随着技术的快速发展,在数据科学领域中,包括库、工具和算法等总会不断地变化的。然而,一直都有这么一个趋势,那就是自动化水平不断地提高。
近些年来,在模型的自动化选择和超参数调整方面取得了一些进展,但是机器学习中最重要的领域 — 特征工程,却被严重地忽视了。这个重要领域中最成熟的工具就是Featuretools,一个开源的Python库。在本文中,我们将使用这个库来了解一下特征工程自动化将如何改变你更好地进行机器学习的方式。

特征工程自动化是一种相对较新的技术,但是,它解决了许多实际数据集的使用问题。在这里,我们将用GitHub上的Jupyter Notebooks提供的代码来看看其中两个项目的结果和最终结论。
每个项目都强调了特征工程自动化的一些好处:
·贷款偿还能力预测:与人工特征工程相比,自动化的特征工程可以将机器学习开发的时间缩短10倍,同时提供更好的建模性能表现;(笔记)
·消费支出预测:自动化的特征工程通过内部的处理时间序列过滤器来创建有实际意义的特征,同时防止数据泄漏,从而实现成功的模型部署;(笔记)
特征工程:人工与自动
特征工程是获取数据集并构造可解释的变量—特征的过程,用于训练预测问题的机器学习模型。通常,数据分布在多个表中,并且必须汇集到一个表之中,其中的行包含观察结果和列中的特征。
传统的特征工程方法是使用相关领域知识创建一个特征,这是一个冗长、耗时且容易出错的过程,称为人工特征工程。人工特征工程是依赖于具体问题的,必须为每个新数据集重新编写代码。
特征工程自动化通过自动从一组相关的数据表中提取有用且有意义的特征,并使用一个可应用于任何问题的框架,来改进这个标准工作流。它不仅减少了在特征工程上花费的时间,而且还创建了可解释的特征,并通过过滤具有时间依赖性的数据来防止数据泄漏。
贷款偿还:建立更快更好的模型
当数据科学家在处理家庭信贷贷款问题的时候,所面临的主要难题是数据的大小和分布。看看完整的数据集,你会发现面对的是分布在7个表中的5800万行数据。
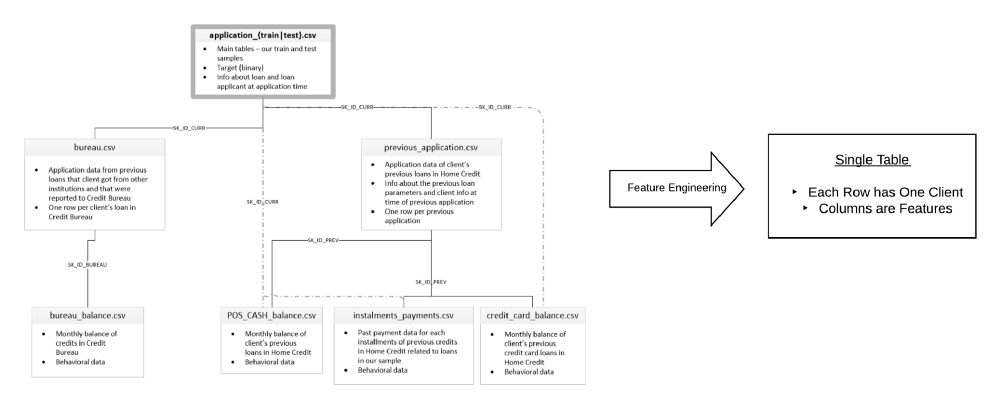
特征工程需要将一组相关表中的所有信息放到一个表中
我曾经使用传统的人工特征工程花了10个小时创建了一组特征。首先,我查阅了其他数据科学家的成果,还查看了相关的数据,并研究了问题域,以获得必要的相关领域知识。然后我将这些知识翻译成代码,一次创建一个特征。作为单一的人工特征的一个例子,我找到了客户以前贷款的逾期还款总数,这一操作需要用到3个不同的表。
