1.概述
TimescaleDB是Timescale Inc.(成立于2015年)开发的一款号称兼容全SQL的 时序数据库 。它的本质是一个基于 PostgreSQL(以下简称 PG )的扩展( Extension ),主打的卖点如下:
- 全SQL支持
- 背靠PostgreSQL的高可靠性
- 时序数据的高写入性能
下文将对TimescaleDB这个产品进行解读。如无特殊说明,这里所说的TimescaleDB均是指Github上开源的单机版TimescleDB的v1.1版本。
2.数据模型
由于TimescaleDB的根基还是PG,因此它的数据模型与NoSQL的时序数据库(如我们的阿里时序时空TSDB,InfluxDB等)截然不同。
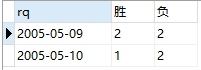
在NoSQL的时序数据库中,数据模型通常如下所示,即一条数据中既包括了时间戳以及采集的数据,还包括设备的元数据(通常以 Tagset 体现)。数据模型如下所示:

但是在TimescaleDB中,数据模型必须以一个二维表的形式呈现,这就需要用户结合自己使用时序数据的业务场景,自行设计定义二维表。
在TimescaleDB的官方文档中,对于如何设计时序数据的数据表,给出了两个范式:
- Narrow Table
- Wide Table
所谓的 Narrow Table 就是将metric分开记录,一行记录只包含一个 metricValue - timestamp 。举例如下:
| metric名 | 属性1 | 属性2 | 属性3 | metric名 | 时间戳 |
|---|---|---|---|---|---|
| free_mem | 设备1属性1值 | 设备1属性2值 | 设备3属性3值 | xxxxxxx | timestamp1 |
| free_mem | 设备2属性1值 | 设备2属性2值 | 设备2属性3值 | xxxxxxx | timestamp1 |
| free_mem | 设备3属性1值 | 设备3属性2值 | 设备3属性3值 | xxxxxxx | timestamp1 |
