业务的知名度越高,其背后技术团队承受的压力就越大。一旦出现技术问题,就有可能被放大,尤其是当服务的是对知识获取体验要求颇高的用户群体。
提供知识服务的罗辑思维主张“省时间的获取知识”,那么其技术团队在技术实践方面是如何践行省时间的理念的呢?本文将还原罗辑思维技术团队在全链路压测上的构建过程,为您一探究竟。
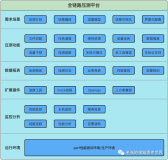
全链路压测知多少
保障服务的可用性和稳定性是技术团队面临的首要任务,也是技术难题之一。例如,罗辑思维提供的是知识服务,服务的是在高铁、地铁和公交车等场所利用碎片时间进行学习,在凌晨、深夜都有可能打开App,以及分布在海外的全球用户。这就需要得到App提供7*24的稳定高性能的服务和体验。
在实际生产环境中,用户的访问行为一旦发生,从CDN到接入层、前端应用、后端服务、缓存、存储、中间件整个链路都面临着不确定的流量,无论是公有云、专有云、混合云还是自建IDC,全局的瓶颈识别、业务整体容量摸底和规划都需要高仿真的全链路压测来检验。这里的不确定的流量指的是某个大促活动、常规高并发时间段以及其他规划外的场景引起的不规则、大小未知的流量。
众所周知,应用的服务状态除了会受到自身稳定性的影响,还会受到流量等环境因素的影响,并且影响面会继续传递到上下游,哪怕一个环节出现一点误差,误差在上下游经过几层累积后会造成什么影响谁都无法确定。
因此,在生产环境里建立起一套验证机制,来验证各个生产环节都是能经受住各类流量的访问,成为保障服务的可用性和稳定性的重中之重。最佳的验证方法就是让事件提前发生,即让真实的流量来访问生产环境,实现全方位的真实业务场景模拟,确保各个环节的性能、容量和稳定性均做到万无一失,这就是全链路压测的诞生背景,也是将性能测试进行全方位的升级,使其具备“预见能力”。

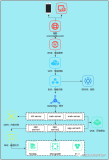
业务压测实施路径
可见,全链路压测做得好,遇到真实环境的流量,系统仅仅只是再经历一次已经被反复验证过的场景,再考一遍做“做过的考题”,不出问题在意料之中将成为可能。
压测的核心要素
实施完整的业务压测,路径很重要。

要达成精准衡量业务承接能力的目标,业务压测就需要做到一样的线上环境、一样的用户规模、一样的业务场景、一样的业务量级和一样的流量来源,让系统提前进行“模拟考”,从而达到精准衡量业务模型实际处理能力的目标,其核心要素是:压测环境、压测基础数据、压测流量(模型、数据)、流量发起、掌控和问题定位。

压测环境和压测基础数据
生产环境上基础数据基本分为两种方式,一种是数据库层面不需要做改造,直接基于基础表里的测试账户(相关的数据完整性也要具备)进行,压测之后将相关的测试产生的流水数据清除(清除的方式可以固化SQL脚本或者落在系统上);另一种就是压测流量单独打标(如单独定义的Header),然后业务处理过程中识别这个标并传递下去,包括异步消息和中间件,最终落到数据库的影子表或者影子库中。这种方式详见阿里的全链路压测实践,我们也是选用了这种方式。此外,生产环境的压测尽量在业务低峰期进行从而避免影响生产的业务。
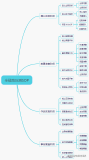
全链路压测的构建过程
目前,罗辑思维已经提供了得到APP、少年得到、和微信公众号得到里的得到商城等多个流量入口。
每一年,罗辑思维都会举办跨年演讲,第一年是在优酷,有200多万人的在线观看,第二年是在深圳卫视合作直播,并在优酷等视频网站同步,直播过程中当二维码放出来的时候,我们就遇到了大量的用户请求,在同一时刻。这就意味着,如果没有对这个期间的流量做好准确的预估,评估好性能瓶颈,那么在直播过程中就有可能出现大面积服务中断。

