MaxCompute Spark开发指南
0. 概述
本文档面向需要使用MaxCompute Spark进行开发的用户使用。本指南主要适用于具备有Spark开发经验的开发人员。
MaxCompute Spark是MaxCompute提供的兼容开源的Spark计算服务,它在统一的计算资源和数据集权限体系之上,提供Spark计算框架,支持用户以熟悉的开发使用方式提交运行Spark作业,以满足更丰富的数据处理分析场景。
本文将重点介绍MaxCompute Spark能够支撑的应用场景,同时说明开发的依赖条件和环境准备,重点对Spark作业开发、提交到MaxCompute集群执行、诊断进行介绍。
1. 前提条件
MaxCompute Spark是阿里云提供的Spark on MaxCompute的解决方案,能够让Spark应用运行在托管的MaxCompute计算环境中。为了能够在MaxCompute环境中安全地运行Spark作业,MaxCompute提供了以下SDK和MaxCompute Spark定制发布包。
SDK定位于开源应用接入MaxCompute SDK:
提供了集成所需的API说明以及相关功能Demo,用户可以基于项目提供的Spark-1.x以及Spark-2.x的example项目构建自己的应用,并且提交到MaxCompute集群上。
MaxCompute Spark客户端发布包:
集成了MaxCompute认证功功能,作为客户端工具,用于通过Spark-submit方式提交作业到MaxCompute项目中运行,目前提供了面向Spark1.x和Spark2.x的2个发布包:spark-1.6.3和spark-2.3.0 SDK在开发时,可以通过配置Maven依赖进行引用。Spark客户端需要根据开发的Spark版本,提前下载。如,需要开发Spark1.x应用,应下载spark-1.6.3版本客户端;如需开发Spark2.x应用,应下载spark-2.3.0客户端。
2. 开发环境准备
2.1 Maxcompute Spark客户端准备
MaxCompute Spark发布包:集成了MaxCompute认证功功能,作为客户端工具,用于通过Spark-submit方式提交作业到MaxCompute项目中运行,目前提供了面向Spark1.x和Spark2.x的2个发布包:
请根据需要开发的Spark版本,选择合适的版本下载并解压Maxcompute Spark发布包。
2.2 设置环境变量
JAVA_HOME设置
# 尽量使用JDK 1.7+ 1.8+ 最佳
export JAVA_HOME=/path/to/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
SPARK_HOME设置
export SPARK_HOME=/path/to/spark_extracted_package
export PATH=$SPARK_HOME/bin:$PATH
2.3 设置Spark-defaults.conf
在 $SPARK_HOME/conf
路径下存在spark-defaults.conf.template文件,这个可以作为spark-defaults.conf的模版,需要在该文件中设置MaxCompute相关的账号信息后,才可以提交Spark任务到MaxCompute。默认配置内容如下,将空白部分根据实际的账号信息填上即可,其余的配置可以保持不变。
# MaxCompute账号信息
spark.hadoop.odps.project.name =
spark.hadoop.odps.access.id =
spark.hadoop.odps.access.key =
# 以下配置保持不变
spark.sql.catalogImplementation=odps
spark.hadoop.odps.task.major.version = cupid_v2
spark.hadoop.odps.cupid.container.image.enable = true
spark.hadoop.odps.cupid.container.vm.engine.type = hyper
spark.hadoop.odps.end.point = http://service.cn.maxcompute.aliyun.com/api
spark.hadoop.odps.runtime.end.point = http://service.cn.maxcompute.aliyun-inc.com/api
3. 访问MaxCompute表所需依赖
若作业需要访问MaxCompute表,需要依赖odps-spark-datasource模块,本节介绍如何把该依赖编译安装到本地maven仓库;若无需访问可直接跳过。
