今天早上分享了下HBase,分享的时候同事提出了一些问题,可能大部分有有这样的困惑,汇总下来:
HBase问题汇总与解答
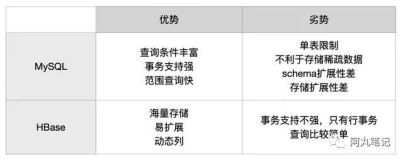
- 两个独立的服务器,一台用HDFS,一台不用HDFS可以吗?HDFS和Hbase必须要装在同一台服务器上吗?
答:
As HBase runs on HDFS (and each StoreFile is written as a file on HDFS), it is important to have an understanding of the HDFS Architecture especially in terms of how it stores files, handles failovers, and replicates blocks.
To operate with the most efficiency, HBase needs data to be available locally. Therefore, it is a good practice to run an HDFS DataNode on each RegionServer
Hbase运行在HDFS之上,每个StoreFile都被写成一个HDFS的文件,能理解HDFS的架构,它是如何存储文件,处理故障转移和复制块很重要
大多数情况下,Hbase将数据存储在HDFS之上,像Hfile和WALs(主要为了防止RegionServer出现故障)都会存储在HDFS上,HDFS提供对Hbase数据的可靠性和保证,为了最大化的操作效率,Hbase也需要本地的数据是可靠的,因此最好是在每一个RegionServer上运行DataNode。
当有问题出现的时候,最好同时检查HDFS和Hbase的日志,因为日志可能再两个地方都有记录。
另外,HBase不支持一台用HDFS,一台不用HDFS,在完全分布式的场景中,多个Hbase的实例运行在集群的多个服务器上面,一般要设置两个属性:
hbase.rootdir指向一个HDFS的文件系统
hbase.cluster.distributed属性设置为true。
如下:可以看到HBase只能指向某一种文件系统的路径上,而且想要HBase完全的分布式,必须要设置上面两个属性。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode.example.org:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node-a.example.com,node-b.example.com,node-c.example.com</value>
</property>
</configuration>HBase是HDFS的客户端,Hbase使用的是DFSClient来和HDFS交互,可以看到配置就是Hbase指向HDFS的那个位置,HBase通过Ip port访问HDFS。
参见:https://hbase.apache.org/book.html#_hbase_and_hdfs
- 除了HDFS之外,还有其他的文件系统可以让Hbase更好的使用吗?
答:HBase和HDFS并不是强制的绑定在一起的,HBase完全可以使用本地文件系统,比如mac的文件系统,Linux的ext3,ext2等等,都可以运行Hbase。
- HLog是写磁盘还是日志?
Hlog其实就是WAL的实现, 它记录Hbase中所有的数据改变,如果在RegionServer在MemStore刷新到磁盘之前,不能访问或者挂掉了,WAL可以保证数据的改变重新再进行一次。
The Write Ahead Log (WAL) records all changes to data in HBase, to file-based storage, WAL ensures that the changes to the data can be replayed

根据官网描述,HLog默认写到磁盘上,即HDFS上,我们在使用Hbase的时候可以设置WAL的持久化方式,有以下四种:
- SKIP_WAL: 不写WAL
- ASYNC_WAL:异步写,不用等到WAL写到磁盘上的时候离开返回客户端,同时后台数据的改变会被刷新到WAL。这个选项可能导致丢失数据
- SYNC_WAL:默认的方式,每一次数据的改变都会写到HDFS上面,只有写入成功才返回给客户端成功。
- FSYNC_WAL:每一次的编辑都会写到HDFS,并且同步到文件系统之后才会返回成功。
Mutation.setDurability(Durability.SKIP_WAL)因此默认方式下,WAL是写到HDFS之上,会尽可能的走持久化,而不是在内存中久留,可能再数据改变的时候经过内存,然后就立刻写到HDFS上面了。
- 列簇能不能改名字?
官方的命令是可以修改列簇的名字的,列簇的添加,删除,修改都是可以的。但是能不能修改取决于是否配置了这个属性:
hbase.online.schema.update.enable
// 给t1表新增f1列簇
alter 't1', NAME => 'f1', VERSIONS => 5
// 删除ns1:t1表的f1列簇
alter 'ns1:t1', NAME => 'f1', METHOD => 'delete'但是就像MySQL我们可以修改列的名字,在数据量很大的情况下,我们一般不会修改原有的列名。
- 客户端的缓存什么时候更新?Master怎么处理
客户端首先通过hbase:meta表找到服务指定范围的行的RegionServer,在定位到是哪个Region之后,客户端直接联系RegionServer,而没有经过Master,然后发出读写请求。当Region被Master重新分配,或者某个RegionSever挂掉的时候,客户端会重新的查询索引表hbase:meta 来决定新的region位置。当RegionServer挂掉的时候,Master节点是可以感知到的,Master做RegionServer的协调工作,会通知RegionSever,在客户端查的时候也知道数据改变了,可以再次请求索引表hbase:meta。
The HBase client finds the RegionServers that are serving the particular row range of interest. It does this by querying the
hbase:metatable. See hbase:meta for details. After locating the required region(s), the client contacts the RegionServer serving that region, rather than going through the master, and issues the read or write request. This information is cached in the client so that subsequent requests need not go through the lookup process. Should a region be reassigned either by the master load balancer or because a RegionServer has died, the client will requery the catalog tables to determine the new location of the user region.
