更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
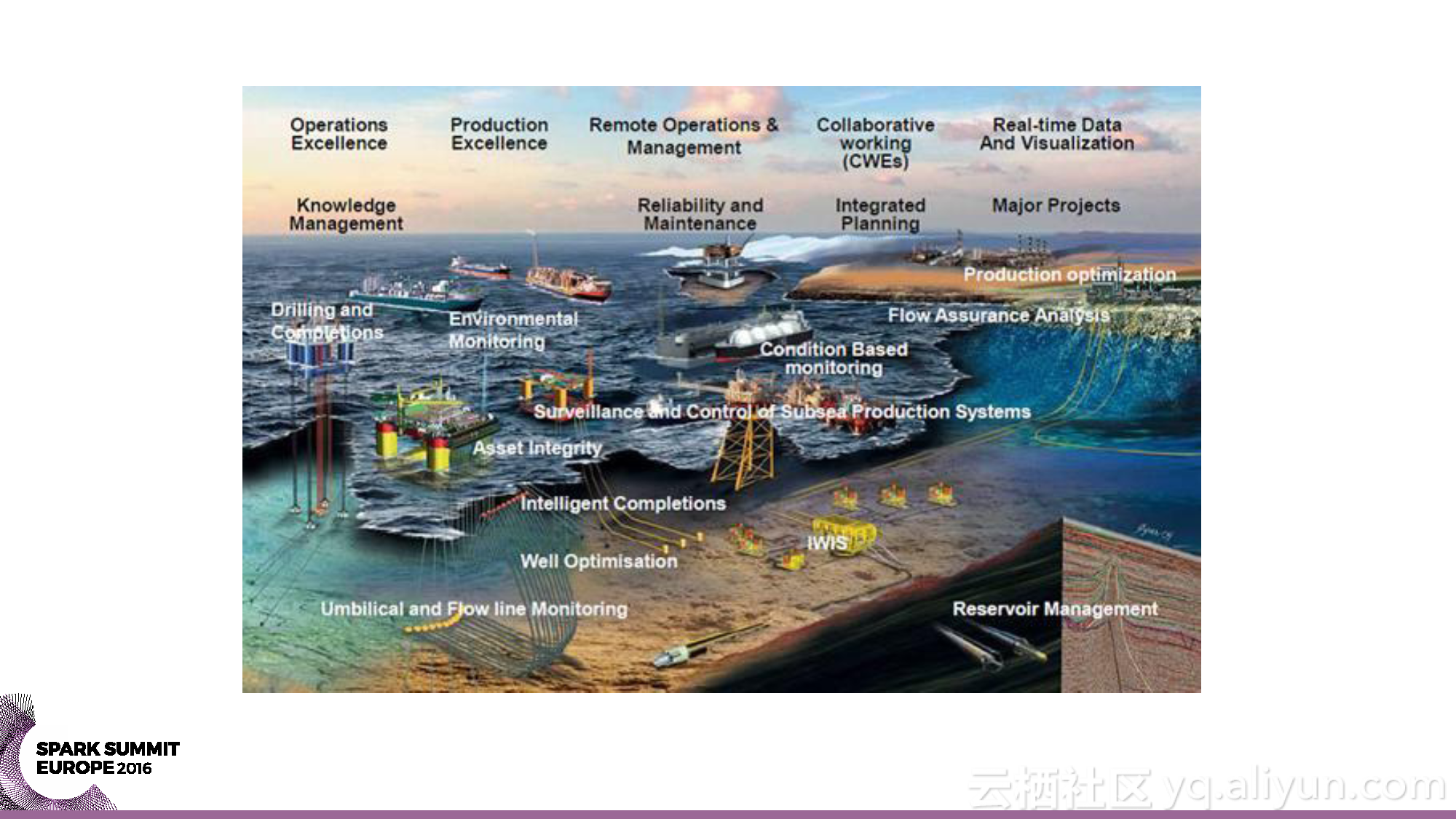
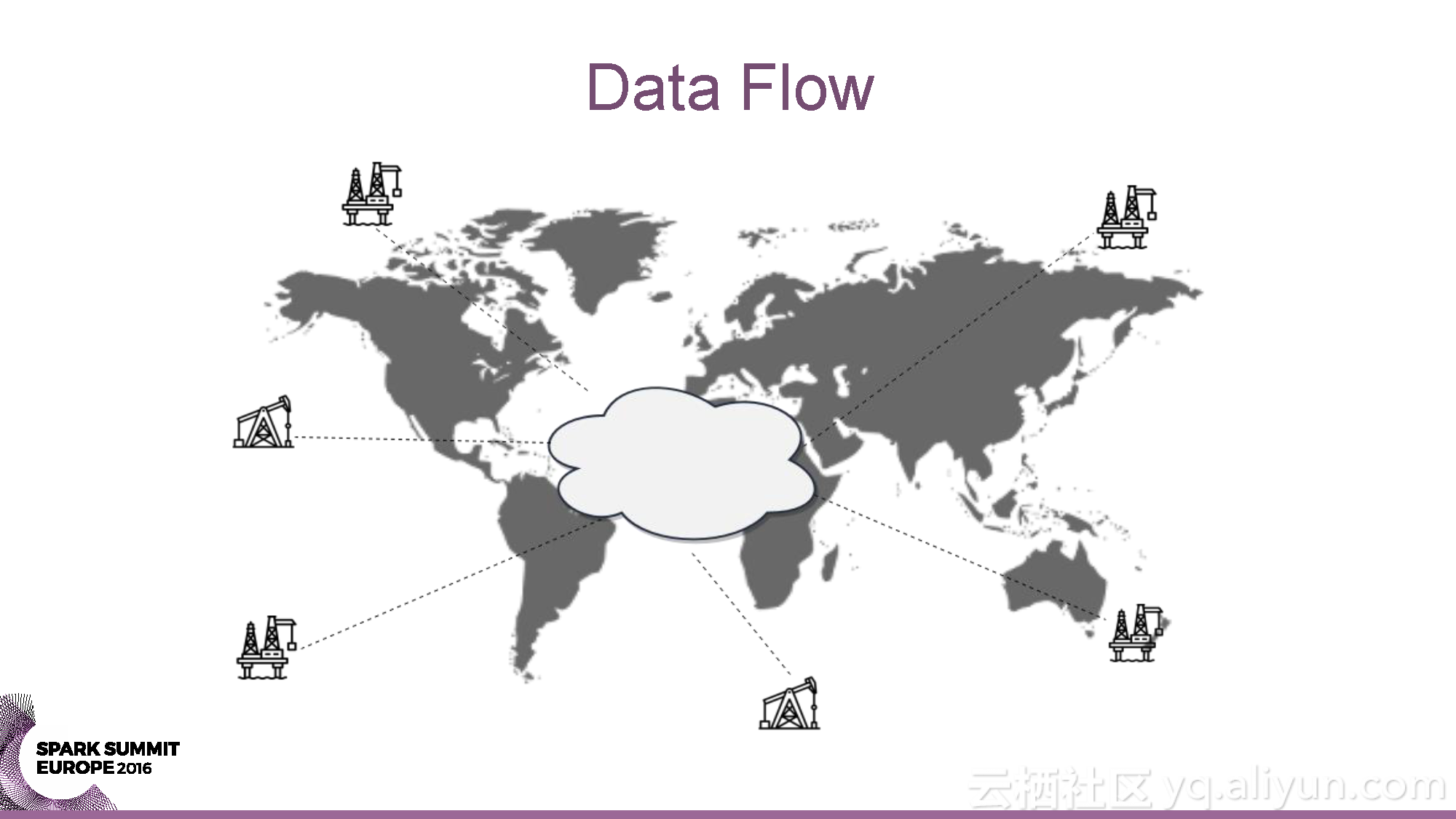