- git clone代码,github地址: https://github.com/aliyun/aliyun-cupid-sdk/tree/3.3.2-public
#git clone git@github.com:aliyun/aliyun-cupid-sdk.git
- 编译模块
#cd ${path to aliyun-cupid-sdk}
#git checkout 3.3.2-public
// 编译并安装cupid-sdk
#cd ${path to aliyun-cupid-sdk}/core/cupid-sdk/
#mvn clean install -DskipTests
// 编译并安装datasource。依赖cupid-sdk
// for spark-2.x
# cd ${path to aliyun-cupid-sdk}/spark/spark-2.x/datasource
# mvn clean install -DskipTests
// for spark-1.x
# cd ${path to aliyun-cupid-sdk}/spark/spark-1.x/datasource
#mvn clean install -DskipTests
- 添加依赖
<!-- Spark-1.x请依赖此模块 -->
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_2.10</artifactId>
<version>3.3.2-public</version>
</dependency>
<!-- Spark-2.x请依赖此模块 -->
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_2.11</artifactId>
<version>3.3.2-public</version>
</dependency>
4. OSS依赖
若作业需要访问OSS,直接添加以下依赖即可
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>hadoop-fs-oss</artifactId>
<version>3.3.2-public</version>
</dependency>
5. 应用开发
MaxCompute产品提供了两个应用构建的模版,用户可以基于此模版进行开发,最后统一构建整个项目后用生成的应用包即可直接提交到MaxCompute集群上运行Spark应用。
5.1 通过模版构建应用
MaxCompute Spark提供两个应用构建模版,用户可以基于此模版进行开发,最后统一构建整个项目后用生成的应用包即可直接提交到MaxCompute集群上运行Spark应用。首先需要把代码clone下来
#git clone git@github.com:aliyun/aliyun-cupid-sdk.git
#cd aliyun-cupid-sdk
#checkout 3.3.2-public
#cd archetypes
// for Spark-1.x
sh Create-AliSpark-1.x-APP.sh spark-1.x-demo /tmp
// for Spark-2.x
Create-AliSpark-2.x-APP.sh spark-2.x-demo /tmp
以上命令会在/tmp目录下创建名为 spark-1.x-demo(spark-2.x-demo)的maven project,执行以下命令进行编译和提交作业:
#cd /tmp/spark-2.x/demo
#mvn clean package
// 提交作业
$SPARK_HOME/bin/spark-submit \
--master yarn-cluster \
--class SparkPi \
/tmp/spark-2.x-demo/target/AliSpark-2.x-quickstart-1.0-SNAPSHOT-shaded.jar
# Usage: sh Create-AliSpark-2.x-APP.sh <app_name> <target_path>
sh Create-AliSpark-2.x-APP.sh spark-2.x-demo /tmp/
cd /tmp/spark-2.x-demo
mvn clean package
# 冒烟测试
# 1 利用编译出来的shaded jar包
# 2 按照文档所示下载MaxCompute Spark客户端
# 3 参考文档”置环境变量”指引,填写MaxCompute项目相关配置项
# 执行spark-submit命令 如下
$SPARK_HOME/bin/spark-submit \
--master yarn-cluster \
