通过最佳实践帮助您实现上述案例效果
Step1:数据准备
接下来,我们需要准备好一张表及数据集;
- Hive表名:hive_dplus_good_sale;
- 是否分区表:分区表,分区名为pt;
- hdfs文件数据列分隔符:英文逗号;
- 表数据量:100条。
源hive表建表语句
CREATE TABLE IF NOT EXISTS hive_dplus_good_sale(
create_time timestamp,
good_cate STRING,
brand STRING,
buyer_id STRING,
trans_num BIGINT,
trans_amount DOUBLE,
click_cnt BIGINT,
addcart_cnt BIGINT,
collect_cnt BIGINT
)
PARTITIONED BY (pt string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' lines terminated by '\n' ;数据预览如下:


Hdfs&datax类型对照表
| 在Hive表中的数据类型 | DataX 内部类型 |
| TINYINT,SMALLINT,INT,BIGINT | Long |
| FLOAT,DOUBLE,DECIMAL | Double |
| String,CHAR,VARCHAR | String |
| BOOLEAN | Boolean |
| Date,TIMESTAMP | Date |
| Binary | Binary |
Step2:MaxCompute目标表准备
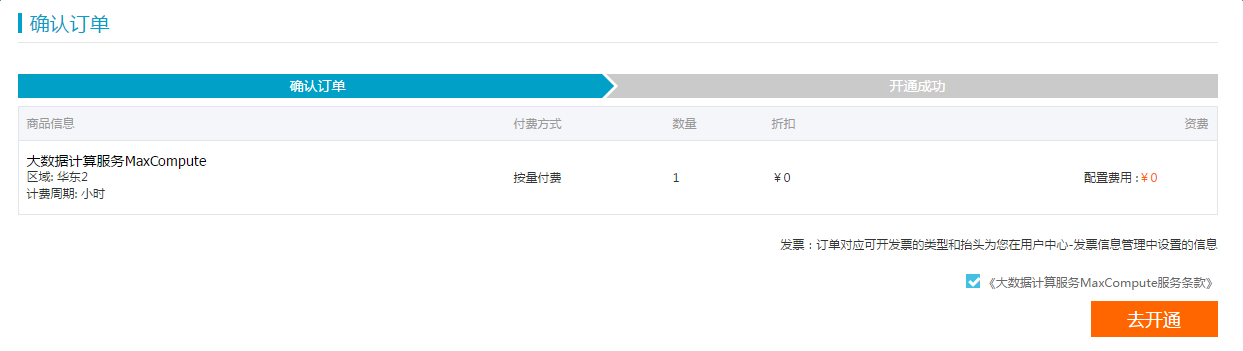
1.1 开通MaxCompute
阿里云实名认证账号访问https://www.aliyun.com/product/odps ,开通MaxCompute,选择按量付费进行购买。

1.2 数加上创建MaxCompute project
操作步骤:
步骤1:进入数加管理控制台,前面开通MaxCompute成功页面,点击管理控制台,或者导航产品->大数据(数加)->MaxCompoute(https://www.aliyun.com/product/odps) 点击管理控制台。

步骤2:创建项目。付费模式选择I/O后付费,输入项目名称:

步骤3:创建MaxCompute表。进入大数据开发套件的数据开发页面:

