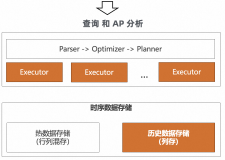
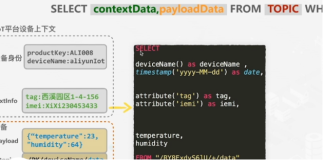
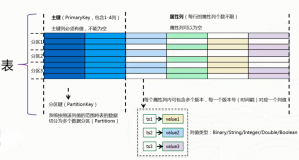
TableStore是阿里云自研的在线数据平台,提供高可靠的存储,实时和丰富的查询功能,适用于结构化、半结构化的海量数据存储以及各种查询、分析。
用户画像数据是一种数据规模较大、数据结构复杂、查询种类多的数据,是公司差异化运营的基础,是打造“千人千面”、智能化的核心数据,帮产品找到最佳目标客户,对各种产品而言是一种很有价值的数据。
我们接下来先看一下用户画像数据的场景和特征,仅以存储和查询的角度看一下用户画像数据的存储选择。
用户画像数据特点
数据量大
用户画像的数据有两大类,一类是用户行为日志,实时由用户的行为产生,数据规模和产品用户的数量和活跃程度相关,这部分是用户画像数据的原始素材,用来产生最终的用户画像数据,另一类就是主角:用户画像数据,这部分数据是真正的用户的画像数据,表示用户的多种维度的特征,包括用户属性、社交关系和行为偏好等。第一类数据会经过复杂的计算分析后产生第二种数据。第二种数据会被最终的各类系统用来给不同用户输送不同的内容。
数据结构复杂
用户画像数据中表示了一个用户的多重维度的特征,维度越多,数据格式越复杂,不仅有多种类型, 也有多种层次,比如用户属性、社交关系和行为偏好等:
-
用户属性:
- 性别:枚举。
- 年龄:整数。
- 职业:字符串。
-
社交关系:
- 同好:字符串数组。
- 好友推荐:字符串数组。
-
行为偏好:
- 品牌:字符串。
- 商圈偏好:字符串。
- 标签:嵌套类型。
这类数据中的数据类型较多,大多数情况下还会有嵌套类型等多维数据,虽然多维数据更加复杂,但是更加自然,符合人的思维,更好理解,但是大多数分布式系统为了水平扩展而牺牲了对这种类型数据的支持。
查询种类多
用户画像数据需要被多种场景使用,一种是需要被用户行为分析系统查询,这种都是指定用户ID批量读取。再一种是被运营系统查询,这种需要按照多种维度查询,以及会有统计聚合需求,比如查询“对巴厘岛感兴趣”的所有用户,比如比较下“对巴厘岛感兴趣”和“对仙本那感兴趣”的用户的数量或者其他特征值。
上述举得两个简单例子中,就会有多种的查询需求:
- 单Key查询。
- 多字段组合查询。
- 分词查询。
- 嵌套查询。
- 统计聚合。
针对上述的场景需求,目前业内已经有多种解决方案,我们接下来看一下:
开源解决方案
一种很容易想到的方案是使用关系型数据库,比如MySQL或PostgreSQL存储,但是这种只适合存储小数据量,如果数据量超过单机存储能力,则会不适合。就算采用了分库分表的方式,也会带来极大的运维压力和产品功能牺牲。
另外一种方案,使用HBase等分布式数据库,但是这种NoSQL数据库只提供单Key和Key前缀范围查询,无法支持按照其他属性列查询,无法满足我们上面的需求,就算引入Phoenix使用了二级索引,也需要提前固定好查询,无法支持自由组合,更无法支持嵌套查询。
还有一种方案,是从查询复杂度考虑,直接使用搜索引擎Elasticsearch或Solr,但是这种虽然能满足查询需求,可惜没法满足数据不能丢的要求,存在丢失数据的风险。
至此,考虑了所有开源系统后,没有一个系统能满足用户需求,那么只能退而求其次,采用组合的方式:
- 存储系统使用HBase,保证数据可靠性。
- 同步方式采用Lily Indexer。
- 查询引擎使用solr系统。
上述架构方案,看起来满足了我们上面的所有需求,虽然麻烦了点。但是只能算是基本满足,因为这套架构存在比较大的问题:
- Lily indexer基于HBase的日志顺序,依赖一个时间戳,推送服务需要根据时间戳进行重排序再写入,在很多场景下难以做到严格的保序,可能会丢数据。
- 存量数据,以及solr中索引数据损坏后需要rebuild index时,需要使用运维人员通过工具去做,增加风险的同时还要只能整个系统的运维压力。
除此之外,还需要运维HBase、Lily index、Proxy和Solr四个系统,需要配备熟悉这四个开源系统的人员,这个又是一笔额外支出。除了开源解决方案外,如今又多了一种选择,使用云解决方案。
TableStore云解决方案
在现有的各种云产品中,能满足上述用户画像数据存储需求的系统并不多,阿里云TableStore是一款符合要求的系统,10年前就开始自研,多年的双十一、公有云客户的锤炼沉淀,保证了系统的可靠性和稳定性。
我们先来看一下基于TableStore存储用户画像数据的架构方案:

- 数据存储在TableStore中,TableStore可以提供10个9的数据可靠性保障,数据可靠性更高。
- 数据和索引都在一个系统里面,写入,读取都是通过同一套API写入和查询,易用性更高。
-
完全满足上述提出的查询需求,包括:
- 单Key查询。
- 多字段组合查询。
- 分词查询。
- 嵌套查询。
- 统计聚合。
- TableStore是分布式系统,可以水平扩展,目前生产环境单表最大有几十PB,每秒写入有几千万行,完全能胜任任何大数据的写入和存储。
示例
接下来,我们举个例子帮助读者理解。
有一个大型连锁超市,有一套自己的用户画像系统,涉及的用户画像包括下列特征;
-
用户属性:
- 年龄
- 性别
- 家庭住址
- 家庭位置
-
社交关系:
- 邻居
- 可能认识的人
- 同好
-
行为偏好:
- 价格敏感度
- 商圈偏好
- 标签:包括喜好的各种品牌
- 周期性购买的产品
首先,我们设计TableStore中主表结构:
| 主键列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 | 属性列 |
|---|---|---|---|---|---|---|---|
| 用户ID | 年龄 | 家庭住址 | 家庭位置 | 可能认识的人 | 价格敏感度 | 商圈偏好 | 标签 |
| String | Long | String | String | String Array | bool | String Array | String Array |
| 100001 | 39 | 杭州市xxx街道xxx小区 | [30.295,120.059] | [1002, 1003] | true | [{"name": "城西银泰", "score": 0.80}{"name": "五洲国际", "score": 0.5}] |
["周六"、“促销”,“距离远”] |
上述表结构中,只能按照用户id查询该用户的画像,但是没法通过用户的画像属性反查用户ID,比如促销系统需要查询周六可能回来购物的用户时,就没法查询了。
为了支持属性列查询,我们需要使用多元索引功能,接下来设计多元索引的结构:
| 列 | 列 | 列 | 列 | 列 | 列 |
|---|---|---|---|---|---|
| 用户ID | 年龄 | 家庭住址 | 家庭位置 | 商圈偏好 | 标签 |
| String | Long | Text | GeoPoint | Nested | String Array |
- 家庭地址使用Text类型,这样可以支持分词,我们就能支持按分词查询了。
- 家庭位置是GeoPoint值,那么就可以查询某个卖场附近3公里内的用户有多少,以及特征是啥。
- 商圈偏好:采用Nested类型,因为每个商圈不仅有名字,还有喜好度,比如0.8,这个时候就需要用Nested,而不是Array。
- 标签:采用String Array,每个用户可以有多个标签,比如“周六”、“促销”等。
基于上述索引,我没就能支持很多钟查询了,比如:
- 城西银泰卖场附近三公里,且喜欢促销的用户。
- 标签中含有“促销”的用户在杭州市各大卖场附近3公里内的数量。
- 住在“蒋村街道”,且喜欢周六购物的客户。
基于上述的表和index,我们就能满足上述提到的所有需求。
总结
开源解决方案和TableStore云解决方案都介绍完了,使用了TableStore云解决方案后,可以为架构和系统带来不少的收益。
减少运维负担
在TableStore解决方案中,用户只需要运维自己的应用程序,不需要运维任何的存储系统、查询系统和其他中间件,运维压力大大减少,同时也减少了运维方面的成本开支。
同时,TableStore是Serverless的服务化产品,用户也无需考虑运维,不需要关注扩容、水位等事项,即开即用,只需要关注功能开发即可。
系统架构更简单
在开源解决方案中6个系统,而TableStore解决方案中只有3个系统,系统数减少后,系统架构会更简单,系统可能产生的风险会更少,系统的稳定性等会更高,可以提供更优质的服务体验。
减少时间成本
TableStore云架构方案相对于开源方案,系统更少,从零开始到上线需要的开发时间更少,同时,TableStore是serverless的云服务,全球多个区域即开即用,可以大大降低客户的开发上线的时间,提前将产品推出,抢先争取市场领先优势。
服务可用性保障
TableStore作为一款云产品,提供了SLA保障,目前在可用性上是3个9的保障,可靠性是10个9的保障,这个在业内算是比较高的了,比自己搭建开源系统的可用性和可靠性都要高的多。而且,如果达不到,会有多倍赔偿,尽量让用户能安心专注产品研发和占领市场。
最后
目前,已经有大量的业务在使用TableStore,后续我们会继续优化改进TableStore,为客户持续提供一款高性能、丰富功能、低成本、高可用性的分布式系统,为客户的海量数据保驾护航。