更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
本讲义出自Mike Gualtieri在Spark Summit East 2017上的演讲,主要分享了企业如何充分利用Spark在人工智能的研究中取得一席之地,以及人工智能如何帮助企业优化产品的用户体验。
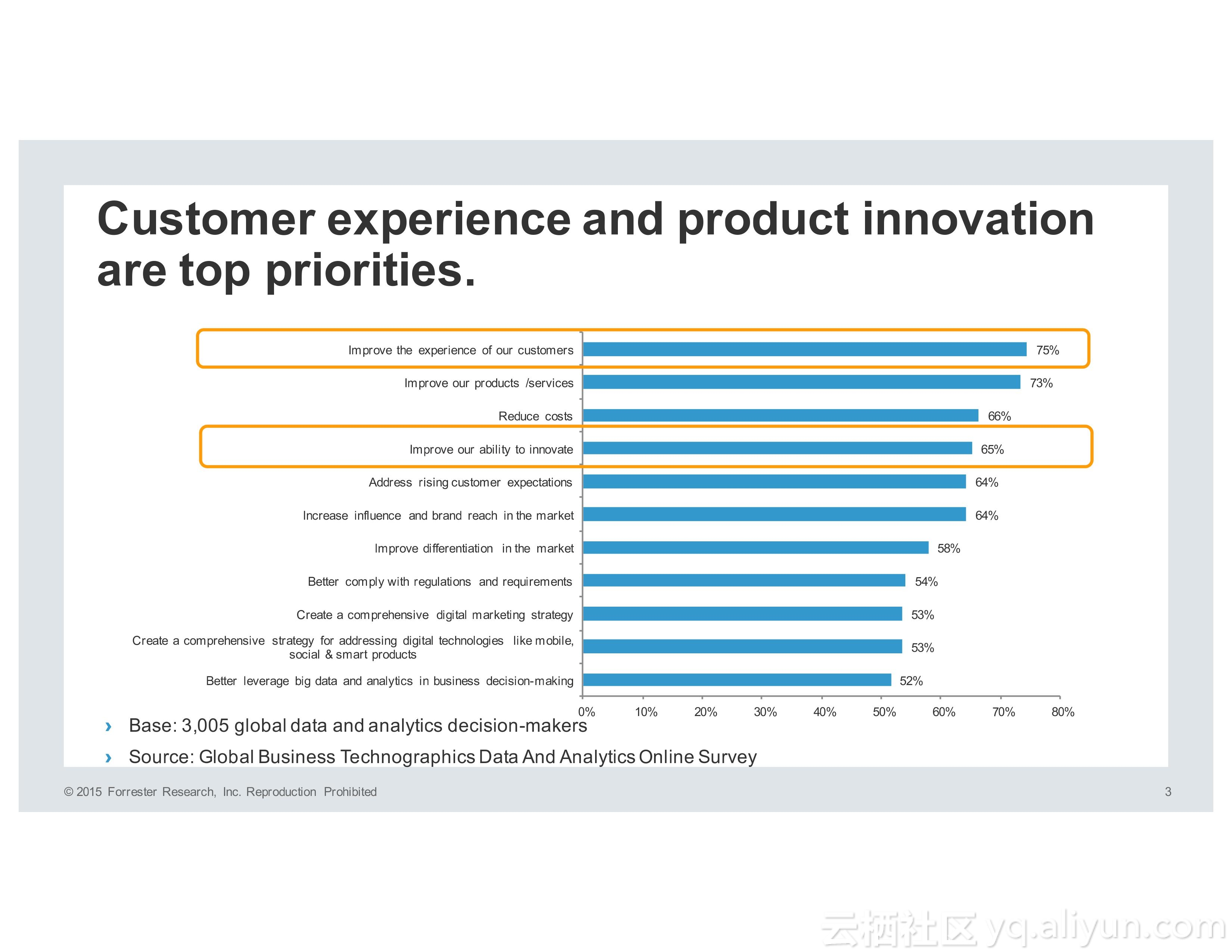
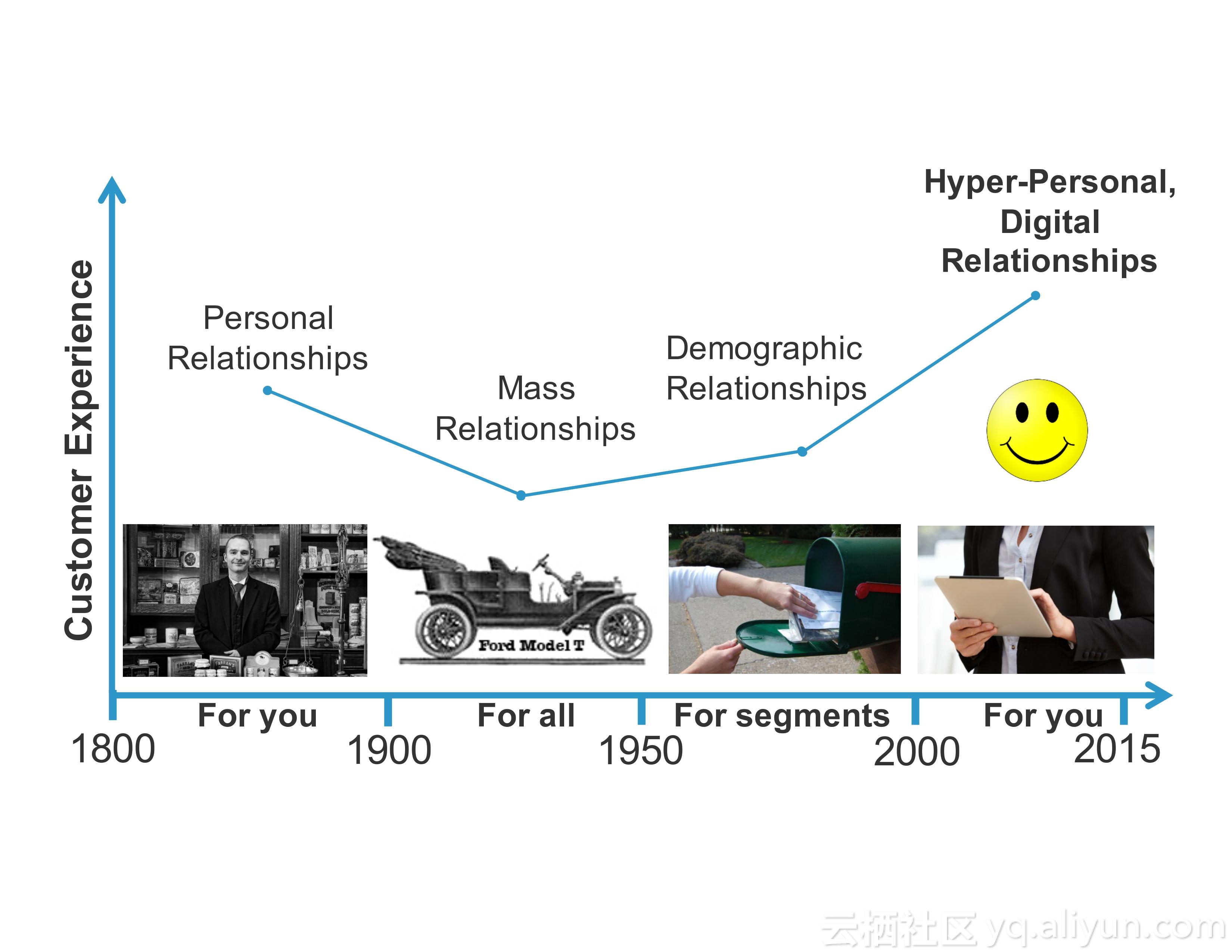
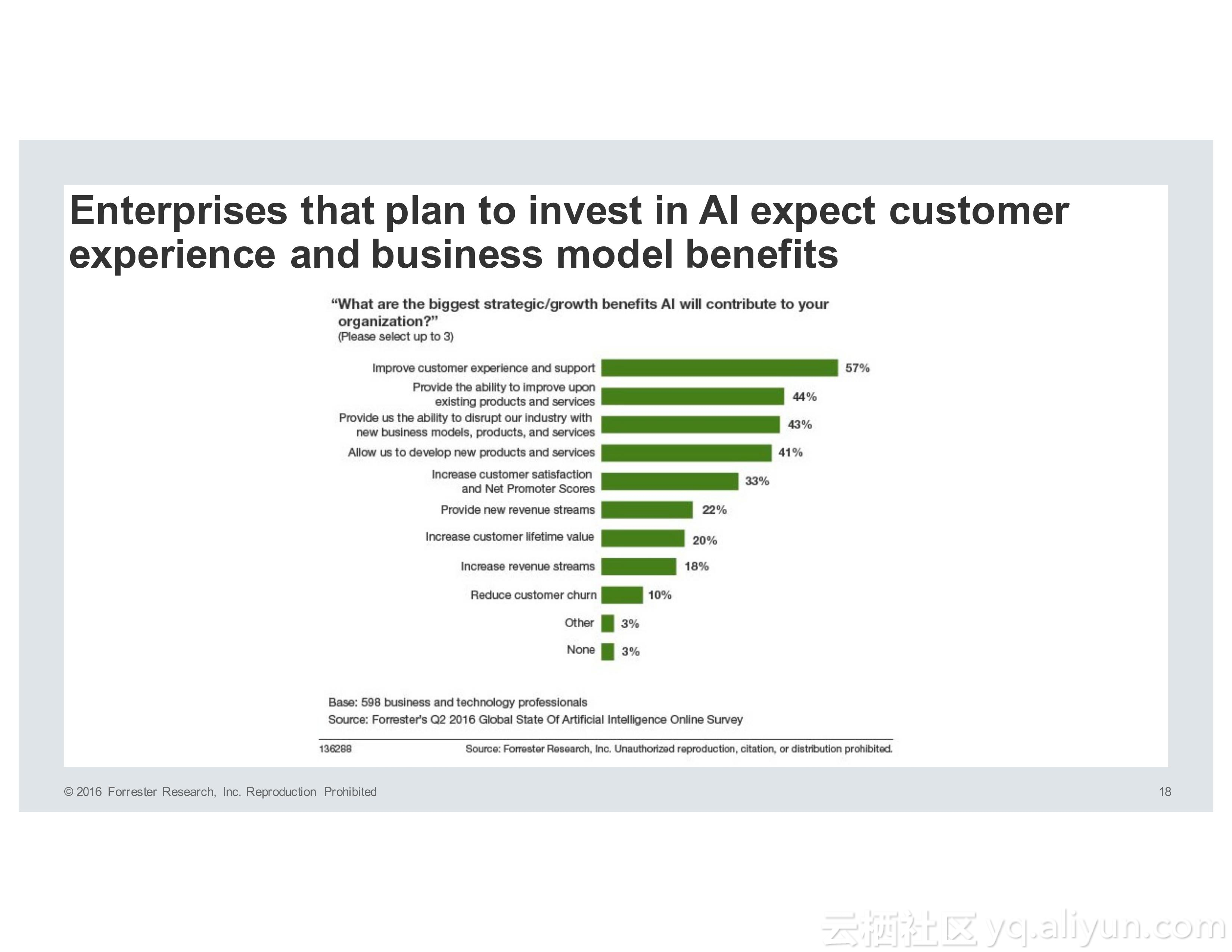
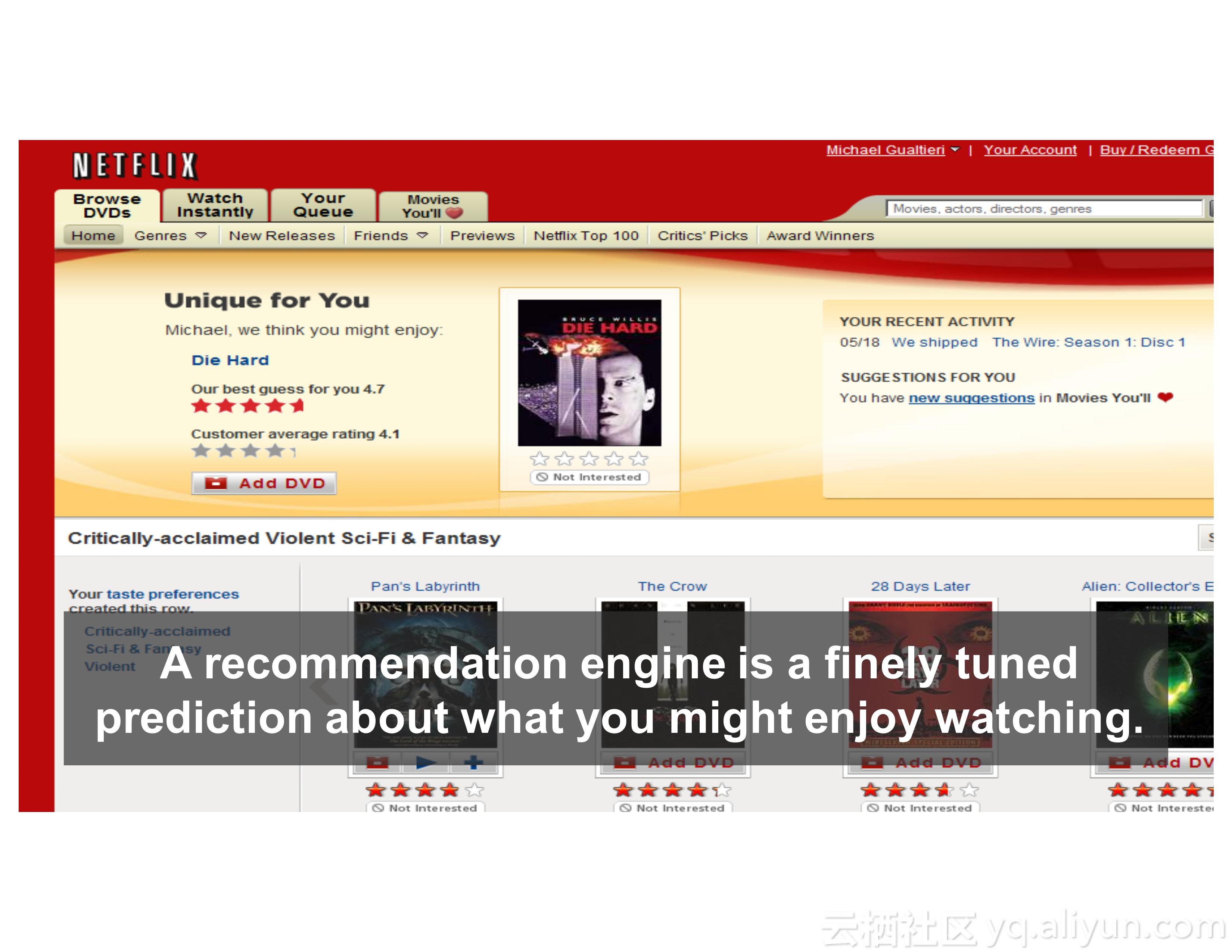
对于企业而言,用户体验和产品的创新性是应该考虑的首要问题。对于用户体验而言,客户希望企业就像老朋友一样了解他们。为了满足所谓的超人际用户体验,产品必须能够学习、预测和适应。为了使得产品能够实现以上的需求,就需要人工智能。目前而言,在人工智能方面进行投资的企业都希望能够在用户体验以及业务模型等方面获得利益。
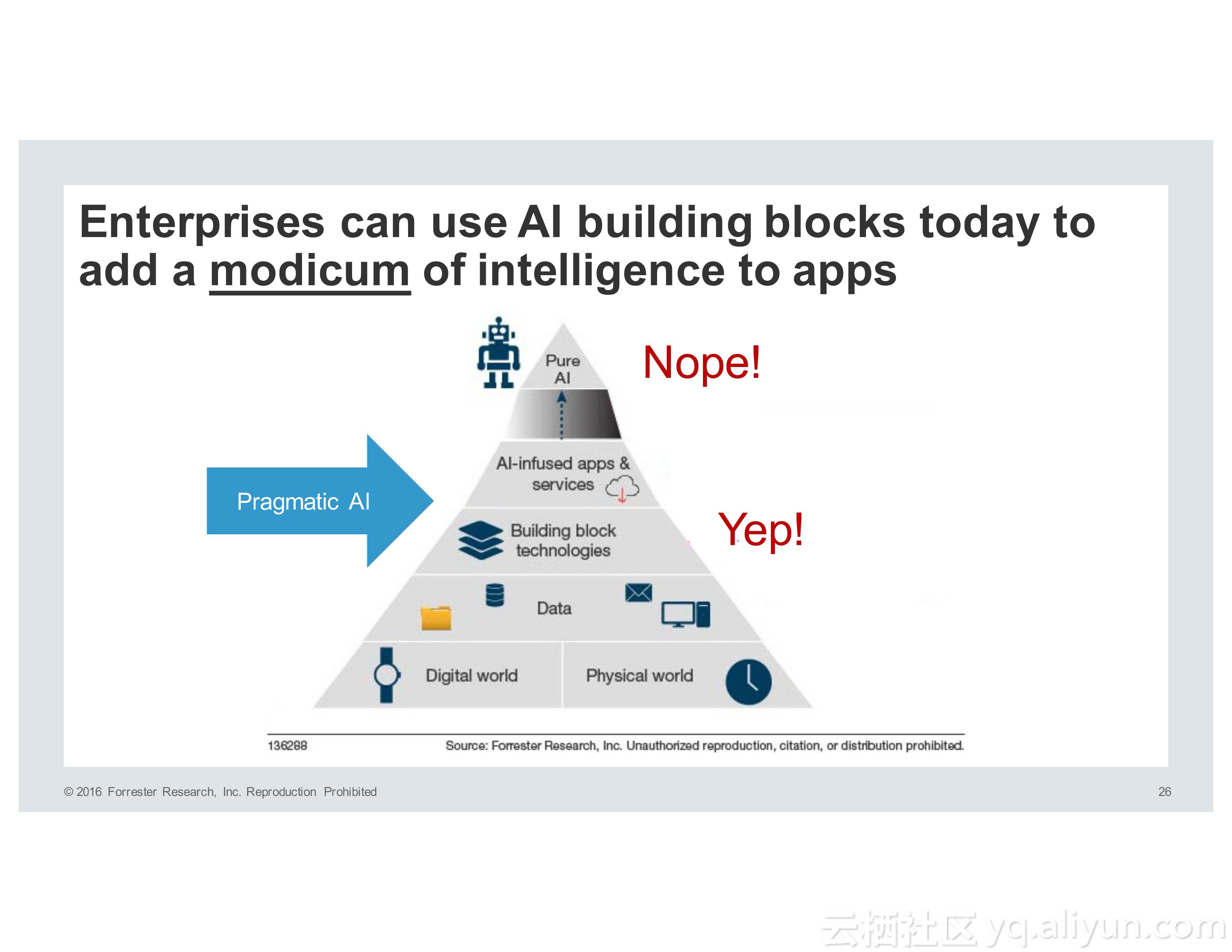
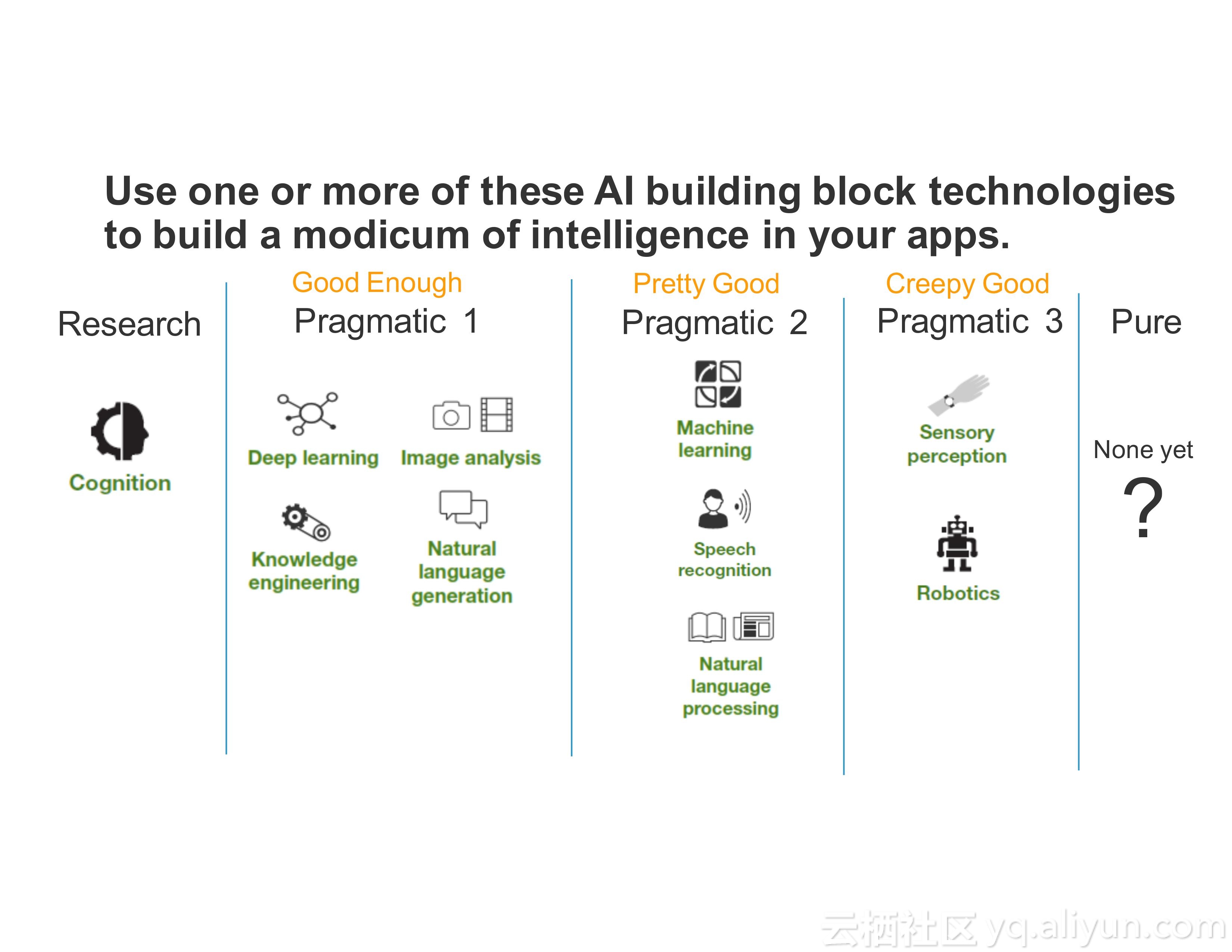
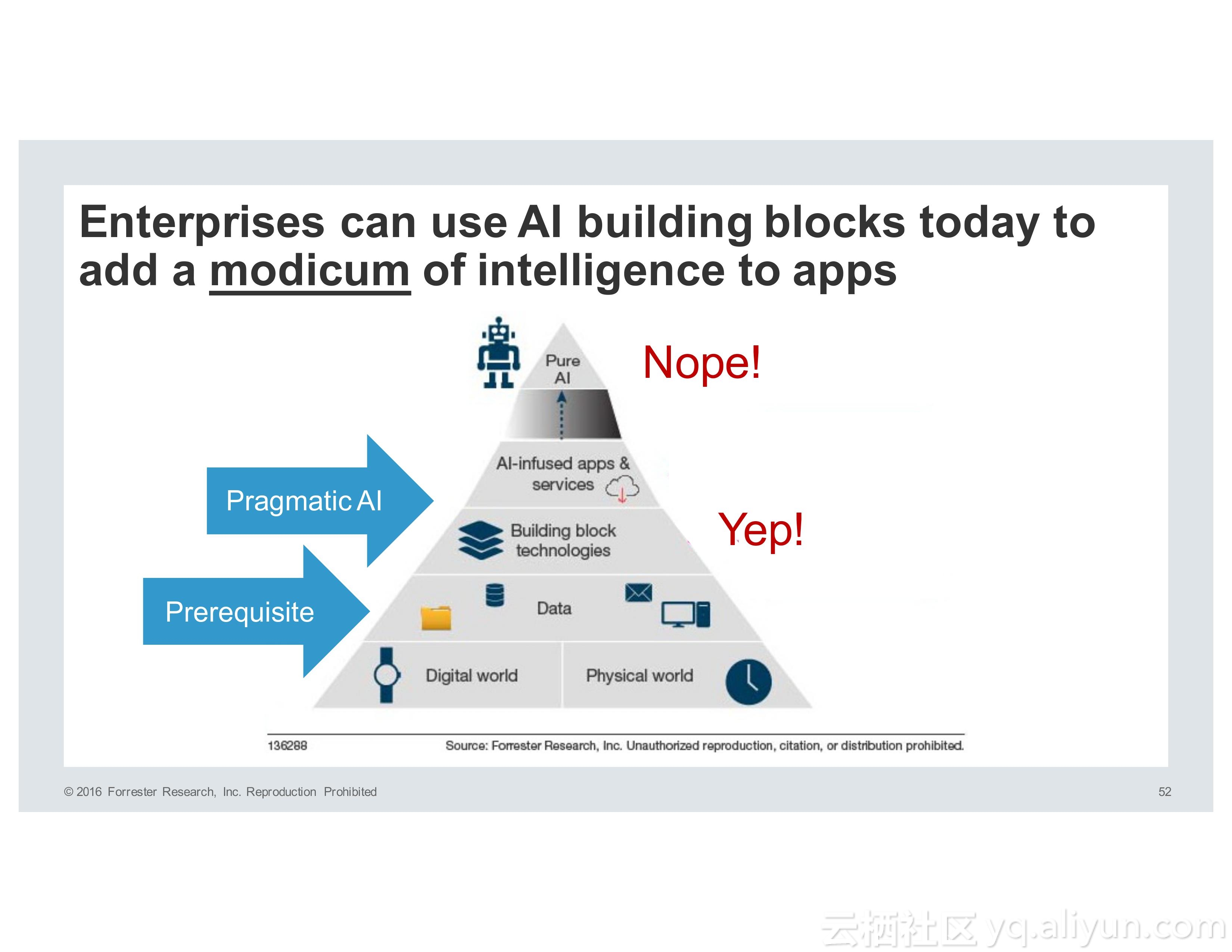
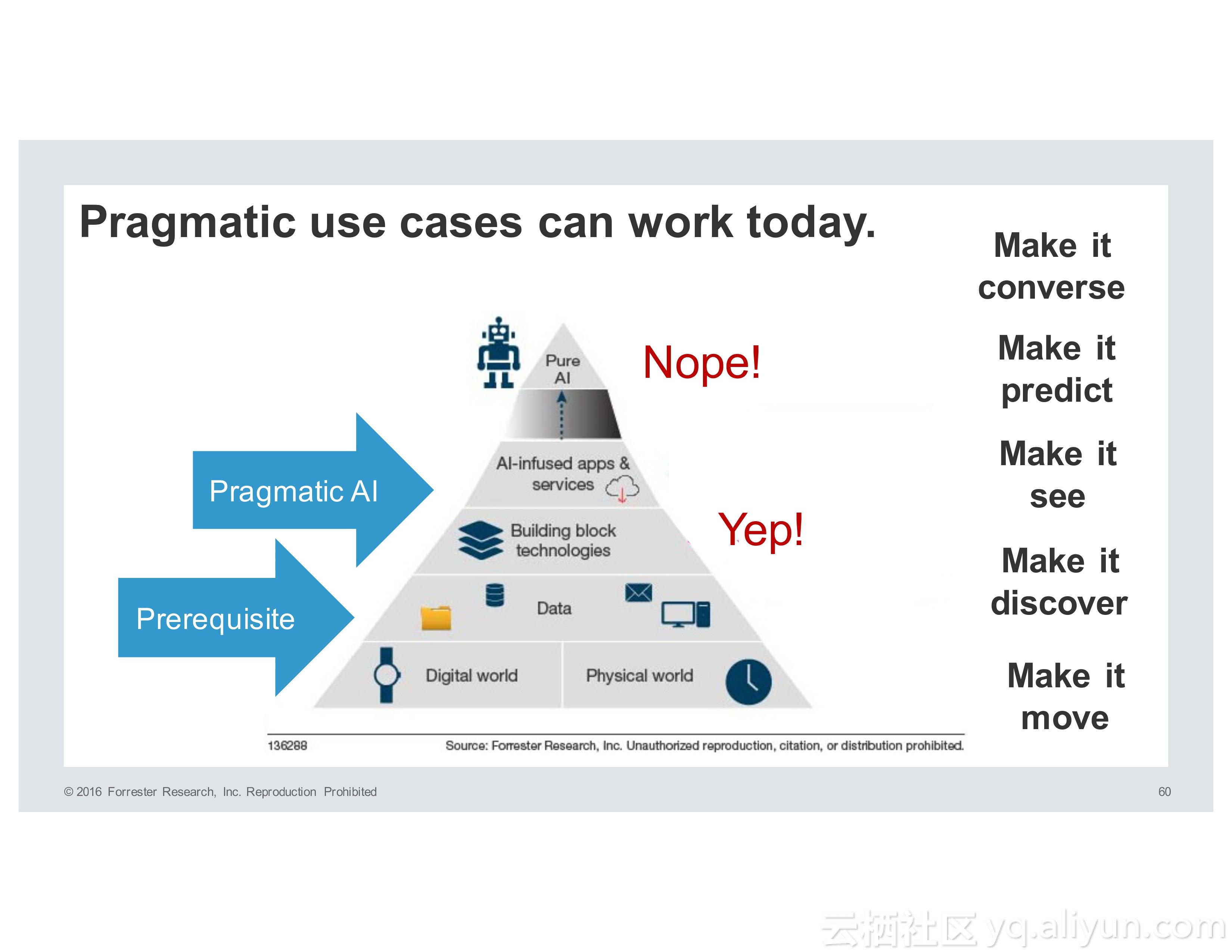
而人工智能的发展经历了很多个阶段,所谓PureAI,也就是纯人工智能希望能够模仿人类的智能,而企业则希望使用PragmaticAI,也就是实用性人工智能为技