一个常问的问题就是Master挂掉的时候,Hbase会发生什么事情,因为Hbase客户端是直接和RegionServer进行通信,而且hbase:meta表并没有存在Master节点上,Master只是进行RegionServer的故障恢复和Region的切分,因此在Master挂掉的短时间内,Hbase还能正常的工作,只不过要尽可能快的修复Master。
Master节点感知的元数据改变是粒度比较大的,比如表改变,列簇改变,Region的切分,合并,移动,都不是频繁的发生的情况。
A common dist-list question involves what happens to an HBase cluster when the Master goes down. Because the HBase client talks directly to the RegionServers, the cluster can still function in a "steady state". Additionally, per Catalog Tables,
hbase:metaexists as an HBase table and is not resident in the Master. However, the Master controls critical functions such as RegionServer failover and completing region splits. So while the cluster can still run for a short time without the Master, the Master should be restarted as soon as possible.
- Master有没有存元数据?
Master一般运行在NameNode上面,没有存储元数据。
另外多说下,Master是可以有多个的,如果主Master挂掉了,剩余的Master会竞争Master的角色。
If run in a multi-Master environment, all Masters compete to run the cluster. If the active Master loses its lease in ZooKeeper (or the Master shuts down), then the remaining Masters jostle to take over the Master role.
-
发送一个key,里面具体怎么获取数据的?
- 因为每一个用户表Region都是一个RowKey Range,meta Region中记录了每一个用户表Region的路由以及状态信息,以RegionName(包含表名,Region StartKey,Region ID,副本ID等信息)作为RowKey。
- Region只要不被迁移,那么获取的该Region的路由信息就是一直有效的,因此,HBase Client有一个Cache机制来缓存Region的路由信息,避免每次读写都要去访问ZooKeeper或者meta Region。
- 类似于Client发送建表到Master的流程,Client发送写数据请求到RegionServer,也是通过RPC的方式。只是,Client到Master以及Client到RegionServer,采用了不同的RPC服务接口。
- RegionServer的RPC Server侧,接收到来自Client端的RPC请求以后,将该请求交给Handler线程处理。如果是single put,则该步骤比较简单,因为在发送过来的请求参数MutateRequest中,已经携带了这条记录所关联的Region,那么直接将该请求转发给对应的Region即可。
-
HBase也采用了LSM-Tree的架构设计:LSM-Tree利用了传统机械硬盘的“顺序读写速度远高于随机读写速度”的特点。随机写入的数据,如果直接去改写每一个Region上的数据文件,那么吞吐量是非常差的。因此,每一个Region中随机写入的数据,都暂时先缓存在内存中(HBase中存放这部分内存数据的模块称之为MemStore,这里仅仅引出概念,下一章节详细介绍),为了保障数据可靠性,将这些随机写入的数据顺序写入到一个称之为WAL(Write-Ahead-Log)的日志文件中.
- WAL中的数据按时间顺序组织:如果位于内存中的数据尚未持久化,而且突然遇到了机器断电,只需要将WAL中的数据回放到Region中即可
- 如果一个WAL中所关联的所有的Region中的数据,都已经被持久化存储了,那么,这个WAL文件会被暂时归档到另外一个目录中
- 在0.94版本之前,Region中的写入顺序是先写WAL再写MemStore,这与WAL的定义也相符。
- 但在0.94版本中,将这两者的顺序颠倒了,当时颠倒的初衷,是为了使得行锁能够在WAL sync之前先释放,从而可以提升针对单行数据的更新性能。详细问题单,请参考HBASE-4528。
在2.0版本中,这一行为又被改回去了,原因在于修改了行锁机制以后(下面章节将讲到),发现了一些性能下降,而HBASE-4528中的优化却无法再发挥作用,详情请参考HBASE-15158。改动之后的逻辑也更简洁了。
至此,这条数据已经被同时成功写到了WAL以及MemStore中, 当MemStore达到阈值的时候,会被刷新到磁盘上进行持久化存储,而如果服务器挂掉了,则可以通过WAL进行数据恢复。
参考:一条数据的HBase之旅,简明HBase入门教程-Write全流程
- Hlog有没有存满之后的淘汰策略?磁盘存满了?HBase怎么存储
像上面提到的Hlog是存储在磁盘上面的,不是内存型存储不需要淘汰策略,要解决的就是磁盘存满之后怎么办?磁盘满了肯定是存不进去了,一般情况下我们都会有磁盘利用率的检测工具,在磁盘到达一定程度之后进行通知,HDFS是可以无限扩容的,就是多加台服务器的事情。
- 并发写一个key?
在之前的版本中,行级别的任何并发写入/更新都是互斥的,由一个行锁控制。但在2.0版本中,这一点行为发生了变化,多个线程可以同时更新一行数据,这里的考虑点为:
- 如果多个线程写入同一行的不同列族,是不需要互斥的
- 多个线程写同一行的相同列族,也不需要互斥,即使是写相同的列,也完全可以通过HBase的MVCC机制来控制数据的一致性
- 当然,CAS操作(如checkAndPut)或increment操作,依然需要独占的行锁
后续单独整理
- 数据恢复,集群管理
Hbase备份和恢复,属于比较大的知识块,后续单独整理