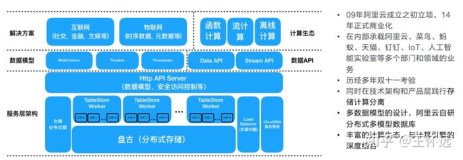
表格存储TableStore是阿里云自研的面向海量结构化和半结构化数据存储的Serverless NoSQL多模型数据库,被广泛用于社交、物联网、人工智能、元数据和大数据等业务场景。表格存储TableStore采用与Google Bigtable类似的宽表模型,天然的分布式架构,能支撑高吞吐的数据写入以及PB级数据存储。
原生的宽表数据模型,存在一些天然的缺陷,例如无法很好的支持属性列的多条件组合查询,或者更高级的全文检索或空间检索。另外在与计算系统的对接上,特别是流计算场景,传统的大数据Lambda架构,需要用户维护多套存储和计算系统,没法很天然的支持数据在存储和计算系统之间的流转。以上这些问题,均在表格存储TableStore在支持阿里巴巴集团内、阿里云公共云以及专有云等业务中逐渐暴露出来。
表格存储TableStore简单可靠的数据模型和架构,开始承担越来越丰富的不同类型的数据存储,例如时序时空数据、元数据、消息数据、用户行为数据和轨迹溯源数据等。越来越多的客户也开始把表格存储TableStore当做一个统一的在线大数据存储平台,所以我们迫切需要支持海量数据中对数据的高效查询、分析和检索。同时也需要考虑如何更贴近业务,抽象出更贴近业务的数据模型,让数据的接入变得更加简单。
在2019年3月6日的云栖发布会,表格存储TableStore对以下几个方面做了重大升级:
- 提供多种数据模型,满足不同数据场景的需求,简化数据建模和开发。
- 提供多元化索引,满足不同场景下简单或复杂条件查询的功能需求。
- 提供实时数据通道,无缝对接流计算引擎,支持表内数据的实时更新订阅。
多模型
表格存储TableStore在选择要支持的数据模型的时候,更多的综合了当前业务现状以及用户画像,提取大部分客户的通用需求,总结和定义了产品适合的几大类核心数据场景,来抽象和定义数据模型。数据模型的定义分为『具象』和『抽象』:抽象模型是类似于关系模型或者文档模型的能满足大部分类型数据的抽象,属于比较通用的数据模型;具象模型是对某一具体特征场景数据的抽象,适合单一垂直类的数据场景。表格存储TableStore同时提供抽象和具象模型,当然在介绍这些模型之前,先来明确我们的核心数据场景。
核心场景

表格存储TableStore的核心场景包含这五大类,分别对应不同类型的应用系统,以及每类数据场景下数据有典型的特征和对存储和计算的特殊的需求,简单来说:
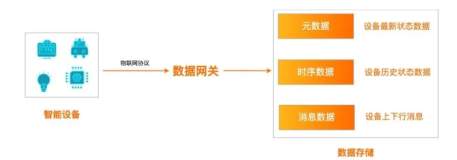
- 时序数据:时序数据解决的是对包含4W(Who, When, Where, What)元素数据的抽象,数据量相对比较庞大,需要存储引擎支持对时间线的索引以及对时间线的时间范围查询。
- 时空数据:时空数据是基于时序数据加上了空间的维度,同时可能没有时序数据的连续性。总的来说,特征和时序数据比较类似。
- 消息数据:消息数据广泛存在于消息系统,例如即时通讯消息系统或者Feeds流消息系统内。消息的存储和传递更像是消息队列模型,但是要求消息队列能够提供海量级消息存储以及海量Topic,这是传统专业级消息队列产品所无法支撑的。
- 元数据:这类元数据属于非关系类元数据,例如历史订单数据、图片智能标签元数据点。特点是量级比较大,每个数据存在的属性比较多且是稀疏的,要求存储能够支持对各种维度属性的条件过滤,对查询可用性有比较高的要求。
- 大数据:这是Bigtable模型所对应的最主要数据场景,特点是数据量极其庞大,需要很好的支持批量计算。
TableStore多模型
基于以上总结的表格存储TableStore所针对的核心数据场景,我们从业务需求中抽象出三大类数据模型,分别是:WideColumn(宽行模型)、Timeline(消息模型)和Timestream(时序模型)。
宽行模型
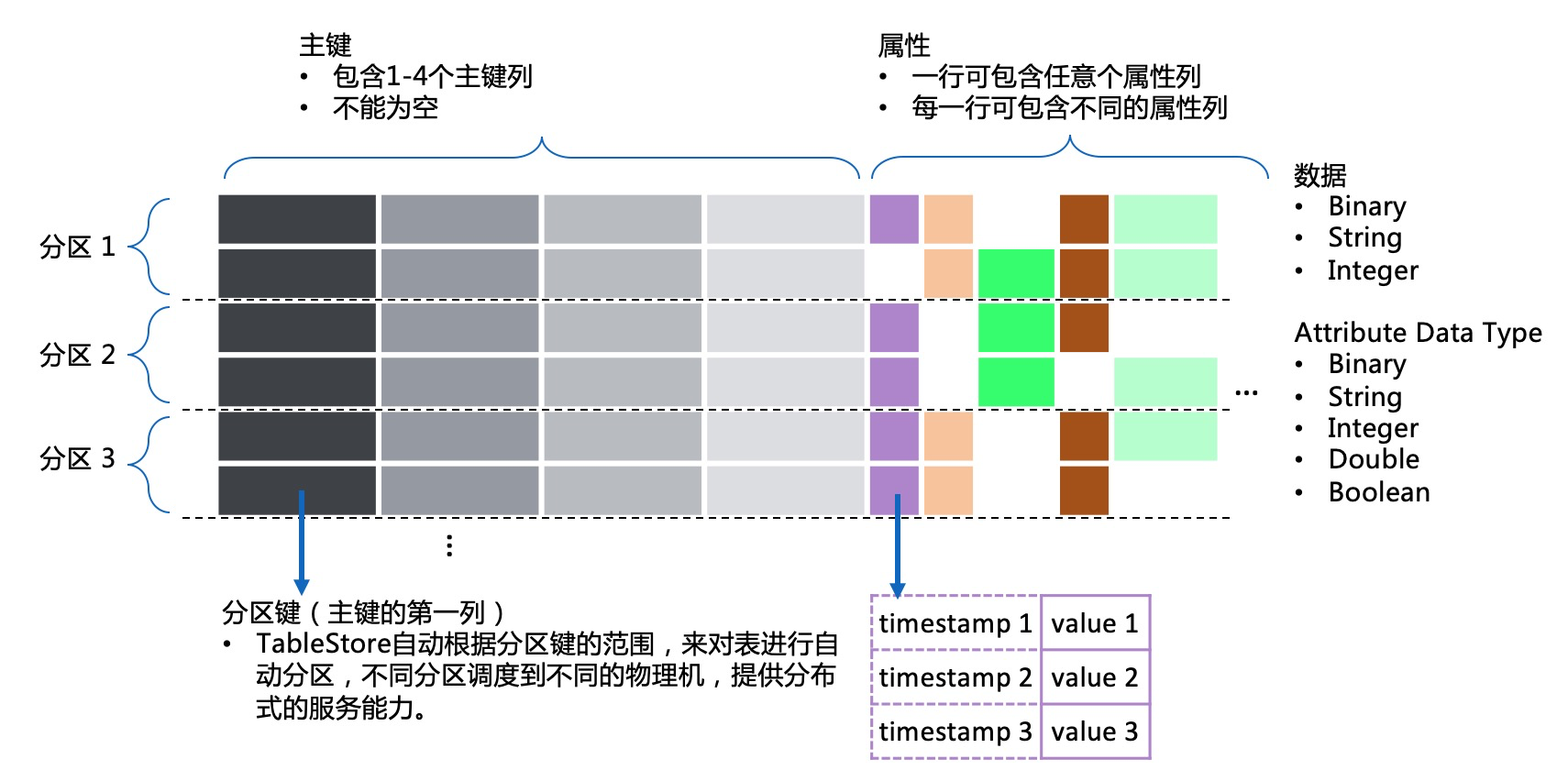
宽行模型是由Bigtable提出,特征是:
- 三维数据结构:对比MySQL的二维数据结构,在属性列这一维度上多了版本属性。同一列数据可以存储多个不同版本,并可定义不同的生命周期,主要用于数据的自动化生命周期管理。
- 稀疏列:表不需要有强格式定义,可以任意的对每一行定义列和类型。
- 大表:一张表可以存储万亿行数据,大表数据根据分区键的范围来分区,不同的分区由不同的机器来加载和提供服务,能比较简单的实现分布式。
宽行模型主要应用于元数据和大数据场景,一些典型应用场景可参考:
我们也提供HBase API兼容的Client:《使用HBase Client访问阿里云NoSQL数据库表格存储》。
消息模型
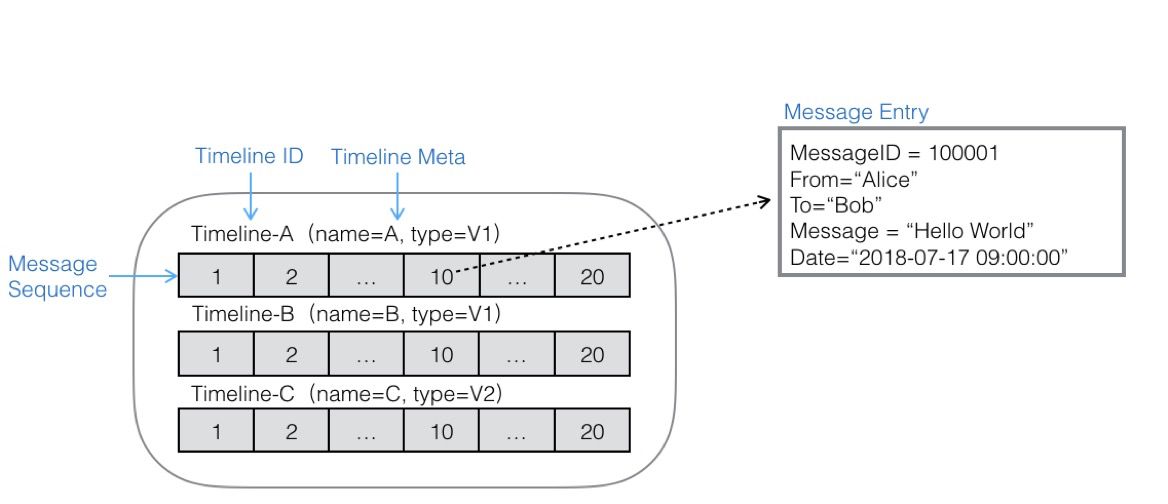
消息模型是表格存储TableStore针对消息数据所抽象的数据模型,主要适用于消息系统中海量消息存储和同步,特征是:
- 轻量级消息队列:大表中能模拟海量消息队列,虽然不能完全模拟一个真正消息队列的所有能力,但是能满足对消息最基本的存储和同步能力。
- 消息永久存储:能保证对数据的永久存储,消息写入和同步的性能不会受到数据规模的影响。
- 消息同步模型:对消息同步模型没有严格要求,应用层可以根据自己的业务特征,同时实现推模型或者拉模型。
消息模型主要应用于消息数据场景,一些典型应用场景可参考:
- 《现代IM系统中消息推送和存储架构的实现》
- 《TableStore Timeline:轻松构建千万级IM和Feed流系统》
- 《如何打造千万级Feed流系统》
- 《基于TableStore构建简易海量Topic消息队列》
- 《如何快速开发一个IM系统》
时序模型
时序模型主要应用与时序和时空场景,也是表格存储TableStore综合了业界主流的时序数据库,所定义和抽象的数据模型,特征是:
- 海量数据存储:能提供PB级数据存储,可打造多租户的时序数据库底层存储,写入和查询性能不受数据规模的影响。
- 时间线索引:提供对时间线的索引,能满足对时间线Tag的任何条件组合过滤,并且能够支持比较海量的时间线规模。
- 完整的模型定义:在业界标杆的时序数据库模型定义上,补充了空间维度的定义并且提供空间索引,以及支持多列值支持,不限制只对数值类型的支持。
时序模型主要应用于时序和时空数据,一些典型应用场景可参考:
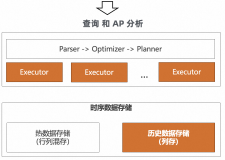
查询优化
上述场景中提到的对于表内数据的查询优化,最基本手段就是需要对数据建立索引。表格存储TableStore选择的做法是,对于不同类型的查询场景,我们需要提供不同类型的索引。业界对海量数据建立索引的方案有多种,在传统技术架构中应用比较多的主要包括Phoenix SQL二级索引或者Elasticsearch搜索引擎。二级索引能提供高效的固定维度的条件查询,查询性能不受数据规模的影响,而Elasticsearch搜索引擎能提供比较灵活的多条件组合查询、全文索引和空间索引。两种类型的索引实现,有不同的优缺点,以及适用于不同的场景。表格存储TableStore的做法是同时实现和这两类索引原理类似的索引,来满足不同场景下对查询的不同需求。
全局二级索引

当用户创建一张表时,其所有PK列构成了该表的『一级索引』:即给定完整的行主键,可以迅速的查找到该主键所在行的数据。但是越来越多的业务场景中,需要对表的属性列,或者非主键前缀列进行条件上的查询,由于没有足够的索引信息,只能通过进行全表的扫描,配合条件过滤,来得到最终结果,特别是全表数据较多,但最终结果很少时,全表扫描将浪费极大的资源。表格存储TableStore提供的全局二级索引功能支持在指定列上建立索引,生成的索引表中数据按用户指定的索引列进行排序,主表的每一笔写入都将自动异步同步到索引表。用户只向主表中写入数据,根据索引表进行查询,在许多场景下,将极大的提高查询的效率。更多的技术解读,请参考这篇文章《通过全局二级索引加速表格存储上的数据查询》。
多元索引
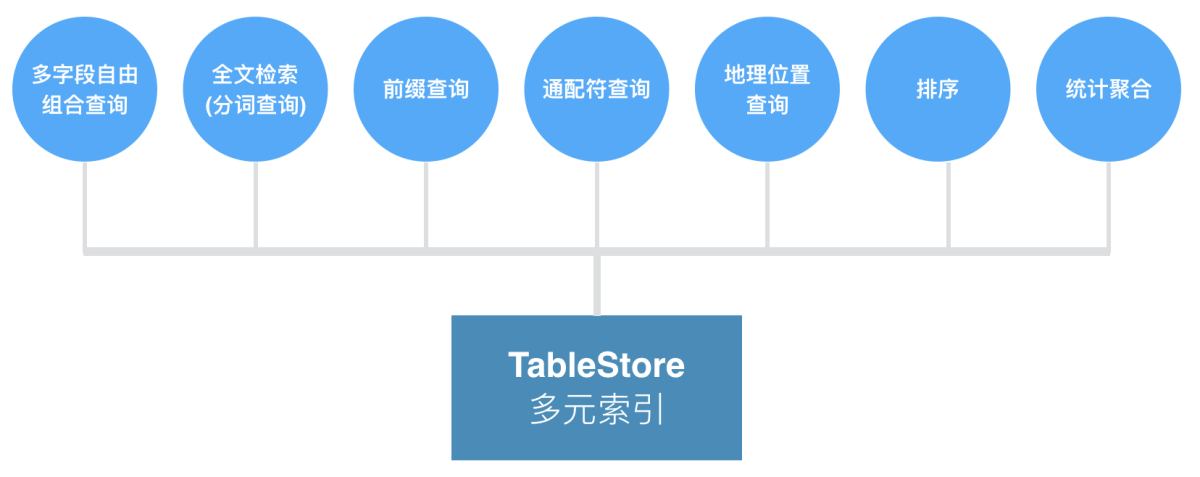
表格存储TableStore多元索引是表格存储TableStore重点打造的一个多功能索引能力,旨在补位二级索引无法覆盖的场景,解决大数据场景下的复杂查询和轻量级分析问题,比如多字段组合查询、前缀查询、通配符查询、嵌套查询、全文检索(分词)、地理位置查询、排序和统计聚合等功能。关于对多元索引的更多解读,可以阅读这篇文章《TableStore多元索引,大数据查询的利器》,关于多元索引的更多应用场景,可以参考以下文章:
计算衔接
表格存储TableStore已经与比较多的开源大数据计算引擎以及阿里云计算产品衔接,例如Hive、Spark、MaxCompute以及DataLakeAnalytics等,覆盖了批量计算和交互式分析。可以由第三方产品提供的数据通道服务,将表格存储TableStore上的数据全量或者增量复制到计算系统,也可以由计算系统通过Connector直接访问表内的数据。
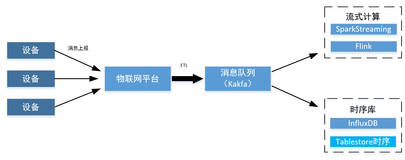
批量计算和交互式分析访问数据存储的方式是批量扫描,主要通过自定义数据Connector的方式。但是其他类计算系统例如流计算或者函数计算(Lambda架构),数据是需要流式的并且实时的从存储系统到计算系统。这个能力是传统开源Bigtable类数据库所做不到的,例如HBase或Cassandra。
如果表内的数据可以实时的流动,那将给表带来更丰富的计算和处理场景,例如可以做跨域复制、备份,或者接入流计算引擎做实时分析或者函数计算做事件触发式编程,也可以由应用方自定义数据处理,来做个性化数据处理。
表格存储TableStore提供了全新的实时数据通道,能支持订阅表内的实时数据更新,来扩充表格存储TableStore的计算能力。
通道服务
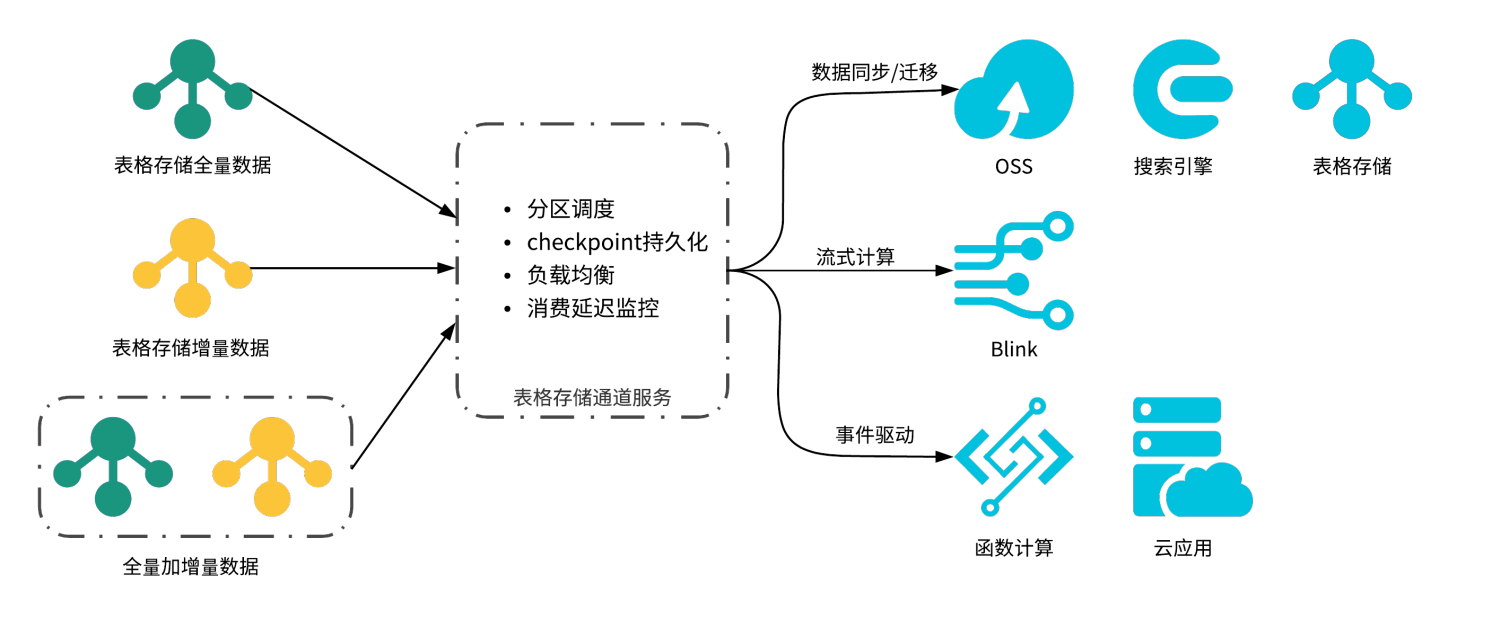
TableStore 通道服务(Tunnel Service)是基于表格存储数据接口之上的全增量一体化服务,通道服务为用户提供了增量、全量、增量加全量三种类型的分布式数据实时消费通道。通过为数据表建立Tunnel Service数据通道,可以简单地实现对表中历史存量和新增数据的消费处理。基于通道服务用户可以轻松的实现如图所示的场景架构:数据同步、搬迁和备份,流式数据处理以及事件驱动架构。
关于对通道服务TunnelService更多的技术解读,可以参考这篇文章:《大数据同步利器: 表格存储全增量一体消费通道》。基于通道服务的更多应用场景,可以参考以下文章:
总结
表格存储TableStore通过同时提供具象和抽象的数据模型,来满足不同核心数据场景的要求,更贴近业务抽象;提供多元化索引(全局二级索引和多元索引)来满足不同类型场景条件查询需求;提供全新的实时数据通道,来扩充实时计算的能力以及可自定义的实时数据处理。这三大方面的新功能发布,能够让我们在数据模型、灵活查询以及数据分析层面,都有一定的提升,帮助打造统一的在线数据存储平台。