目前,大多数的数据科学家都比较熟悉主成分分析 (Principal Components Analysis,PCA),它是一个探索性的数据分析工具。可以这样简要的描述:研究人员经常使用PCA来降低维度,希望在他们的数据中找出有用的信息(例如疾病与非疾病的分类)。PCA是通过寻找正交投影(Orthogonal Projection)向量来实现这一点的,正交投影向量说明了数据中的最大方差量。在实践中,这通常是用奇异值分解(Singular Value Decomposition,SVD)的方法来找到主成分(特征向量),并通过其对数据总方差的贡献(特征值)加权。毫无疑问,在我的专业领域以及许多其它的领域中,PCA是最常用的数据分析工具,但是当它不起作用的时候会发生什么呢?这是否意味着抽样试验的效果不好呢?这是否意味着数据中没有有用的信息呢?我们的小组致力于为化学专业开发新的数据分析工具。在这里,我要给为大家介绍一个PCA的替代方案,叫做投影追踪分析(Projection Pursuit Analysis ,PPA)。
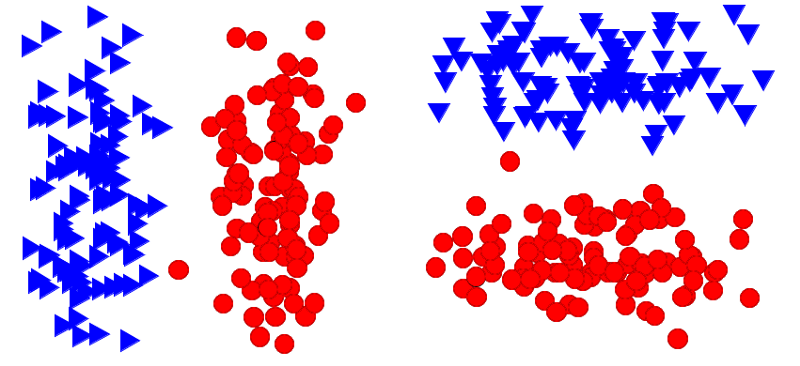
一般因素分析模型
基于方差运算的PCA
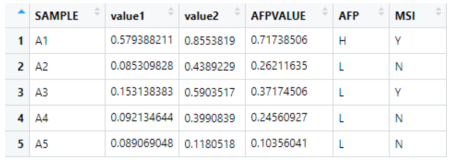
PCA失败在哪了呢?像上面描述的那样,PCA通过在数据中找到最大方差的方向来进行操作。那么如果投射到那个方向上没有效果呢?下图是由200个样本的模拟数据组成的,这些数据形成了两个分离的集群,它们沿着Y轴的方差大于沿着X轴的方差。如果我们对这个二维数据进行PCA操作,那么会得到投影向量v,它将是2×1的列向量([0;1])。投射到这个向量上的原始数据X(200x2)给出了我们的得分T=Xv。在把这些得分可视化之后表明了两个集群之间没有明显的分离。相反,如果我们投射到x轴上(v=[1;0]),那么很容易地就会看到这两个集群中的分离状态。那么我们如何在高维的数据中找到这个向量呢?
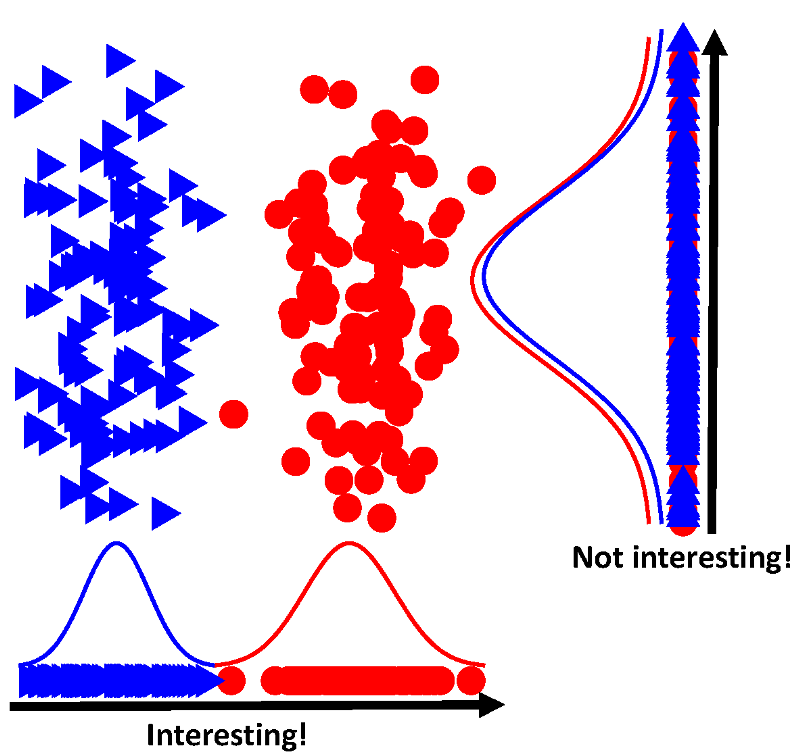
“有趣的”投影显示了分类信息
投影追踪
