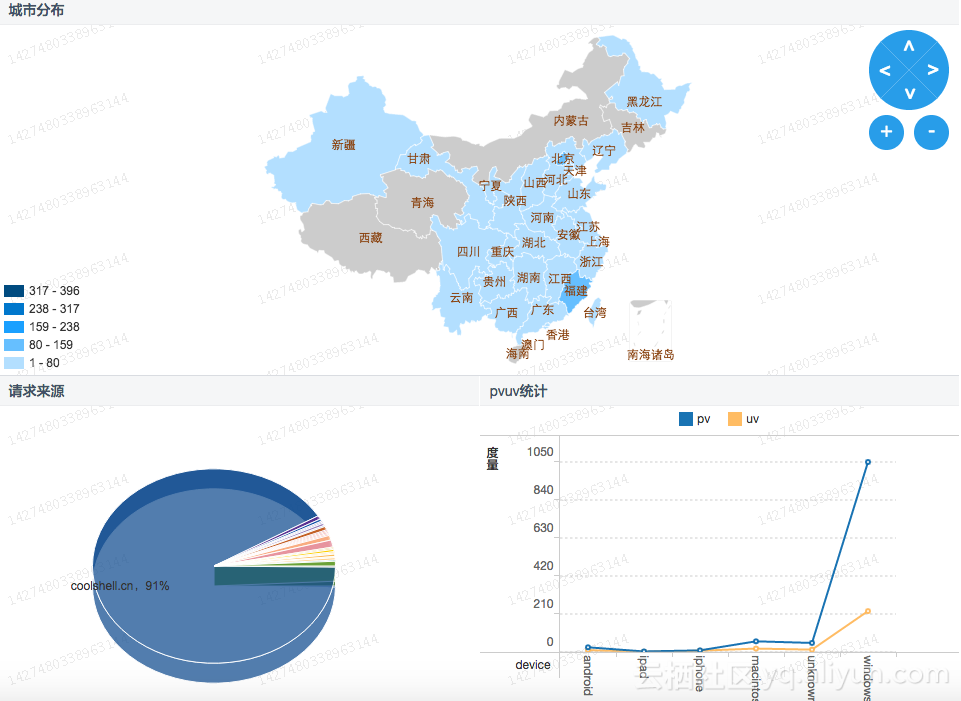
前文背景:【Best Practice】基于阿里云数加·StreamCompute快速构建网站日志实时分析大屏
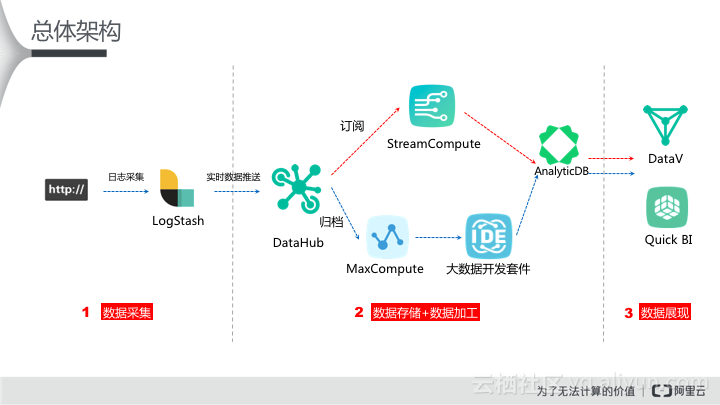
最近很多云栖社区的网友们看了上面一篇文章后都在追我下一篇,由于时间关系先给各位抱歉。那本篇文章我们来阐述如何通过MaxCompute和Quick BI来完成网站用户画像分析。还是和以往一样,看看整个数据架构图如下:
开通阿里云数加产品
前提条件
为了保证整个实验的顺利开展,需要用户使用开通相关产品及服务,包括DataHub、MaxCompute、AnalyticDB、Data IDE、Quick BI。
业务场景
数据来源于网站上的HTTP访问日志数据,基于这份网站日志来实现如下分析需求:
n 统计并展现网站的PV和UV,并能够按照用户的终端类型(如Android、iPad、iPhone、PC等)分别统计。
n 统计并展现网站的流量来源。
n 统计并展现网站的用户地域分布。
【说明】浏览次数(PV)和独立访客(UV)是衡量网站流量的两项最基本指标。用户每打开一个网站页面,记录一个PV,多次打开同一页面PV 累计多次。独立访客是指一天内,访问网站的不重复用户数,一天内同一访客多次访问网站只计算1 次。
数据说明
该数据的格式如下:
$remote_addr - $remote_user [$time_local] “$request” $status $body_bytes_sent”$http_referer” “$http_user_agent” [unknown_content];主要字段说明如下:
| 字段名称 |
字段说明 |
| $remote_addr |
发送请求的客户端IP地址 |
| $remote_user |
客户端登录名 |
| $time_local |
服务器本地时间 |
| $request |
请求,包括HTTP请求类型+请求URL+HTTP协议版本号 |
| $status |
服务端返回状态码 |
| $body_bytes_sent |
返回给客户端的字节数(不含header) |
| $http_referer |
该请求的来源URL |
| $http_user_agent |
发送请求的客户端信息,如使用的浏览器等 |
真实源数据如下:
18.111.79.172 - - [12/Feb/2014:03:15:52 +0800] “GET /articles/4914.html HTTP/1.1” 200 37666
“http://coolshell.cn/articles/6043.html” “Mozilla/5.0 (Windows NT 6.2; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36” – 具体流程