新建表

对应建表语句:
CREATE TABLE IF NOT EXISTS mc_dplus_good_sale (
create_time DATETIME COMMENT '时间',
good_cate STRING COMMENT '商品种类',
brand STRING COMMENT '品牌',
buyer_id STRING COMMENT '用户id',
trans_num BIGINT COMMENT '交易量',
trans_amount DOUBLE COMMENT '金额',
click_cnt BIGINT COMMENT '点击次数',
addcart_cnt BIGINT COMMENT '加入购物车次数',
collect_cnt BIGINT COMMENT '加入收藏夹次数'
)
PARTITIONED BY (pt STRING);Step3:通过Datax进行数据迁移
MaxCompute中的结构化数据是以表的形式存在,我们可以通过工具或者API将数据直接写入表中。
网络传输
- datax: https://github.com/alibaba/DataX 本case我们选用datax方式进行数据迁移。
datax是阿里开源的一款工具,可以适配常见的数据源,包括关系数据库、文本文件等,这是一款单机的软件,适用于中小数据量的传输,传输效率按照单机网卡 50%(约50MB/s)计算,一天可以传输的数据量为
50MB/s 60 60 * 24 / 1024/1024 ≈ 4T
具体的传输效率会取决于网络环境(机房出口带宽、本地网络),机器性能,文件格式与数量等多个因素。
使用datax传输数据到ODPS的部署结构如下,在ECS机器或一台物理机器上部署好dataX,此机器要能够同时连通数据源与MaxCompute(原ODPS)服务。

- sqoop: https://github.com/aliyun/aliyun-odps-sqoop
sqoop可以并行起多个任务导出数据,相比datax可以取得更好的性能。
磁盘导入
当数据量比较大(PB级别以上)时,可以考虑通过磁盘将数据导入ODPS,需要磁盘导入请联系相应的大数据业务架构师。
API: Tunnel SDK
当数据源较特殊,无法使用以上现有的工具的时候,可以用SDK编写适配的工具,从数据源读出并写入ODPS中,Tunnel是数据上传的底层接口,可以同时接受大量客户端并行的写入。
