热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
Docker常见问题1: driver failed programming external connectivity on endpoint
【视频】随机波动率SV模型原理和Python对标普SP500股票指数预测|数据分享
sync修饰符-子组件修改父组件属性
PostgreSQL 递归查询(含层级和结构)
构建高效Android应用:内存优化实战指南
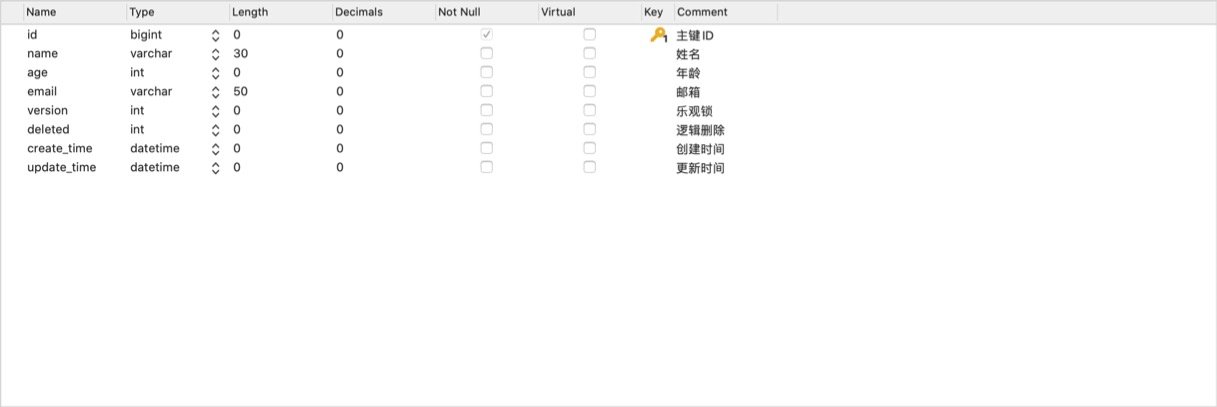