如上图所示,红色箭线部分为流式数据处理部分,主要拆解如下:
l 配置Logstash,将CoolShell.cn产生的日志实时采集至DataHub。
l 申请开通DataHub,创建项目Project及Topic(DataHub服务订阅和发布的最小单位)。
l 开通MaxCompute及大数据开发套件,创建项目Project,并创建MaxCompute表及数据同步任务。
l 将数据加工得到的结果表数据同步至AnalyticDB中便于Quick BI进行分析。
数据结构设计
离线分析的处理逻辑中主要设计到DataHub Topic、MaxCompute表、AnalyticDB表。那这些表之间的逻辑结果以及数据链路是怎样的呢?如下示例:
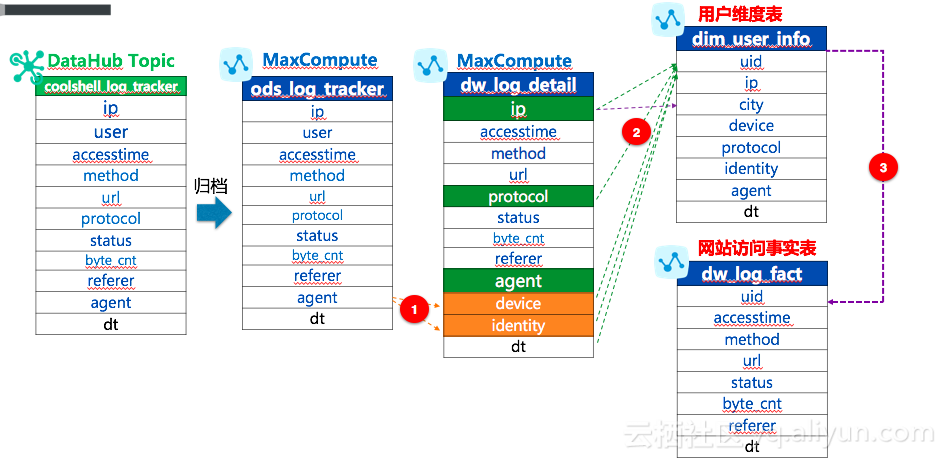
DataHub Topic
根据如上数据链路涉及到的DataHub Topic包括:coolshell_log_tracker。
Coolshell_log_tracker
Topic是DataHub服务订阅和发布的最小单位,可以用来表示一类或者一种流数据。通过对日志结构的解析原始DataHub Topic:coolshell_log_tracker格式如下:
| 字段名称 |
字段类型 |
| ip |
string |
| user |
string |
| accesstime |
string |
| method |
string |
| url |
string |
| protocol |
string |
| status |
bigint |
| byte_cnt |
bigint |
| referer |
string |
| agent |
string |
| dt |
string |
ods_log_tracker
针对Topic CoolShell_log_tracker可进行归档至MaxCompute 表中做进一步的离线分析和加工。(说明:数据归档的频率为每个Shard每5分钟或者Shard中新写入的数据量达到64MB,Connector服务会批量进行一次数据归档进入MaxCompute表的操作。)
具体结构如下:
| 字段名称 |
字段类型 |
字段说明 |
| ip |
string |
客户端请求ip |
| user |
string |
客户端登录名 |
| accesstime |
string |
服务器本地时间 |
| method |
string |
请求方法 |
| url |
string |
访问路径或页面 |
| protocol |
string |
HTTP协议版本号 |
| status |
bigint |
服务器返回状态码 |
| byte_cnt |
bigint |
返回给客户端的字节数 |
| referer |
string |
该请求的来源URL |
| agent |