术添砖加瓦,帮助产品或者应用更具有智能性。
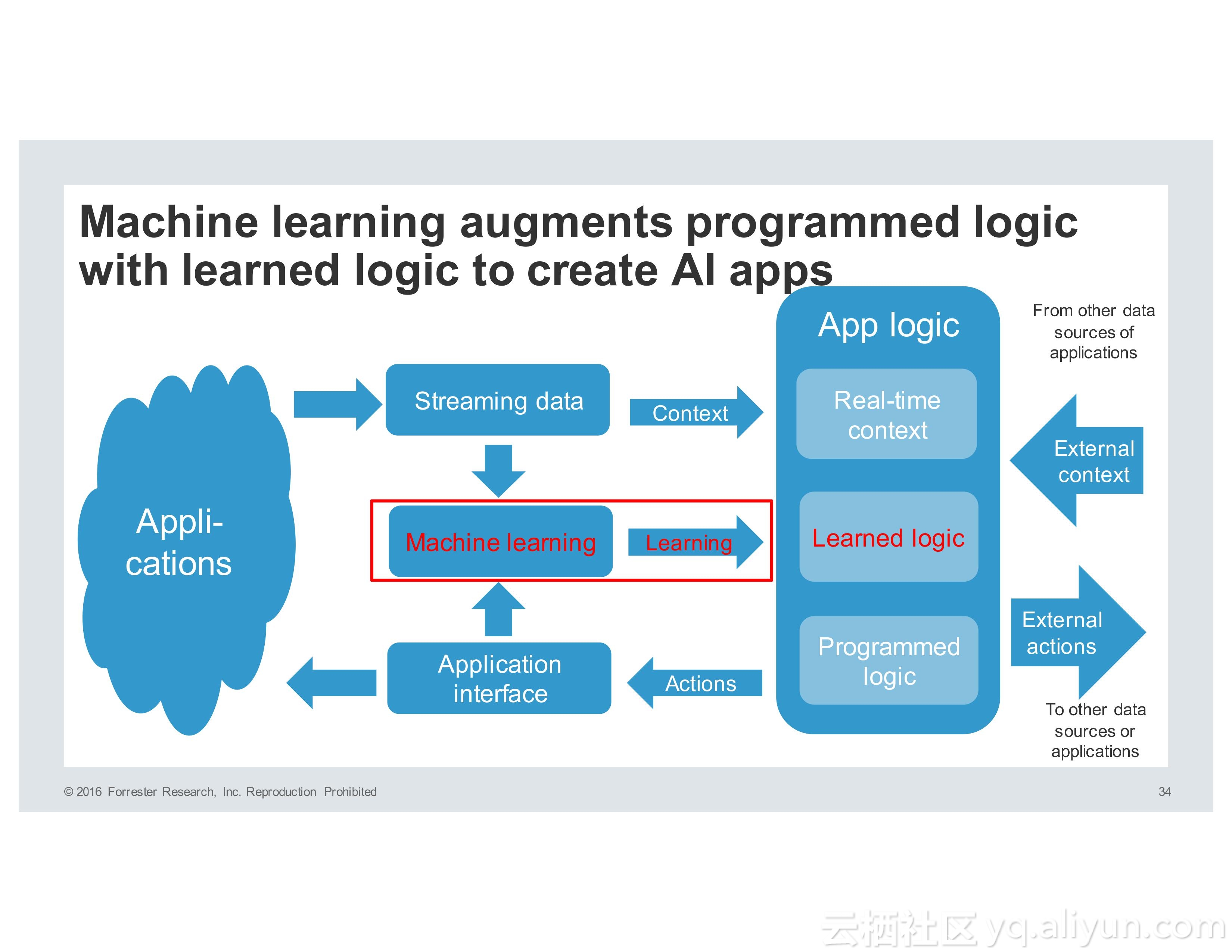
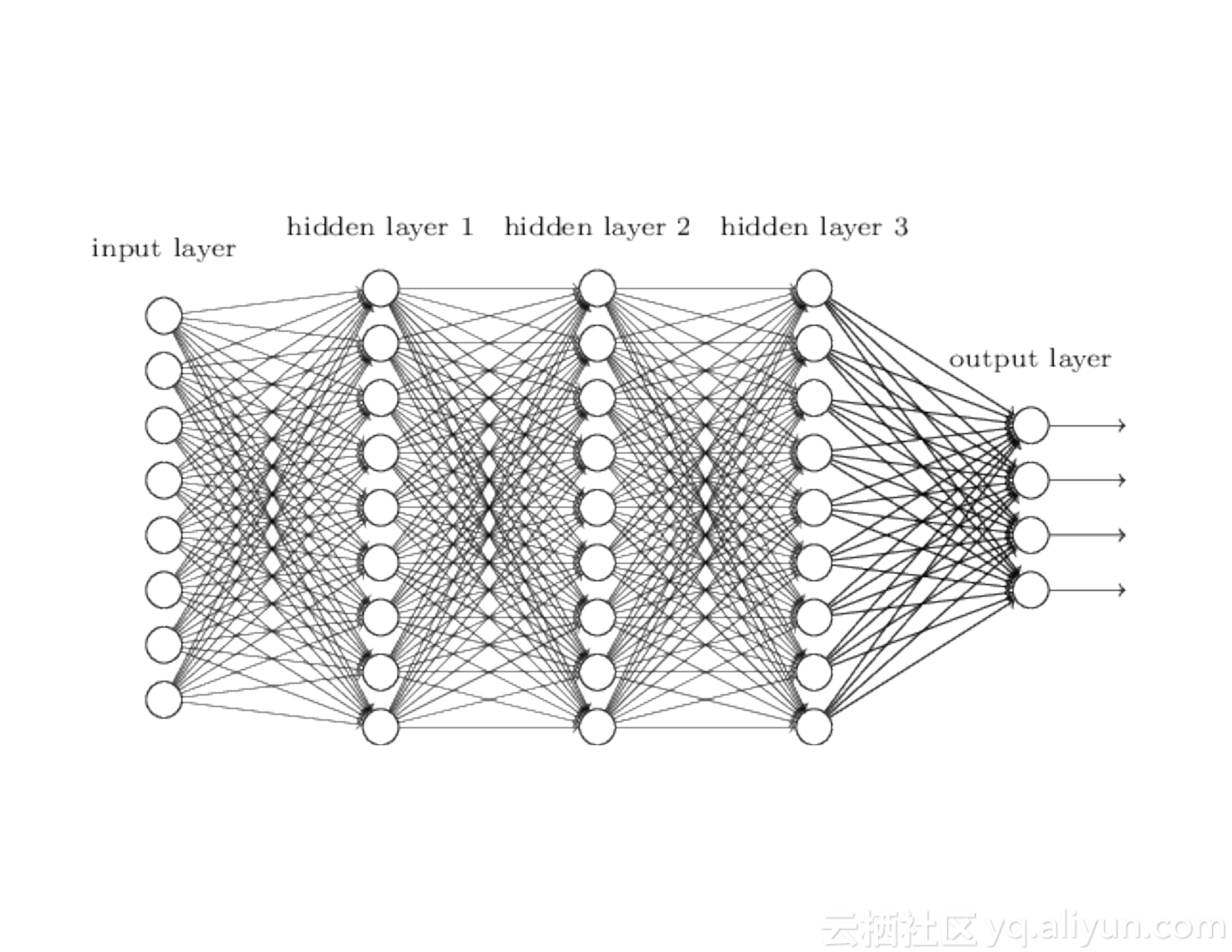
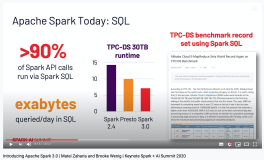
而机器学习则被数据分析专家用于预测概率性的模型,深度学习则需要构建更加精确的模型。而Spark正是为了速度、大规模、分布式机器学习以及深度学习而设计的,并且目前已经拥有了非常活跃的生态系统。