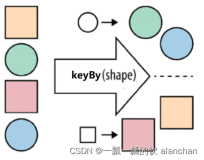
Flink1.7.2 DataStream Operator 示例
源码
- https://github.com/opensourceteams/flink-maven-scala
- https://github.com/opensourceteams/flink-maven-scala/tree/master/src/main/scala/com/opensourceteams/module/bigdata/flink/example/datastream/operator
map
- 处理所有元素
- 输入数据
模板- 程序
模板- 输出数据
模板map
- 处理所有元素
-
输入数据
你好 发送数据 -
程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.map import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment import org.apache.flink.streaming.api.scala._ /** * nc -lk 1234 输入数据 */ object Run { def main(args: Array[String]): Unit = { val port = 1234 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val dataStream = env.socketTextStream("localhost", port, '\n') val dataStreamMap = dataStream.map(x => x + " 增加的数据") dataStreamMap.print() if(args == null || args.size ==0){ env.execute("默认作业") }else{ env.execute(args(0)) } println("结束") } } -
输出数据
1> 你好 增加的数据 2> 发送数据 增加的数据
flatMap
- 处理所有元素,并且把每行中的子集合,汇总成一个大集合
-
输入数据
a b c e f g -
程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.flatmap import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} /** * nc -lk 1234 输入数据 */ object Run { def main(args: Array[String]): Unit = { val port = 1234 // get the execution environment val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val dataStream = env.socketTextStream("localhost", port, '\n') val dataStream2 = dataStream.flatMap(x => x.split(" ")) dataStream2.print() if(args == null || args.size ==0){ env.execute("默认作业") }else{ env.execute(args(0)) } println("结束") } } -
输出数据
a b c e f g
filter
- 过滤数据
-
输入数据
a b c a c b b d d -
程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.filter import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment} /** * nc -lk 1234 输入数据 */ object Run { def main(args: Array[String]): Unit = { val port = 1234 // get the execution environment val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val dataStream = env.socketTextStream("localhost", port, '\n') val dataStreamMap = dataStream.filter( x => (x.contains("a"))) dataStreamMap.print() if(args == null || args.size ==0){ env.execute("默认作业") }else{ env.execute(args(0)) } println("结束") } } -
输出数据
3> a b c 4> a c
keyBy
- 指定某列为key,一般按key分组时用
-
输入数据
c a b a -
程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.sum import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.time.Time /** * nc -lk 1234 输入数据 */ object Run { def main(args: Array[String]): Unit = { val port = 1234 // get the execution environment val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val dataStream = env.socketTextStream("localhost", port, '\n') val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1)) .keyBy(0) //dataStream.keyBy("someKey") // Key by field "someKey" //dataStream.keyBy(0) // Key by the first element of a Tuple .timeWindow(Time.seconds(2))//每2秒滚动窗口 .sum(1) dataStream2.print() if(args == null || args.size ==0){ env.execute("默认作业") }else{ env.execute(args(0)) } println("结束") } } - 输出数据,数据输出顺序多线程是不固定的,但也是一样的规则取
-
默认并行度
6> (a,2) 4> (c,1) 2> (b,1) -
并行度为1,就先去重,取第一个元素,再按从最后一个开始,即 c a b a 变为 c a b 然后变成 c b a
(c,1) (b,1) (a,2)
sum
- keyBy指定某列为key,一般按key分组时用,sum按key分组后求合
-
输入数据
c a b a -
程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.sum import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.time.Time /** * nc -lk 1234 输入数据 */ object Run { def main(args: Array[String]): Unit = { val port = 1234 // get the execution environment val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment val dataStream = env.socketTextStream("localhost", port, '\n') val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1)) .keyBy(0) //dataStream.keyBy("someKey") // Key by field "someKey" //dataStream.keyBy(0) // Key by the first element of a Tuple .timeWindow(Time.seconds(2))//每2秒滚动窗口 .sum(1) dataStream2.print() if(args == null || args.size ==0){ env.execute("默认作业") }else{ env.execute(args(0)) } println("结束") } } - 输出数据,数据输出顺序多线程是不固定的,但也是一样的规则取