string |
客户端信息,如浏览器 |
| dt |
string |
时间分区YYYYMMDD |
dw_log_detail
根据agent字段的规律拆分出device(设备)和identity(请求来源标识)并将数据写入MaxCompute的dw_log_detail表中。表结果如下所示:
| 字段名称 |
字段类型 |
字段说明 |
| ip |
string |
客户端请求ip |
| accesstime |
string |
服务器本地时间 |
| method |
string |
请求方法 |
| url |
string |
访问路径或页面 |
| protocol |
string |
HTTP协议版本号 |
| status |
bigint |
服务器返回状态码 |
| byte_cnt |
bigint |
返回给客户端的字节数 |
| referer |
string |
该请求的来源URL |
| agent |
string |
客户端信息,如浏览器 |
| device |
string |
请求来源设备情况 |
| identity |
string |
请求来源标识,如爬虫 |
| dt |
string |
时间分区YYYYMMDD |
dim_user_info
假设基于简单规则,ip、device、protocol、identity和agent字段信息完全一致可以认为是同一个用户,来确认uid(识别唯一用户)。同时根据ip2region的自定义函数将ip地址转换为city字段,最终产生用户维度表:dim_user_info,表结构如下所示:
| 字段名称 |
字段类型 |
字段说明 |
| uid |
string |
用户唯一标识 |
| ip |
string |
客户端请求ip |
| city |
string |
ip对应的城市 |
| protocol |
string |
HTTP协议版本号 |
| device |
string |
请求来源设备情况 |
| identity |
string |
请求来源标识,如爬虫 |
| agent |
string |
客户端信息,如浏览器 |
| dt |
string |
时间分区YYYYMMDD |
dw_log_fact
按照用户维表进行聚合展现具体的数据产生事实表,具体表结构如下:
| 字段名称 |
字段类型 |
字段说明 |
| uid |
string |
用户唯一标识 |
| accesstime
|
string |
服务器本地时间 |
| method |
string |
请求方法 |
| url |
string |
访问路径或页面 |
| status |
string |
服务器返回状态码 |
| byte_cnt |
string |
返回给客户端的字节数 |
| referer |
string |
该请求的来源URL |
| dt |