MybatisPlus入门(下)
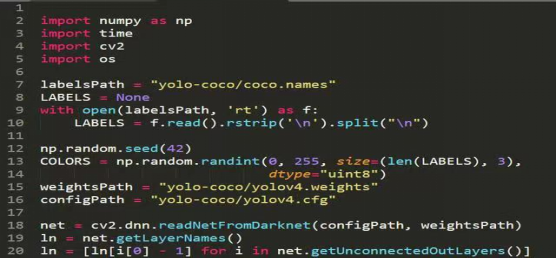
每天解析一个脚本(41)
MybatisPlus入门(中)
构建高效微服务架构:后端开发者的终极指南
MybatisPlus入门(上)
PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据|数据分享(下)
电子技术的魅力与奥秘
C++:编程语言的演变、应用与最佳实践
Linux Centos虚拟机扩容
Spring Boot解决跨域问题方法汇总
PYTHON银行机器学习:回归、随机森林、KNN近邻、决策树、高斯朴素贝叶斯、支持向量机SVM分析营销活动数据|数据分享(上)
C语言:编程世界的基础与魅力
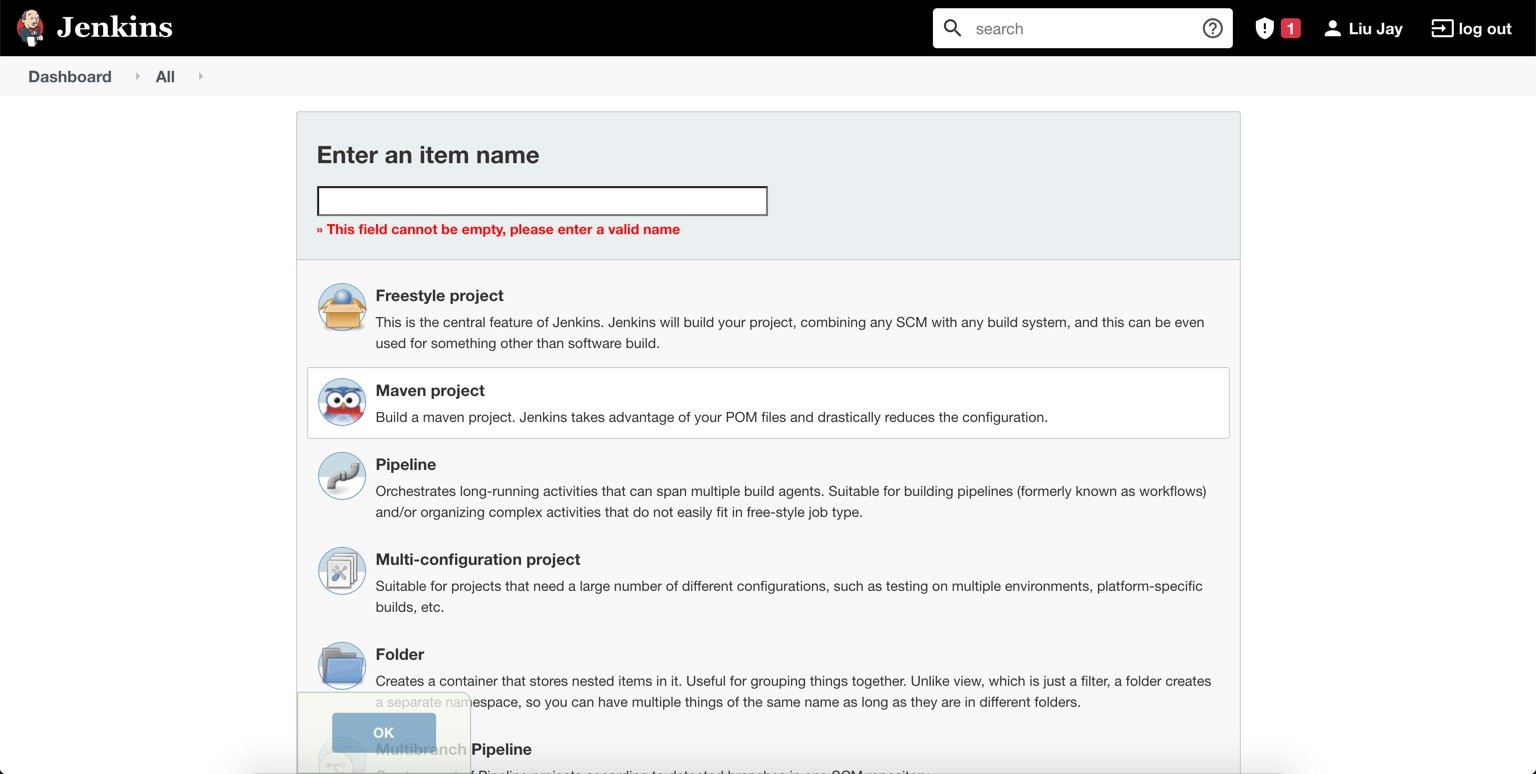
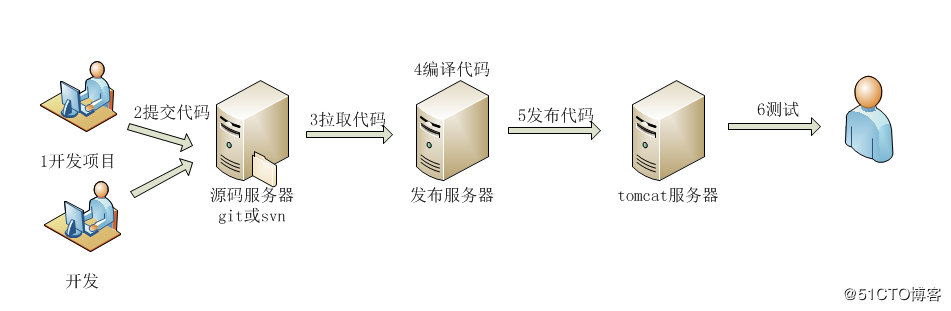
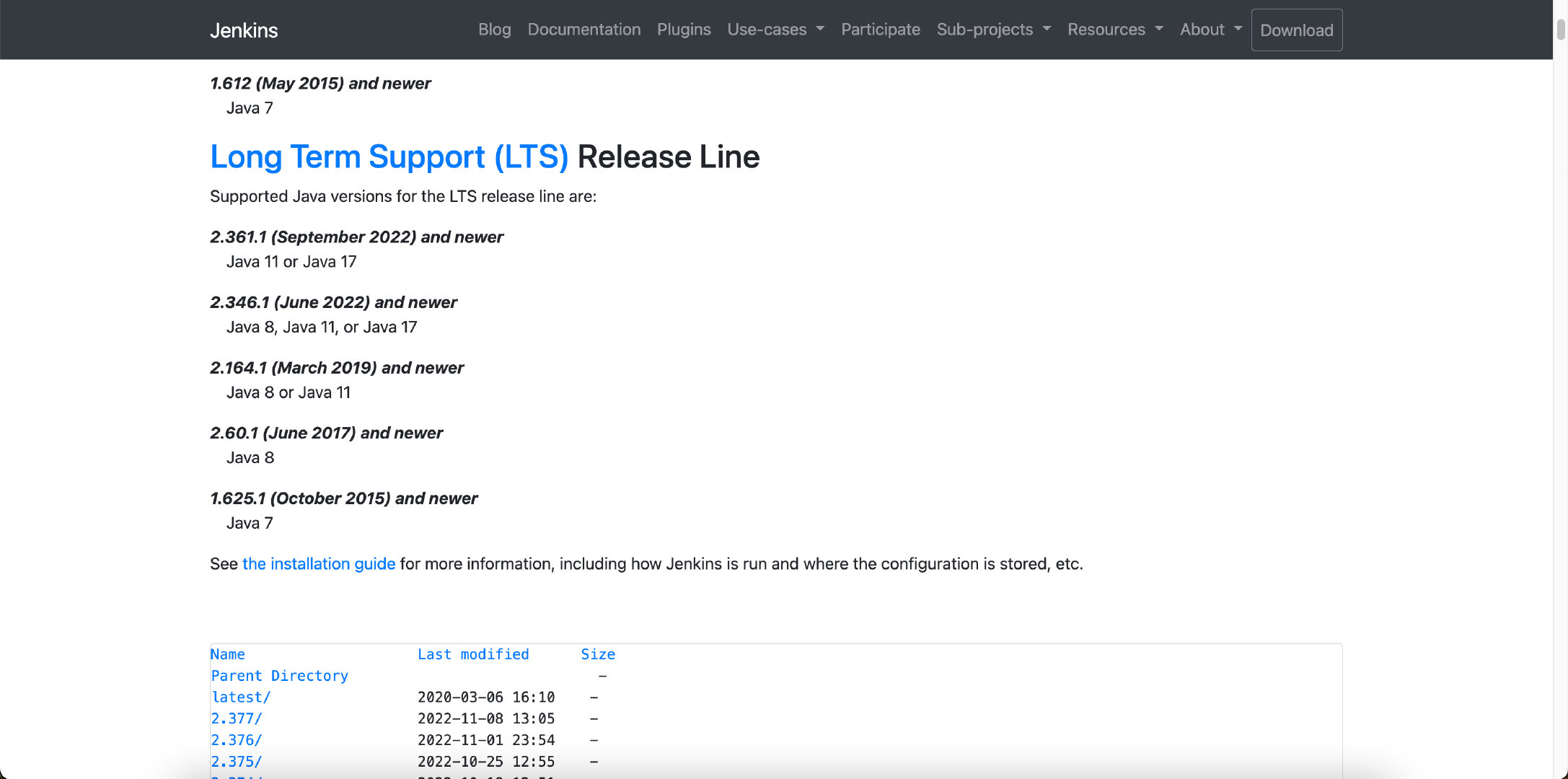
Jenkins 快速入门 (含Jenkins + Docker + Git 简单的自动化实操)(下)
Jenkins 快速入门 (含Jenkins + Docker + Git 简单的自动化实操)(上)
C语言:基础与应用的双重魅力
阿里云ClickHouse企业版正式商业化,为开发者提供容灾性更好、性价比更高的实时数仓
DSP:数字信号处理技术的魅力与应用
Jenkins 迁移及安装
EDA设计:从理论到实践
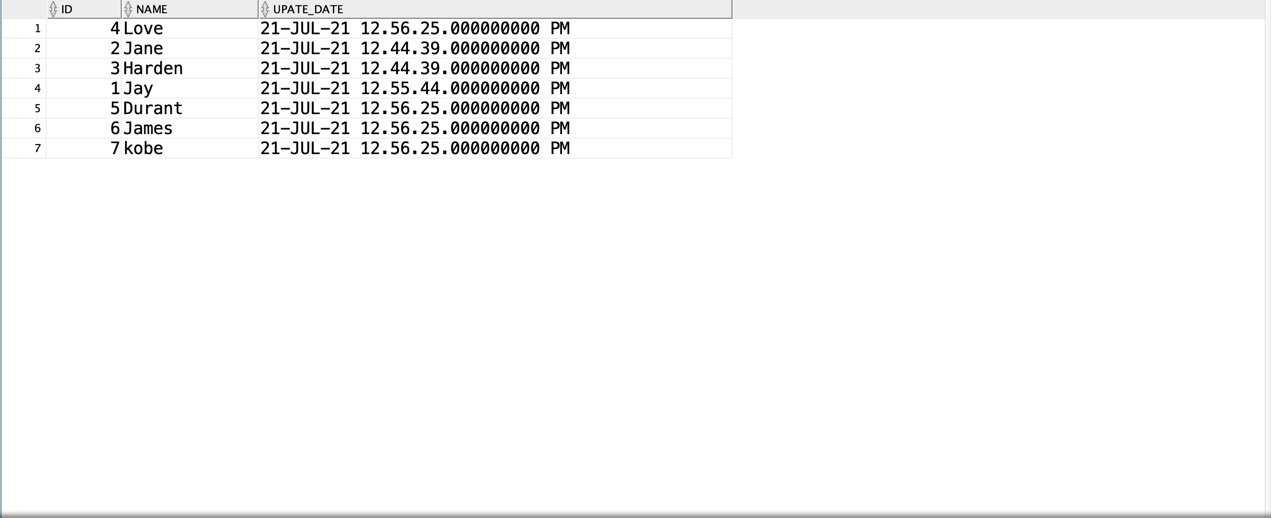
不小心删除表或数据后,如何利用Oracle的闪回进行恢复
探索移动应用开发的未来:跨平台框架与原生系统的挑战
即拼商城模式开发系统案例|即拼逻辑|
EDA设计:技术深度解析与实战代码应用
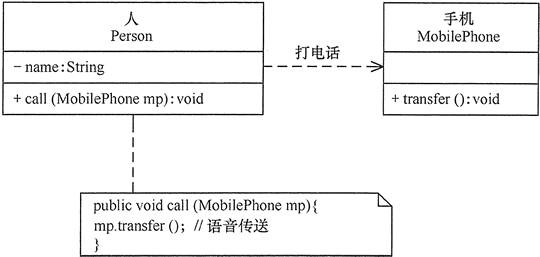
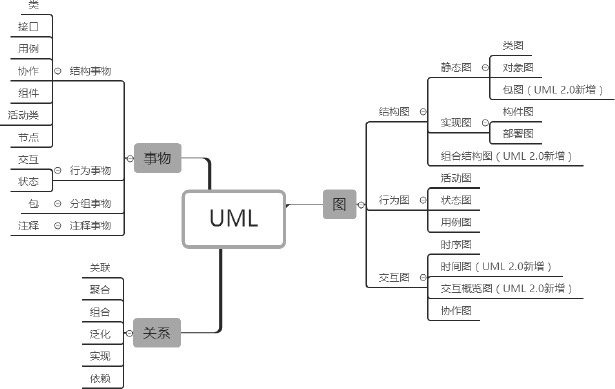
UML学习笔记(下)
构建高效机器学习模型的最佳实践
每天解析一个脚本(40)
EDA设计:探索与实现
UML学习笔记(上)
EDA设计:原理、应用与代码实践
Oracle PLM Agile936 单点登录配置方式
数据泵导出导入(映射表空间、Schema)
FPGA(现场可编程门阵列)技术概述及其应用实例
Linux 查询文件夹挂载点
Linux查找大文件的方法
Java之Lambda表达式的介绍
Java 构建树型结构
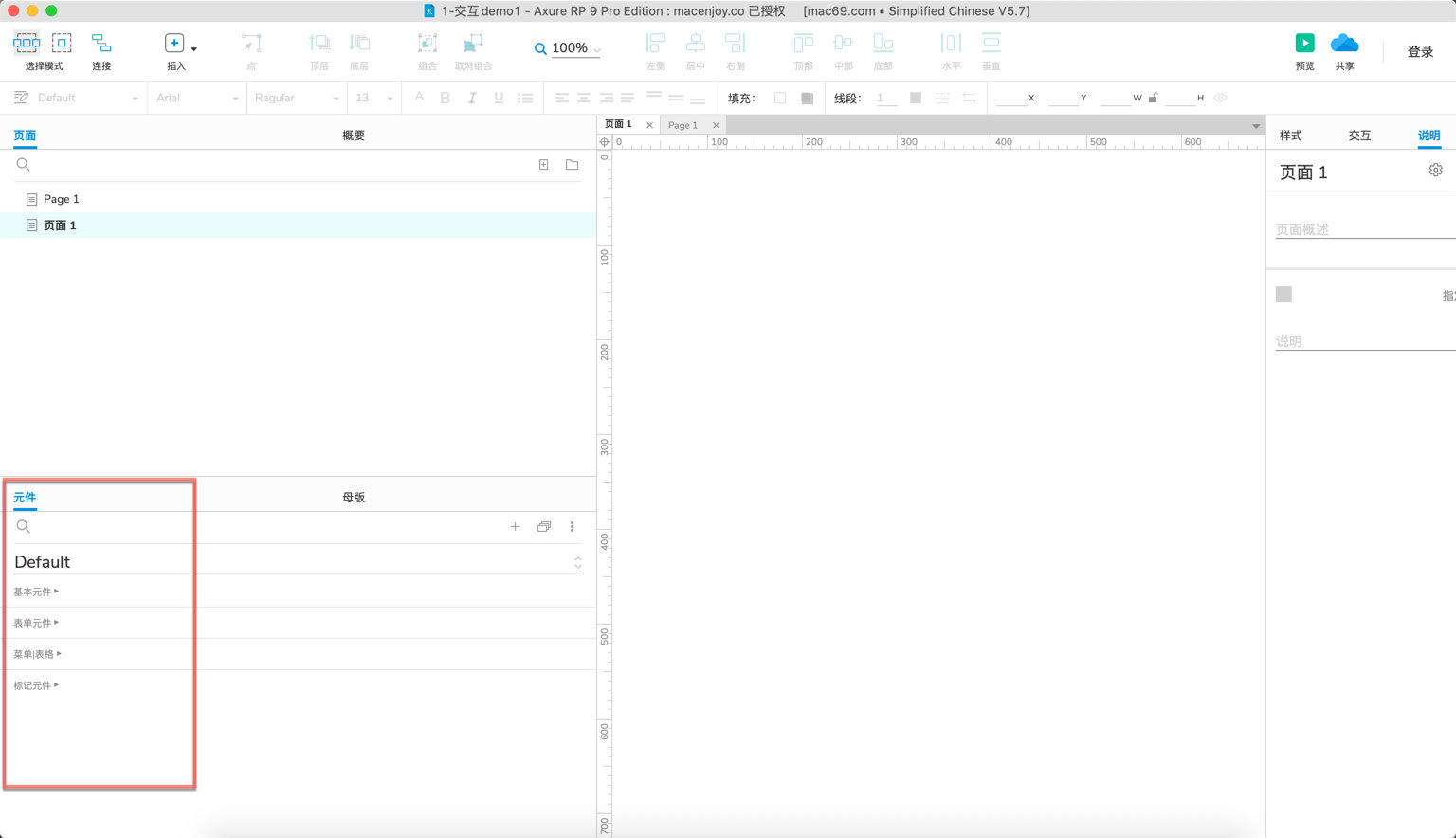
03-Axure9默认元件库
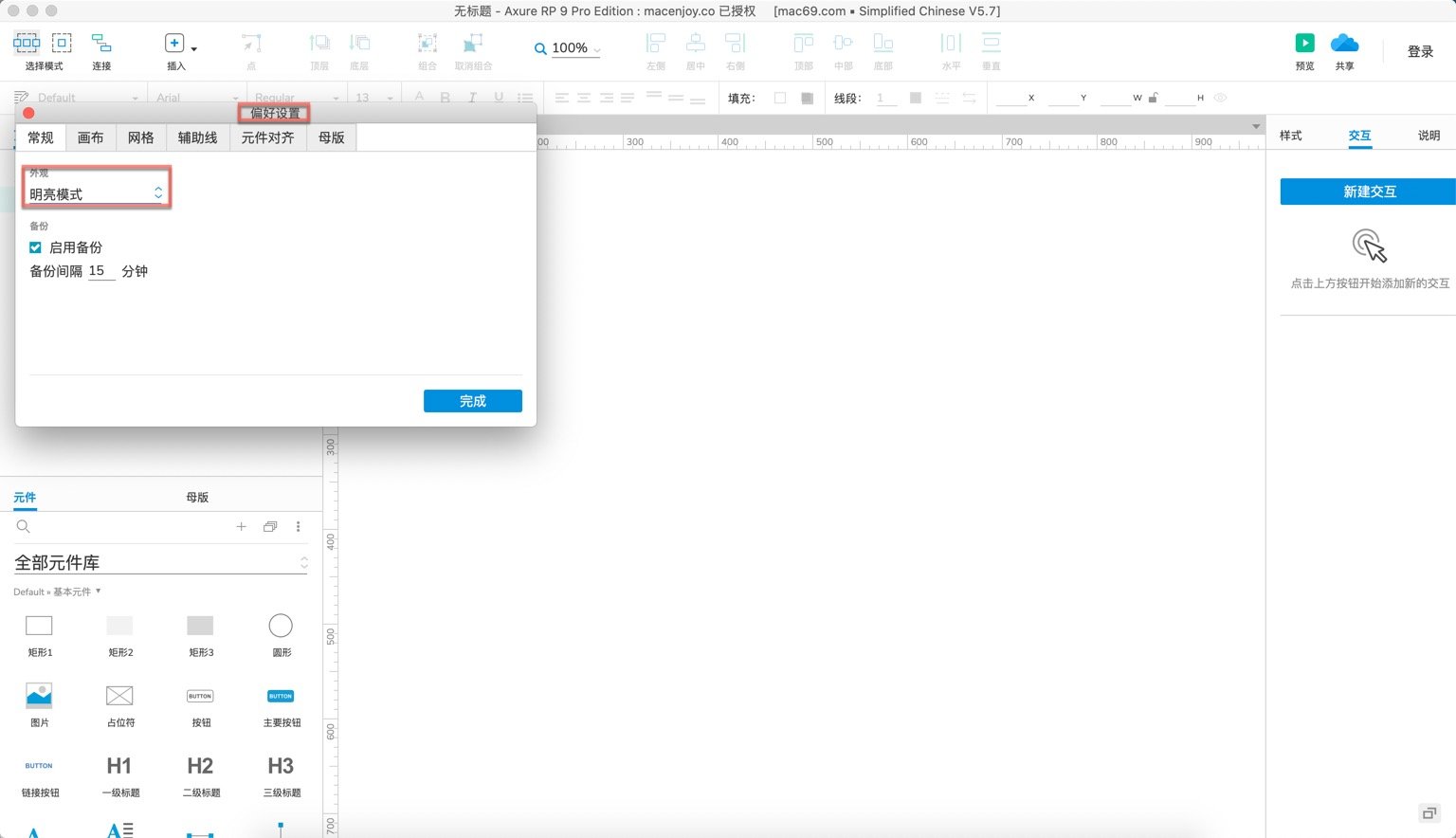
02-Axure9.0软件布局及介绍
未来技术的融合潮流:区块链、物联网与虚拟现实的交汇点
FPGA:可编程逻辑器件的新篇章
01-Axure9入门培训