更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
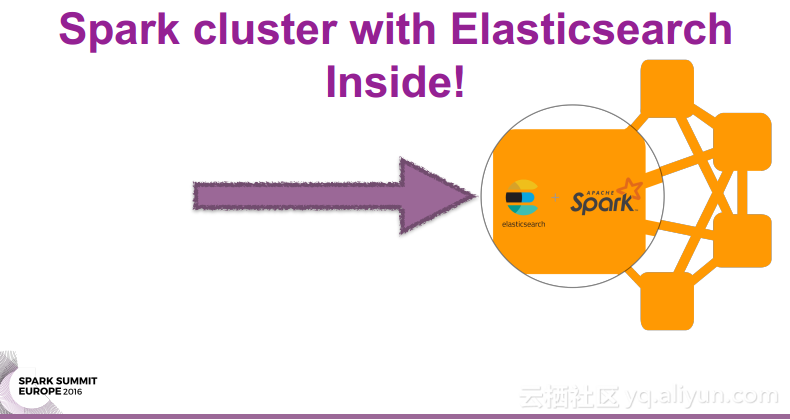
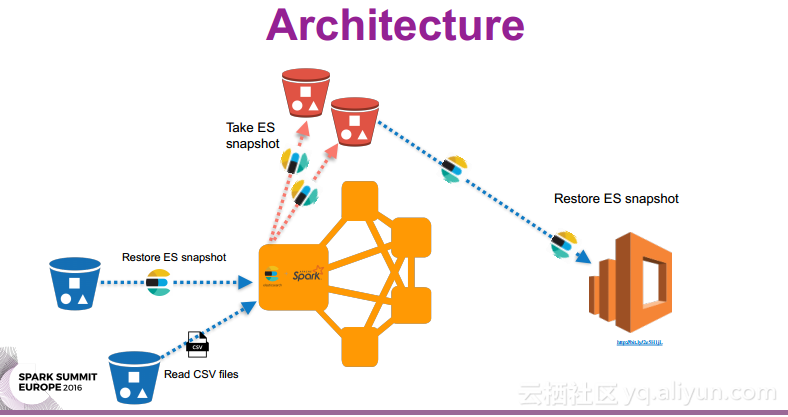
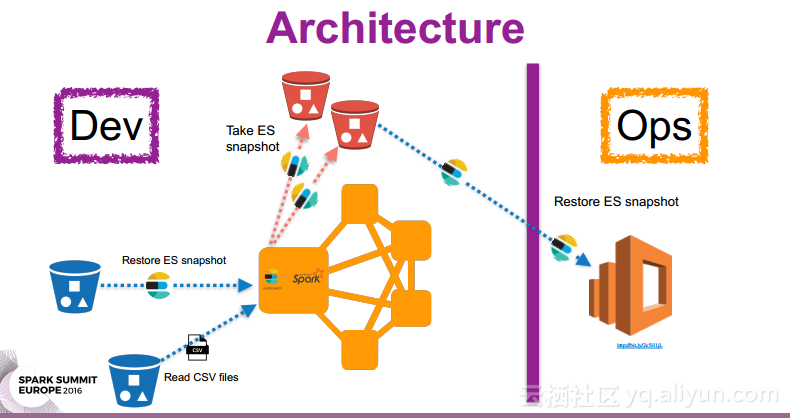
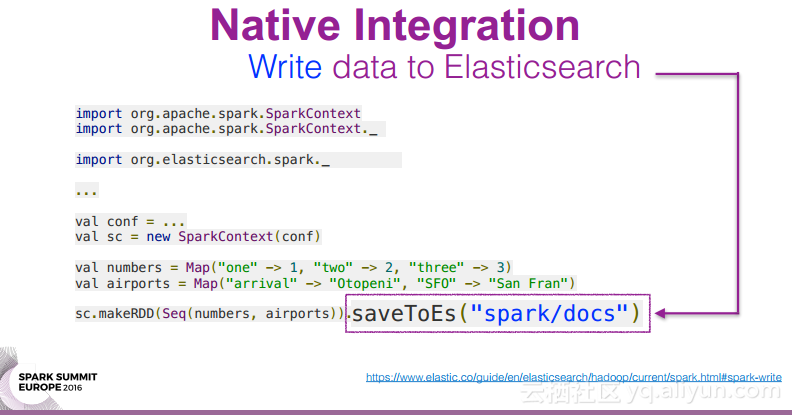
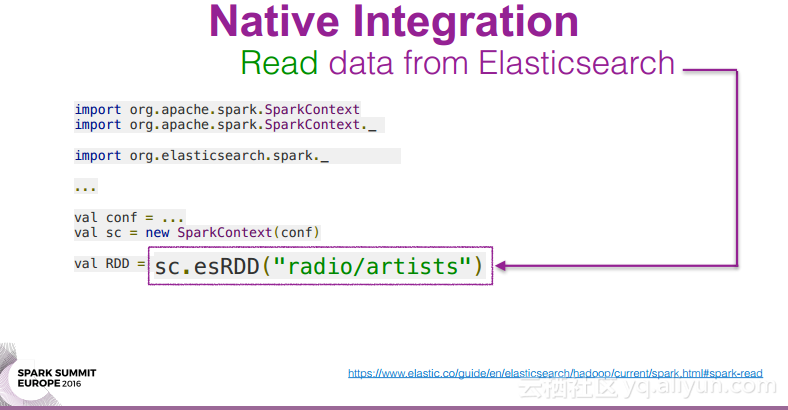
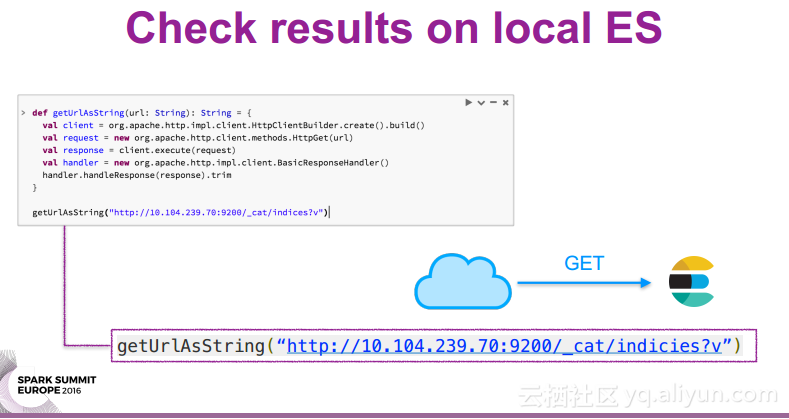
本讲义出自Oscar Castaneda在Spark Summit EU上的演讲,在使用ES-Hadoop进行开发的过程中,使Elasticsearch运行在Spark集群外部是一件非常繁琐的事情,为了在开发过程中更好地Elasticsearch实例,并且尽可能地降低开发团队之间的依赖关系,使用ES快照作为团队合作的接口,并且提高QA的效率,所以提出了在Spark集群中内置Elasticsearch的方式。