string |
时间分区YYYYMMDD |
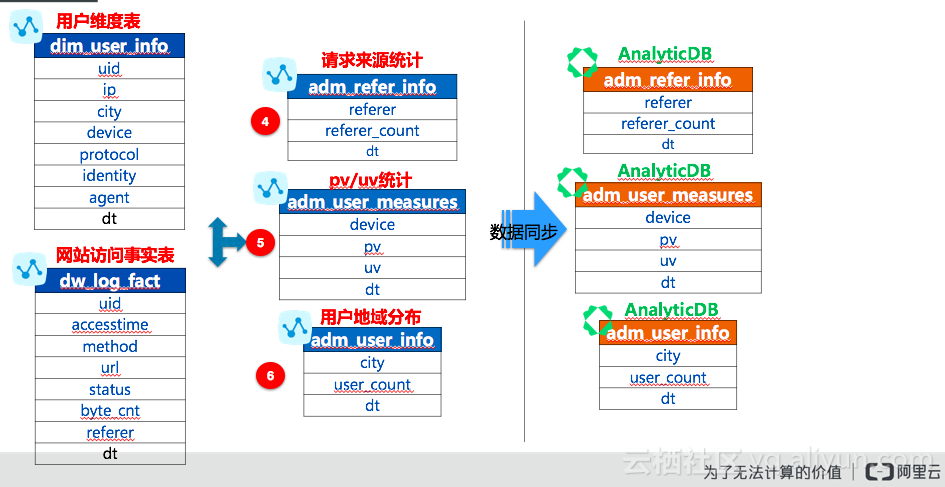
接着我们按照需要分析的主题进行加工数据,也就是数据仓库领域中的ADM(数据集市)层。具体如下:
adm_refer_info
按照请求来源类型进行统计,具体表结构如下所示:
| 字段名称 |
字段类型 |
字段说明 |
| referer |
string |
请求来源 |
| referer_count
|
bigint |
请求来源总数 |
| dt |
string |
时间分区YYYYMMDD |
adm_user_measures
按照pv/uv来进行统计,具体表结构如下所示:
| 字段名称 |
字段类型 |
字段说明 |
| device |
string |
设备类型 |
| pv
|
bigint |
页面浏览量 |
| uv |
bigint |
页面访客数 |
| dt |
string |
时间分区YYYYMMDD |
adm_user_info
按照地域来统计用户数,具体表结构如下:
| 字段名称 |
字段类型 |
字段说明 |
| city |
string |
城市 |
| user_count
|
bigint |
每个城市的用户数 |
| dt |
string |
时间分区YYYYMMDD |
AnalyticDB Table
由于MaxCompute更适合于做离线数据加工分析,最终的展现要将数据导入AnalyticDB进行QuickBI的展现,对应的表结构同adm_refer_info、adm_user_measures、adm_user_info。
日志数据的实时解析和采集: Logstash安装与配置
ruby{
code => "
md = event.get('accesstime')
event.set('dt',DateTime.strptime(md,'%d/%b/%Y:%H:%M:%S').strftime('%Y%m%d'))
"
}
DataHub Topic的结构与上一篇流式数据处理的结构相同。
创建MaxCompute表
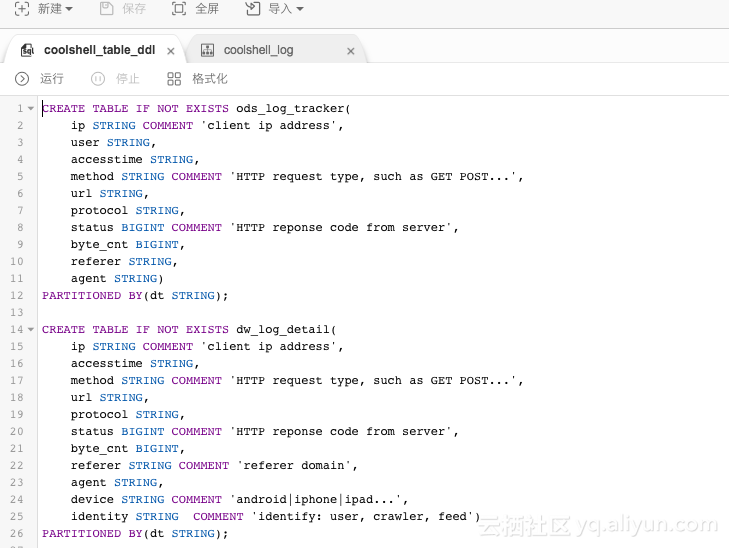
CREATE TABLE IF NOT EXISTS ods_log_tracker(
ip STRING COMMENT 'client ip address',
user STRING,
accesstime string,
method STRING COMMENT 'HTTP request type, such as GET POST...',
url STRING,
protocol STRING,
status BIGINT COMMENT 'HTTP reponse code from server',
byte_cnt BIGINT,
referer STRING,