--class SparkPi \
/tmp/spark-2.x-demo/target/AliSpark-2.x-quickstart-1.0-SNAPSHOT-shaded.jar
5.2 Java/Scala开发样例
Spark-1.x
pom.xml 须知
请注意 用户构建Spark应用的时候,由于是用MaxCompute提供的Spark客户端去提交应用,故需要注意一些依赖scope的定义
- spark-core spark-sql等所有spark社区发布的包,用provided scope
- odps-spark-datasource 用默认的compile scope
<!-- spark相关依赖, provided -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- datasource依赖, 用于访问MaxCompute表 -->
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_${scala.binary.version}</artifactId>
<version>3.3.2-public</version>
</dependency>
案例说明
WordCount
详细代码
提交方式
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.WordCount \
${path to aliyun-cupid-sdk}/spark/spark-1.x/spark-examples/target/spark-examples_2.10-version-shaded.jar
Spark-SQL on MaxCompute Table
详细代码
提交方式
# 运行可能会报Table Not Found的异常,因为用户的MaxCompute Project中没有代码中指定的表
# 可以参考代码中的各种接口,实现对应Table的SparkSQL应用
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.sparksql.SparkSQL \
${path to aliyun-cupid-sdk}/spark/spark-1.x/spark-examples/target/spark-examples_2.10-version-shaded.jar
GraphX PageRank
详细代码
提交方式
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.graphx.PageRank \
${path to aliyun-cupid-sdk}/spark/spark-1.x/spark-examples/target/spark-examples_2.10-version-shaded.jar
Mllib Kmeans-ON-OSS
详细代码
提交方式
# 代码中的OSS账号信息相关需要填上,再编译提交
conf.set("spark.hadoop.fs.oss.accessKeyId", "***")
conf.set("spark.hadoop.fs.oss.accessKeySecret", "***")
conf.set("spark.hadoop.fs.oss.endpoint", "oss-cn-hangzhou-zmf.aliyuncs.com")
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.mllib.KmeansModelSaveToOss \
${path to aliyun-cupid-sdk}/spark/spark-1.x/spark-examples/target/spark-examples_2.10-version-shaded.jar
OSS UnstructuredData
详细代码
提交方式
# 代码中的OSS账号信息相关需要填上,再编译提交
conf.set("spark.hadoop.fs.oss.accessKeyId", "***")
conf.set("spark.hadoop.fs.oss.accessKeySecret", "***")
conf.set("spark.hadoop.fs.oss.endpoint", "oss-cn-hangzhou-zmf.aliyuncs.com")
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.oss.SparkUnstructuredDataCompute \
${path to aliyun-cupid-sdk}/spark/spark-1.x/spark-examples/target/spark-examples_2.10-version-shaded.jar
Spark-2.x
pom.xml 须知
请注意 用户构建Spark应用的时候,由于是用MaxCompute提供的Spark客户端去提交应用,故需要注意一些依赖scope的定义
- spark-core spark-sql等所有spark社区发布的包,用provided scope
- odps-spark-datasource 用默认的compile scope
<!-- spark相关依赖, provided -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>cupid-sdk</artifactId>
<scope>provided</scope>
</dependency>
<!-- datasource依赖, 用于访问MaxCompute表 -->
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-spark-datasource_${scala.binary.version}</artifactId>
<version>3.3.2-public</version>
</dependency>
案例说明
WordCount
详细代码
提交方式
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.WordCount \
${path to aliyun-cupid-sdk}/spark/spark-2.x/spark-examples/target/spark-examples_2.11-version-shaded.jar
Spark-SQL 操作MaxCompute表
详细代码
提交方式
# 运行可能会报Table Not Found的异常,因为用户的MaxCompute Project中没有代码中指定的表
# 可以参考代码中的各种接口,实现对应Table的SparkSQL应用
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.sparksql.SparkSQL \
${path to aliyun-cupid-sdk}/spark/spark-2.x/spark-examples/target/spark-examples_2.11-version-shaded.jar
GraphX PageRank
详细代码
提交方式
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.graphx.PageRank \
${path to aliyun-cupid-sdk}/spark/spark-2.x/spark-examples/target/spark-examples_2.11-version-shaded.jar
Mllib Kmeans-ON-OSS
KmeansModelSaveToOss
详细代码
提交方式
# 代码中的OSS账号信息相关需要填上,再编译提交
val spark = SparkSession
.builder()
.config("spark.hadoop.fs.oss.accessKeyId", "***")
.config("spark.hadoop.fs.oss.accessKeySecret", "***")
.config("spark.hadoop.fs.oss.endpoint", "oss-cn-hangzhou-zmf.aliyuncs.com")
.appName("KmeansModelSaveToOss")
.getOrCreate()
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.mllib.KmeansModelSaveToOss \
${path to aliyun-cupid-sdk}/spark/spark-2.x/spark-examples/target/spark-examples_2.11-version-shaded.jar
OSS UnstructuredData
SparkUnstructuredDataCompute
详细代码
提交方式
# 代码中的OSS账号信息相关需要填上,再编译提交
val spark = SparkSession
.builder()
.config("spark.hadoop.fs.oss.accessKeyId", "***")
.config("spark.hadoop.fs.oss.accessKeySecret", "***")
