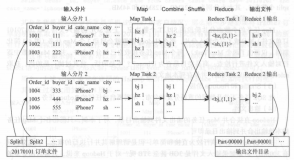
HIVE TopN Shuffle
TopN 问题是排序中的一个经典问题。对于一个长度为 m 的数组,取其最大的 n (n <= m) 条数据,可以不必对整个数组进行全排。一般的算法对 m 进行全排的复杂度大约为 mlog2(m)。假设我们只取其中最大的 n 条,那么可以把这个复杂度降低到 m * log2(n)。如果 n << m,那么收益还是很大的。
HIVE-3562 引入了一个针对 TopN 的优化,即将带有 limit 算子的 order by 推至 map 端,这样 map 不必将所有数据 shuffle 到 reduce。order by 和 limit 算子在日常使用场景中经常一起出现,因此这个优化就显得很有必要。
抛开 limit 是如何下推的不管,我们这里只关注 ReduceSinkOperator 拿到 limit 算子后如何处理这个逻辑。代码入口是 ReduceSinkOperator#process(...) 方法。
ReduceSinkOperator 内维护了一个 TopNHash 变量 reducerHash,该变量决定了一条 row 是否被 collect,也就是说,是否被 shuffle 到下游:
// Try to store the first key.
// if TopNHashes aren't active, always forward
// if TopNHashes are active, proceed if not already excluded (i.e order by limit)
final int firstIndex =
(reducerHash != null) ? reducerHash.tryStoreKey(firstKey, partKeyNull) : TopNHash.FORWARD;
if (firstIndex == TopNHash.EXCLUDE)
{
return; // Nothing to do.
}
// Compute value and hashcode - we'd either store or forward them.
BytesWritable value = makeValueWritable(row);
if (firstIndex == TopNHash.FORWARD) {
collect(firstKey, value);
} else {
// invariant: reducerHash != null
assert firstIndex >= 0;
reducerHash.storeValue(firstIndex, firstKey.hashCode(), value, false);
}其中有一个非常重要的方法TopNHash.tryStoreKey(...)。它的意思是尝试把该行存到一个 topN 的 heap 中。之所以是尝试,是因为它有几个返回值,每个返回值都代表这行应当被如何操作:
- TopNHash.FORWARD (-1): 该 row 将被 collect,也就是要被 shuffle
- TopNHash.EXCLUDE (-2): 该 row 将被抛弃
- index >= 0: 说明该行被 topN 堆给记录下来了,有幸进入 topN 候选,该 row 的值不会被直接 collect,而是通过
reducerHash.storeValue(...)方法存储下来。
我们回过头来看上面的代码:当没有 limit 信息时,reducerHash 不被初始化,因此所有的 row 都是 TopNHash.FORWARD,之后被 collect。反之,如果有 limit,则会根据 TopNHash.tryStoreKey(...) 的返回值走相应的逻辑。如果返回值是 index >= 0,那么该行数据会被存到 topN 的 heap 中,待到整个 map 结束,被记录的这 topN 个 record 会被 collect,从而被 shuffle 出去:
private void flushInternal() throws IOException, HiveException {
for (int index : indexes.indexes()) {
if (index != evicted && values[index] != null) {
collector.collect(keys[index], values[index], hashes[index]);
usage -= values[index].length;
values[index] = null;
hashes[index] = -1;
}
}
excluded = 0;
}不考虑 TopNHash.FORWARD,整个逻辑是非常清晰的。一行数据进来,要么进入 heap 参与排序,要么 heap 都进不了,直接被 EXCLUDE。随着处理的行数越来越多,heap 中的数据主键被替换成了 topN。
但是 TopNHash.FORWARD 是个什么鬼?TopNHash.tryStoreKey(...) 在什么情况下会返回 TopNHash.FORWARD 呢?仔细深入代码看一下
private int insertKeyIntoHeap(HiveKey key) throws IOException, HiveException {
if (usage > threshold) {
flushInternal();
if (excluded == 0) {
LOG.info("Top-N hash is disabled");
isEnabled = false;
}
// we can now retry adding key/value into hash, which is flushed.
