Docker资源限制与Cgroups
一、Linux control groups
简介
- Resource limitation: 限制资源使用,比如内存使用上限以及文件系统的缓存限制。
- Prioritization: 优先级控制,比如:CPU利用和磁盘IO吞吐。
- Accounting: 一些审计或一些统计,主要目的是为了计费。
- Control: 挂起进程,恢复执行进程。
CGroup的术语
-
blkio — 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
-
cpu — 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
-
cpuacct — 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
-
cpuset — 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
-
devices — 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
-
freezer — 这个子系统挂起或者恢复 cgroup 中的任务。
-
memory — 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成内存资源使用报告。
-
net_cls — 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
-
net_prio — 这个子系统用来设计网络流量的优先级
-
hugetlb — 这个子系统主要针对于HugeTLB系统进行限制,这是一个大页文件系统。
操作接口
在linux系统中一皆文件,当然对CGroup的接口操作也是通过文件来实现的,我们可以通过mount命令查看其挂载目录:
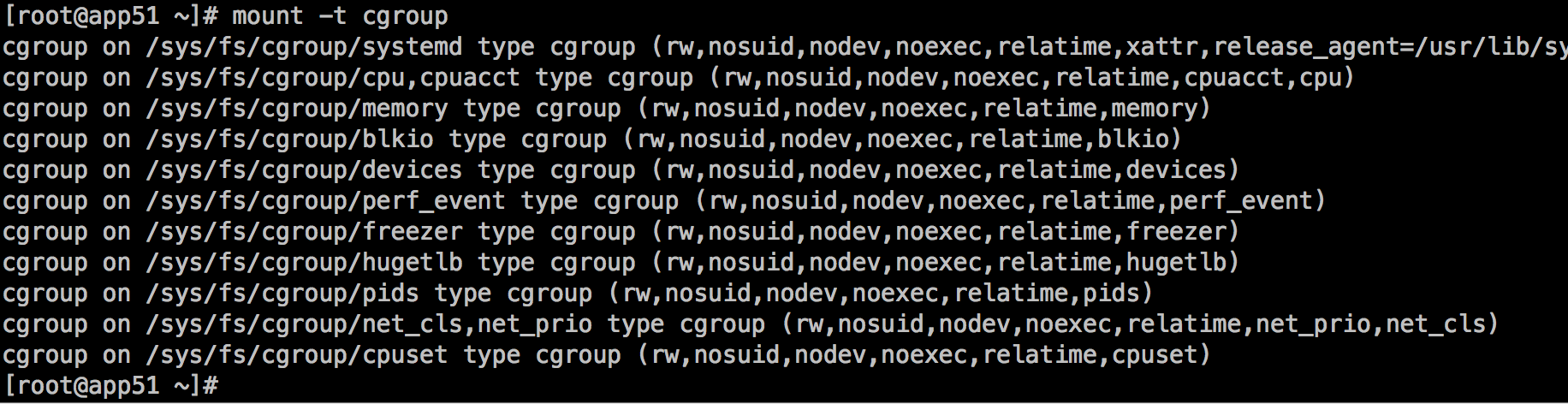
以上目录都可以是限制的对象,也就是对应的术语中的各个子系统。例如查看这里的CPU限制目录:
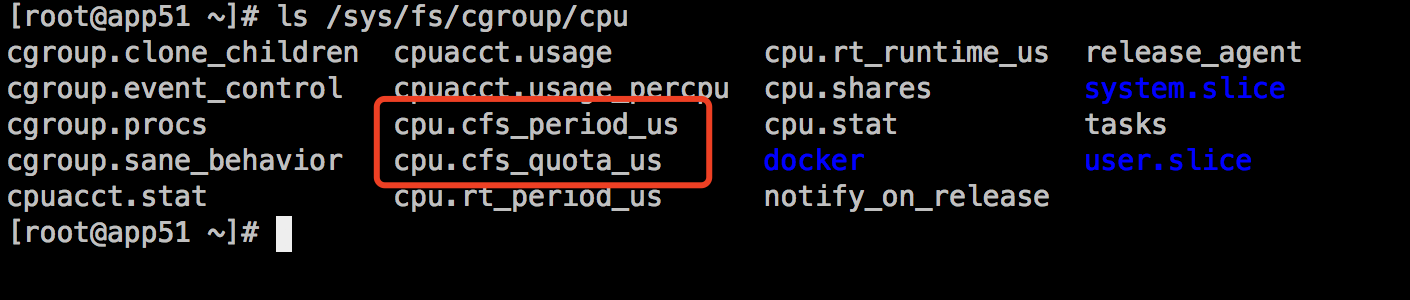
如果你熟悉CPU管理的话,cfs_period 和 cfs_quota两个可能不会陌生,这两个参数需要组合使用,可以用来限制进程在长度为cfs_period 的一段时间内,只能被分配到总量为cfs_quota 的 CPU 时间。以下示例将会演示如何限制。
限制CPU
限制CPU的使用需要在子系统目录(/sys/fs/cgroup/cpu)下创建目录,这里创建一个cpu_limit_demo目录:

可以看到当我们在CPU子系统下创建目录时候,其对应的限制配置文件会自动进行创建,现在在后台写个死循环跑满CPU:

此时使用top命令查看pid为10069的进程CPU使用状况:
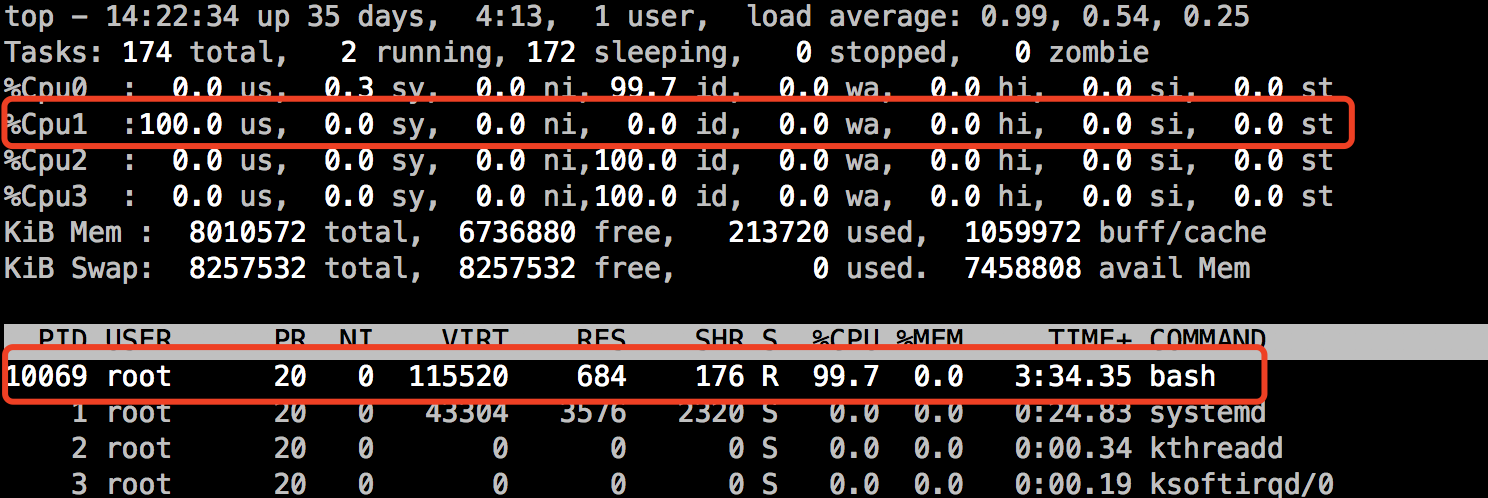

cpu.cfs_quota_us值为-1代表没有任何限制,cpu.cfs_period_us 则是默认的 100 ms,即100000us,下面将向cpu_limit_demo控制组的cpu.cfs_quota_us文件写入50ms即50000us,这表示在100ms周期内,cpu最多使用%50,同时将该进程的pid号为10069写入对应的tasks文件,表示对那个进程限制:

于是pid为10069的进程cpu就被限制成了%Cpu :50.0 us,此时利用top在此查看cpu使用情况(top后按1可看到每个逻辑cpu具体使用):
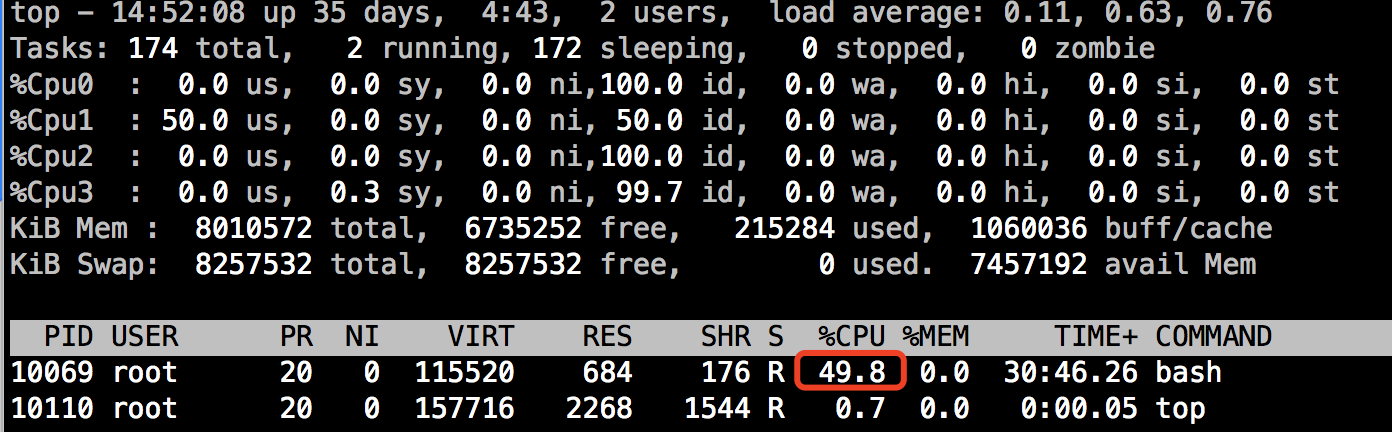
以上可以看到此时pid10069的进程使用率已经变成了50%了,说明限制生效了。同样的道理,在/sys/fs/cgroup下的子系统都可以限制不通的资源使用如Block IO、Memory等。
限制内存
首先在 /sys/fs/cgroup/memory 下新建一个名为 limit_memory_demo 的 cgroup:
mkdir /sys/fs/cgroup/memory/limit_memory_demo
限制该 cgroup 的内存使用量为 500 MB:
# 物理内存500M(下面单位Byte) MB并且不使用swap echo 524288000 > /sys/fs/cgroup/memory/limit_memory/memory.limit_in_bytes echo 0 > /sys/fs/cgroup/memory/limit_memory/memory.swappiness
最后将需要限制的进程号的pid写入task文件就可以了:
echo [pid] > /sys/fs/cgroup/memory/limit_memory_demo/tasks
限制磁盘IO
使用dd写到null设备:
[root@app51 blkio]# dd if=/dev/sda of=/dev/null bs=1M
使用iotop(安装使用yum install -y iotop)查看io速率,此时读的速率为2.17G/s

创建一个blkio(块设备IO)的cgroup,并查看设备号,然后将pid和限制的设备以及速度写入文件:


mkdir /sys/fs/cgroup/blkio/ echo '8:0 1048576' > /sys/fs/cgroup/blkio/limit_io/blkio.throttle.read_bps_device echo [pid] > /sys/fs/cgroup/blkio/limit_io/tasks
二、 Docker中资源限制原理
在了解了Cgroup对资源的限制方法,再来理解Docker中的资源限制其实就变的容易了。默认情况下,Docker会在需要限制的子系统下创建一个目录为docker的控制组如下:

当容器运行后,会在这些目录生成以容器ID为目录的子目录用于限制的容器资源。例如,以cpu为例,docker run启动参数中--cpu-quota 参数可以指定默认时间内使用的cpu:
[root@app51 docker]# docker run -d --name nginx-c1 --cpu-quota 50000 nginx:latest e9432a513e4bed0a744a29a8eaba2b27d9e40efabfe479d19d32f9558888ed29 [root@app51 docker]#
此时我们查看cpu对应的容器资源限制:
[root@app51 docker]# cd /sys/fs/cgroup/cpu/docker/ [root@app51 docker]# cat e9432a513e4bed0a744a29a8eaba2b27d9e40efabfe479d19d32f9558888ed29/cpu.cfs_quota_us 50000 [root@app51 docker]# cat e9432a513e4bed0a744a29a8eaba2b27d9e40efabfe479d19d32f9558888ed29/tasks 10561 10598
从上面结果我们能看出,docker run的启动限制参数值,被注入到了Cgroups的cpu控制组的对应配置文件中了。同时还有看到有两个进程同时被限制了,这是因为我们启动的nginx,nginx的主进程会启动多个子进程,使用ps -ef可以查看:
[root@app51 docker]# ps -ef |grep 10561 root 10561 10544 0 16:32 ? 00:00:00 nginx: master process nginx -g daemon off; 101 10598 10561 0 16:32 ? 00:00:00 nginx: worker process root 10614 10179 0 16:38 pts/2 00:00:00 grep --color=auto 10561 [root@app51 docker]#
不难看到,其中主进程为10561(nginx master),子进程为10598(nginx worker)。以上则是docker的资源限制原理。Docker对资源限制主要是CPU和内存,其中还有很多参数可以使用,以下将会介绍docker中CPU和MEMERY限制参数。
三、CPU限制参数
默认情况下,容器的资源是不受限制的,宿主机提供多少资源,容器就可以使用多少资源,如果不对容器做资源限制,很有可能一个或几个容器把宿主机的资源耗尽,而导致应用或者服务不可用。所以对容器资源的限制显得非常重要,而docker主要提供两种类别的资源限制:CPU和内存,通过docker run 时指定参数实现。cpu限制资源限制有多种维度,以下将详细介绍。
限制cpu配额
docker run -d --cpu-period=100000 --cpu-quota=250000 --name test-c1 nginx:latest
限制cpu可用数量
[root@app51 ~]# docker run -d --cpus=2 --name test-c2 nginx:latest 5347269d0974e37af843b303124d8799c6f4336a14f61334d21ce9356b1535bc
使用固定的cpu
通过--cpuset-cpus参数指定,表示指定容器运行在某个或某些个固定的cpu上,多个cpu使用逗号隔开。例如四个cpu,0代表第一个cpu,--cpuset-cpus=1,3代表该容器只能运行在第二个或第四个cpu上。查看cpu可以通过cat /proc/cpuinfo查看。
示例:
[root@app51 ~]# docker run -d --cpuset-cpus=1,3 --name test-c3 nginx:latest
276056fce04982c2de7969ca309560ce60b0ebf960cf7197808616d65aa112d4
设置CPU比例(权重)
[root@app51 ~]# docker run -d --cpu-shares=2048 --name test-c4 nginx:latest 578506d61324b38d7a01bf1d2ec87cb5d1ab50276ef6f7b28858f2d2e78b2860 [root@app51 ~]# docker run -d --cpu-shares=4096 --name test-c5 nginx:latest d56a90bf080b70d11d112468348874e48fe4a78d09d98813a0377b34fa382924
四、 MEMORY限制参数
内存是一种不可压缩资源,一旦某个进程或者容器中应用内存不足就会引起OOM异常(Out Of Memory Exception),这将导致应用不可用,并且在Linux主机上,如果内核检测到没有足够的内存来执行重要的系统功能,系统会按照一定优先级杀死进程来释放系统内存。docker对内存的限制分为swap限制和物理内存限制,单位可以使用b,k, m,g。
限制最大物理内存使用
通过-m或者—memory指定,是硬限制,如果设置此选项,则允许设置的最小值为4m,该参数是最常用参数。
示例:
[root@app51 ~]# docker run -d --memory=512m --name mem-c1 nginx:latest 67b0cb645c401bc6df3235d27d629185870716351396c71dfa3877abbbd377c8
限制swap使用
- --memory-swap 设置为正整数,那么这两个--memory和 --memory-swap 必须设置。--memory-swap 表示可以使用的memory 和 swap,并且--memory控制非交换内存(物理内存)使用的量。列如--memory=300m 和--memory-swap=1g,容器可以使用300m的内存和700m(1g - 300m)swap。
- --memory-swap 设置为0,则忽略该设置,并将该值视为未设置。
- --memory-swap 设置为与值相同的值--memory,并且--memory设置为正整数,则容器不能使用swap,可以通过此方法限制容器不使用swap。
- --memory-swap 未设置并--memory 设置,则容器可以使用两倍于--memory设置的swap,主机容器需要配置有swap。例如,如果设置--memory="300m" 和--memory-swap 未设置,容器可以使用300m的内存和600m的swap。
- --memory-swap 设置为-1,则允许容器使用无限制swap,最多可达宿主机系统上可用的数量。
示例:
[root@app51 ~]# docker run -d --memory=512m --memory-swap=512m --name mem-c2 nginx:latest 6b52c015a53be2c3e0e509eea918125a760c1c14df4cc977f05b5b31b83161d5
其他
- --oom-kill-disable :默认情况下,如果发生内存不足(OOM)错误,内核会终止容器中的进程,如要更改此行为,使用该--oom-kill-disable选项,但是该选项有个前提就是-m选项必须设置。
- --memory-swappiness:默认情况下,容器的内核可以交换出一定比例的匿名页。--memory-swappiness就是用来设置这个比例的。--memory-swappiness可以设置为从 0 到 100。0 表示关闭匿名页面交换。100 表示所有的匿名页都可以交换。默认情况下,如果不适用--memory-swappiness,则该值从父进程继承而来。
- --memory-reservation:Memory reservation 是一种软性限制,用于限制物理内存的最大用值,它只是确保容器不会长时间占用超过--memory-reservation限制的内存大小。给--memory-reservation设置一个比-m小的值后,虽然容器最多可以使用-m使用的内存大小,但在宿主机内存资源紧张时,在系统的下次内存回收时,系统会回收容器的部分内存页,强迫容器的内存占用回到--memory-reservation设置的值大小。