https://help.aliyun.com/document_detail/27837.html?spm=5176.doc34614.6.144.RyeirI
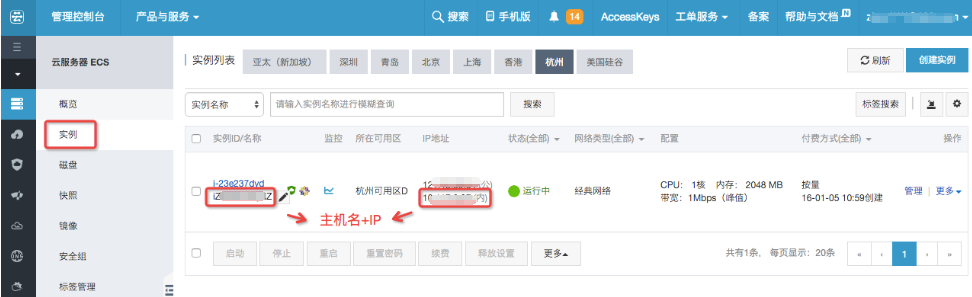
ECS机器部署
前提准备:获取ECS的主机名和IP:
操作步骤:
步骤1:增加调度资源。大数据开发套件->项目管理->调度资源管理->增加调度资源,输入名称和标识hive2mc:
步骤2:添加配置ECS服务器: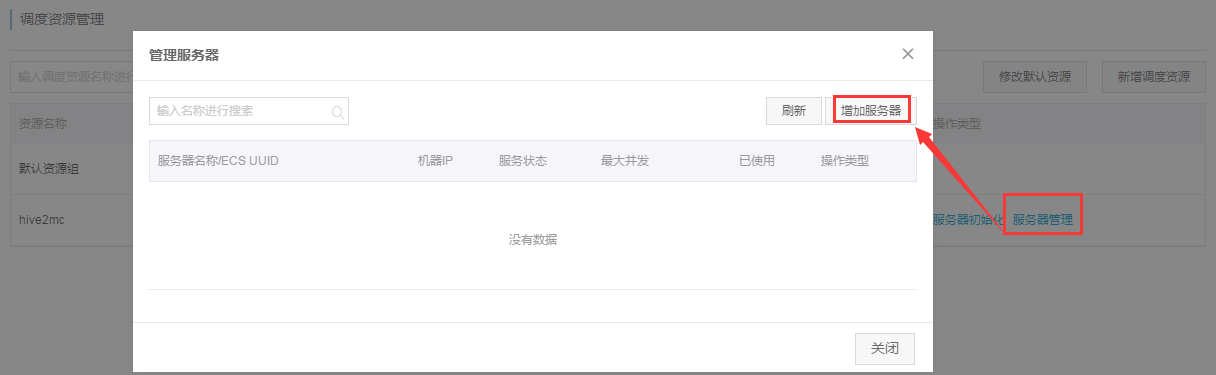
输入前提准备中获取到的ECS服务器名称和IP,点击添加。
步骤3:初始化ECS服务器: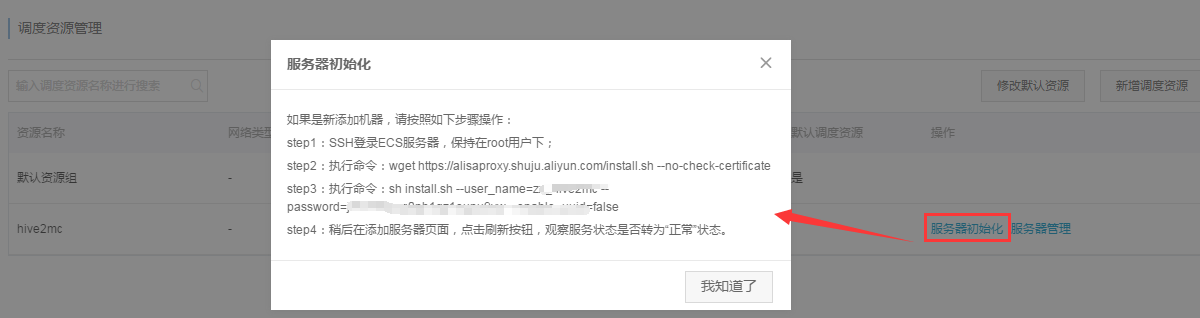
按照弹框提示,登录ECS服务器(登录外网IP)在root用户下执行两个命令,即部署相关datax等服务。
命令执行成功后,回到“管理服务器”页面,点击刷新按钮可以看到服务器状态为“正常”状态:
此时该项目的调度资源组就有两个:默认资源组、刚添加成功的资源组,后面执行datax任务即使用刚添加成功的资源组进行调度运行。
任务配置
前提准备:查看hive表对应数据文件地址
操作步骤:
步骤1:前面ECS机器部署介绍的资源组配置好后,导航上点击进入“数据开发”页面进行任务开发。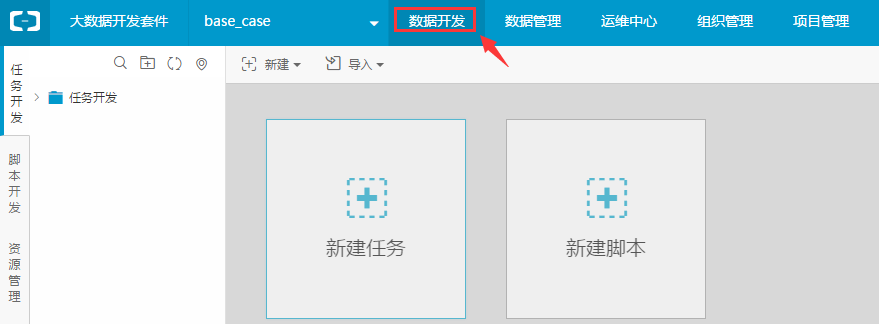
步骤2:创建工作流,命名为hive2MC_demo,选择一次性调度(本case是做一次性迁移,若需要每日生产调度则选择周期调度):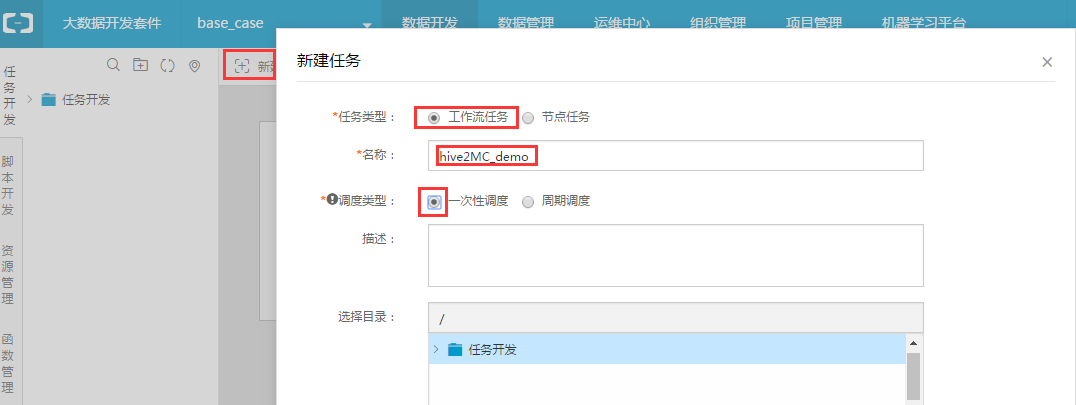
步骤3:在工作流中创建shell节点:
步骤4:代码配置。Shell节点创建后,双击节点图,进入代码编辑器进行Shell代码编辑。
代码中进行datax配置,reader为hdfsreader,writer为odpswriter,具体代码如下,只需要修改reader和writer的配置:
shell_datax_home='/home/admin/shell_datax'
mkdir -p ${shell_datax_home}
shell_datax_config=${shell_datax_home}/${ALISA_TASK_ID}
echo '''
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/user/hive/warehouse/hive_table_name/*",