投影追踪方法最初是由Friedman和Tukey在1974年的时候提出来的,他们试图根据投影指数的最大化或最小化来在数据中找到“有趣的”投影。通过扩展,在PCA框架中,投影指数(方差)被最大化了。现在的问题是,什么样的是好的预测指数呢?数据科学家们在定义新的投影指数方面已经做了大量的研究,但是今天我要关注的一个已经被证明对探索化学领域数据有用的指标是峰态系数(kurtosis)。
基于峰态系数的投影追踪(Kurtosis-based projection pursuit)
第四个统计矩,峰态系数,已被证明了是一个很有用的投影指数 (https://www.sciencedirect.com/science/article/pii/S0003267011010804)。
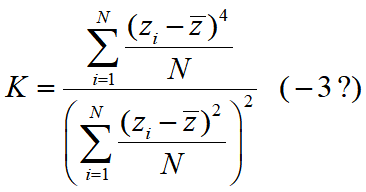
单变量的峰态系数
当峰态系数最大化时,它往往会显示数据中的异常值。这会有些用处,但是实际上它并不是我们想要寻找并显示类或集群信息的东西。然而,当峰态系数最小化时,它将1个维度中的数据分为2组(2个维度中分为4组,3个维度中分为8组)。
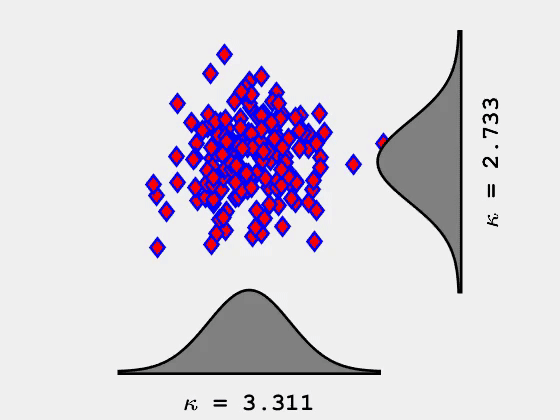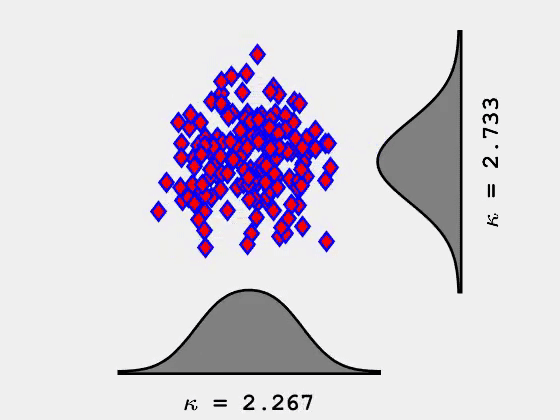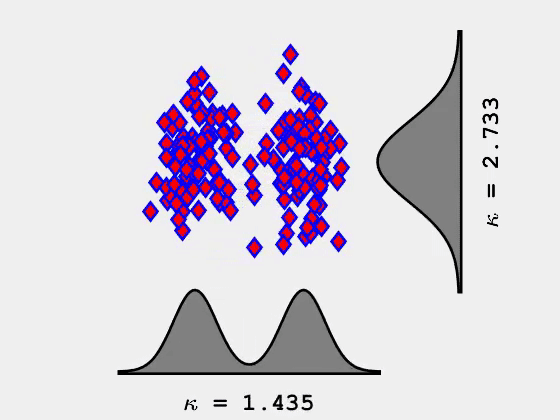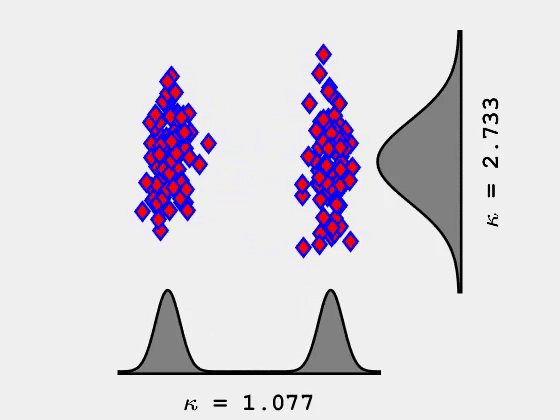
峰态系数最小化
现在最大的问题是如何使用峰态系数查找这些投影向量?Quasai-power学习算法. 请见https://www.sciencedirect.com/science/article/pii/S0003267011010804。本文中,Hou和Wentzell证明了利用下面的学习算法可以找到最小化峰态系数的投影向量:
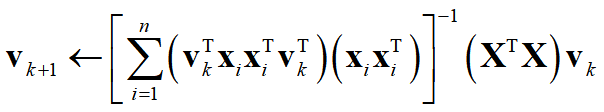
寻找最小化峰态系数的投影向量
实例模拟