-
默认并行度
6> (a,2) 4> (c,1) 2> (b,1) -
并行度为1,就先去重,取第一个元素,再按从最后一个开始,即 c a b a 变为 c a b 然后变成 c b a
(c,1) (b,1) (a,2)
reduce
- keyBy指定某列为key,一般按key分组时用,对相同的key,元素之间进行的函数运算
-
输入数据
a b b c -
程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.reduce import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.time.Time /** * nc -lk 1234 输入数据 */ object Run { def main(args: Array[String]): Unit = { val port = 1234 // get the execution environment val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setParallelism(1) //设置并行度 val dataStream = env.socketTextStream("localhost", port, '\n') val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,2)) .keyBy(0) //dataStream.keyBy("someKey") // Key by field "someKey" //dataStream.keyBy(0) // Key by the first element of a Tuple .timeWindow(Time.seconds(2))//每2秒滚动窗口 .reduce((a,b) => (a._1,a._2 * b._2) ) dataStream2.print() println("=======================打印StreamPlanAsJSON=======================\n") println("JSON转图在线工具: https://flink.apache.org/visualizer") println(env.getStreamGraph.getStreamingPlanAsJSON) println("==================================================================\n") if(args == null || args.size ==0){ env.execute("默认作业") }else{ env.execute(args(0)) } println("结束") } } - 输出数据,数据输出顺序多线程是不固定的,但也是一样的规则取
- 默认并行度
6> (a,2)
4> (c,1)
2> (b,1)- 并行度为1,就先去重,取第一个元素,再按从最后一个开始,即 c a b a 变为 c a b 然后变成 c b a
(a,2)
(c,2)
(b,4)
fold
- 按key进行处理,第一个参数,是字符串,放在每次处理的最前面第二个是表达式,第二个表达式有两个参数,第一个参数,就是第一个参数的值,第二个参数,我每次循环key时,迭代的下一个元素
- 输入数据
a a b c c - 程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.fold
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.time.Time
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream("localhost", port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
//dataStream.keyBy("someKey") // Key by field "someKey"
//dataStream.keyBy(0) // Key by the first element of a Tuple
.timeWindow(Time.seconds(2))//每2秒滚动窗口
.fold("开始字符串")((str, i) => { str + "-" + i} )
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
开始字符串-(a,1)-(a,1)
开始字符串-(c,1)-(c,1)
开始字符串-(b,1)Aggregations (sum ,max,min)
sum
- 处理所有元素,相同key进行累加
- 输入数据
a a c b c- 程序
package com.opensourceteams.module.bigdata.flink.example.stream.operator.aggregations.sum
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.time.Time
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//env.setParallelism(1) //设置并行度,不设置就是默认最高并行度为的cpu ,我的四核8线程,就是最高并行度为8
val dataStream = env.socketTextStream("localhost", port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
//dataStream.keyBy("someKey") // Key by field "someKey"
//dataStream.keyBy(0) // Key by the first element of a Tuple
.timeWindow(Time.seconds(2))//每2秒滚动窗口
.sum(1)
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
4> (c,2)
2> (b,1)
6> (a,2)
min(和minBy一样,没发现区别)
- 处理所有元素,对相同key的元素,进行求最小的值
- 输入数据
b a b a a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.aggregations.sum
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.time.Time
//import org.apache.flink.streaming.api.scala._
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//env.setParallelism(1) //设置并行度,不设置就是默认最高并行度为的cpu ,我的四核8线程,就是最高并行度为8
val dataStream = env.socketTextStream("localhost", port, '\n')
var i = 0
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map( x => {
i = i + 1
(x,i)
})
.keyBy(0)
.timeWindow(Time.seconds(2))//每2秒滚动窗口
.min(1)
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
- 最终输出数据,顺序取决于线程的调用
2> (b,1)
6> (a,2)- 中间输出数据
6> (a,2)
2> (b,1)
6> (a,4)
2> (b,3)
6> (a,5)
2> (b,6)max(和maxBy一样)
- 处理所有元素,对相同key的元素,进行求最大的值
- 输入数据
b a b a a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.aggregations.sum
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.time.Time
//import org.apache.flink.streaming.api.scala._
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//env.setParallelism(1) //设置并行度,不设置就是默认最高并行度为的cpu ,我的四核8线程,就是最高并行度为8
val dataStream = env.socketTextStream("localhost", port, '\n')
var i = 0
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map( x => {
i = i + 1
(x,i)
})
.keyBy(0)
.timeWindow(Time.seconds(2))//每2秒滚动窗口
.max(1)
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
- 最终输出数据,顺序取决于线程的调用
2> (b,6)
6> (a,5)
- 中间输出数据
6> (a,2)
2> (b,1)
6> (a,4)
2> (b,3)
6> (a,5)
2> (b,6)
Window
window
- 定义window,并指定分配元素到window的方式
- 可以在已经分区的KeyedStream上定义Windows。 Windows根据某些特征(例如,在最后5秒内到达的数据)对每个密钥中的数据进行分组。 有关窗口的完整说明,请参见windows。
- 输入数据
b a b a a b
- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.window.window
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.{ TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream("localhost", port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
/**
* 定义window,并指定分配元素到window的方式
* 可以在已经分区的KeyedStream上定义Windows。 Windows根据某些特征(例如,在最后5秒内到达的数据)对每个密钥中的数据进行分组。 有关窗口的完整说明,请参见windows。
*/
.window(TumblingProcessingTimeWindows.of(Time.seconds(2)))
.sum(1)
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
(b,3)
(a,3)
WindowAll
- 配合process.ProcessAllWindowFunction函数,该函数的参数elements: Iterable[(String, Int)] 即为当前window的所有元素,可以进行处理,再发给下游sink
- 输入数据
b a b a a b
- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.window.windowAll
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream("localhost", port, '\n')
dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
.windowAll( TumblingProcessingTimeWindows.of(Time.seconds(2)))
.process(new ProcessAllWindowFunction[(String, Int),(String, Int),TimeWindow] {
override def process(context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//可以对当前window中的所有元素进行操作,处理后,再发送给Sink
for(element <- elements) out.collect(element)
}
})
.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
8> (a,1)
7> (b,1)
3> (a,1)
2> (a,1)
1> (b,1)
4> (b,1)
Window.apply
- 对一批window进行元素处理
- 输入数据
b a b a a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.window.window.apply
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.{TimeWindow, Window}
import org.apache.flink.util.Collector
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream("localhost", port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
/**
* 定义window,并指定分配元素到window的方式
* 可以在已经分区的KeyedStream上定义Windows。 Windows根据某些特征(例如,在最后5秒内到达的数据)对每个密钥中的数据进行分组。 有关窗口的完整说明,请参见windows。
*/
.window(TumblingProcessingTimeWindows.of(Time.seconds(2)))
/**
* * @tparam IN The type of the input value.
* * @tparam OUT The type of the output value.
* * @tparam KEY The type of the key.
*/
.apply(new WindowFunction[(String,Int),(String,Int),Tuple,TimeWindow] {
override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit ={
//对window的所有元素进行处理
for(element <- input) out.collect(element)
}
})
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
2> (a,1)
3> (a,1)
7> (b,1)
4> (b,1)
1> (b,1)
8> (a,1)
Window.reduce
- 处理所有元素,对window中相同key的元素进行,函数表达式计算
- 输入数据
b a b a a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.window.window.reduce
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream("localhost", port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
/**
* 定义window,并指定分配元素到window的方式
* 可以在已经分区的KeyedStream上定义Windows。 Windows根据某些特征(例如,在最后5秒内到达的数据)对每个密钥中的数据进行分组。 有关窗口的完整说明,请参见windows。
*/
.window(TumblingProcessingTimeWindows.of(Time.seconds(2)))
/**
* * @tparam IN The type of the input value.
* * @tparam OUT The type of the output value.
* * @tparam KEY The type of the key.
*/
.reduce((a,b) => (a._1,a._2 +b._2))
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
2> (b,3)
6> (a,3)Window.fold
- 按key进行处理,第一个参数,是字符串,放在每次处理的最前面第二个是表达式,第二个表达式有两个参数,第一个参数,就是第一个参数的值,第二个参数,我每次循环key时,迭代的下一个元素
- 输入数据
b a b a a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.window.window.fold
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream("localhost", port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
/**
* 定义window,并指定分配元素到window的方式
* 可以在已经分区的KeyedStream上定义Windows。 Windows根据某些特征(例如,在最后5秒内到达的数据)对每个密钥中的数据进行分组。 有关窗口的完整说明,请参见windows。
*/
.window(TumblingProcessingTimeWindows.of(Time.seconds(2)))
/**
* 按key进行处理,第一个参数,是字符串,放在每次处理的最前面第二个是表达式,第二个表达式有两个参数,第一个参数,就是第一个参数的值,第二个参数,我每次循环key时,迭代的下一个元素
*/
.fold("字符串开始")((str, i) => { str + "-" + i} )
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
6> 字符串开始-(a,1)-(a,1)-(a,1)
2> 字符串开始-(b,1)-(b,1)-(b,1)DataStream union DataStream
- 对两个DataStream进行合并,合并之后不能再次进行计算
- 输入数据
a a bc c a- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.union
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream1 = getDataStream(env,1234,"localhost")
val dataStream2 = getDataStream(env,12345,"localhost")
/**
* 只是将两个流的数据,union在一起,之后,不能再进行操作了
*/
val dataStream3 = dataStream1.union(dataStream2)
dataStream3.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
def getDataStream(env: StreamExecutionEnvironment,port:Int,host:String):DataStream[(String,Int)]={
//env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream(host, port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
.timeWindow(Time.seconds(5))//每2秒滚动窗口
.sum(1)
dataStream2
}
}
- 输出数据
6> (a,2)
4> (c,2)
2> (b,1)
6> (a,1)DataStream join DataStram
- join,两上流根据key相等进行连接,然后调用apply函数,进行具体的相同key进行计算
- 输入数据
a a bc c c a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.join
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream1 = getDataStream(env,1234,"localhost")
val dataStream2 = getDataStream(env,12345,"localhost")
/**
* 只是将两个流的数据,union在一起,之后,不能再进行操作了
*/
val dataStream3 = dataStream1.join(dataStream2)
dataStream3.where(x => x._1).equalTo(x => x._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(2)))
.apply((a,b) => (a._1,a._2 + b._2) )
.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
def getDataStream(env: StreamExecutionEnvironment,port:Int,host:String):DataStream[(String,Int)]={
//env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream(host, port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
.timeWindow(Time.seconds(5))//每2秒滚动窗口
.sum(1)
dataStream2
}
}
- 输出数据
6> (a,3)
2> (b,2)DataStream.intervalJoin
- 两流,根据key,连接,找到两流都有的共同元素,进行函数处理process()
- 输入数据
c c aa a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.intervaljoin
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.ProcessJoinFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.util.Collector
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
val dataStream1 = getDataStream(env,1234,"localhost")
val dataStream2 = getDataStream(env,12345,"localhost")
val dataStream3 = dataStream1.keyBy(0).intervalJoin(dataStream2.keyBy(0))
dataStream3.between(Time.seconds(-5), Time.seconds(5))
//.upperBoundExclusive(true) // optional
//.lowerBoundExclusive(true) // optional
.process(new ProcessJoinFunction[(String,Int),(String,Int),String] {
override def processElement(left: (String, Int), right: (String, Int), ctx: ProcessJoinFunction[(String, Int), (String, Int), String]#Context, out: Collector[String]): Unit = {
println(left + "," + right)
out.collect( left + "," + right)
}
})
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
def getDataStream(env: StreamExecutionEnvironment,port:Int,host:String):DataStream[(String,Int)]={
//env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream(host, port, '\n')
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
dataStream2
}
}
- 输出数据
(a,1),(a,1)
(a,1),(a,1)DataStream.cogroup
- 对两个数据流进行处理,按key去重取两个流的并集,再按key分别统计每一个流的元素,进行汇总处理
- 第一个流的元素为 c,a 第二个流的元素为 a b ,所以一个统计了四个元素,每一个元素在每个流中千是多少,也统计出来了
- 输入数据
c c aa a b- 程序
模板- 输出数据
==============开始
first
[(a,1)]
second
[(a,1), (a,1)]
==============结束
==============开始
first
[(c,1), (c,1)]
second
[]
==============结束
==============开始
first
[]
second
[(b,1)]
==============结束DataStraem.connect
- 相当于两个数的数据,都通过 ConnectStream.函数来处理,函数都有两个方法,一个处理流一,一个处理流二
- 输入数据
c c aa a b- 程序
模板- 输出数据
(a,1)
(a,1)
(b,1)
(c,1)
(c,1)
(a,1)
DataStraem.coMap
- 相当于两个数的数据,都通过 ConnectStream.函数来处理,函数都有两个方法,一个处理流一,一个处理流二
- 输入数据
c c aa a b- 程序
模板- 输出数据
(a,1)
(a,1)
(b,1)
(c,1)
(c,1)
(a,1)
DataStraem.coFlatMap
- 相当于两个数的数据,都通过 ConnectStream.函数来处理,函数都有两个方法,一个处理流一,一个处理流二
- 输入数据
c c aa a b- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.coFlatMap
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.co.CoMapFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
env.setParallelism(1) //由于想看数据结构,所以先设为1,这样
val dataStream1 = getDataStream(env,1234,"localhost")
val dataStream2 = getDataStream(env,12345,"localhost")
val dataStream3 = dataStream1.connect(dataStream2)
dataStream3
.flatMap(x => x.toString.split(" ") , x => x.toString.split(" "))
.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
def getDataStream(env: StreamExecutionEnvironment,port:Int,host:String):DataStream[String]={
//env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream(host, port, '\n')
// val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
dataStream
}
}
- 输出数据
a
a
b
c
c
a
Datastream.assignAscendingTimestamps
- 指定时间戳
- 输入数据
c c a- 程序
package com.opensourceteams.module.bigdata.flink.example.datastream.operator.assignTimestamps
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.time.Time
/**
* nc -lk 1234 输入数据
*/
object Run {
def main(args: Array[String]): Unit = {
val port = 1234
// get the execution environment
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //设置并行度
val dataStream = env.socketTextStream("localhost", port, '\n')
dataStream.assignAscendingTimestamps(x => System.currentTimeMillis())
val dataStream2 = dataStream.flatMap(x => x.split(" ")).map((_,1))
.keyBy(0)
.timeWindow(Time.seconds(2))//每2秒滚动窗口
.sum(1)
dataStream2.print()
println("=======================打印StreamPlanAsJSON=======================\n")
println("JSON转图在线工具: https://flink.apache.org/visualizer")
println(env.getStreamGraph.getStreamingPlanAsJSON)
println("==================================================================\n")
if(args == null || args.size ==0){
env.execute("默认作业")
}else{
env.execute(args(0))
}
println("结束")
}
}
- 输出数据
(c,2)
(a,1)