"defaultFS": "hdfs://xxx:port",
"column": [
{
"index": 0,
"type": "date"
},
{
"index": 1,
"type": "STRING"
},
{
"index":2,
"type": "STRING"
},
{
"index":3,
"type": "STRING"
},
{
"index": 4,
"type": "long"
}
,
{
"index": 5,
"type": "DOUBLE"
},
{
"index": 6,
"type": "long"
},
{
"index": 7,
"type": "long"
},
{
"index": 8,
"type": "long"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": ","
}
},
"writer": {
"name": "odpswriter",
"parameter": {
"project": "base_case",
"table": "mc_dplus_good_sale",
"partition":"pt=20160618",
"column": ["create_time","good_cate","brand","buyer_id","trans_num","trans_amount","click_cnt","addcart_cnt","collect_cnt"],
"accessId": "xxxxxxxxxx",
"accessKey": "xxxxxxxxxxx",
"truncate": true,
"odpsServer": "http://service.odps.aliyun.com/api",
"tunnelServer": "http://dt.odps.aliyun.com",
"accountType": "aliyun"
}
}
}
]
}
}''' > ${shell_datax_config}
echo "`date '+%Y-%m-%d %T'` shell datax config: ${shell_datax_config}"
/home/admin/datax3/bin/datax.py ${shell_datax_config}
shell_datax_run_result=$?