// but for simplicity, just forward them
return FORWARD;
}
int size = indexes.size();
int index = size < topN ? size : evicted;
keys[index] = Arrays.copyOf(key.getBytes(), key.getLength());
distKeyLengths[index] = key.getDistKeyLength();
hashes[index] = key.hashCode();
if (null != indexes.store(index)) {
// it's only for GBY which should forward all values associated with the key in the range
// of limit. new value should be attatched with the key but in current implementation,
// only one values is allowed. with map-aggreagtion which is true by default,
// this is not common case, so just forward new key/value and forget that (todo)
return FORWARD;
}
if (size == topN) {
evicted = indexes.removeBiggest(); // remove the biggest key
if (index == evicted) {
excluded++;
return EXCLUDE; // input key is bigger than any of keys in hash
}
removed(evicted);
}
return index;
}里边的注释很明显地写着,这是为了处理 group by limit(GBY) 这种情况。(GBY)是一种与 order by limit(OBY) 不同的情形。对于前者,limit 是限制在 group 上的,而后者 limit 是限制在 row 上的。下面是一个栗子。
假设一张表具有 schema (age,name,其他字段),OBY 和 GBY 的 key 都是前两个字段的组合。假设表有如下内容:
+------------
|10,zhangsan,xxx
|20,lisi,xxx
|20,lisi,yyy
|30,wangwu,zzz
+------------那么 OBY limit 3 输出
+------------
|10,zhangsan,xxx
|20,lisi,xxx
|20,lisi,yyy
+------------GBY limit 3 输出
+------------
|10,zhangsan,xxx
+------------
|20,lisi,xxx
|20,lisi,yyy
+------------
|30,wangwu,zzz
+------------这里很清楚地显示了两种 limit 的区别。在 OBY 情况下,所有 row 会一视同仁,limit 限制在 row 上。而在 GBY 情况下,具有相同 order 值的行不会被重复计数,因此对于 (20,lisi,yyy) 这一行,函数就会返回 TopNHash.FORWARD。
窗口函数
对于 Rank,DenseRank 这种窗口函数,我们经常会有这样的操作
select rand over (partition k1 order by k2) as rk from xxx where rk <= 10
HIVE-7063 对这种情况也做了 map 端 topN 优化。这种情况与上面两种都有所不同。首先它要求结果是分组的(partition),其次它要求分组内 limit (rk <= 10)。但是 HIVE-7063 比较巧妙地应用了上文提到的 topN 优化。它是怎么做的呢?实际上,HIVE-7063 对每个分组都分配了一个 TopNHash,这样,每个分组内取 topN 就可以了。但是 rank 函数还有点特殊的地方,因为两条记录的 rank 值可能会相同,而 rank 值相同的记录都需要被输出,因此 rk <= 100 输出的行数可能会大于 100 行。在这种情况下,每个分组内取 topN 的逻辑采用 GBY 的逻辑就可以了,于是就解决了这问题。
后记
这里有一个给笔者造成很大困扰的问题。问题的根源就在于这个返回值 TopNHash.FORWARD。由于 map 端的输入是无序的,那么当一个 row 进来的时候,TopNHash 可能会因为 heap 中已经存有相同的 key 而为该 row 返回 TopNHash.FORWARD。但是这一行不一定是真正的 topN,因为真正的 topN 只有当所有行都处理过了才知道。在不知道一行是不是属于真正 topN 的时候,返回 TopNHash.FORWARD 不就造成输出的数据大于 topN 了吗?是的,最终输出的数据数量确实大于 topN。但是在一般情况下,TopNHash 仍然能够过滤掉大量数据,它并不强制要求最后输出的就是真正的 topN,不在乎 topN 中是否掺杂有其他数据。当一行数据到来时,它只是尝试把它往 topN heap 里塞。如果能塞下,那么就输出它,即便它可能不是最终的 topN。如果数据是随机的,那么用不了多久,topN 的 heap 就塞满了,后来的数据如果再想往里塞,必须满足 heap 的入门标准。随着处理的数据越来越多,heap 的入门标准越来越高,因此会有越来越多的 row 被拒绝。这样,只有等所有的 row 都处理完毕后,TopNHash 保存的 rows 就是我们想要的 topN。其 map 输出可能是这样的(假设数据总量为 M)
row1 heap
row2 heap
row3 heap
...
rowN heap
rowN+1 forward
rowN+2 forward
rowN+3 heap
rowN+4 exclude
rowN+5 heap
rowN+6 forward
rowN+7 heap
...
row_M-6 forward
row_M-5 heap
row_M-4 exclude
row_M-3 exclude
row_M-2 exclude
row_M-1 exclude
row_M exclude在最开始的前 N 个数会进入 heap,然后会有较多的 heap 换入换出,也有较多的 forward,但随着数据处理的进行,forward 会越来越少,exclude 会越来越多,heap 中的数据会主键被替换为 topN 的数据。在数据排序随机的情况下,topN 中会很快的达到一个很高的入门标准,forward 减少的速度会很快。在大数情况下,exclude 的比例会非常接近 (M-N)/N。
如果数据已经是递增排序排好了呢?这种情况下,不会有数据被 reject。数据只有两种情况,一种是被 forward,一种是被换入 heap,将更小的数据换出。