agent STRING)
PARTITIONED BY(dt STRING);
CREATE TABLE IF NOT EXISTS dw_log_detail(
ip STRING COMMENT 'client ip address',
accesstime string,
method STRING COMMENT 'HTTP request type, such as GET POST...',
url STRING,
protocol STRING,
status BIGINT COMMENT 'HTTP reponse code from server',
byte_cnt BIGINT,
referer STRING COMMENT 'referer domain',
agent STRING,
device STRING COMMENT 'android|iphone|ipad...',
identity STRING COMMENT 'identify: user, crawler, feed')
PARTITIONED BY(dt STRING);
CREATE TABLE IF NOT EXISTS dim_user_info(
uid STRING COMMENT 'unique user id',
ip STRING COMMENT 'client ip address',
city string comment 'city',
protocol STRING,
device STRING,
identity STRING COMMENT 'user, crawler, feed',
agent STRING)
PARTITIONED BY(dt STRING);
CREATE TABLE IF NOT EXISTS dw_log_fact(
uid STRING COMMENT 'unique user id',
accesstime string,
method STRING COMMENT 'HTTP request type, such as GET POST...',
url STRING,
status BIGINT COMMENT 'HTTP reponse code from server',
byte_cnt BIGINT,
referer STRING)
PARTITIONED BY(dt STRING);
CREATE TABLE IF NOT EXISTS adm_user_measures(
device STRING COMMENT 'such as android, iphone, ipad...',
pv BIGINT,
uv BIGINT)
PARTITIONED BY(dt STRING);
CREATE TABLE adm_refer_info(
referer STRING,
referer_count BIGINT)
