训练稀疏模型
所有刚刚提出的优化算法都会产生密集的模型,这意味着大多数参数都是非零的。 如果你在运行时需要一个非常快速的模型,或者如果你需要它占用较少的内存,你可能更喜欢用一个稀疏模型来代替。
实现这一点的一个微不足道的方法是像平常一样训练模型,然后摆脱微小的权重(将它们设置为 0)。
另一个选择是在训练过程中应用强 l1 正则化,因为它会推动优化器尽可能多地消除权重(如第 4 章关于 Lasso 回归的讨论)。
但是,在某些情况下,这些技术可能仍然不足。 最后一个选择是应用双重平均,通常称为遵循正则化领导者(FTRL),一种由尤里·涅斯捷罗夫(Yurii Nesterov)提出的技术。 当与 l1 正则化一起使用时,这种技术通常导致非常稀疏的模型。 TensorFlow 在FTRLOptimizer类中实现称为 FTRL-Proximal 的 FTRL 变体。
学习率调整
找到一个好的学习速度可能会非常棘手。 如果设置太高,训练实际上可能偏离(如我们在第 4 章)。 如果设置得太低,训练最终会收敛到最佳状态,但这需要很长时间。 如果将其设置得太高,开始的进度会非常快,但最终会在最优解周围跳动,永远不会安顿下来(除非您使用自适应学习率优化算法,如 AdaGrad,RMSProp 或 Adam,但是 即使这样可能需要时间来解决)。 如果您的计算预算有限,那么您可能必须在正确收敛之前中断训练,产生次优解决方案(参见图 11-8)。
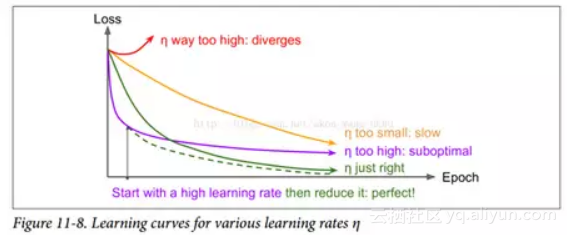
通过使用各种学习率和比较学习曲线,在几个迭代内对您的网络进行多次训练,您也许能够找到相当好的学习率。 理想的学习率将会快速学习并收敛到良好的解决方案。
然而,你可以做得比不断的学习率更好:如果你从一个高的学习率开始,然后一旦它停止快速的进步就减少它,你可以比最佳的恒定学习率更快地达到一个好的解决方案。 有许多不同的策略,以减少训练期间的学习率。 这些策略被称为学习率调整(我们在第 4 章中简要介绍了这个概念),其中最常见的是:
预定的分段恒定学习率:

Andrew Senior 等2013年的论文。 比较了使用动量优化训练深度神经网络进行语音识别时一些最流行的学习率调整的性能。 作者得出结论:在这种情况下,性能调度和指数调度都表现良好,但他们更喜欢指数调度,因为它实现起来比较简单,容易调整,收敛速度略快于最佳解决方案。
使用 TensorFlow 实现学习率调整非常简单:
initial_learning_rate = 0.1
decay_steps = 10000
global_step = tf.Variable(0, trainable=False, name="global_step")
decay_rate = 1/10
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step,
decay_steps, decay_rate) optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
training_op = optimizer.minimize(loss, global_step=global_step)
设置超参数值后,我们创建一个不可训练的变量global_step(初始化为 0)以跟踪当前的训练迭代次数。 然后我们使用 TensorFlow 的exponential_decay()函数来定义指数衰减的学习率(η0= 0.1和r = 10,000)。 接下来,我们使用这个衰减的学习率创建一个优化器(在这个例子中是一个MomentumOptimizer)。 最后,我们通过调用优化器的minimize()方法来创建训练操作;因为我们将global_step变量传递给它,所以请注意增加它。 就是这样!
由于 AdaGrad,RMSProp 和 Adam 优化自动降低了训练期间的学习率,因此不需要添加额外的学习率调整。 对于其他优化算法,使用指数衰减或性能调度可显著加速收敛。
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_outputs = 10
n_hidden2 = 50
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y") with tf.name_scope("dnn"):
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("eval"):
with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(xentropy, name="loss")
initial_learning_rate = 0.1
correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy") with tf.name_scope("train"): # not shown in the book decay_steps = 10000
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
decay_rate = 1/10 global_step = tf.Variable(0, trainable=False, name="global_step") learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step, decay_steps, decay_rate)
for epoch in range(n_epochs):
training_op = optimizer.minimize(loss, global_step=global_step) init = tf.global_variables_initializer() saver = tf.train.Saver() n_epochs = 5 batch_size = 50 with tf.Session() as sess: init.run()
y: mnist.test.labels})
for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
save_path = saver.save(sess, "./my_model_final.ckpt")
print(epoch, "Test accuracy:", accuracy_val)
完整代码:
通过正则化避免过拟合
有四个参数,我可以拟合一个大象,五个我可以让他摆动他的象鼻。
—— John von Neumann,cited by Enrico Fermi in Nature 427
深度神经网络通常具有数以万计的参数,有时甚至是数百万。 有了这么多的参数,网络拥有难以置信的自由度,可以适应各种复杂的数据集。 但是这个很大的灵活性也意味着它很容易过拟合训练集。
有了数以百万计的参数,你可以适应整个动物园。 在本节中,我们将介绍一些最流行的神经网络正则化技术,以及如何用 TensorFlow 实现它们:早期停止,l1 和 l2 正则化,drop out,最大范数正则化和数据增强。
早期停止
为避免过度拟合训练集,一个很好的解决方案就是尽早停止训练(在第 4 章中介绍):只要在训练集的性能开始下降时中断训练。
与 TensorFlow 实现方法之一是评估其对设置定期(例如,每 50 步)验证模型,并保存一个“winner”的快照,如果它优于以前“winner”的快照。 计算自上次“winner”快照保存以来的步数,并在达到某个限制时(例如 2000 步)中断训练。 然后恢复最后的“winner”快照。
虽然早期停止在实践中运行良好,但是通过将其与其他正则化技术相结合,您通常可以在网络中获得更高的性能。
L1 和 L2 正则化
就像你在第 4 章中对简单线性模型所做的那样,你可以使用 l1 和 l2 正则化约束一个神经网络的连接权重(但通常不是它的偏置)。
使用 TensorFlow 做到这一点的一种方法是简单地将适当的正则化项添加到您的损失函数中。 例如,假设您只有一个权重为weights1的隐藏层和一个权重为weight2的输出层,那么您可以像这样应用 l1 正则化:
我们可以将正则化函数传递给tf.layers.dense()函数,该函数将使用它来创建计算正则化损失的操作,并将这些操作添加到正则化损失集合中。 开始和上面一样:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_outputs = 10
n_hidden2 = 50
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
接下来,我们将使用 Python partial()函数来避免一遍又一遍地重复相同的参数。 请注意,我们设置了内核正则化参数(正则化函数有l1_regularizer(),l2_regularizer(),l1_l2_regularizer()):
scale = 0.001
my_dense_layer = partial(
tf.layers.dense, activation=tf.nn.relu,
kernel_regularizer=tf.contrib.layers.l1_regularizer(scale))
with tf.name_scope("dnn"):
hidden2 = my_dense_layer(hidden1, n_hidden2, name="hidden2")
hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
name="outputs")
logits = my_dense_layer(hidden2, n_outputs, activation=None,
该代码创建了一个具有两个隐藏层和一个输出层的神经网络,并且还在图中创建节点以计算与每个层的权重相对应的 l1 正则化损失。TensorFlow 会自动将这些节点添加到包含所有正则化损失的特殊集合中。 您只需要将这些正则化损失添加到您的整体损失中,如下所示:
接下来,我们必须将正则化损失加到基本损失上:
with tf.name_scope("loss"): # not shown in the book
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits( # not shown
labels=y, logits=logits) # not shown
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
base_loss = tf.reduce_mean(xentropy, name="avg_xentropy") # not shown
loss = tf.add_n([base_loss] + reg_losses, name="loss")
其余的和往常一样:
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
learning_rate = 0.01 with tf.name_scope("train"):
training_op = optimizer.minimize(loss)
optimizer = tf.train.GradientDescentOptimizer(learning_rate) init = tf.global_variables_initializer()
for epoch in range(n_epochs):
saver = tf.train.Saver() n_epochs = 20 batch_size = 200 with tf.Session() as sess: init.run()
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
for iteration in range(mnist.train.num_examples // batch_size): X_batch, y_batch = mnist.train.next_batch(batch_size)
save_path = saver.save(sess, "./my_model_final.ckpt")
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels}) print(epoch, "Test accuracy:", accuracy_val)
不要忘记把正则化的损失加在你的整体损失上,否则就会被忽略。
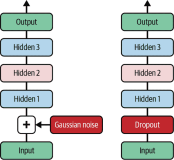
Dropout
深度神经网络最流行的正则化技术可以说是 dropout。 它由 GE Hinton 于 2012 年提出,并在 Nitish Srivastava 等人的论文中进一步详细描述,并且已被证明是非常成功的:即使是最先进的神经网络,仅仅通过增加丢失就可以提高1-2%的准确度。 这听起来可能不是很多,但是当一个模型已经具有 95% 的准确率时,获得 2% 的准确度提升意味着将误差率降低近 40%(从 5% 误差降至大约 3%)。
这是一个相当简单的算法:在每个训练步骤中,每个神经元(包括输入神经元,但不包括输出神经元)都有一个暂时“丢弃”的概率p,这意味着在这个训练步骤中它将被完全忽略, 在下一步可能会激活(见图 11-9)。 超参数p称为丢失率,通常设为 50%。 训练后,神经元不会再下降。 这就是全部(除了我们将要讨论的技术细节)。
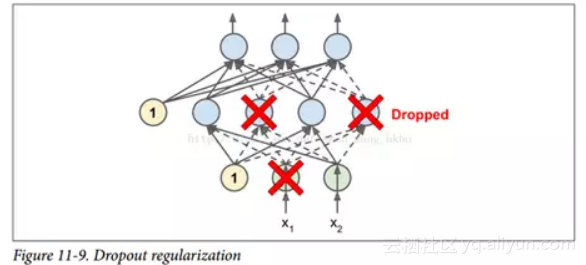
一开始这个技术是相当粗鲁,这是相当令人惊讶的。如果一个公司的员工每天早上被告知要掷硬币来决定是否上班,公司的表现会不会更好呢?那么,谁知道;也许会!公司显然将被迫适应这样的组织构架;它不能依靠任何一个人填写咖啡机或执行任何其他关键任务,所以这个专业知识将不得不分散在几个人身上。员工必须学会与其他的许多同事合作,而不仅仅是其中的一小部分。该公司将变得更有弹性。如果一个人离开了,并没有什么区别。目前还不清楚这个想法是否真的可以在公司实行,但它确实对于神经网络是可以的。神经元被dropout训练不能与其相邻的神经元共适应;他们必须尽可能让自己变得有用。他们也不能过分依赖一些输入神经元;他们必须注意他们的每个输入神经元。他们最终对输入的微小变化会不太敏感。最后,你会得到一个更强大的网络,更好地推广。
了解 dropout 的另一种方法是认识到每个训练步骤都会产生一个独特的神经网络。 由于每个神经元可以存在或不存在,总共有2 ^ N个可能的网络(其中 N 是可丢弃神经元的总数)。 这是一个巨大的数字,实际上不可能对同一个神经网络进行两次采样。 一旦你运行了 10,000 个训练步骤,你基本上已经训练了 10,000 个不同的神经网络(每个神经网络只有一个训练实例)。 这些神经网络显然不是独立的,因为它们共享许多权重,但是它们都是不同的。 由此产生的神经网络可以看作是所有这些较小的神经网络的平均集成。
有一个小而重要的技术细节。 假设p = 50%,在这种情况下,在测试期间,在训练期间神经元将被连接到两倍于(平均)的输入神经元。 为了弥补这个事实,我们需要在训练之后将每个神经元的输入连接权重乘以 0.5。 如果我们不这样做,每个神经元的总输入信号大概是网络训练的两倍,这不太可能表现良好。 更一般地说,我们需要将每个输入连接权重乘以训练后的保持概率(1-p)。 或者,我们可以在训练过程中将每个神经元的输出除以保持概率(这些替代方案并不完全等价,但它们工作得同样好)。
要使用 TensorFlow 实现dropout,可以简单地将dropout()函数应用于输入层和每个隐藏层的输出。 在训练过程中,这个功能随机丢弃一些节点(将它们设置为 0),并用保留概率来划分剩余项目。 训练结束后,这个函数什么都不做。下面的代码将dropout正则化应用于我们的三层神经网络:
注意:本书使用tf.contrib.layers.dropout()而不是tf.layers.dropout()(本章写作时不存在)。 现在最好使用tf.layers.dropout(),因为contrib模块中的任何内容都可能会改变或被删除,恕不另行通知。tf.layers.dropout()函数几乎与tf.contrib.layers.dropout()函数相同,只是有一些细微差别。 最重要的是:
keep_prob
),其中
rate
简单地等于
1 - keep_prob
![]() is_training
is_trainingtraining。
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
training = tf.placeholder_with_default(False, shape=(), name='training')
dropout_rate = 0.5 # == 1 - keep_prob X_drop = tf.layers.dropout(X, dropout_rate, training=training)
hidden1_drop = tf.layers.dropout(hidden1, dropout_rate, training=training)
with tf.name_scope("dnn"): hidden1 = tf.layers.dense(X_drop, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2_drop = tf.layers.dropout(hidden2, dropout_rate, training=training)
hidden2 = tf.layers.dense(hidden1_drop, n_hidden2, activation=tf.nn.relu, name="hidden2") logits = tf.layers.dense(hidden2_drop, n_outputs, name="outputs") with tf.name_scope("loss"):
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(xentropy, name="loss") with tf.name_scope("train"): training_op = optimizer.minimize(loss) with tf.name_scope("eval"): correct = tf.nn.in_top_k(logits, y, 1)
for iteration in range(mnist.train.num_examples // batch_size):
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) init = tf.global_variables_initializer() saver = tf.train.Saver() n_epochs = 20 batch_size = 50 with tf.Session() as sess: init.run() for epoch in range(n_epochs): X_batch, y_batch = mnist.train.next_batch(batch_size)
save_path = saver.save(sess, "./my_model_final.ckpt")
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch}) acc_test = accuracy.eval(feed_dict={X: mnist.test.images, y: mnist.test.labels}) print(epoch, "Test accuracy:", acc_test)
你想在tensorflow.contrib.layers中使用dropout()函数,而不是tensorflow.nn中的那个。 第一个在不训练的时候关掉(没有操作),这是你想要的,而第二个不是。
如果观察到模型过拟合,则可以增加 dropout 率(即,减少keep_prob超参数)。 相反,如果模型欠拟合训练集,则应尝试降低 dropout 率(即增加keep_prob)。 它也可以帮助增加大层的 dropout 率,并减少小层的 dropout 率。
dropout 似乎减缓了收敛速度,但通常会在调整得当时使模型更好。 所以,这通常值得花费额外的时间和精力。
Dropconnect是dropout的变体,其中单个连接随机丢弃而不是整个神经元。 一般而言,dropout表现会更好。
最大范数正则化

n_inputs = 28 * 28
n_hidden1 = 300
n_outputs = 10
n_hidden2 = 50
momentum = 0.9
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y") with tf.name_scope("dnn"):
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("train"):
with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(xentropy, name="loss")
correct = tf.nn.in_top_k(logits, y, 1)
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum) training_op = optimizer.minimize(loss) with tf.name_scope("eval"):
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
接下来,让我们来处理第一个隐藏层的权重,并创建一个操作,使用clip_by_norm()函数计算剪切后的权重。 然后我们创建一个赋值操作来将权值赋给权值变量:
threshold = 1.0
weights = tf.get_default_graph().get_tensor_by_name("hidden1/kernel:0")
clipped_weights = tf.clip_by_norm(weights, clip_norm=threshold, axes=1)
clip_weights = tf.assign(weights, clipped_weights)
我们也可以为第二个隐藏层做到这一点:
weights2 = tf.get_default_graph().get_tensor_by_name("hidden2/kernel:0")
clipped_weights2 = tf.clip_by_norm(weights2, clip_norm=threshold, axes=1)
clip_weights2 = tf.assign(weights2, clipped_weights2)
让我们添加一个初始化器和一个保存器:
init = tf.global_variables_initializer()
saver = tf.train.Saver()
现在我们可以训练模型。 与往常一样,除了在运行training_op之后,我们运行clip_weights和clip_weights2操作:
n_epochs = 20
batch_size = 50
with tf.Session() as sess: # not shown in the book
init.run() # not shown
for iteration in range(mnist.train.num_examples // batch_size): # not shown
for epoch in range(n_epochs): # not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
X_batch, y_batch = mnist.train.next_batch(batch_size) # not shown clip_weights.eval()
y: mnist.test.labels}) # not shown
clip_weights2.eval() # not shown acc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not shown
save_path = saver.save(sess, "./my_model_final.ckpt") # not shown
print(epoch, "Test accuracy:", acc_test) # not shown
上面的实现很简单,工作正常,但有点麻烦。 更好的方法是定义一个max_norm_regularizer()函数:
def max_norm_regularizer(threshold, axes=1, name="max_norm",
collection="max_norm"): def max_norm(weights):
clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes)
clip_weights = tf.assign(weights, clipped, name=name) tf.add_to_collection(collection, clip_weights)
return max_norm
return None # there is no regularization loss term
然后你可以调用这个函数来得到一个最大范数调节器(与你想要的阈值)。 当你创建一个隐藏层时,你可以将这个正则化器传递给kernel_regularizer参数:
n_inputs = 28 * 28
n_hidden1 = 300
n_outputs = 10
n_hidden2 = 50
momentum = 0.9
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
max_norm_reg = max_norm_regularizer(threshold=1.0) with tf.name_scope("dnn"):
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg, name="hidden1") kernel_regularizer=max_norm_reg, name="hidden2")
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
logits = tf.layers.dense(hidden2, n_outputs, name="outputs") with tf.name_scope("loss"): loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
with tf.name_scope("train"): optimizer = tf.train.MomentumOptimizer(learning_rate, momentum) training_op = optimizer.minimize(loss)
saver = tf.train.Saver()
correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
训练与往常一样,除了每次训练后必须运行重量裁剪操作:
请注意,最大范数正则化不需要在整体损失函数中添加正则化损失项,所以max_norm()函数返回None。 但是,在每个训练步骤之后,仍需要运行clip_weights操作,因此您需要能够掌握它。 这就是为什么max_norm()函数将clip_weights节点添加到最大范数剪裁操作的集合中的原因。您需要获取这些裁剪操作并在每个训练步骤后运行它们:
n_epochs = 20
batch_size = 50
clip_all_weights = tf.get_collection("max_norm")
with tf.Session() as sess: init.run()
for iteration in range(mnist.train.num_examples // batch_size):
for epoch in range(n_epochs):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
X_batch, y_batch = mnist.train.next_batch(batch_size) sess.run(clip_all_weights)
y: mnist.test.labels}) # not shown
acc_test = accuracy.eval(feed_dict={X: mnist.test.images, # not shown in the book print(epoch, "Test accuracy:", acc_test) # not shown
save_path = saver.save(sess, "./my_model_final.ckpt") # not shown
数据增强
最后一个正则化技术,数据增强,包括从现有的训练实例中产生新的训练实例,人为地增加了训练集的大小。 这将减少过拟合,使之成为正则化技术。 诀窍是生成逼真的训练实例; 理想情况下,一个人不应该能够分辨出哪些是生成的,哪些不是生成的。 而且,简单地加白噪声也无济于事。 你应用的修改应该是可以学习的(白噪声不是)。
例如,如果您的模型是为了分类蘑菇图片,您可以稍微移动,旋转和调整训练集中的每个图片的大小,并将结果图片添加到训练集(见图 11-10)。 这迫使模型更能容忍图片中蘑菇的位置,方向和大小。 如果您希望模型对光照条件更加宽容,则可以类似地生成具有各种对比度的许多图像。 假设蘑菇是对称的,你也可以水平翻转图片。 通过结合这些转换,可以大大增加训练集的大小。

通常最好在训练期间生成训练实例,而不是浪费存储空间和网络带宽。TensorFlow 提供了多种图像处理操作,例如转置(移位),旋转,调整大小,翻转和裁剪,以及调整亮度,对比度,饱和度和色调(请参阅 API 文档以获取更多详细信息)。 这可以很容易地为图像数据集实现数据增强。
训练非常深的神经网络的另一个强大的技术是添加跳过连接(跳过连接是将层的输入添加到更高层的输出时)。 我们将在第 13 章中谈论深度残差网络时探讨这个想法。
实践指南
在本章中,我们已经涵盖了很多技术,你可能想知道应该使用哪些技术。 表 11-2 中的配置在大多数情况下都能正常工作。

当然,如果你能找到解决类似问题的方法,你应该尝试重用预训练的神经网络的一部分。
这个默认配置可能需要调整:
有了这些指导方针,你现在已经准备好训练非常深的网络 - 好吧,如果你非常有耐心的话,那就是! 如果使用单台机器,则可能需要等待几天甚至几个月才能完成训练。 在下一章中,我们将讨论如何使用分布式 TensorFlow 在许多服务器和 GPU 上训练和运行模型。
练习
使用 He 初始化随机选择权重,是否可以将所有权重初始化为相同的值?可以将偏置初始化为 0 吗?
说出 ELU 激活功能与 ReLU 相比的三个优点。
在哪些情况下,您想要使用以下每个激活函数:ELU,leaky ReLU(及其变体),ReLU,tanh,logistic 以及 softmax?
使用
MomentumOptimizer
时,如果将
momentum
超参数设置得太接近 1(例如,0.99999),会发生什么情况?
请列举您可以生成稀疏模型的三种方法。
dropout 是否会减慢训练? 它是否会减慢推断(即预测新的实例)?
深度学习。
建立一个 DNN,有五个隐藏层,每层 100 个神经元,使用 He 初始化和 ELU 激活函数。
使用 Adam 优化和提前停止,请尝试在 MNIST 上进行训练,但只能使用数字 0 到 4,因为我们将在下一个练习中在数字 5 到 9 上进行迁移学习。 您需要一个包含五个神经元的 softmax 输出层,并且一如既往地确保定期保存检查点,并保存最终模型,以便稍后再使用它。
使用交叉验证调整超参数,并查看你能达到什么准确度。
现在尝试添加批量标准化并比较学习曲线:它是否比以前收敛得更快? 它是否会产生更好的模型?
模型是否过拟合训练集? 尝试将 dropout 添加到每一层,然后重试。 它有帮助吗?
迁移学习。
创建一个新的 DNN,它复制先前模型的所有预训练的隐藏层,冻结它们,并用新的一层替换 softmax 输出层。
在数字 5 到 9 训练这个新的 DNN ,每个数字只使用 100 个图像,需要多长时间? 尽管样本这么少,你能达到高准确度吗?
尝试缓存冻结的层,并再次训练模型:现在速度有多快?
再次尝试复用四个隐藏层而不是五个。 你能达到更高的准确度吗?
现在,解冻前两个隐藏层并继续训练:您可以让模型表现得更好吗?
辅助任务的预训练。
在本练习中,你将构建一个 DNN,用于比较两个 MNIST 数字图像,并预测它们是否代表相同的数字。 然后,你将复用该网络的较低层,来使用非常少的训练数据来训练 MNIST 分类器。 首先构建两个 DNN(我们称之为 DNN A 和 B),它们与之前构建的 DNN 类似,但没有输出层:每个 DNN 应该有五个隐藏层,每个层包含 100 个神经元,使用 He 初始化和 ELU 激活函数。 接下来,在两个 DNN 上添加一个输出层。 你应该使用 TensorFlow 的
concat()函数和
axis = 1`,将两个 DNN 的输出沿着横轴连接,然后将结果输入到输出层。 输出层应该包含单个神经元,使用 logistic 激活函数。
将 MNIST 训练集分为两组:第一部分应包含 55,000个 图像,第二部分应包含 5000 个图像。 创建一个生成训练批次的函数,其中每个实例都是从第一部分中挑选的一对 MNIST 图像。 一半的训练实例应该是属于同一类的图像对,而另一半应该是来自不同类别的图像。 对于每一对,如果图像来自同一类,训练标签应该为 0;如果来自不同类,则标签应为 1。
在这个训练集上训练 DNN。 对于每个图像对,你可以同时将第一张图像送入 DNN A,将第二张图像送入 DNN B。整个网络将逐渐学会判断两张图像是否属于同一类别。
现在通过复用和冻结 DNN A 的隐藏层,并添加 1 0个神经元的 softmax 输出层来创建一个新的 DNN。 在第二部分上训练这个网络,看看你是否可以实现较好的表现,尽管每类只有 500 个图像。
原文发布时间为:2018-06-25
本文作者:ApacheCN【翻译】
本文来自云栖社区官方钉群“Python技术进阶”,了解相关信息可以关注“Python技术进阶”。
Python技术进阶交流群