对整体系统进行全链路压测,从而有效保障每个流量入口的服务稳定性成为技术团队的当务之急。因此,我们在2017年,计划引入全链路压测。期间,也对系统做了服务化改造,对于服务化改造的内容之前在媒体上传播过,这次我们主要是讲下保障服务稳定性的核心 - 全链路压测。大致的构建过程如下:
- 2017年10月
启动全链路压测项目,完成商城的首页、详情、购物车、下单的改造方案设计、落地、基础数据准备和接入,以及得到APP首页和核心功能相关的所有读接口接入,并在进行了得到APP的第一次读接口的全链路压测。
- 2017年11月
商城核心业务和活动形态相对稳定,进入全面的压测&攻坚提升期,同时拉新、下单和支付改造开始,得到APP开始进入写改造,活动形态初具雏形,读写覆盖范围已经覆盖首页、听书、订阅、已购、拉新、知识账本,并启动用户中心侧用户部分的底层改造,包括短信等三方的业务挡板开发。
- 2017年12月
商城进行最后的支付改造补齐,然后是全链路压测&优化的整体迭代;得到APP全链路压测接入范围继续增加,覆盖全部首页范围和下侧5个tab,同时开始部分模块组合压测和性能调优的迭代;完成底层支付和用户中心配合改造,以及支付和短信所有外部调用的挡板改造;行了多轮次的全链路形态完整压测,并从中发现发现,给予问题定位,提升体系稳定性;梳理对焦了风险识别、预案和值班等等。
经过3个多月的集中实施,我们将全链路压测接入链路174个,创建44个场景,压测消耗VUM1.2亿,发现各类问题200多个。
如果说2017年全链路压测的设施在罗辑是从0到1,那么2018年就是从1到N了。
从2018年开始,全链路压测进入比较成熟的阶段,我们的测试团队基于PTS和之前的经验,迅速地将全链路压测应用于日常活动和跨年活动中,并应用于新推出的业务「少年得到」上。目前,全链路压测已经成为保障业务稳定性的核心基础设施之一。
全链路压测的构建与其说是一个项目,不如说是一项工程。仅凭我们自己的技术积累和人员配置是无法完成的,在此特别感谢阿里云PTS及其他技术团队提供的支持,帮助我们将全链路压测在罗辑思维进行落地。下面我们将落地过程中积累的经验以工作笔记的方式分享给大家。
工作笔记
A. 流量模型的确定:
流量较大的时候可以通过日志和监控快速确定。但是往往可能日常的峰值没有那么高,但是要应对的一个活动却有很大的流量,有个方法是可以基于业务峰值的一个时间段内统计各接口的峰值,最后拼装成压测的流量模型。
B. 脏数据的问题:
无论是通过生产环境改造识别压测流量的方式还是在生产环境使用测试帐号的方式,都有可能出现产生脏数据的问题,最好的办法是:
- 在仿真环境或者性能环境多校验多测试:
有个仿真环境非常重要,很多问题的跟进、复现和debug不需要再上生产环境,降低风险。
- 有多重机制保障:
比如对了压测流量单独打标还需要UID有较强的区分度,关键数据及时做好备份等等。
C. 监控:
由于是全链路压测,目的就是全面的识别和发现问题,所以要求监控的覆盖度很高。从网络接入到数据库,从网络4层到7层和业务的,随着压测的深入,你会发现监控总是不够用。
D. 压测的扩展:
比如我们会用压测进行一些技术选型的比对,这个时候要确保是同样的流量模型和量级,可以通过全链路压测测试自动扩容或者是预案性质的手工扩容的速度和稳定性。在全链路压测的后期,也要进行重要的比如限流能力的检验和各种故障影响的实际检验和预案的演练。
E. 网络接入:
如果网络接入的节点较多,可以分别做一些DIS再压测,逐个确定能力和排除问题,然后整体enable之后再一起压测确定整体的设置和搭配上是否有能力对不齐的情况。
比如,网络上使用了CDN动态加速、WAF、高防、SLB等等,如果整体压测效果不理想的时候建议屏蔽掉一些环节进行压测,收敛问题,常见的比如WAF和SLB之间的会话保持可能带来负载不匀的问题。当然这些产品本身的容量和规格也是需要压测和验证的,如SLB的CPS、QPS、带宽、连接数都有可能成为瓶颈,通过在PTS的压测场景中集成相关SLB监控可以方便地一站式查看,结合压测也可以更好的选择成本最低的使用方式。
另外负载不匀除了前面说的网络接入这块的,内部做硬负载的Nginx的负载也有可能出现不匀的现象,特别是在高并发流量下有可能出现,这也是全链路、高仿真压测的价值。
特别是一些重要活动的压测,建议要做一下业务中会真实出现的流量脉冲的情况。
阿里云PTS是具备这个能力的,可以在逐级递增满足容量的背景下再观察下峰值脉冲的系统表现,比如验证限流能力,以及看看峰值脉冲会不会被识别为DDOS。
F. 参数调优:
压测之后肯定会发现大量的参数设置不合理,我们的调优主要涉及到了这些:内核网络参数调整(比如快速回收连接)、Nginx的常见参数调优、PHP-FPM的参数调整等等,这些网上相关的资料非常多。
G. 缓存和数据库:
- 重要业务是否有缓存;
- Redis CPU过高可以重点看下是否有模糊匹配、短连接的不合理使用、高时间复杂度的指令的使用、实时或准实时持久化操作等等。同时,可以考虑升级Redis到集群版,另外对于热点数据考虑Local Cache的优化机制(活动形态由于K-V很少,适合考虑Local Cache);
- 重要数据库随着压测的进行和问题的发现,可能会有索引不全的情况;
H. Mock服务:
一般在短信下发、支付环节上会依赖第三方,压测涉及到这里的时候一般需要做一些特殊处理,比如搭建单独的Mock服务,然后将压测流量路由过来。这个Mock服务涉及了第三方服务的模拟,所以需要尽量真实,比如模拟的延迟要接近真正的三方服务。当然这个Mock服务很可能会出现瓶颈,要确保其容量和高并发下的接口延时的稳定性,毕竟一些第三方支付和短信接口的容量、限流和稳定性都是比较好的。
I. 压测时系统的CPU阈值和业务SLA
我们的经验是CPU的建议阈值在50到70%之间,主要是考虑到容器的环境的因素。然后由于是互联网性质的业务,所以响应时间也是将1秒作为上限,同时压测的时候也会进行同步的手工体感的实际测试检查体验。(详细的指标的解读和阈值可以点击阅读原文)
J. 其他
- 限流即使生效了,也需要在主要客户端版本上的check是否限流之后的提示和体验是否符合预期,这个很重要;
- 全链路压测主要覆盖核心的各种接口,除此以外的接口也要有一定的保护机制,比如有默认的限流阈值,确保不会出现非核心接口由于预期外流量或者评估不足的流量导致核心系统容量不足(如果是Java技术栈可以了解下开源的Sentinel或者阿里云上免费的限流工具 AHAS)
- 核心的应用在物理机层面要分开部署;
省时间的技术理念
目前,全链路压测已成为罗辑思维的核心技术设施之一,大幅提升了业务的稳定性。借助阿里云PTS,全链路压测的自动化程度得以进一步提高,加速了构建进程、降低了人力投入。我们非常关注技术团队的效率和专注度,不仅是全链路压测体系的构建,还包括其他很多业务层面的系统建设,我们都借助了合作伙伴的技术力量,在可控时间内支撑起业务的快速发展。
当业务跑的快的时候,技术建设的路径和方式,是团队的基础调性决定的。