PARTITIONED BY(dt STRING);
CREATE TABLE adm_user_info(
city STRING,
user_count BIGINT)
PARTITIONED BY(dt STRING);
AnalyticDB表创建
在大数据开发套件中创建好 MaxCompute 表后,需要将 ADM 数据集市层的表同步至 AnalyticDB 中,再利用 QuickBI 进行数据分析和洞察。步骤1 进入阿里云数加AnalyticDB管控台,开通并创建数据库确定。
步骤1 点击操作栏中的进入,进入DMS for AnalyticDB。
步骤2 创建AnalyticDB表组,具体如下:
create tablegroup coolshell_log options(minRedundancy=2 executeTimeout=30000);
步骤3 创建AnalyticDB数据表,DDL语句分别如下。
create tablegroup coolshell_log options(minRedundancy=2 executeTimeout=30000);
CREATE TABLE adm_user_measures(
device varchar COMMENT 'such as android, iphone, ipad...',
pv BIGINT,
uv BIGINT)
PARTITION BY HASH KEY(device)
PARTITION NUM 50
SUBPARTITION BY LIST(dt bigint)
SUBPARTITION OPTIONS (available_partition_num = 30)
tablegroup coolshell_log;
CREATE TABLE adm_refer_info(
referer varchar,
referer_count BIGINT)
PARTITION BY HASH KEY(referer)
PARTITION NUM 50
SUBPARTITION BY LIST(dt bigint)
SUBPARTITION OPTIONS (available_partition_num = 30)
tablegroup coolshell_log;
CREATE TABLE adm_user_info(
city varchar,
user_count BIGINT)
PARTITION BY HASH KEY(city)
PARTITION NUM 50
SUBPARTITION BY LIST(dt bigint)
SUBPARTITION OPTIONS (available_partition_num = 30)
tablegroup coolshell_log;
新建ODPS SQL任务
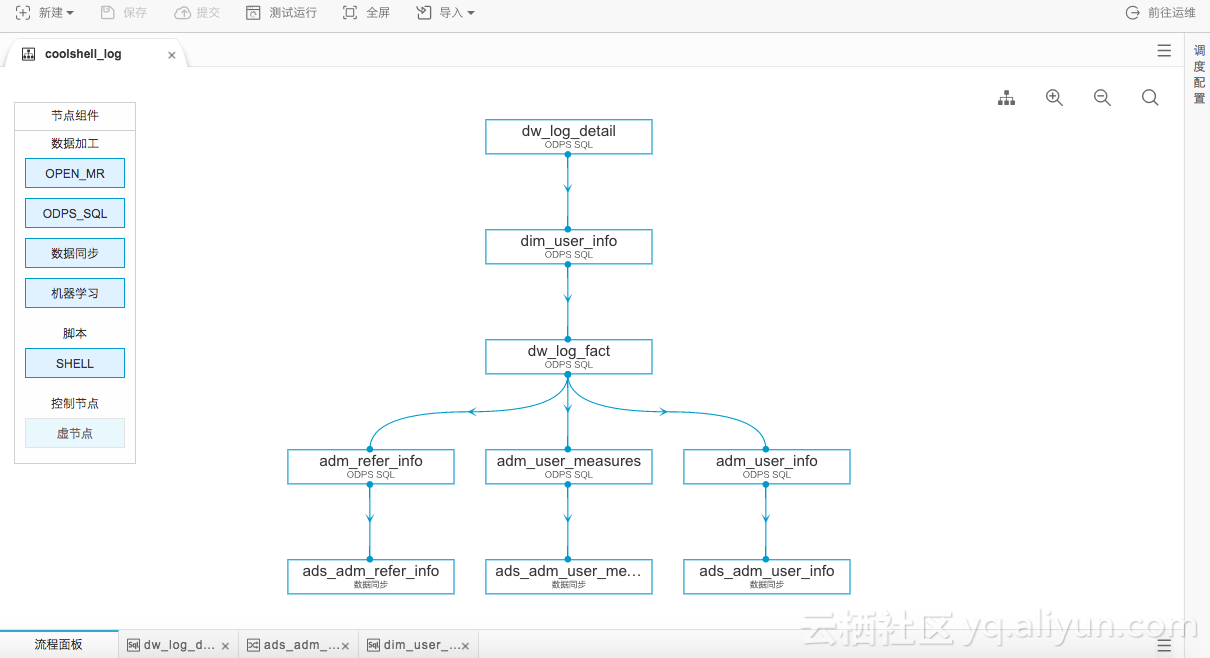
