更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
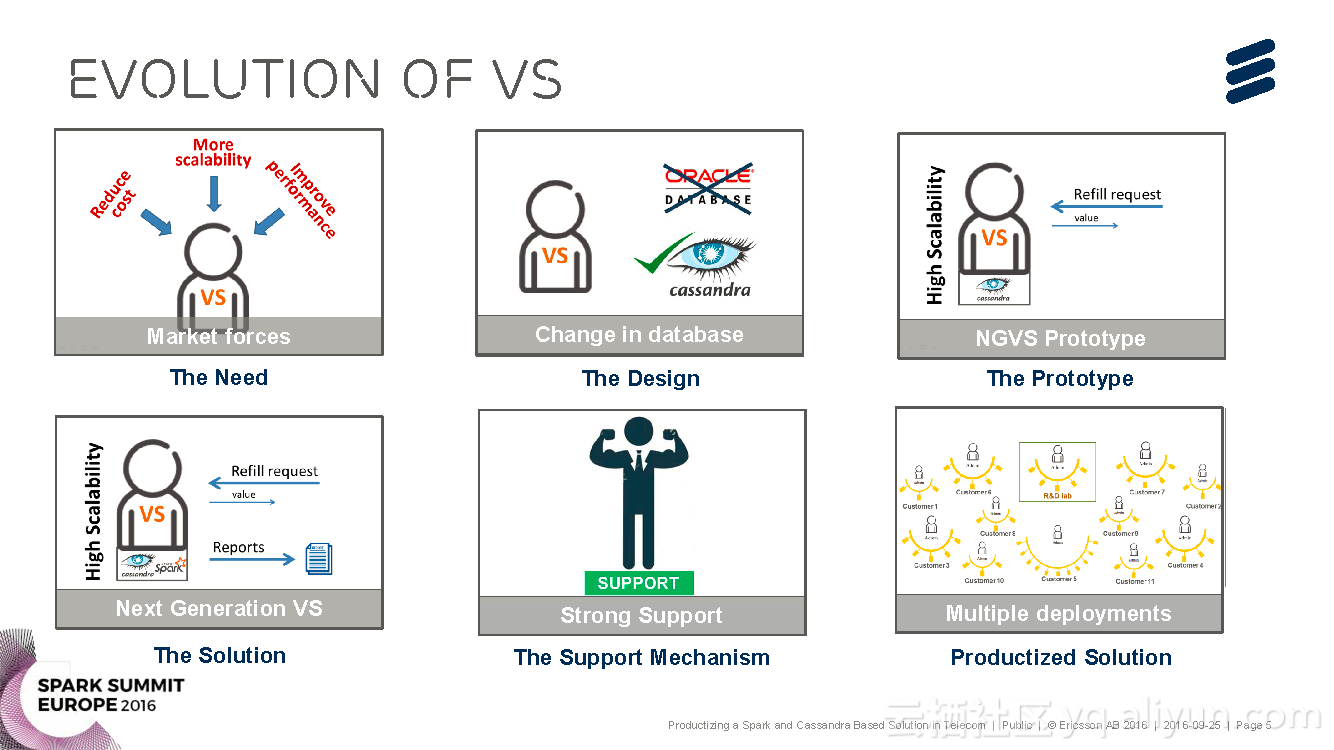
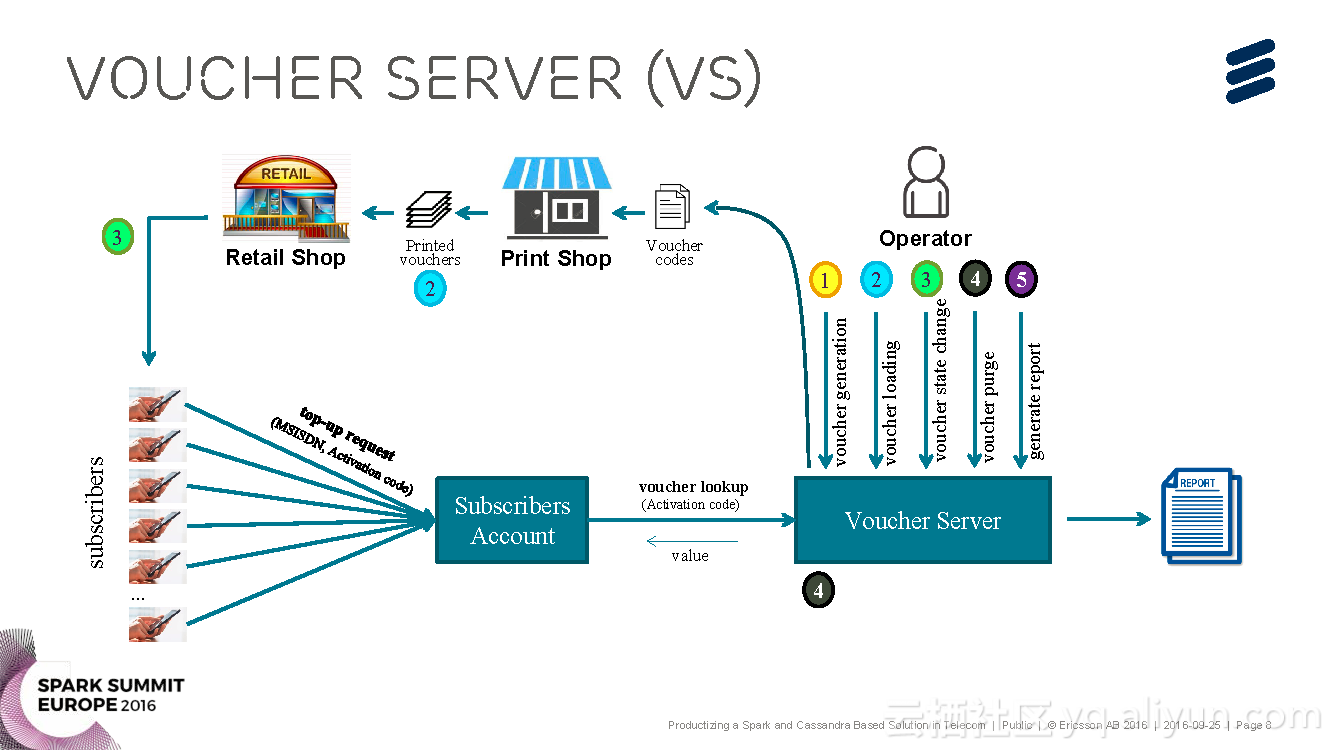
本讲义出自Brij Bhushan Ravat在Spark Summit EU上的演讲,主要介绍了爱立信公司研发的基于Spark与Cassandra的电信产品化解决方案Voucher Server。
Brij Bhushan Ravat从什么是产品化这个命题入手,分享了关于产品和Voucher Server
进化的观点,并对Voucher Server这款产品进行了简单介绍,并分享了Voucher Server面对的挑战与其发展进化的过程以及关于产品的运行和维护的挑战。