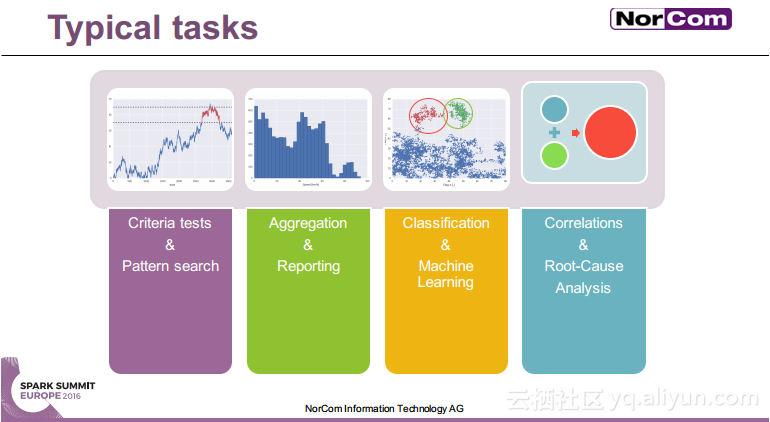
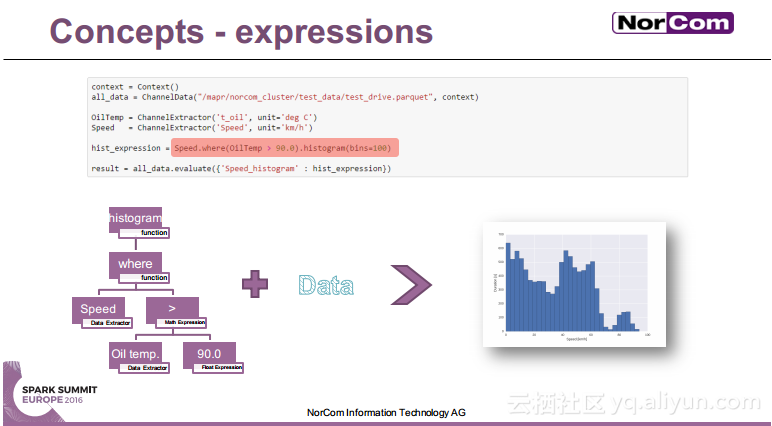
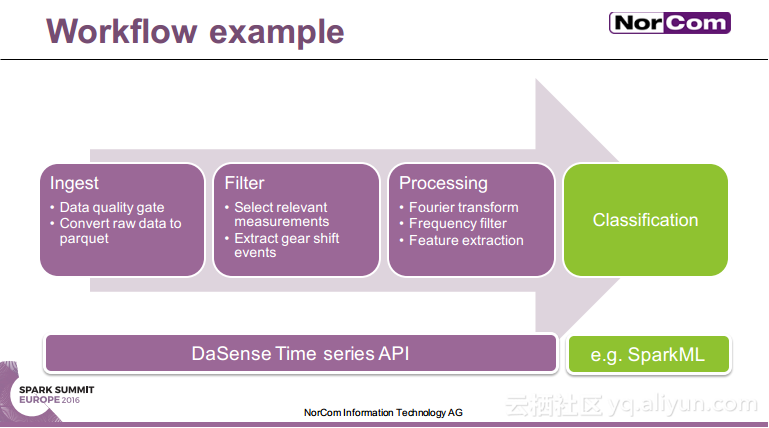
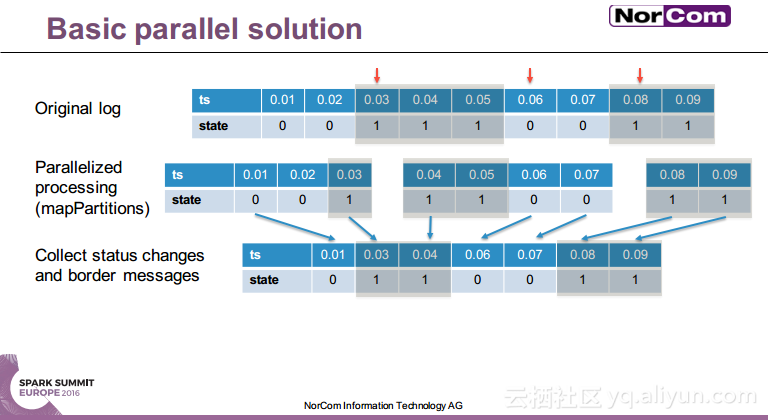
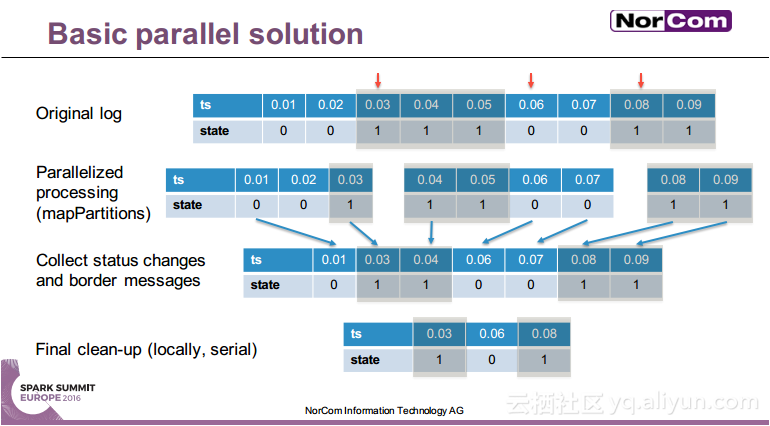
本讲义出自Miha Pelko与Til Piffl在Spark Summit EU上的演讲,主要介绍了汽车行业目前已经成为了主要的数据产生者,由于汽车行业的数据问题比较特殊,所以需要进行并行的时间序列分析。除此之外还介绍了关于多传感器时间序列分析的Spark API——DaSense,并行状态机在汽车行业的使用以及并行的大数据解决方案。