---adm_refer_info中的处理逻辑---
INSERT OVERWRITE TABLE adm_refer_info PARTITION (dt='${bdp.system.bizdate}')
SELECT referer
, COUNT(*) AS referer_cnt
FROM dw_log_fact
WHERE LENGTH(referer) > 1
AND dt = '${bdp.system.bizdate}'
GROUP BY referer;
--adm_user_measures中的处理逻辑---
INSERT OVERWRITE TABLE adm_user_measures PARTITION (dt='${bdp.system.bizdate}')
SELECT u.device
, COUNT(*) AS pv
, COUNT(DISTINCT u.uid) AS uv
FROM dw_log_fact f
JOIN dim_user_info u
ON f.uid = u.uid
AND u.identity = 'user'
AND f.dt = '${bdp.system.bizdate}'
AND u.dt = '${bdp.system.bizdate}'
GROUP BY u.device;
--adm_user_info中的处理逻辑—
INSERT OVERWRITE TABLE adm_user_info PARTITION (dt='${bdp.system.bizdate}')
SELECT city
, COUNT(*) AS user_count
FROM dim_user_info
where dt=${bdp.system.bizdate}
GROUP BY city;
INSERT OVERWRITE TABLE dw_log_fact PARTITION (dt=${bdp.system.bizdate})
SELECT u.uid
, d.accesstime
, d.method
, d.url
, d.status
, d.byte_cnt
, d.referer
FROM dw_log_detail d
JOIN dim_user_info u
ON (d.ip = u.ip
AND d.protocol = u.protocol
AND d.agent = u.agent) and d.dt = ${bdp.system.bizdate} AND u.dt =${bdp.system.bizdate};
创建自定义函数
需要通过自定义函数-Java UDF来处理IP,将IP地址转化为地域region。具体的jar包详见附件。创建自定义函数的具体操作流程详见:https://help.aliyun.com/document_detail/30270.html
配置项说明如下:
函数名:getregion