rm ${shell_datax_config}
if [ ${shell_datax_run_result} -ne 0 ]
then
echo "`date '+%Y-%m-%d %T'` shell datax ended failed :("
exit -1
fi
echo "`date '+%Y-%m-%d %T'` shell datax ended success~"hdfsreader
- path:hive表hdfs文件路径(注意格式);
- defaultFS: hdfs文件系统namenode节点地址(注意格式);
- index:hdfs数据文本第几列,以0开始。
- Type:hdfs数据对应datax的类型,请看hdsf&datax类型对照表;
- fileType: hdfs数据文件类型;
- encoding: hdfs数据文件的编码;
- fieldDelimiter: hdfs数据文件字段分隔符。
Odpswriter - project: MaxCompute目标表所属项目名称;
- table: MaxCompute目标表名称;
- partition:表分区值,此case直接用固定值;
- column:目标表列,注意顺序与reader的列顺序一一对应;
- accessId:写入目标表所用的云账号access id;
- accessKey:写入目标表所用的云长access key;
- truncate:写入前是否清空当前表/分区数据,需要清空就true,需要保留就false。
步骤5:保存shell节点,提交工作流。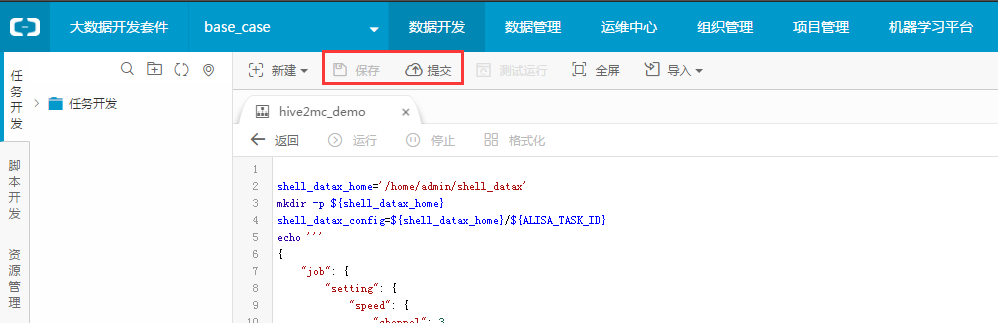
步骤6:指派执行资源组。这里将给shell任务指定执行的机器即我们前面部署的ECS。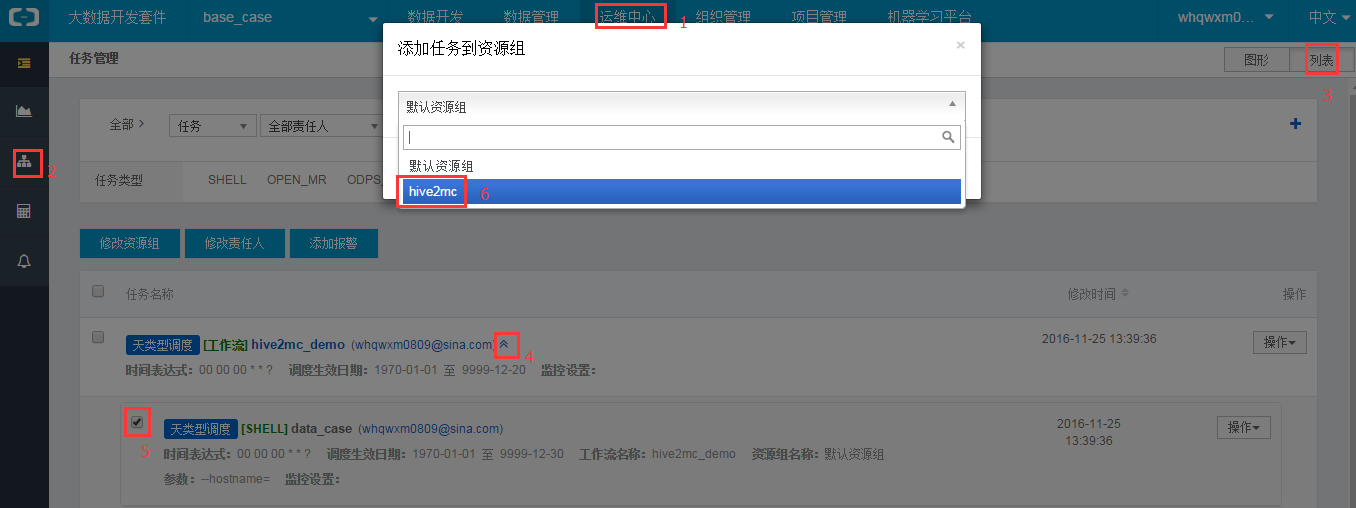
hive2mc资源组即为《ECS机器部署》章节中配置的资源组。资源组配置好后,后面就可以执行shell任务进行数据迁移。