让我们同时利用PCA和PPA两种技术来模拟一些数据。与打开的图形类似,我们的数据将会分为两个类,每个类有100个样本,并且只需要1个维度来显示类分离。第一个类在x轴上以-4为中心,标准偏差为5,而第二类则以+4为中心,标准偏差也是5。
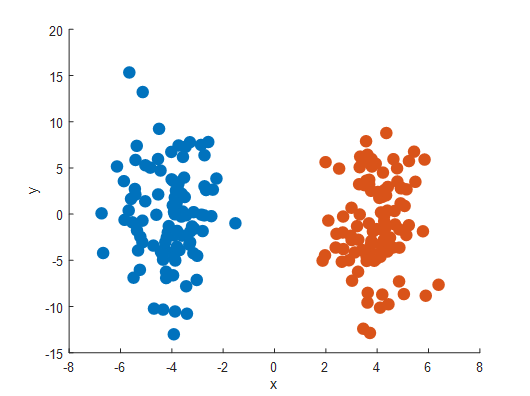
原始数据
为了使这个模拟更真实,让我们通过乘以一个2 x 600的随机旋转矩阵,将这个200 x 2的矩阵旋转为600个维度。这就是我们现在需要利用探索工具来找到数据中一些有趣的投影的地方。首先,让列的平均值集中我们的数据,同时应用PCA,并将第一个成分可视化为一个样本数量的函数。
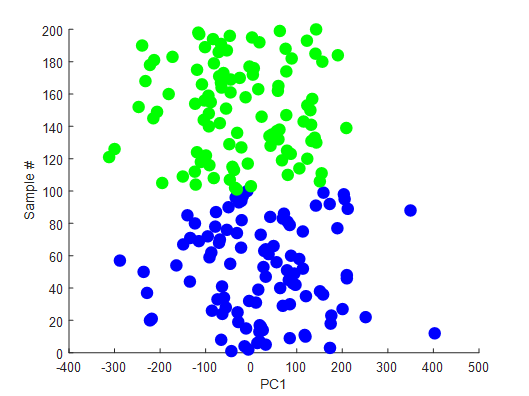
来自PCA的第一个成分
我们会看到,向下投射到第一个PC上的数据不会显示类信息。那我们现在就来应用PPA。
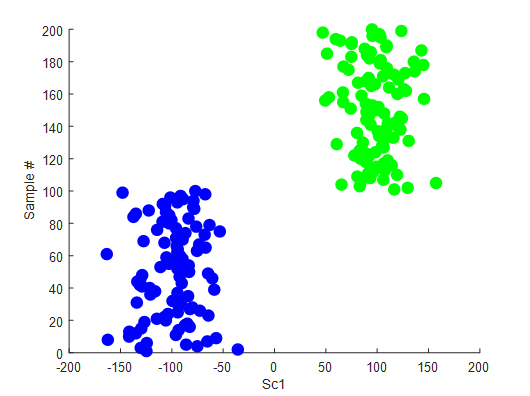
来自PPA的第一个得分
PPA能够找到对我们有用的投影(即提供类分离的投影)。
PPA的问题
尽管在大多数的情况下,我们发现PPA的性能都优于PCA,但是当PPA没有效果的时候,有一些重要的注意事项需要在这里说明一下。当类的大小不相等的时候,PPA就不会正常地工作了,例如,如果我在上面的实例中使用5:1的类比率并应用PPA,我们会得到以下结果:
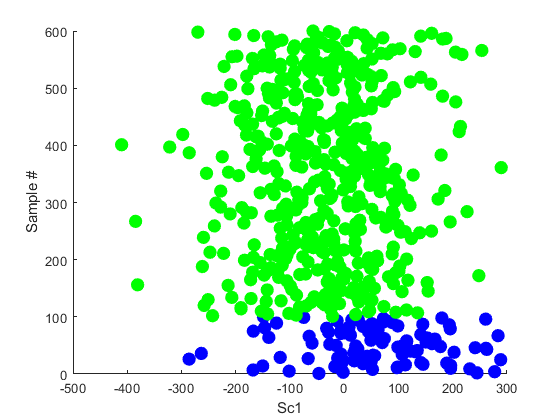
由于分离的几何学方面的原因,当类的数量不是2的n次方时,PPA也会有问题。PPA也会遇到过度拟合问题,并且通常需要执行数据压缩,大约需要10:1的样本与变量比率。否则,该算法就将人工地把样本忽略掉。我们小组目前的工作是开发一些能缓解这些问题的方法,好消息是我们应该在未来的几个月之内就会发表一些关于这方面的论文!我一定会及时通知大家的。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《“Interesting” Projections — Where PCA Fails》
译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文