最终人工设计的特征表现的相当好,比基线特征提高了65%,表明了正确特征设计的重要性。
然而,效率却非常低下。对于人工特征工程,我最终花了超过15分钟来完成每个特征,因为我使用传统的方法一次生成一个特性。
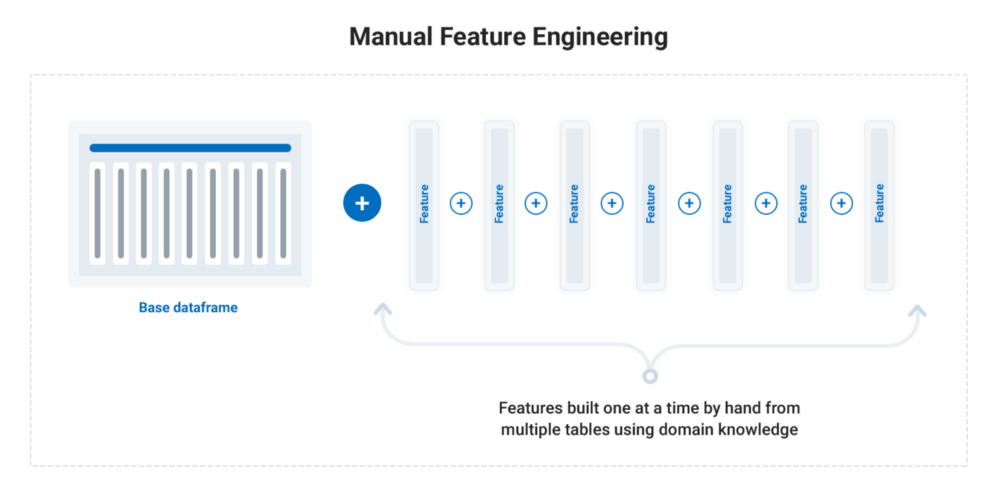
人工特征工程过程
除了单调乏味和耗时之外,人工特征工程还有以下问题:
·用于特定问题:我花费了很长时间编写的代码并不能应用于任何其它的问题;
·易错:每一行代码都会有可能导致其它的错误;
另外,最终的人工设计的特征受到了人类创造力和耐心方面的限制:我们只能考虑创建这么多的特征,并且只能花费这么多的时间。
特征工程自动化的承诺是通过获取一组相关的表,并使用可以应用于所有问题的代码,来自动创建数以百计有用的特征,进而跨越这些限制。
从人工到自动化特征工程
特征工程自动化甚至允许像我这样的新手,在一组相关的数据表中可以创建数以千计的相关特征。我们只需要知道表的基本结构以及它们之间的关系,我们在一个称为实体集的单一数据结构中来跟踪它们。一旦我们有了一个实体集,使用一个称为深度特征合成(Deep Feature Synthesis,DFS)的方法,我们就能够在一个函数调用中创建数以千计的特征了。
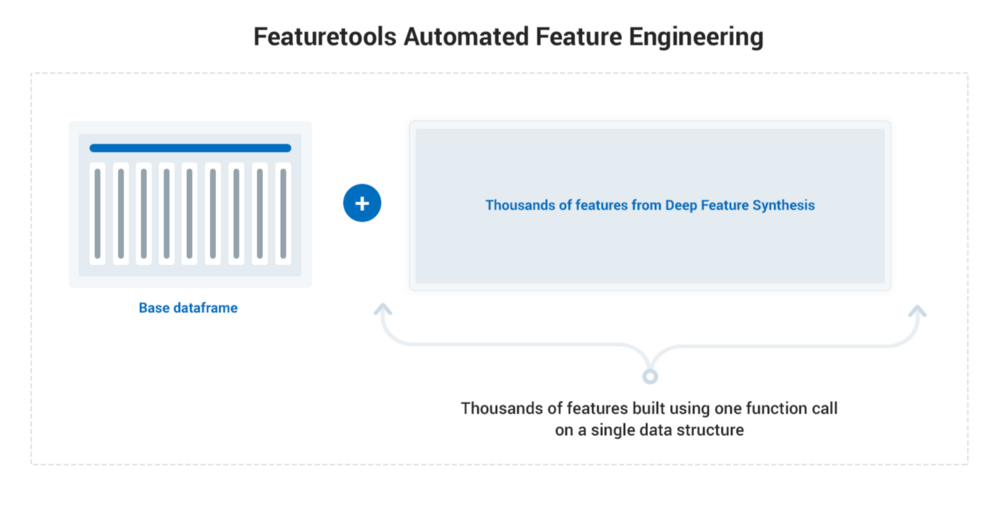
使用FeatureTools的特征工程自动化过程
DFS使用称为“primitives”的函数来进行聚合和转换数据。这些primitives可以简单到仅获取一个平均值或列的最大值,也可以复杂到基于主题的专业知识,因为FeatureTools允许我们定义自己的primitives。
特征primitives包括许多人工操作,但是通过使用FeatureTools,我们可以在任何关系数据库中使用相同准确的语法,而不是再重新编写代码并在不同的数据集中使用相同的操作。此外,当我们将primitives相互堆叠在一起来创建深层次的特征时,DFS的威力就来了。
深度特征合成是灵活的,它被允许应用于任何数据科学领域的问题。它同时也是很强大的,通过创建深度特征来揭示我们对数据的推断。
我会为你省去环境设置所需的几行代码,但DFS只在一行中运行。在这里,我们使用数据集中的所有7个表为每个客户生成数千个特征:
# Deep feature synthesis
feature_matrix, features = ft.dfs(entityset=es,
target_entity='clients',
agg_primitives = agg_primitives,
trans_primitives = trans_primitives)下面是我们自动从FeatureTools获得的1820个特征中的一部分:
·客户以前贷款的最高总额。这是在3个表中使用1个MAX 和1个SUM 的primitive得来的;
·客户以前的信用卡平均债务的百分比排名,这在两个表中使用了百分比(PERCENTILE)和平均值(MEAN)的primitive;
·在申请过程中,客户是否提交了两份文件,这将使用1个AND 转换primitive和1个表;
这些特征中的任何一个都是用简单的聚合创建的。FeatureTools创建了许多与我手工创建的相同的特征,但也有数千个是我从未考虑过的。并不是每一个特征都与问题相关,有些特征是高度相关的,然而,拥有太多的特征是一个比拥有太少的特征更好解决的问题。
在进行了一些功能选择和模型优化之后,与人工特征相比,预测模型中的这些特征要稍好一些,总体开发时间为1小时,与人工的过程相比减少了10倍。FeatureTools速度更快,这是因为它需要的领域知识更少,而且要编写的代码行也少的相当多。
我承认学习Featuretools需要一点时间成本,但这是一项有回报的投资。在花了一个小时左右的时间学习Featuretools之后,你就可以将其应用于任何机器学习问题了。
以下的图表总结了我在贷款偿还问题上的经验:
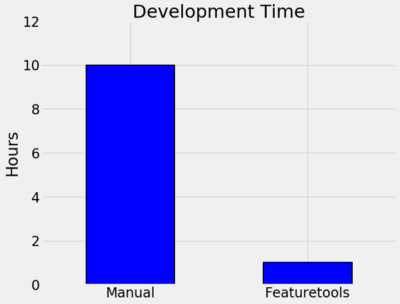
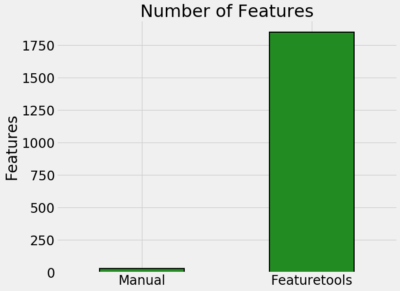
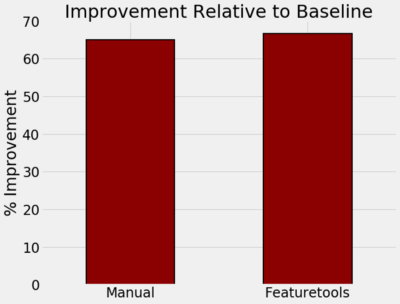
自动和人工特征工程按时间、特征的数量和性能之间的比较
·开发时间:10小时人工与1小时自动;
·该方法创建的特征数量: 30个人工特征与1820个自动特征;
·相对于基线提高了的百分比是:65% 人工 vs 66% 自动
我的结论是,特征工程自动化不会取代数据科学家,而是通过显著地提高效率,使他们在机器学习的其它方面可以花费更多的时间。