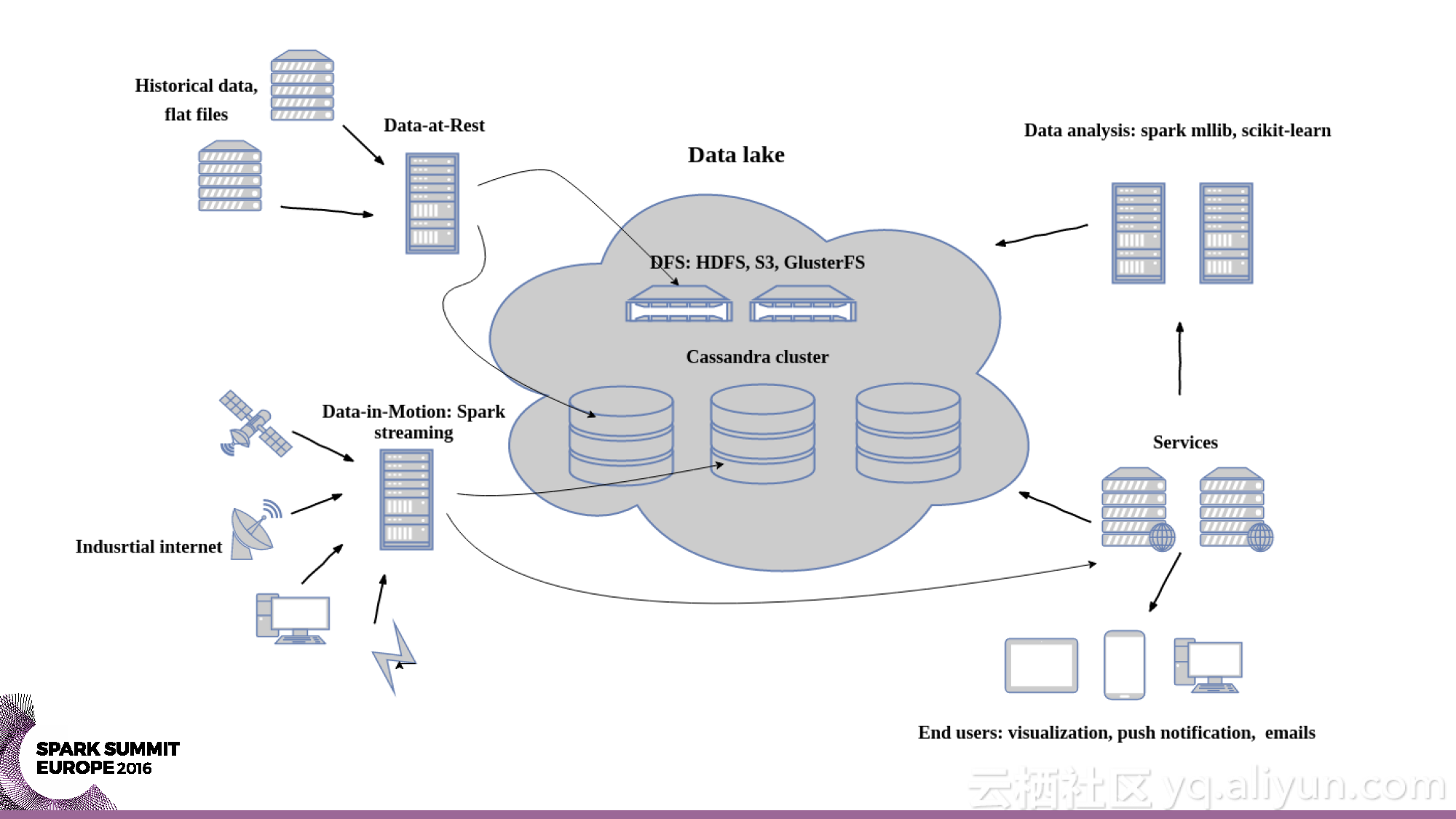
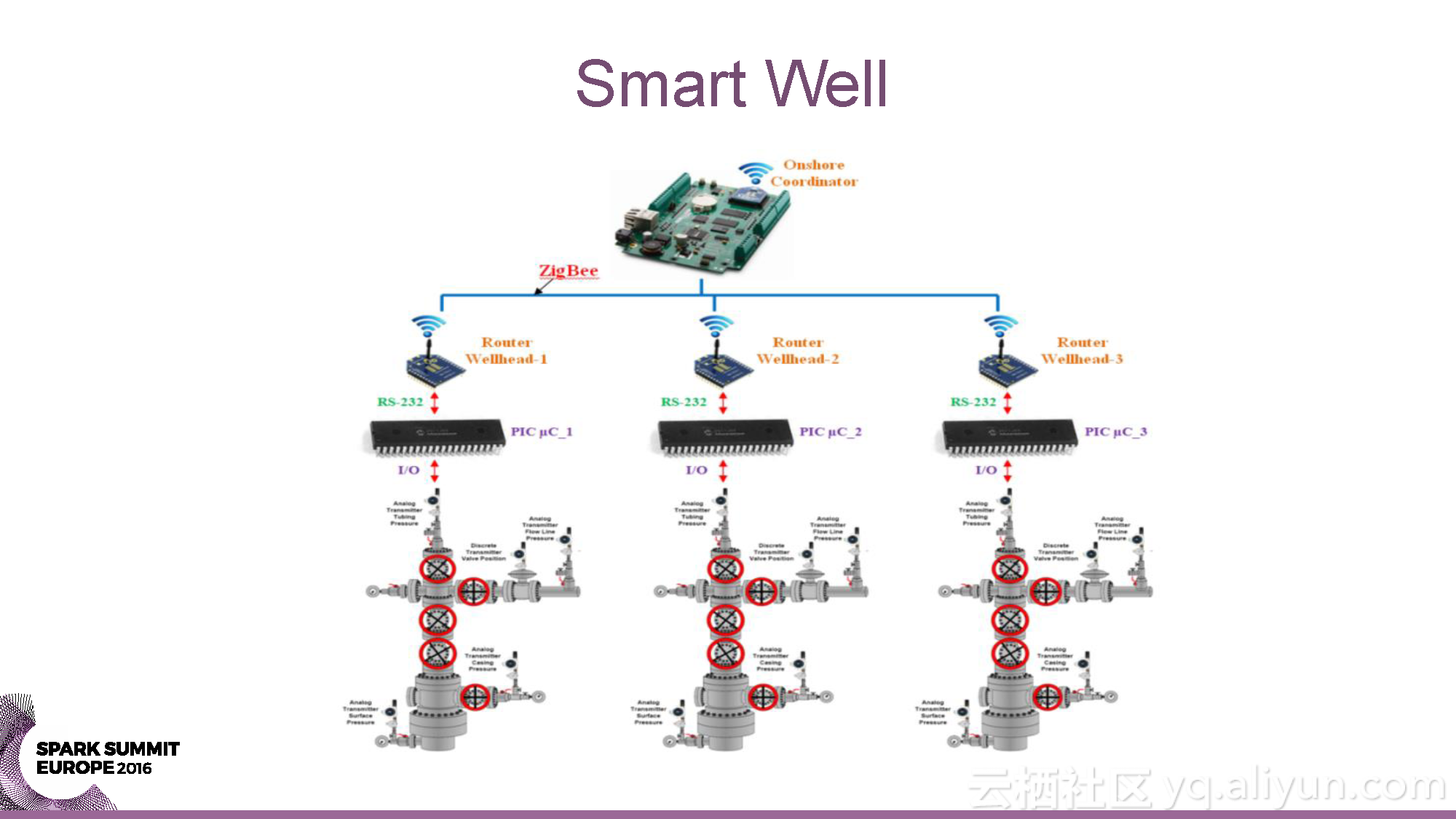
