Kube Controller Manager 源码分析
Controller Manager 在k8s 集群中扮演着中心管理的角色,它负责Deployment, StatefulSet, ReplicaSet 等资源的创建与管理,可以说是k8s的核心模块,下面我们以概略的形式走读一下k8s Controller Manager 代码。
func NewControllerManagerCommand() *cobra.Command {
s, err := options.NewKubeControllerManagerOptions()
if err != nil {
klog.Fatalf("unable to initialize command options: %v", err)
}
cmd := &cobra.Command{
Use: "kube-controller-manager",
Long: `The Kubernetes controller manager is a daemon that embeds
the core control loops shipped with Kubernetes. In applications of robotics and
automation, a control loop is a non-terminating loop that regulates the state of
the system. In Kubernetes, a controller is a control loop that watches the shared
state of the cluster through the apiserver and makes changes attempting to move the
current state towards the desired state. Examples of controllers that ship with
Kubernetes today are the replication controller, endpoints controller, namespace
controller, and serviceaccounts controller.`,
Run: func(cmd *cobra.Command, args []string) {
verflag.PrintAndExitIfRequested()
utilflag.PrintFlags(cmd.Flags())
c, err := s.Config(KnownControllers(), ControllersDisabledByDefault.List())
if err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
if err := Run(c.Complete(), wait.NeverStop); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
},
}Controller Manager 也是一个命令行,通过一系列flag启动,具体的各个flag 我们就不多看,有兴趣的可以去文档或者flags_opinion.go 文件里面去过滤一下,我们直接从Run 函数入手。
Run Function 启动流程
Kube Controller Manager 既可以单实例启动,也可以多实例启动。 如果为了保证 HA 而启动多个Controller Manager,它就需要选主来保证同一时间只有一个Master 实例。我们来看一眼Run 函数的启动流程,这里会把一些不重要的细节函数略过,只看重点
func Run(c *config.CompletedConfig, stopCh <-chan struct{}) error {
run := func(ctx context.Context) {
rootClientBuilder := controller.SimpleControllerClientBuilder{
ClientConfig: c.Kubeconfig,
}
controllerContext, err := CreateControllerContext(c, rootClientBuilder, clientBuilder, ctx.Done())
if err != nil {
klog.Fatalf("error building controller context: %v", err)
}
if err := StartControllers(controllerContext, saTokenControllerInitFunc, NewControllerInitializers(controllerContext.LoopMode), unsecuredMux); err != nil {
klog.Fatalf("error starting controllers: %v", err)
}
controllerContext.InformerFactory.Start(controllerContext.Stop)
close(controllerContext.InformersStarted)
select {}
}
id, err := os.Hostname()
if err != nil {
return err
}
// add a uniquifier so that two processes on the same host don't accidentally both become active
id = id + "_" + string(uuid.NewUUID())
rl, err := resourcelock.New(c.ComponentConfig.Generic.LeaderElection.ResourceLock,
"kube-system",
"kube-controller-manager",
c.LeaderElectionClient.CoreV1(),
resourcelock.ResourceLockConfig{
Identity: id,
EventRecorder: c.EventRecorder,
})
if err != nil {
klog.Fatalf("error creating lock: %v", err)
}
leaderelection.RunOrDie(context.TODO(), leaderelection.LeaderElectionConfig{
Lock: rl,
LeaseDuration: c.ComponentConfig.Generic.LeaderElection.LeaseDuration.Duration,
RenewDeadline: c.ComponentConfig.Generic.LeaderElection.RenewDeadline.Duration,
RetryPeriod: c.ComponentConfig.Generic.LeaderElection.RetryPeriod.Duration,
Callbacks: leaderelection.LeaderCallbacks{
OnStartedLeading: run,
OnStoppedLeading: func() {
klog.Fatalf("leaderelection lost")
},
},
WatchDog: electionChecker,
Name: "kube-controller-manager",
})
panic("unreachable")
}这里的基本流程如下:
- 首先定义了run 函数,run 函数负责具体的controller 构建以及最终的controller 操作的执行
- 使用Client-go 提供的选主函数来进行选主
- 如果获得主权限,那么就调用
OnStartedLeading注册函数,也就是上面的run 函数来执行操作,如果没选中,就hang住等待
选主流程解析
Client-go 选主工具类主要是通过kubeClient 在Configmap或者Endpoint选择一个资源创建,然后哪一个goroutine 创建成功了资源,哪一个goroutine 获得锁,当然所有的锁信息都会存在Configmap 或者Endpoint里面。之所以选择这两个资源类型,主要是考虑他们被Watch的少,但是现在kube Controller Manager 还是适用的Endpoint,后面会逐渐迁移到ConfigMap,因为Endpoint会被kube-proxy Ingress Controller等频繁Watch,我们来看一眼集群内Endpoint内容
[root@iZ8vb5qgxqbxakfo1cuvpaZ ~]# kubectl get ep -n kube-system kube-controller-manager -o yaml
apiVersion: v1
kind: Endpoints
metadata:
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"iZ8vbccmhgkyfdi8aii1hnZ_d880fea6-1322-11e9-913f-00163e033b49","leaseDurationSeconds":15,"acquireTime":"2019-01-08T08:53:49Z","renewTime":"2019-01-22T11:16:59Z","leaderTransitions":1}'
creationTimestamp: 2019-01-08T08:52:56Z
name: kube-controller-manager
namespace: kube-system
resourceVersion: "2978183"
selfLink: /api/v1/namespaces/kube-system/endpoints/kube-controller-manager
uid: cade1b65-1322-11e9-9931-00163e033b49可以看到,这里面涵盖了当前Master ID,获取Master的时间,更新频率以及下一次更新时间。这一切最终还是靠ETCD 完成的选主。主要的选主代码如下
func New(lockType string, ns string, name string, client corev1.CoreV1Interface, rlc ResourceLockConfig) (Interface, error) {
switch lockType {
case EndpointsResourceLock:
return &EndpointsLock{
EndpointsMeta: metav1.ObjectMeta{
Namespace: ns,
Name: name,
},
Client: client,
LockConfig: rlc,
}, nil
case ConfigMapsResourceLock:
return &ConfigMapLock{
ConfigMapMeta: metav1.ObjectMeta{
Namespace: ns,
Name: name,
},
Client: client,
LockConfig: rlc,
}, nil
default:
return nil, fmt.Errorf("Invalid lock-type %s", lockType)
}
}StartController
选主完毕后,就需要真正启动controller了,我们来看一下启动controller 的代码
func StartControllers(ctx ControllerContext, startSATokenController InitFunc, controllers map[string]InitFunc, unsecuredMux *mux.PathRecorderMux) error {
// Always start the SA token controller first using a full-power client, since it needs to mint tokens for the rest
// If this fails, just return here and fail since other controllers won't be able to get credentials.