.config("spark.hadoop.fs.oss.endpoint", "oss-cn-hangzhou-zmf.aliyuncs.com")
.appName("SparkUnstructuredDataCompute")
.getOrCreate()
Step 1. build aliyun-cupid-sdk
Step 2. properly set spark.defaults.conf
Step 3. bin/spark-submit --master yarn-cluster --class \
com.aliyun.odps.spark.examples.oss.SparkUnstructuredDataCompute \
${path to aliyun-cupid-sdk}/spark/spark-2.x/spark-examples/target/spark-examples_2.11-version-shaded.jar
PySpark开发样例
需要文件
若需要访问MaxCompute表,则需要参考第三节(访问MaxCompute表所需依赖)编译datasource包
SparkSQL应用示例(spark1.6)
from pyspark import SparkContext, SparkConf
from pyspark.sql import OdpsContext
if __name__ == '__main__':
conf = SparkConf().setAppName("odps_pyspark")
sc = SparkContext(conf=conf)
sql_context = OdpsContext(sc)
df = sql_context.sql("select id, value from cupid_wordcount")
df.printSchema()
df.show(200)
df_2 = sql_context.sql("select id, value from cupid_partition_table1 where pt1 = 'part1'")
df_2.show(200)
#Create Drop Table
sql_context.sql("create table TestCtas as select * from cupid_wordcount").show()
sql_context.sql("drop table TestCtas").show()
提交运行:
./bin/spark-submit \
--jars ${path to odps-spark-datasource_2.10-3.3.2-public.jar} \
example.py
SparkSQL应用示例(spark2.3)
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("spark sql").getOrCreate()
df = spark.sql("select id, value from cupid_wordcount")
df.printSchema()
df.show(10, 200)
df_2 = spark.sql("SELECT product,category,revenue FROM (SELECT product,category,revenue, dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank FROM productRevenue) tmp WHERE rank <= 2");
df_2.printSchema()
df_2.show(10, 200)
df_3 = spark.sql("select id, value from cupid_partition_table1 where pt1 = 'part1'")
df_3.show(10, 200)
#Create Drop Table
spark.sql("create table TestCtas as select * from cupid_wordcount").show()
spark.sql("drop table TestCtas").show()
提交运行:
spark-submit --master yarn-cluster \
--jars ${path to odps-spark-datasource_2.11-3.3.2-public.jar \
example.py
6. 通过Spark访问VPC环境内服务
对于用户使用Spark on MaxCompute对VPC环境内的RDS、Redis、ECS主机部署的服务等,受限于VPC的访问限制,暂时还无法访问,即将在近期支持。