| temperature | 设备1属性1值 | 设备1属性2值 | 设备3属性3值 | △△△△△△△ | timestamp1 |
| temperature | 设备2属性1值 | 设备2属性2值 | 设备2属性3值 | △△△△△△△ | timestamp1 |
| temperature | 设备3属性1值 | 设备3属性2值 | 设备3属性3值 | △△△△△△△ | timestamp1 |
而所谓的 Wide Table 就是以时间戳为轴线,将同一设备的多个metric记录在同一行,至于设备一些属性(元数据)则只是作为记录的辅助数据,甚至可直接记录在别的表(之后需要时通过 JOIN 语句进行查询)
| 时间戳 | 属性1 | 属性2 | 属性3 | metric名1 | metric名2 | metric名3 |
|---|---|---|---|---|---|---|
| timestamp1 | 设备1属性1值 | 设备1属性2值 | 设备1属性3值 | metric值1 | metric值2 | metric值3 |
| timestamp2 | 设备2属性1值 | 设备2属性2值 | 设备2属性3值 | metric值1 | metric值2 | metric值3 |
基本上可以认为: Narrow Table 对应的就是 单值模型 ,而Wide Table对应的就是 多值模型
由于采用的是传统数据库的关系表的模型,所以TimescaleDB的metric值必然是强类型的,它的类型可以是PostgreSQL中的 数值类型 , 字符串类型 等。
3.TimescaleDB的特性
TimescaleDB在PostgreSQL的基础之上做了一系列扩展,主要涵盖以下方面:
- 时序数据表的透明自动分区特性
- 提供了若干面向时序数据应用场景的特殊SQL接口
- 针对时序数据的写入和查询对PostgreSQL的 Planner 进行扩展
- 面向时序数据表的定制化并行查询
其中 3 和 4 都是在PostgreSQL的现有机制上进行的面向时序数据场景的微创新。因此下文将主要对上述的 1 和 2 稍加展开说明
透明自动分区特性
在时序数据的应用场景下,其记录数往往是非常庞大的,很容易就达到 数以billion计 。而对于PG来说,由于大量的还是使用B+tree索引,所以当数据量到达一定量级后其写入性能就会出现明显的下降(这通常是由于索引本身变得非常庞大且复杂)。这样的性能下降对于时序数据的应用场景而言是不能忍受的,而TimescaleDB最核心的 自动分区 特性需要解决就是这个问题。这个特性希望达到的目标如下:
- 随着数据写入的不断增加,将时序数据表的数据分区存放,保证每一个分区的索引维持在一个较小规模,从而维持住写入性能
- 基于时序数据的查询场景,自动分区时以时序数据的时间戳为分区键,从而确保查询时可以快速定位到所需的数据分区,保证查询性能
- 分区过程对用户透明,从而达到Auto-Scalability的效果
TimescaleDB对于自动分区的实现,主要是基于PG的表继承机制进行的实现。TimescaleDB的自动分区机制概要可参见下图:
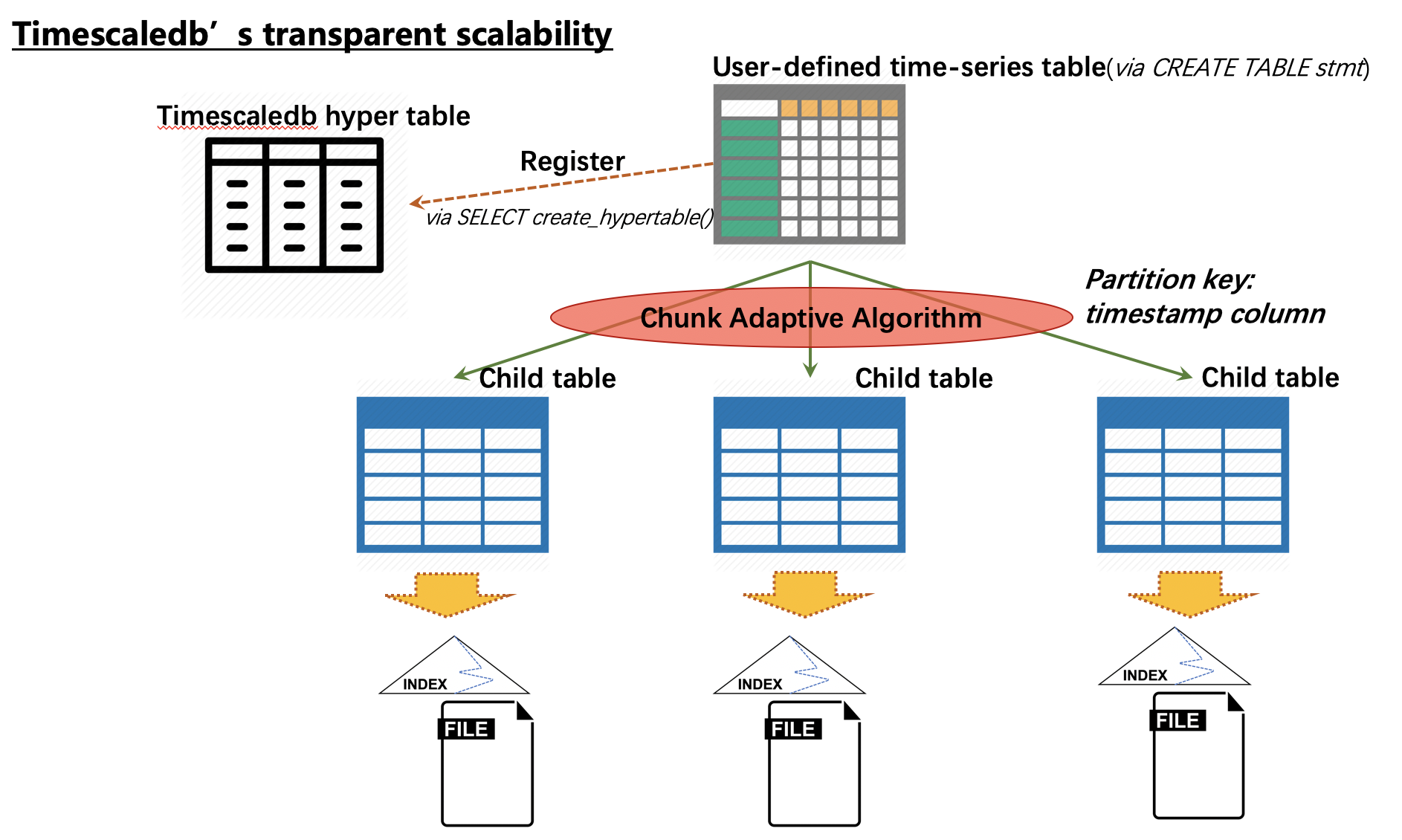
在这个机制下, 用户创建了一张普通的时序表后,通过TimescaleDB的接口进行了hyper table注册后,后续的数据写入和查询操作事实上就由TimescaleDB接手了。上图中,用户创建的原始表一般被称为“主表”(main table), 而由TimescaleDB创建出的隐藏的子表一般被称为“chunk”
需要注意的是,chunk是伴随着数据写入而自动创建的,每次创建新的chunk时会计算这个chunk预计覆盖的时间戳范围(默认是 一周 )。且为了考虑到不同应用场景下,时序数据写入速度及密度都不相同,对于创建新分区时,新分区的时间戳范围会经过一个自适应算法进行计算,以便逐渐计算出某个应用场景下最适合的时间戳范围。与PG 10.0
自适应算法的详细实现位于TimescaleDB的chunk_adaptive.c的ts_calculate_chunk_interval(),其基本思路就是基于历史chunk的 时间戳填充因子 以及 文件尺寸填充因子 进行合理推算下一个chunk应该按什么时间戳范围来进行界定。
借助 透明化自动分区 的特性,根据官方的测试结果,在同样的数据量级下,TimescaleDB的写入性能与PG的 传统单表 写入场景相比,即使随着数量级的不断增大,性能也能维持在一个比较稳定的状态。
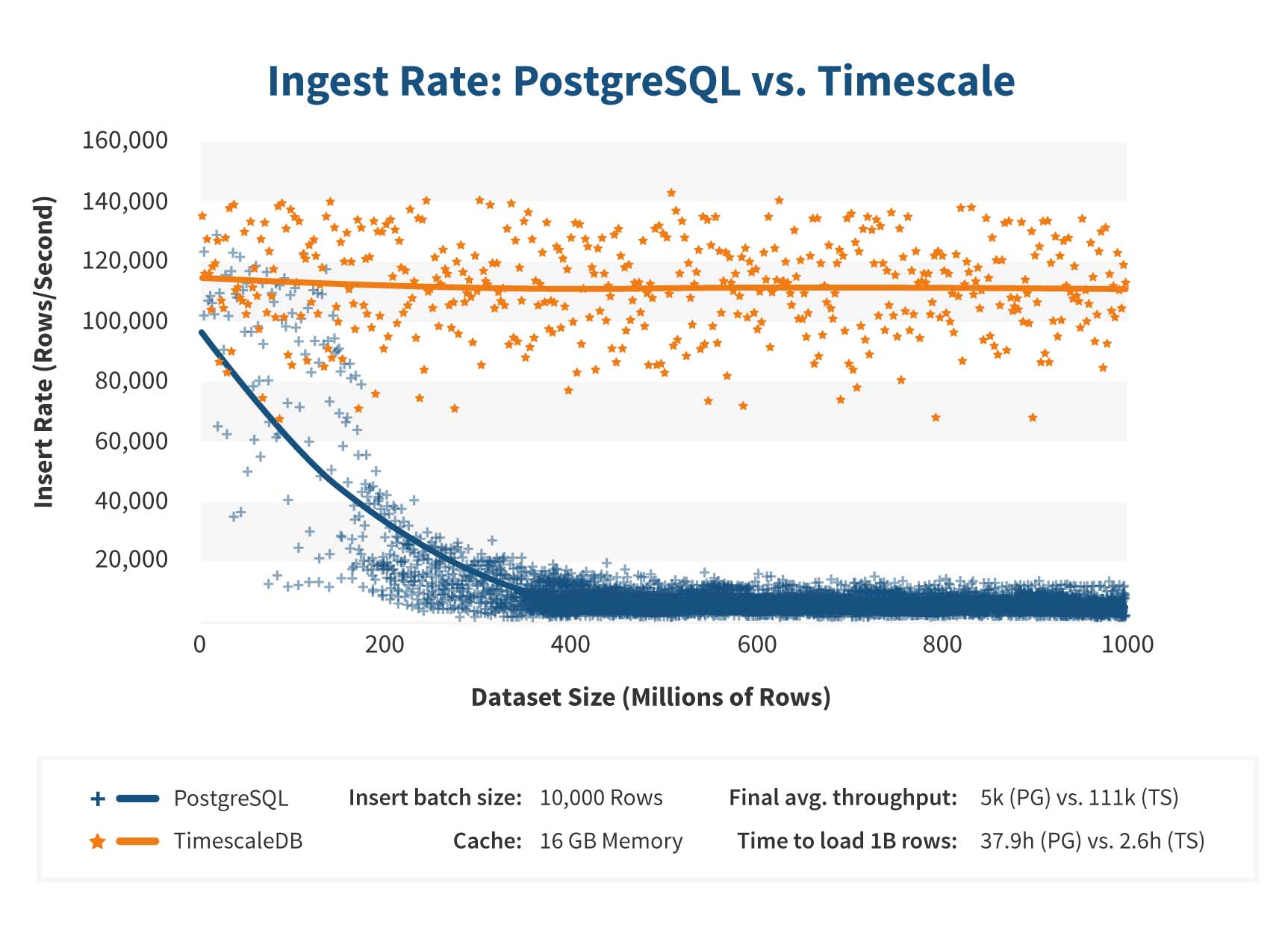
注: 上述Benchmark测试结果摘自Timescale官网
面向时序场景的定制功能
TimescaleDB的对外接口就是SQL,它100%地继承了PG所支持的全部SQL特性。除此之外,面向时序数据库的使用场景,它也定制了一些接口供用户在应用中使用,而这些接口都是通过 SQL函数(标准名称为 User-defined Function)予以呈现的。以下列举了一些这类接口的例子:
-
time_bucket()函数该函数用于 降采样 查询时使用,通过该函数指定一个时间间隔,从而将时序数据按指定的间隔降采样,并辅以所需的聚合函数从而实现降采样查询。一个示例语句如下:
SELECT time_bucket('5 minutes', time) AS five_min, avg(cpu) FROM metrics GROUP BY five_min ORDER BY five_min DESC LIMIT 10;将数据点按5分钟为单位做降采样求均值
-
新增的聚合函数
为了提供对时序数据进行多样性地分析查询,TimescaleDB提供了下述新的聚合函数。
-
first()求被聚合的一组数据中的第一个值 -
last()求被聚合的一组数据中的最后一个值 -
histogram()求被聚合的一组数据中值分布的直方图
注: 新增的聚合函数在非时序场景也可以使用
-
-
drop_chunks()
删除指定时间点之前/之后的数据chunk. 比如删除三个月时间前的所有chunk等等。这个接口可以用来类比 InfluxDB 的 Retention Policies 特性,但是目前TimescaleDB尚未实现自动执行的chunk删除。若需要完整的 Retention Policies 特性,需要使用系统级的定时任务(如 crontab)加上drop_chunks()语句来实现。drop_chunks()的示例语句如下。含义是删除conditions表中所有距今三个月之前以及四个月之后的数据分区:SELECT drop_chunks(older_than => interval '3 months', newer_than => interval '4 months', table_name => 'conditions');
除此之外,TimescaleDB定制的一些接口基本都是方便数据库管理员对元数据进行管理的相关接口,在此就不赘述。包括以上接口在内的定义和示例可参见官方的API文档
4.TimescaleDB的存储机制
TimescaleDB对PG的存储引擎未做任何变更,因此其索引数据和表数据的存储都是沿用的PG的存储。而且,TimescaleDB给chunk上索引时,都是使用的默认的B+tree索引,因此每一个chunk中数据的存储机制可以参见下图:
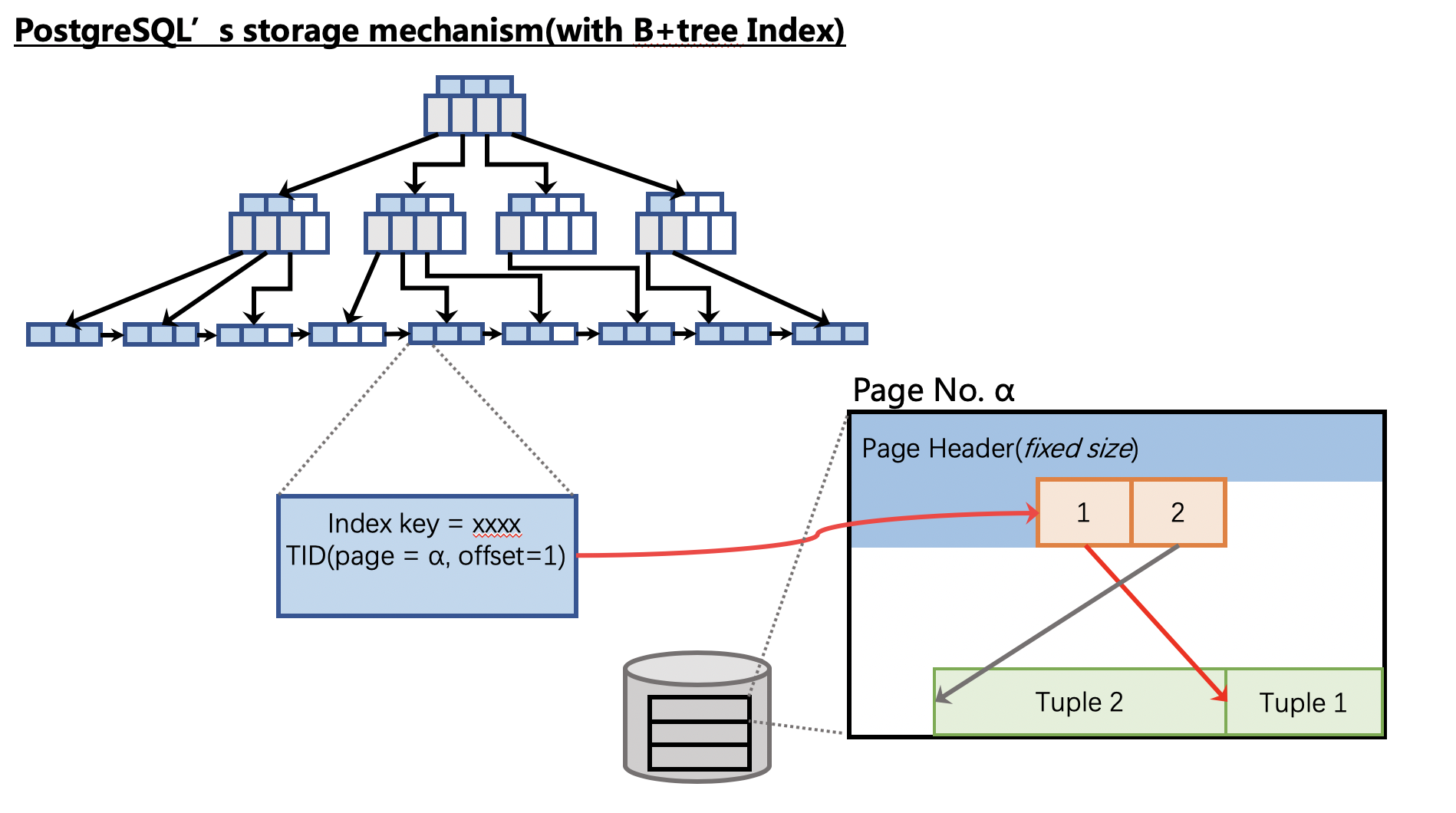
关于这套存储机制本身不用过多解释,毕竟TimescaleDB对其没有改动。不过考虑到时序数据库的使用场景,可以发现TimescaleDB的Chunk采用这套机制是比较合适的:
-
PG存储的特征是 只增不改 ,即无论是数据的插入还是变更。体现在Heap Tuple中都是Tuple的Append操作。因此这个存储引擎在用于OLTP场景下的普通数据表时,会存在表膨胀问题;而在时序数据的应用场景中,时序数据正常情况下不会被更新或删除,因此可以避免表膨胀问题(当然,由于时序数据本身写入量很大,所以也可以认为海量数据被写入的情况下单表实际上仍然出现了膨胀,但这不是此处讨论的问题)
-
在原生的PG中,为了解决表膨胀问题,所以PG内存在 AUTOVACUUM 机制,即自动清理表中因更新/删除操作而产生的“Dead Tuple”,但是这将会引入一个新的问题,即AUTOVACUUM执行时会对表加共享锁从而对写入性能的影响。但是在时序数据的应用场景中,由于没有更新/删除的场景,也就不会存在“Dead Tuple“,因此这样的Chunk表就不会成为AUTOVACUUM的对象,因此INSERT性能便不会受到来自这方面的影响。
至于对海量数据插入后表和索引增大的问题,这正好通过上述的 自动分区 特性进行了规避。
此外,由于TimescaleDB完全基于PG的存储引擎,对于 WAL 也未做任何修改。因此TimescaleDB的高可用集群方案也可基于PG的流复制技术进行搭建。TimescaleDB官方也介绍了一些基于开源组件的HA方案
5.小结
综上所述,由于TimescaleDB完全基于PostgreSQL构建而成,因此它具有若干与生俱来的 优势 :
- 100%继承PostgreSQL的生态。且由于完整支持SQL,对于未接触过时序数据的初学者反而更有吸引力
- 由于PostgreSQL的品质值得信赖,因此TimescaleDB在质量和稳定性上拥有品牌优势
- 强ACID支持
当然,它的 短板 也是显而易见的
- 由于只是PostgreSQL的一个Extension,因此它不能从内核/存储层面针对时序数据库的使用场景进行极致优化。
- 当前的产品架构来看仍然是一个单机库,不能发挥分布式技术的优势。而且数据虽然自动分区,但是由于时间戳决定分区,因此很容易形成I/O热点。
- 在功能层面,面向时序数据库场景的特性还比较有限。目前更像是一个 传统OLTP数据库 + 部分时序特性 。
不管怎样,TimescaleDB也算是面向时序数据库从另一个角度发起的尝试。在当前时序数据库仍然处于新兴事物的阶段,它未来的发展方向也是值得我们关注并借鉴的。
阿里云时序时空数据库TSDB 1元购!立即体验:https://promotion.aliyun.com/ntms/act/tsdbtry.html?spm=5176.149792.775960.1.dd9e34e2zgsuEM&wh_ttid=pc