类名:org.alidata.odps.udf.Ip2Region
资源:ip2region.jar
数据导出AnalyticDB
经过上述步骤,数据加工逻辑已经可以正常执行,那么需要进行数据导出工作。创建三个同步任务将adm数据集市层的数据导入至分析型数据库中,供后续Quick BI更高效的洞察数据。
选择数据源为ADS,填写配置信息并测试连通性通过后,点击 确定 保存配置。(其中AccessID和AccessKey都是大数据开发套件对应项目的生产账号)
在MaxCompute console中需要对garuda_build@aliyun.com 与 garuda_data@aliyun.com。如下进行:
add user ALIYUN$garuda_build@aliyun.com;
add user ALIYUN$garuda_data@aliyun.com;
grant describe,select on table adm_refer_info to user ALIYUN$garuda_build@aliyun.com;
grant describe,select on table adm_refer_info to user ALIYUN$garuda_data@aliyun.com;
grant describe,select on table adm_user_measures to user ALIYUN$garuda_data@aliyun.com;
grant describe,select on table adm_user_measures to user ALIYUN$garuda_build@aliyun.com;
grant describe,select on table adm_user_info to user ALIYUN$garuda_build@aliyun.com;
grant describe,select on table adm_user_info to user ALIYUN$garuda_data@aliyun.com;
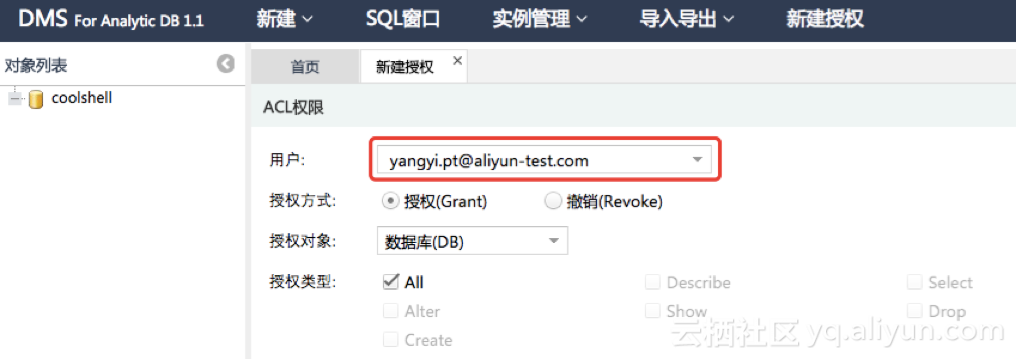
在 DMS for AnalyticDB 中新建授权,用户为大数据开发套件项目对应的生产账号(可从项目管理 >项目配置 中获取)。
分析数据集
操作步骤
点击 adm_user_info 操作栏中的 分析。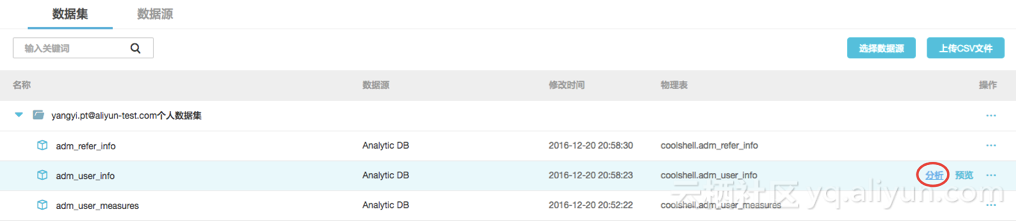
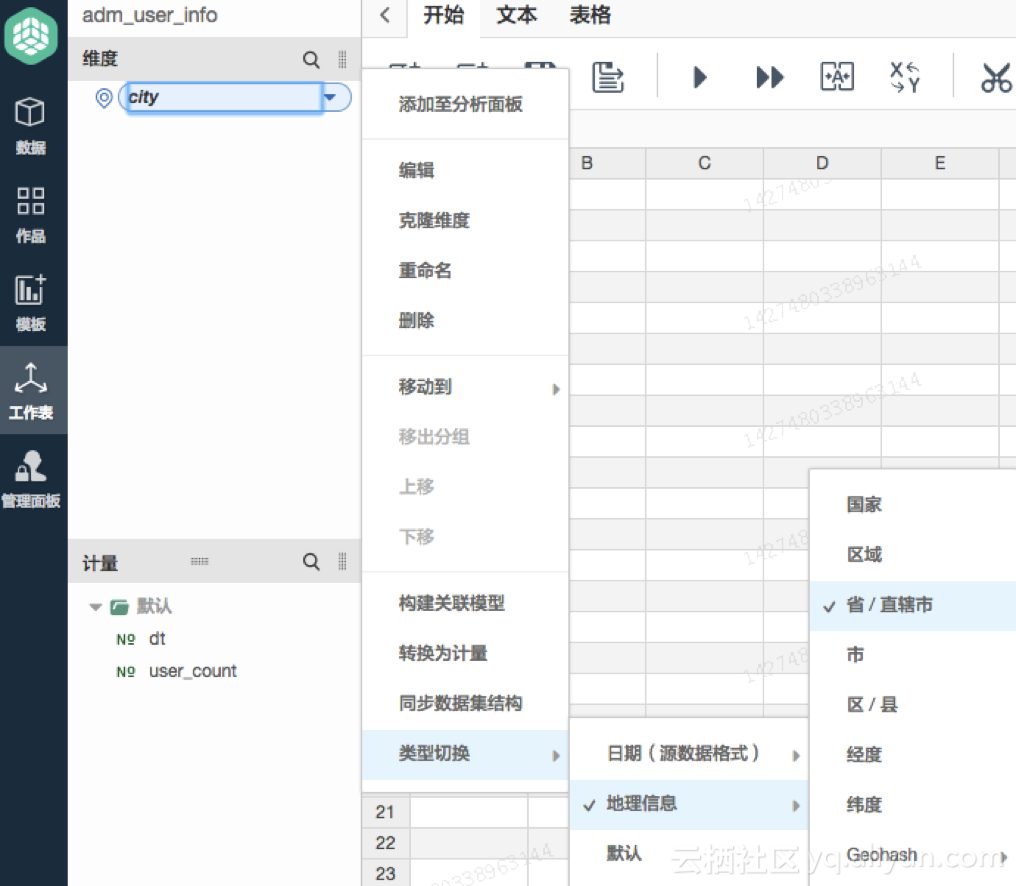
创建图表模板
操作步骤
点击左侧 模板 进入,选择空白图表模板。按照自己需要的布局进行。
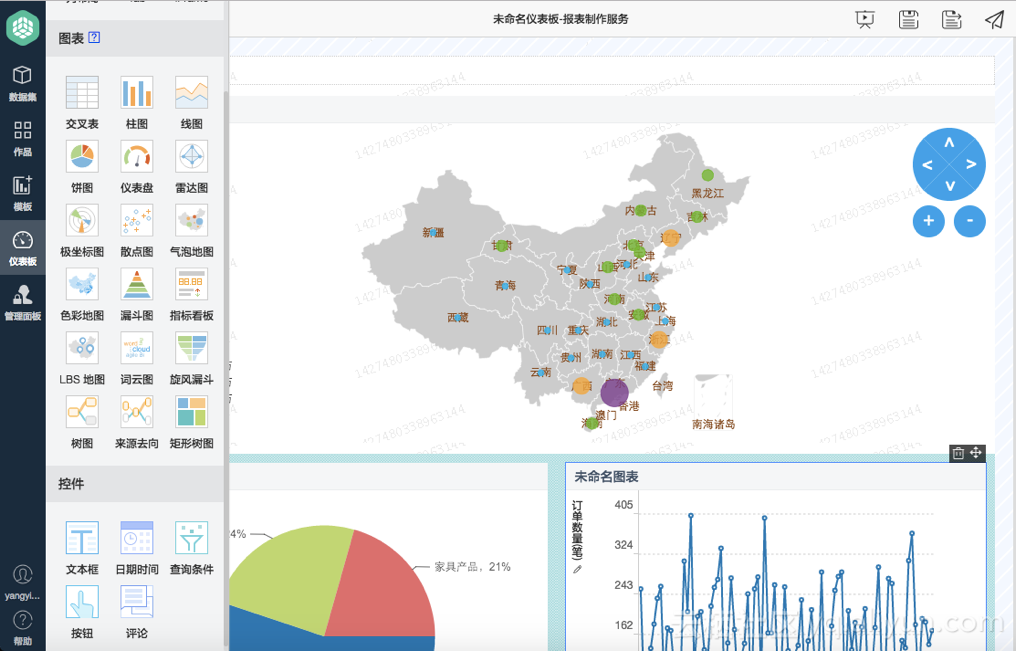
针对每个图标可以在右侧进行关联数据集,如来自工作表..等。最终实现的效果如下: