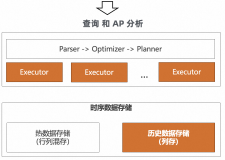
TableStore是阿里云自研的在线数据平台,提供高可靠的存储,实时和丰富的查询功能,适用于结构化、半结构化的海量数据存储以及各种查询、分析。
交通数据是一种数据规模大,实时性要求高的数据,数据的专业性极强,对社会生产的价值极大,我们接下来先看一下交通数据的场景和特征,我们仅以交通路口的车辆同行数据为例。
交通数据特点
数据量大
每个城市都有数以万计的交通路口,每时每刻都有车辆通过每个交通路口,这些交通路口的车辆实时数据,包括车牌、颜色、车速、位置、类型等,就是可以发挥重大价值的交通数据。假设一个城市有五千个交通路口,每个交通路口每秒同行1辆车,那么每秒就会产生5000行数据,每天就能产生5000 * 3600 * 24 = 4亿行数据,每个月就能产生120亿行数据,这个数据规模已经非常大。同时,这些数据对公安刑侦也有价值,保留时间越长越好,数据规模只会越来越大。
查询种类多
交通类的数据种类比较多,既包括了车辆信息(车牌、颜色、类型),也包括了车辆实时状态(车速、位置、时间),数据既包括了枚举类型,字符串,也包括地理位置。所以,对查询的需求就比较多,比如:
- 查询某一辆车过去十二个小时的行车路线(只要列出交通路况,就能画出行车路线)。
- 查找某个时间段经过某个交通路况的,白色私家轿车的列表。
- 查找某个银行(地点)附近5公里的交通路口,过去10分钟同行过的红色摩托车。
- 查找过去1分钟内,全市通行车辆最多的10个路口,以及通过的车辆数。
上述列举了三种查询,这三种查询涉及了好几种查询类型:
- 多字段自由组合查询。
- 范围查询。
- 地理位置查询。
- 统计聚合。
数据不能丢
交通数据除了用来调节城市交通外,还有一个重要作用是公安用来查询嫌疑车辆的通行情况,类似于我上面“查询种类多”中列举的第一种查询需求,这种场景下,每一辆经过交通路况的车辆信息都不能丢失,否则会影响刑侦判断和进展,可能会造成比较严重的后果。所以,整个系统对数据存储的可靠性,以及传输链路的可靠性要求都极高,尽力要做到不丢数据。
针对上述的场景需求,目前业内已经有多种解决方案,我们接下来看一下:
开源解决方案
一种很容易想到的方案是使用关系型数据库,比如MySQL或PostgreSQL存储,但是这种只适合存储小数据量,如果数据量超过单机存储能力,则会不适合。就算采用了分库分表的方式,也会带来极大的运维压力和产品功能牺牲。
另外一种方案,是从数据可靠性角度考虑,使用HBase等分布式NoSQL数据库,但是这种NoSQL数据库只提供单Key和Key前缀范围查询,无法支持按照其他属性列查询,无法满足我们上面的需求,就算引入Phoenix使用了二级索引,也需要提前固定好查询,无法支持自由组合,更无法支持地理位置查询。
还有一种方案,是从查询复杂度考虑,直接使用搜索引擎Elasticsearch或Solr,但是这种虽然能满足查询需求,可惜没法满足数据不能丢的要求,存在丢失数据的风险。
至此,考虑了所有开源系统后,没有一个系统能满足用户需求,那么只能退而求其次,采用组合大法:

- 存储系统使用HBase,保证数据可靠性。
- 同步方式采用Lily Indexer。
- 查询引擎使用solr系统。
上述架构方案,看起来满足了我们上面的所有需求,虽然麻烦了点。但是只能算是基本满足,因为这套架构存在比较大的问题:
- Lily indexer基于HBase的日志顺序,依赖一个时间戳,推送服务需要根据时间戳进行重排序再写入,在很多场景下难以做到严格的保序,可能会丢数据。
- 存量数据,以及solr中索引数据损坏后需要rebuild index时,需要使用运维人员通过工具去做,增加风险的同时还要只能整个系统的运维压力。
除此之外,还需要运维HBase、Lily index、Proxy和Solr四个系统,需要配备熟悉这四个开源系统的人员,这个又是一笔额外支出。除了开源解决方案外,如今又多了一种选择,使用云解决方案。
TableStore云解决方案
在现有的各种云产品中,能满足上述交通数据存储需求的系统并不多,阿里云TableStore是一款符合要求的系统,10年前就开始自研,多年的双十一、公有云客户的锤炼沉淀,保证了系统的可靠性和稳定性。
我们先来看一下基于TableStore存储交通数据的架构方案:

- 数据存储在TableStore中,TableStore可以提供10个9的数据可靠性保障,数据可靠性更高。
- 数据和索引都在一个系统里面,写入,读取都是通过同一套API写入和查询,易用性更高。
- 完全满足上述提出的查询需求,包括:
- 多字段自由组合查询。
- 范围查询。
- 地理位置查询。
- TableStore是分布式系统,可以水平扩展,目前生产环境单表最大有几十PB,每秒写入有几千万行,完全能胜任任何大数据的写入和存储。
示例
接下来,我们举个例子帮助读者理解。
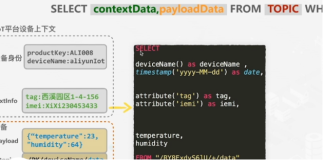
某个城市在每一个交通路口安装了摄像头,记录通过每个路口的实时车辆信息,包括车牌、车颜色、车类型(救护车、消防车、公交车、私家轿车等)、车速、时间、路口位置、路口名称。
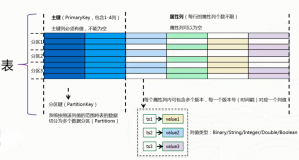
首先,我们设计TableStore中主表结构:
| 主键列 |
主键列 |
主键列 |
属性列 |
属性列 |
属性列 |
属性列 |
属性列 |
| 路口ID |
时间戳 |
车牌 |
车颜色 |
车类型 |
车速 |
路口名称 |
路口位置 |
| String |
String |
String |
String |
String |
Double |
String |
String |
| 10001 |
1551340084 |
浙A. XXXXX |
蓝色 |
私家轿车 |
42.5 |
西湖区余杭塘路五常港路口 |
[30.295,120.059] |
上述主表结构中,只能支持查询某个路口过去一段时间内的车辆通行列表,或者每个路口实时的车辆通行情况。
另外,这种表中,我们把路口的信息,包括路口名称、路口位置等也存在了每辆车通行信息中,这样带来的好处是查询的时候简单,只需要查询单个系统即可,但是也带来了数据冗余,有时候也会将这部分数据单独存储。
接下来,我们定义TableStore多元索引的结构:
| 列 |
列 |
列 |
列 |
列 |
列 |
列 |
| 时间戳 |
车牌 |
车颜色 |
车类型 |
车速 |
路口名称 |
路口位置 |
| String |
String |
String |
String |
Double |
Text:单字分词 |
GeoPoint |
- 时间戳、车牌、车颜色、车类型都是String,其中车牌可以支持模糊查询和前缀查询。
- 车速是浮点数。
- 路口名称采用了Text类型, 支持分词,分词使用了单字分词,这样通过查询“余杭塘河路”就能查询到“花蒋路和余杭塘路”,这里不要采用其他分词方式,因为其他分词方式总会有bad case,会导致某些查询不到。
- 路口位置采用了GeoPoint类型,这个类型支持范围查询,比如某个点附近几公里内的车辆信息,同时也支持某个多边形范围内的车辆通行信息。
基于上述的表和index,我们就能满足上述提到的所有查询需求。另外,可能还有一些统计需求,比如统计每个路口过去二十小时的通行车辆数,或者统计过去一分钟通过车辆最多的前10个路口。
总结
至此,开源解决方案和TableStore云解决方案都介绍完了,使用了TableStore云解决方案后,能带来不少的收益。
减少运维负担
在TableStore解决方案中,用户只需要运维自己的应用程序,不需要运维任何的存储系统、查询系统和其他中间件,运维压力大大减少,同时也减少了运维方面的成本开支。
另外,TableStore是Serverless的服务化产品,用户也无需考虑运维,不需要关注扩容、水位等事项,只需要关注功能开发即可。
系统架构更简单
在开源解决方案中4个系统,而TableStore解决方案中只有1个系统,系统数减少后,系统架构会更简单,系统可能产生的风险会更少,系统的稳定性等会更高,可以提供更优质的服务体验。
减少时间成本
TableStore云架构方案相对于开源方案,系统更少,从零开始到上线需要的开发时间更少,同时,TableStore是serverless的云服务,全球多个区域即开即用,可以大大降低客户的开发上线的时间,提前将产品推出,抢先争取市场领先优势。
数据可靠性更高
在开源解决方案中,数据有可能会丢失,影响最终的业务,而在TableStore解决方案中,可以提供更高的可靠性,可以让数据不丢失,保障业务的准确执行。
最后
目前,已经有大量的业务在使用TableStore,后续我们会继续优化改进TableStore,为客户持续提供一款高性能、丰富功能、低成本、高可用性的分布式系统,为客户的海量数据保驾护航。