另外,我为第一个项目编写的Featuretools代码可以应用于任何数据集,而人工工程的代码则没法再利用。
消费支出:创建有意义的特征并防止数据泄漏
第二个数据集,在线时间戳的客户交易记录,预测问题是将客户分为两个部分,消费超过500美元的客户和消费不会超过500美元的客户。但是,不是对所有标签使用一个月,而是每个客户多次使用一个标签。我们可以把他们5月份的消费支出作为一个标签,然后6月份的,等等。
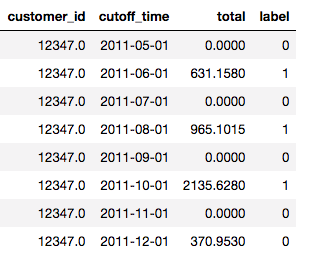
客户被多次用作训练示例
在部署中,我们永远不会有未来的数据,因此无法将其用于训练模型。企业通常会遇到这个问题,并且经常部署一个在实际应用中比在开发中更糟糕的模型,因为这是使用无效的数据来进行训练的。
幸运的是,要确保我们的数据在时间序列问题中是有效的,这在FeatureTools中很简单。在深度特征合成函数中,我们传递一个如上图所示的dataframe,其中截止时间表示我们不能使用任何标签数据中过去的时间点,FeatureTools在创建特征时会自动考虑时间。
客户在指定月份的特征是使用过滤到该月份之前的数据来创建的。请注意,用于创建特征集的调用与添加截止时间的贷款偿还问题的调用相同。
# Deep feature synthesis
feature_matrix, features = ft.dfs(entityset=es,
target_entity='customers',
agg_primitives = agg_primitives,
trans_primitives = trans_primitives,
cutoff_time = cutoff_times)执行深度特征合成的结果是一个特征表,每个客户一个月一个。我们可以使用这些特征来训练一个带有标签的模型,然后可以对任何月份进行预测。此外,我们可以放心,模型中的特征不会使用导致不公平优势的未来信息,并产生误导训练的分数。
有了自动化特征,我能够创建一个机器学习模型,在预测一个月内客户消费支出类别的时候,与已知为0.69的基线相比,ROC AUC达到0.90。
除了提供令人印象深刻的预测能力之外,FeatureTools的实现还为我提供了一些同样有价值的东西:可解释的特征。看一下随机森林模型中的15个最重要的特征:
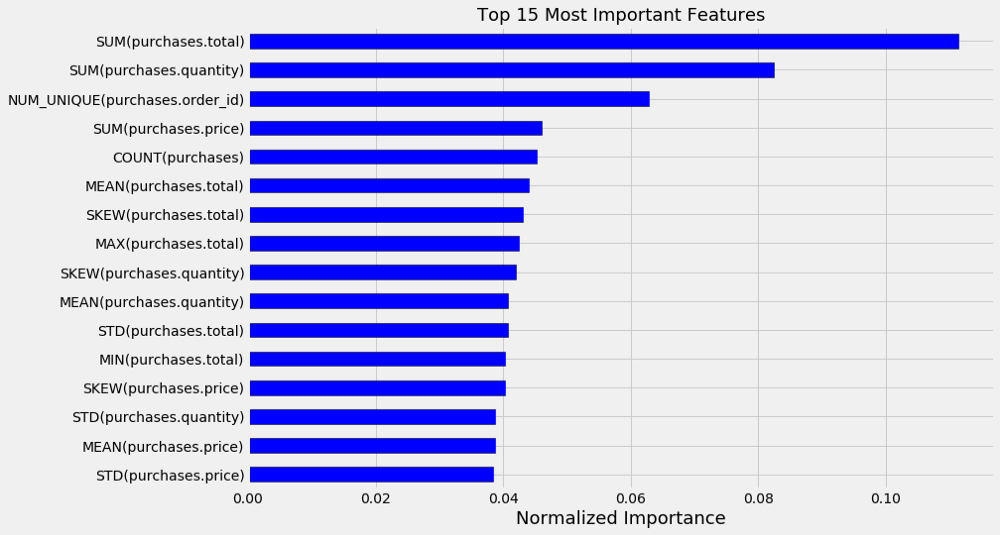
15个来自随机森林模型的最重要的特征
特征的重要性告诉我们,预测客户将在下个月花多少钱的最重要素是他们之前花了多少钱SUM,以及购物的数量SUM。这些是可以手工创建的特征,但是我们不得不担心数据泄漏的问题,并创建在开发中比部署中效果要好的模型。
如果可以创建有意义的特征工具已经存在了,而无需担心任何特征的有效性,那么为什么要人工实现呢?另外,自动化特征在问题的上下文中是完全明确的,并且可以为我们的实际推理提供信息。
自动化特征工程识别出最重要的信号,实现了数据科学的主要目标:揭示隐藏在海量数据中的规律。
即使在人工特征工程上花费的时间比我用FeatureTools花的时间多得多,那么我也无法开发出一组性能表现接近的特征。下图显示了使用在两个数据集上训练的模型对未来一个月的客户销售情况进行分类的ROC曲线。左上方的曲线表示更准确的预测:
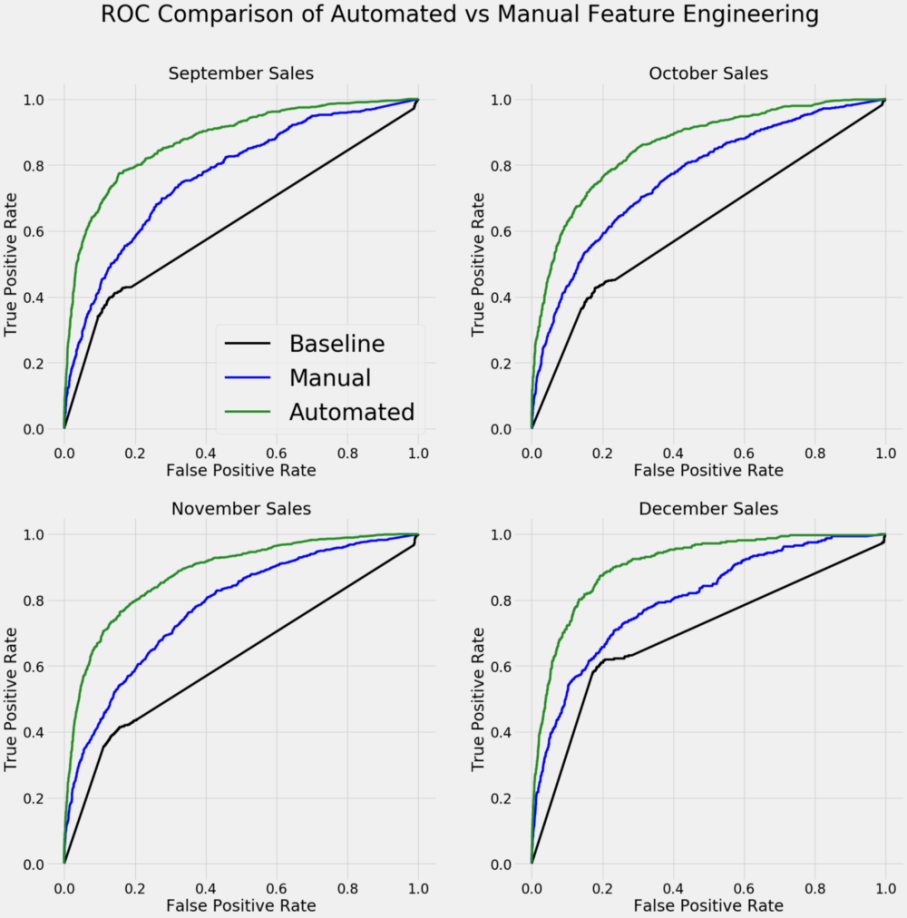
比较自动的和人工的特征工程结果的ROC曲线,左侧和顶部的曲线表示其性能表现更好。
我甚至不能完全确定人工特征是否使用了有效的数据,但是通过FeatureTools我不必担心时间依赖性问题中的数据泄漏。
我们在日常生活中使用自动安全系统,Featuretools中的特征工程自动化是在时间序列问题中创建有意义的机器学习特征的安全方法,同时提供了卓越的预测性能表现。
结论
我经过了这些项目之后,确信特征工程自动化应该是机器学习工作流程中不可或缺的一部分。这项技术并不完美,但依旧能显著地提高效率。
主要的结论就是特征工程自动化:
·将执行时间缩短了10倍;
·在同一级别或更高级别上实现的建模性能;
·交付的具有实际意义的可解释性特征;
·防止使用不正确的数据而导致的模型无效;
·适应现有的工作流程和机器学习模型;
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Why Automated Feature Engineering Will Change the Way You Do Machine Learning》
译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文