7. 如何把开源Spark代码迁移到Spark on MaxCompute
case1. 作业无需访问MaxCompute表和OSS
用户jar包可直接运行,参照第二节准备开发环境和修改配置。注意,对于spark或hadoop的依赖必须设成provided。
case2. 作业需要访问MaxCompute表
参考第三节编译datasource并安装到本地maven仓库,在pom中添加依赖后重新打包即可。
case3. 作业需要访问OSS
参考第四节在pom中添加依赖后重新打包即可。
8. 任务提交执行
目前MaxCompute Spark支持以下几种运行方式:local模式,cluster模式,和在DataWorks中执行模式。
8.1 Local模式
local模式主要是让用户能够方便的调试应用代码,使用方式跟社区相同,我们添加了用tunnel读写ODPS表的功能。用户可以在ide和命令行中使用该模式,需要添加配置spark.master=local[N],其中N表示执行该模式所需要的cpu资源。此外,local模式下的读写表是通过读写tunnel完成的,需要在Spark-defaults.conf中增加tunnel配置项(请根据MaxCompute项目所在的region及网络环境填写对应的Tunnel Endpoint地址):tunnel_end_point=http://dt.cn-beijing.maxcompute.aliyun.com。命令行执行该模式的方式如下:
1.bin/spark-submit --master local[4] \
--class com.aliyun.odps.spark.examples.SparkPi \
${path to aliyun-cupid-sdk}/spark/spark-2.x/spark-examples/target/spark-examples_2.11-version-shaded.jar
8.2 Cluster模式
在Cluster模式中,用户需要指定自定义程序入口Main,Main结束(Success or Fail)spark job就会结束。使用场景适合于离线作业,可以与阿里云DataWorks产品结合进行作业调度。命令行提交方式如下:
1.bin/spark-submit --master yarn-cluster \
–class SparkPi \
${ProjectRoot}/spark/spark-2.x/spark-examples/target/spark-examples_2.11-version-shaded.jar
8.3 DataWorks执行模式
用户可以在DataWorks中运行MaxCompute Spark离线作业(cluster模式),以方便与其他类型执行节点集成和调度。
用户需要在DataWorks的业务流程中上传并提交(记得要单击"提交"按钮)资源:
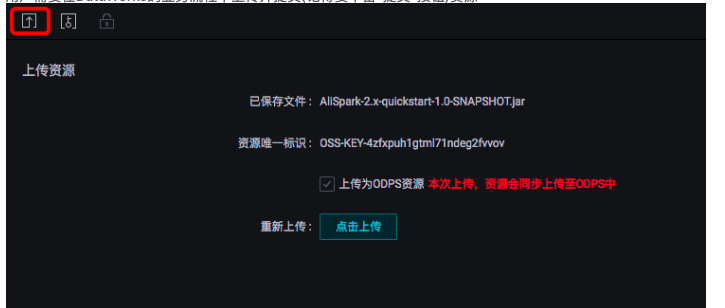
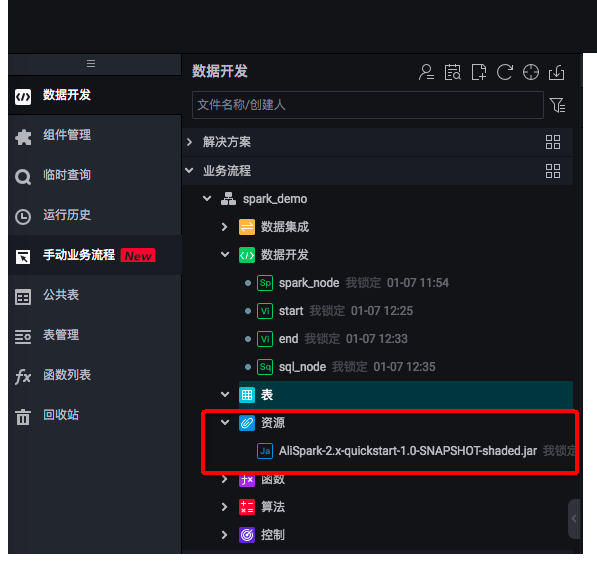
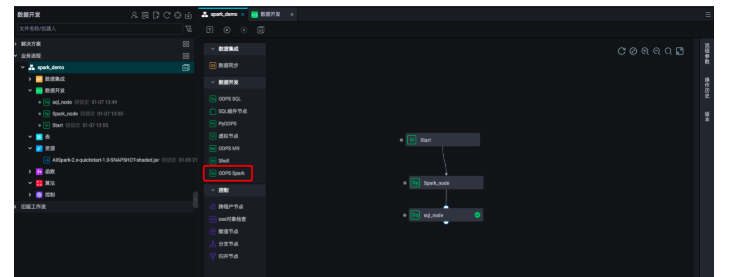
双击拖拽到工作流的Spark节点,对Spark作业进行任务定义:
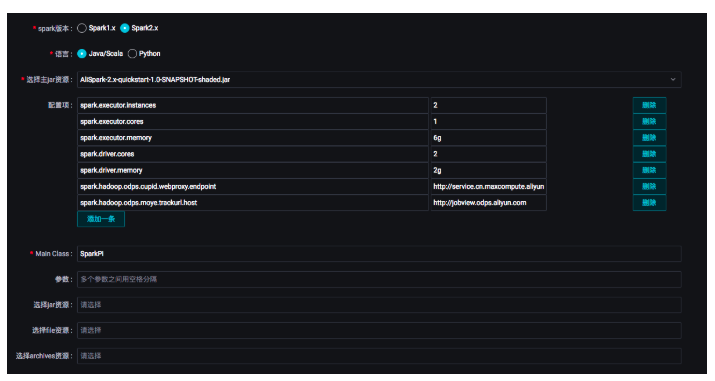
选择Spark的版本、任务使用的开发语言,并指定任务所使用的资源文件。这里的资源文件就是第一步在业务流程中预先上传并发布的资源文件。同时,您还可以指定提交作业时的配置项,如executor的数量、内存大小等配置项。同时设置配置项:spark.hadoop.odps.cupid.webproxy.endpoint(取值填写项目所在region的endpoint,如http://service.cn.maxcompute.aliyun-inc.com/api)、spark.hadoop.odps.moye.trackurl.host(取值填写:http://jobview.odps.aliyun.com)
以便能够查看日志中打印出的jobview信息。
手动执行Spark节点,可以查看该任务的执行日志,从打印出来的日志中可以获取该任务的logview和jobview的url,编译进一步查看与诊断
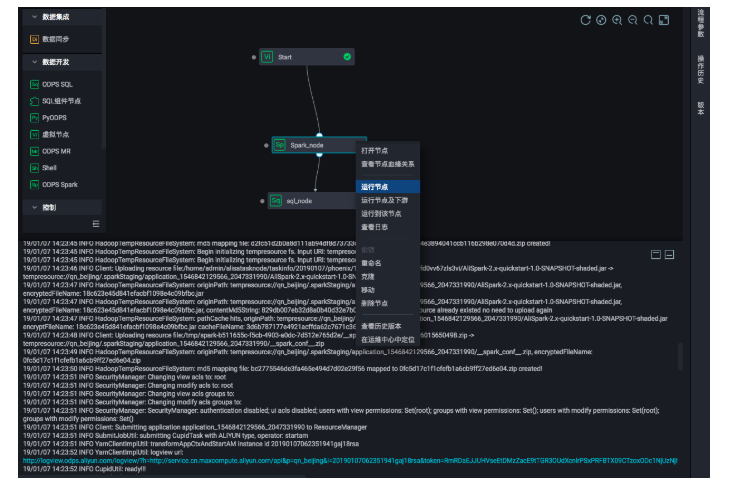
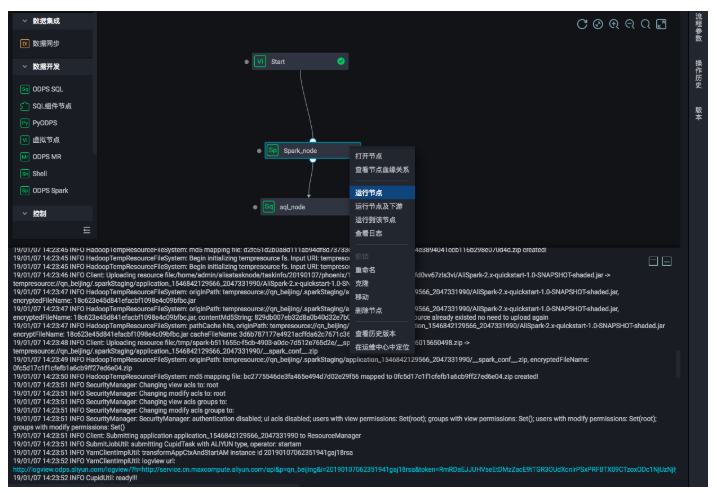
Spark作业定义完成后,即可以在业务流程中对不同类型服务进行编排、统一调度执行。
9. 作业诊断
提交作业后,需要根据作业日志来检查作业是否正常提交并执行,MaxCompute对于Spark作业提供了Logview工具以及Spark Web-UI来帮助开发者进行作业诊断。
例如,通过Spark-submit方式(dataworks执行spark任务时也会产生相应日志)提交作业,在作业日志中会打印以下关键内容:
cd $SPARK_HOME
bin/spark-submit --master yarn-cluster --class SparkPi /tmp/spark-2.x-demo/target/AliSpark-2.x-quickstart-1.0-SNAPSHOT-shaded.jar
作业提交成功后,MaxCompute会创建一个instance,在日志中会打印instance的logview:
19/01/05 20:36:47 INFO YarnClientImplUtil: logview url: http://logview.odps.aliyun.com/logview/?h=http://service.cn.maxcompute.aliyun.com/api&p=qn_beijing&i=20190105123647703gpqn26pr2&token=eG94TG1iTkZDSFErc1ZPcUZyTTdSWWQ3UE44PSxPRFBTX09CTzoxODc1NjUzNjIyNTQzMDYxLDE1NDY5NTEwMDcseyJTdGF0ZW1lbnQiOlt7IkFjdGlvbiI6WyJvZHBzOlJlYWQiXSwiRWZmZWN0IjoiQWxsb3ciLCJSZXNvdXJjZSI6WyJhY3M6b2RwczoqOnByb2plY3RzL3FuX2JlaWppbmcvaW5zdGFuY2VzLzIwMTkwMTA1MTIzNjQ3NzAzZ3BxbjI2cHIyIl19XSwiVmVyc2lvbiI6IjEifQ==
成功标准: <看到以下输出,可能会有其他日志一并输出>
19/01/05 20:37:34 INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 11.220.203.36
ApplicationMaster RPC port: 30002
queue: queue
start time: 1546691807945
final status: SUCCEEDED
tracking URL: http://jobview.odps.aliyun.com/proxyview/jobview/?h=http://service.cn.maxcompute.aliyun-inc.com/api&p=project_name&i=20190105123647703gpqn26pr2&t=spark&id=application_1546691794888_113905562&metaname=20190105123647703gpqn26pr2&token=TjhlQWswZTRpYWN2L3RuK25VeE5LVy9xSUNjPSxPRFBTX09CTzoxODc1NjUzNjIyNTQzMDYxLDE1NDY5NTEwMzcseyJTdGF0ZW1lbnQiOlt7IkFjdGlvbiI6WyJvZHBzOlJlYWQiXSwiRWZmZWN0IjoiQWxsb3ciLCJSZXNvdXJjZSI6WyJhY3M6b2RwczoqOnByb2plY3RzL3FuX2JlaWppbmcvaW5zdGFuY2VzLzIwMTkwMTA1MTIzNjQ3NzAzZ3BxbjI2cHIyIl19XSwiVmVyc2lvbiI6IjEifQ==
- 通过日志输出的logview在浏览器中可以查看CUPID类型的任务执行的基本信息。
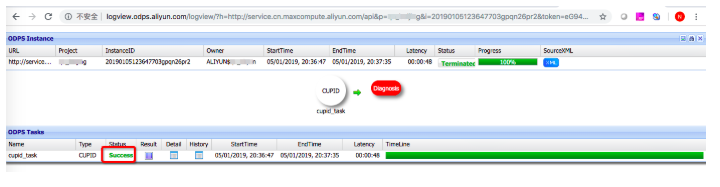
单击TaskName为
master-0任务条,在下方FuxiInstance栏中,通过
All按钮过滤后,
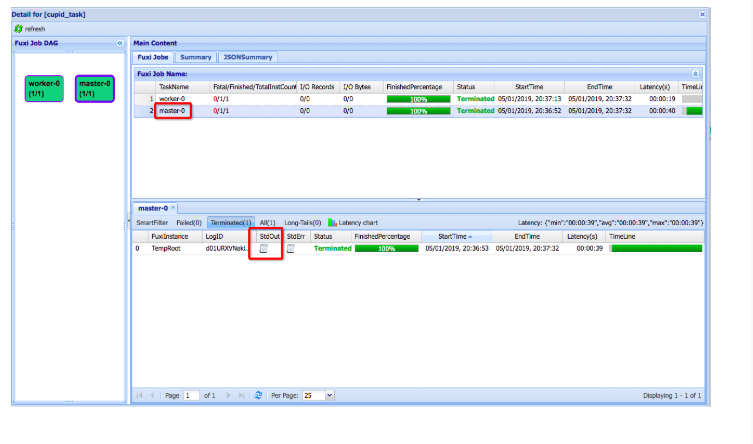
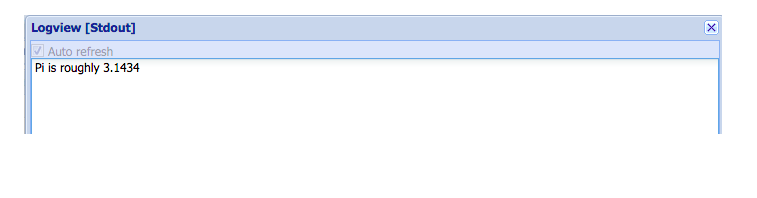
单击TempRoot的StdOut按钮可以查看SparkPi的输出结果:
- 日志中打印出上述的TrackingUrl,表示您的作业已经提交到MaxCompute集群,这个TrackingUrl非常关键,它既是SparkWebUI,也是HistoryServer的Url。在浏览器中打开这个Url,可以追踪Spark作业的运行情况。
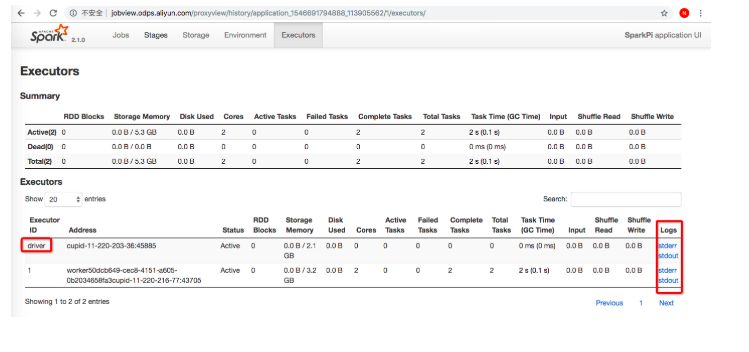
单击driver的stdout即可以查看Spark作业的输出内容。
更多的内容见MaxCompute产品官方地址:https://www.aliyun.com/product/odps
想了解更多阿里巴巴大数据计算服务MaxCompute,可以加入社群一起交流。