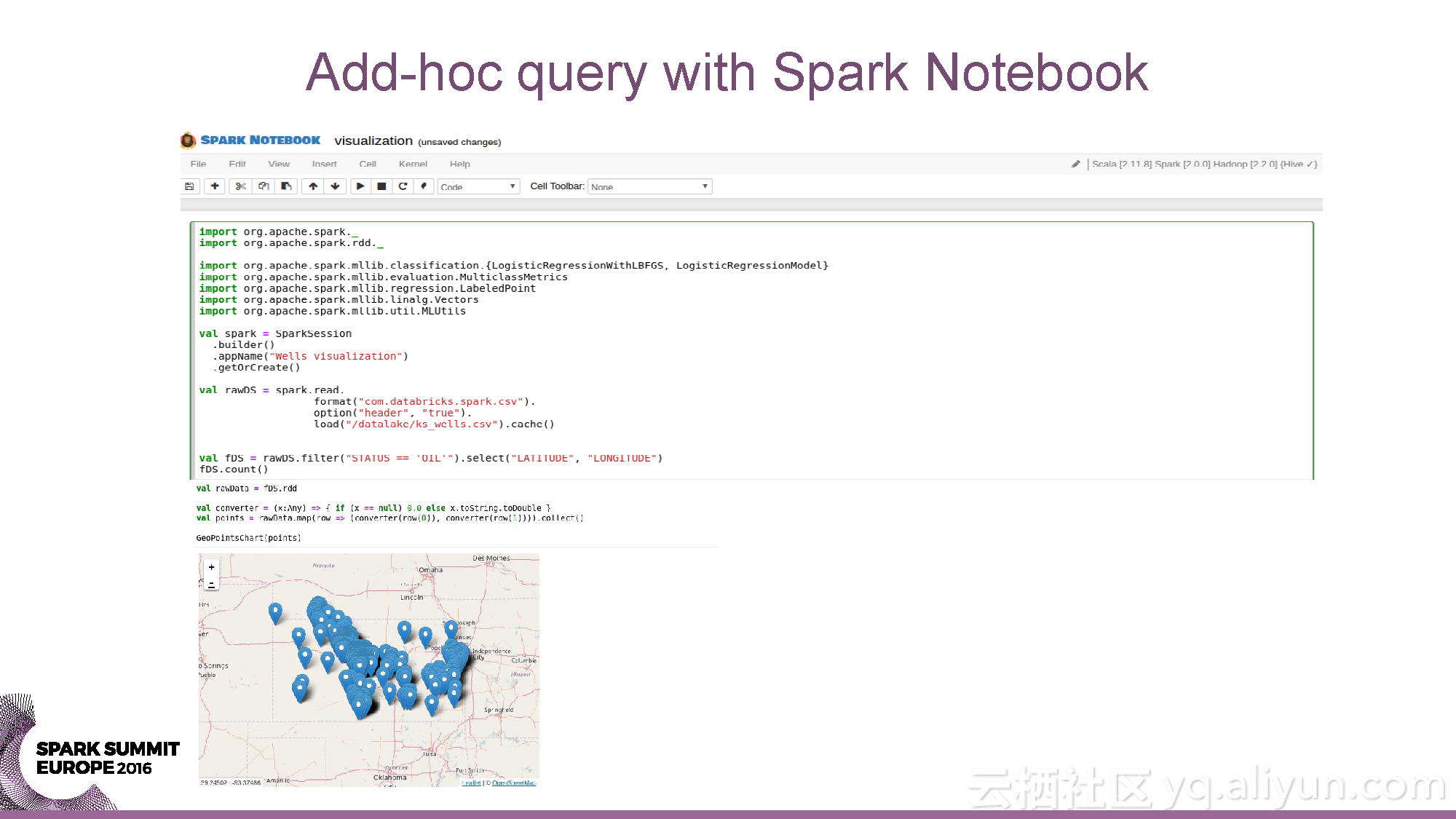
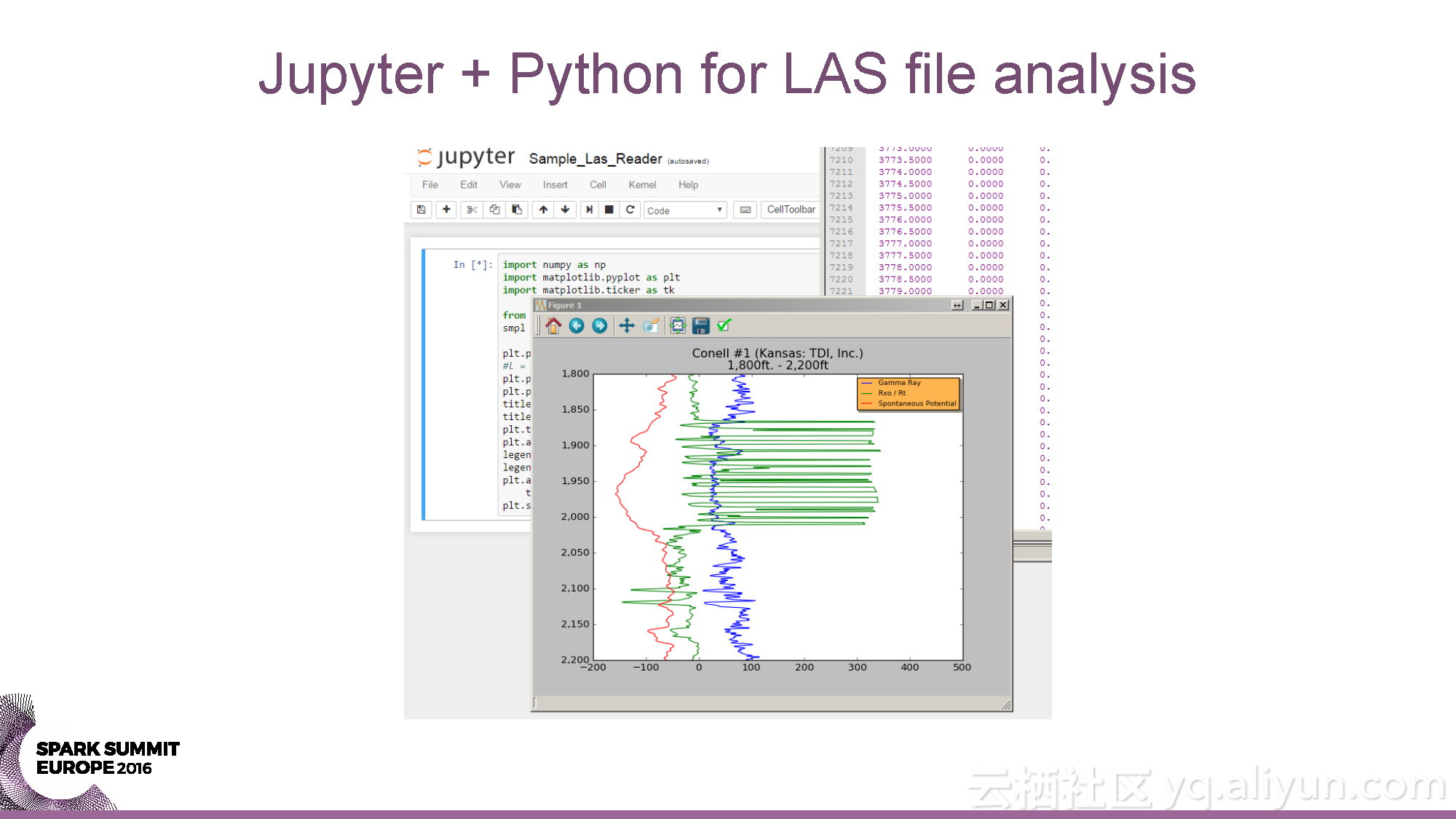
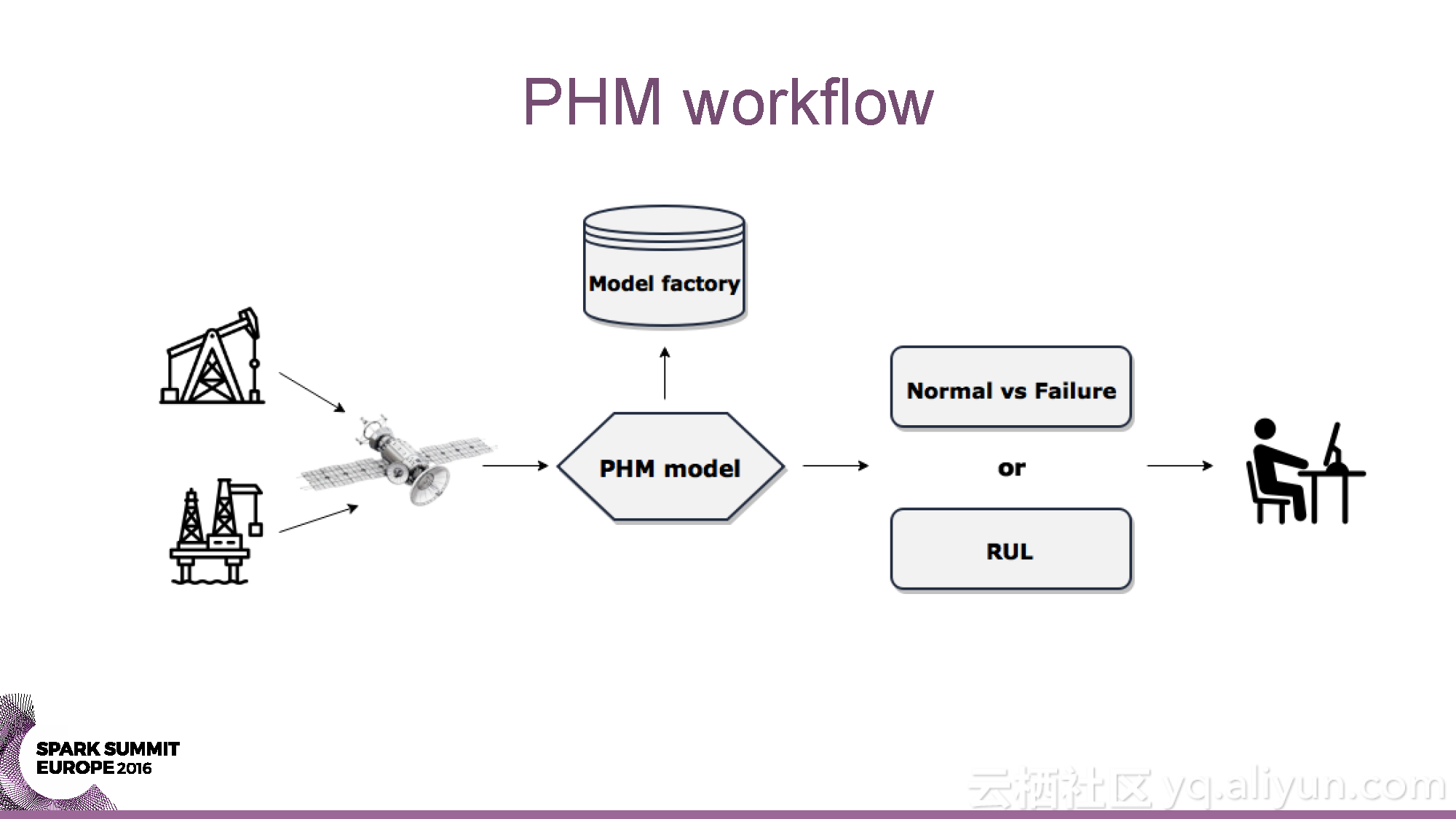
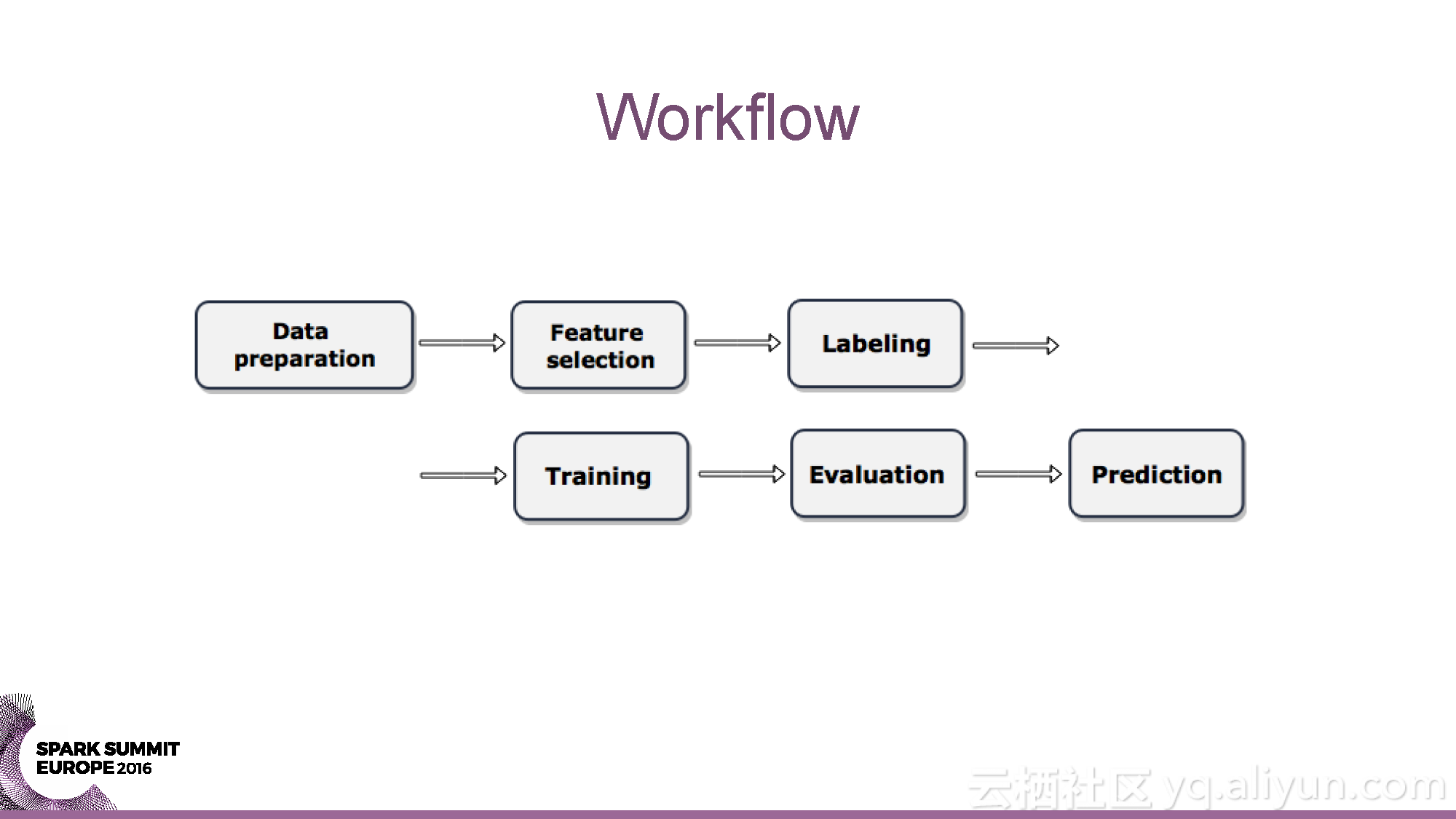
本讲义出自Yaroslav Nedashkovsky与Andy Starzhinsky在Spark Summit EU 2016上的演讲,主要介绍了从数据收集到预测分析的石油行业的数据分析过程,分享了石油工业的概览,以及从数据源头到数据收集,再到数据分析的全过程,并且分享了如何利用Spark打造处理石油工业数据的全球化计算引擎。