Step4:执行数据迁移任务
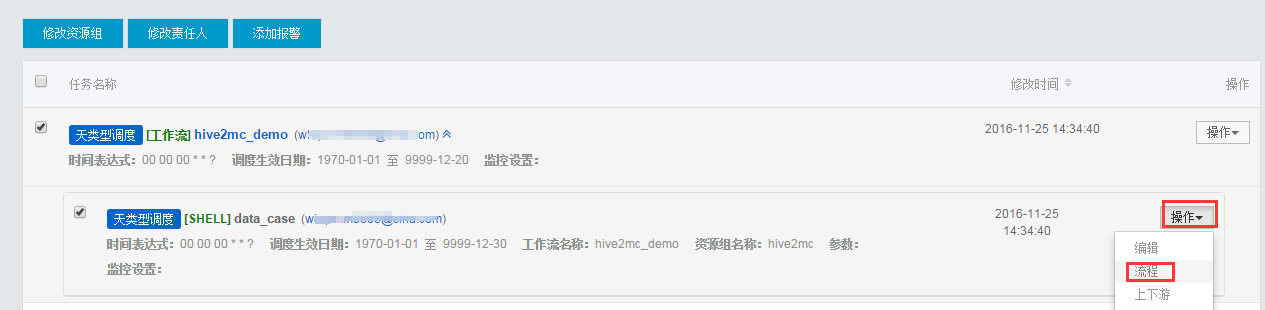
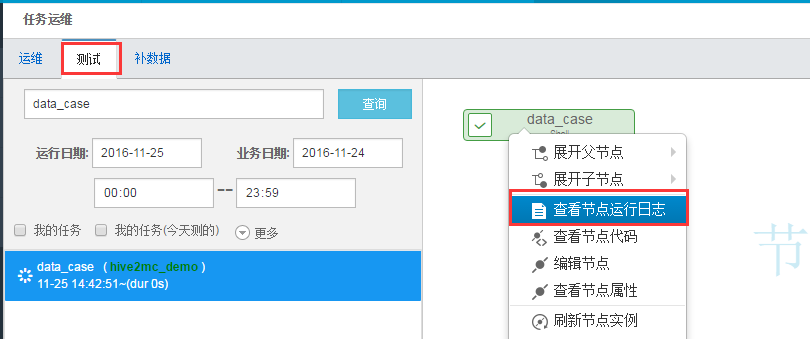
接前面的步骤,点击shell节点的操作->流程:
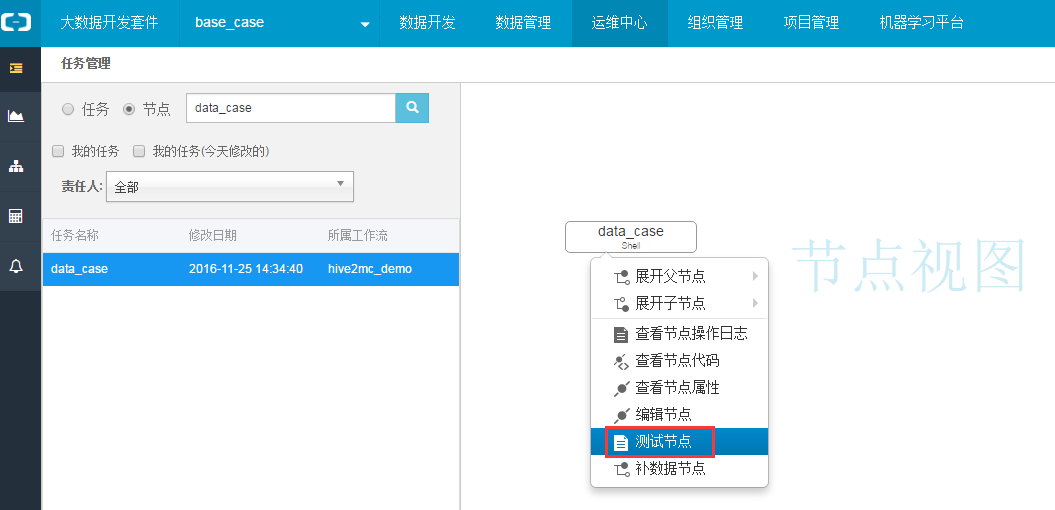
进入该节点的任务管理视图界面,右击节点图,选择测试节点,即可把该阶段调度执行起来:
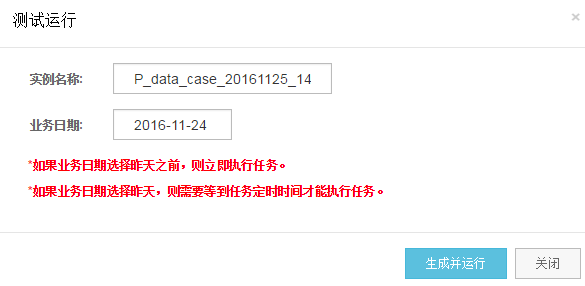
示例名称和业务日期采用默认,直接点击生成并运行,然后点击“前往查看运行结果”。
进入测试实例视图,可以看到节点示例执行状态,如下图变成绿色打勾的符号说明执行成功,右击节点图选择 查看运行日志 查看具体执行日志。
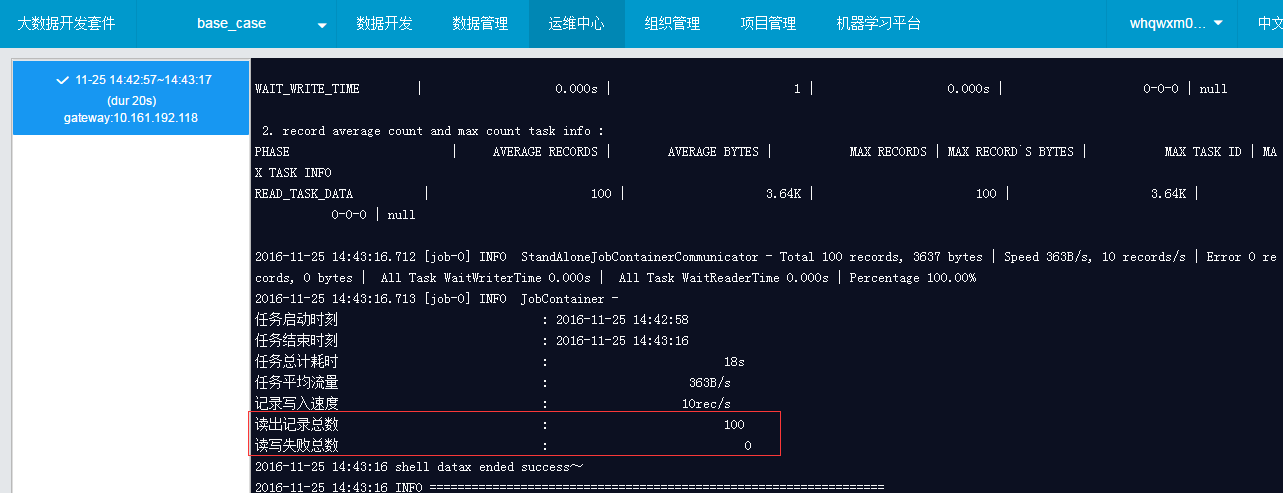
查看日志中读出100条,写入失败0条,说明成功写入100条数据;
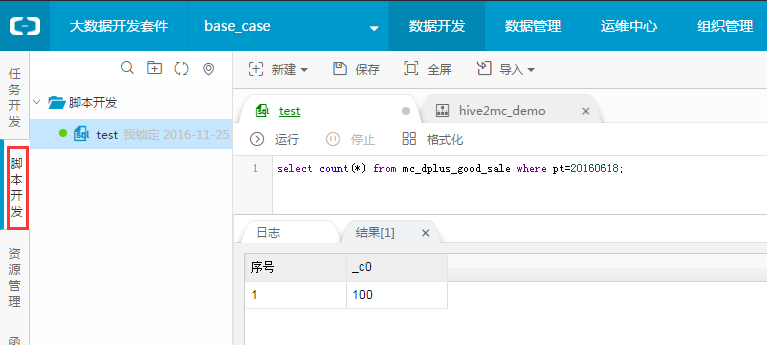
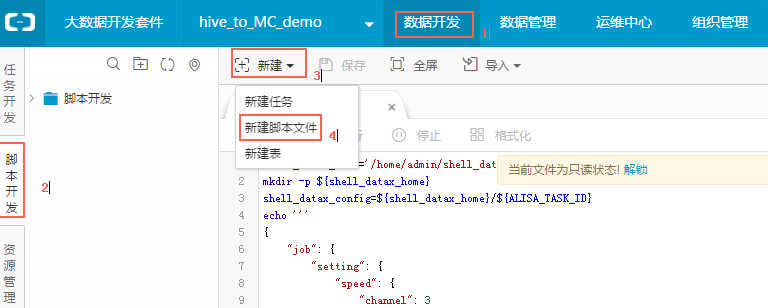
Step5:校验MaxCompute表数据
可以到数据开发中创建一个脚本文件
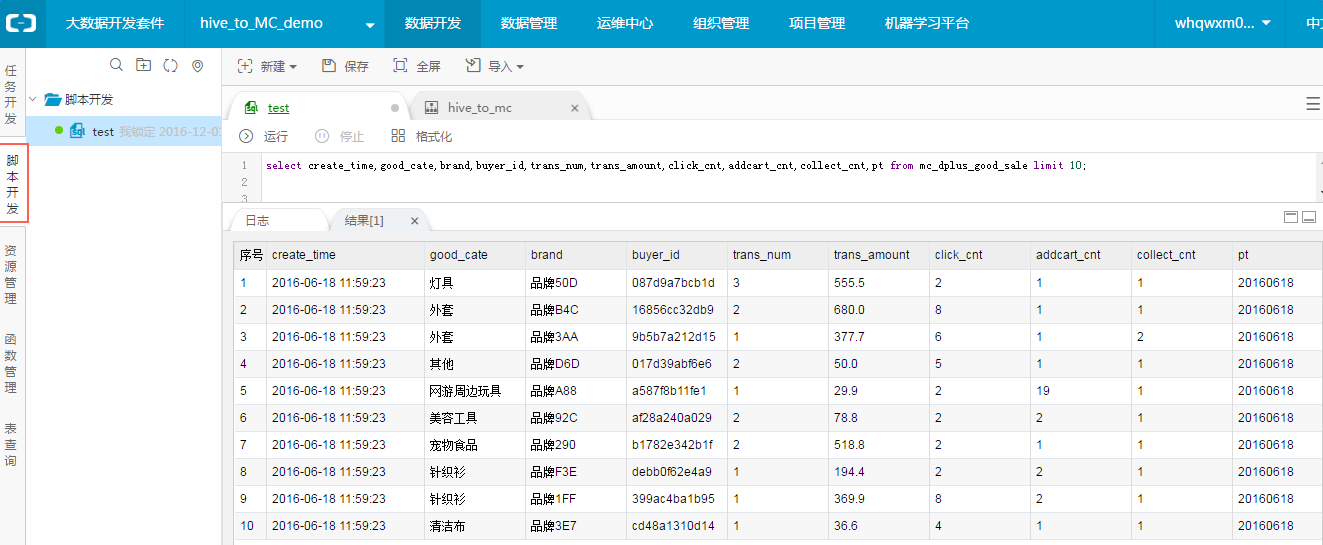
运行代码:
select create_time,good_cate,brand,buyer_id,trans_num,trans_amount,click_cnt,addcart_cnt,collect_cnt from mc_dplus_good_sale limit 10; 查看数据是否正常。
也可以执行
select count(*) from mc_dplus_good_sale where pt=20160618;
查看是否导入的数据是否是100条。