if _, _, err := startSATokenController(ctx); err != nil {
return err
}
// Initialize the cloud provider with a reference to the clientBuilder only after token controller
// has started in case the cloud provider uses the client builder.
if ctx.Cloud != nil {
ctx.Cloud.Initialize(ctx.ClientBuilder, ctx.Stop)
}
for controllerName, initFn := range controllers {
if !ctx.IsControllerEnabled(controllerName) {
klog.Warningf("%q is disabled", controllerName)
continue
}
time.Sleep(wait.Jitter(ctx.ComponentConfig.Generic.ControllerStartInterval.Duration, ControllerStartJitter))
klog.V(1).Infof("Starting %q", controllerName)
debugHandler, started, err := initFn(ctx)
if err != nil {
klog.Errorf("Error starting %q", controllerName)
return err
}
if !started {
klog.Warningf("Skipping %q", controllerName)
continue
}
if debugHandler != nil && unsecuredMux != nil {
basePath := "/debug/controllers/" + controllerName
unsecuredMux.UnlistedHandle(basePath, http.StripPrefix(basePath, debugHandler))
unsecuredMux.UnlistedHandlePrefix(basePath+"/", http.StripPrefix(basePath, debugHandler))
}
klog.Infof("Started %q", controllerName)
}
return nil
}- 遍历所有的controller list
- 执行每个controller 的Init Function
那么一共有多少Controller 呢
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
controllers := map[string]InitFunc{}
controllers["endpoint"] = startEndpointController
controllers["replicationcontroller"] = startReplicationController
controllers["podgc"] = startPodGCController
controllers["resourcequota"] = startResourceQuotaController
controllers["namespace"] = startNamespaceController
controllers["serviceaccount"] = startServiceAccountController
controllers["garbagecollector"] = startGarbageCollectorController
controllers["daemonset"] = startDaemonSetController
controllers["job"] = startJobController
controllers["deployment"] = startDeploymentController
controllers["replicaset"] = startReplicaSetController
controllers["horizontalpodautoscaling"] = startHPAController
controllers["disruption"] = startDisruptionController
controllers["statefulset"] = startStatefulSetController
controllers["cronjob"] = startCronJobController
controllers["csrsigning"] = startCSRSigningController
controllers["csrapproving"] = startCSRApprovingController
controllers["csrcleaner"] = startCSRCleanerController
controllers["ttl"] = startTTLController
controllers["bootstrapsigner"] = startBootstrapSignerController
controllers["tokencleaner"] = startTokenCleanerController
controllers["nodeipam"] = startNodeIpamController
controllers["nodelifecycle"] = startNodeLifecycleController
if loopMode == IncludeCloudLoops {
controllers["service"] = startServiceController
controllers["route"] = startRouteController
controllers["cloud-node-lifecycle"] = startCloudNodeLifecycleController
// TODO: volume controller into the IncludeCloudLoops only set.
}
controllers["persistentvolume-binder"] = startPersistentVolumeBinderController
controllers["attachdetach"] = startAttachDetachController
controllers["persistentvolume-expander"] = startVolumeExpandController
controllers["clusterrole-aggregation"] = startClusterRoleAggregrationController
controllers["pvc-protection"] = startPVCProtectionController
controllers["pv-protection"] = startPVProtectionController
controllers["ttl-after-finished"] = startTTLAfterFinishedController
controllers["root-ca-cert-publisher"] = startRootCACertPublisher
return controllers
}答案就在这里,上面的代码列出来了当前kube controller manager 所有的controller,既有大家熟悉的Deployment StatefulSet 也有一些不熟悉的身影。下面我们以Deployment 为例看看它到底干了什么
Deployment Controller
先来看一眼Deployemnt Controller 启动函数
func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) {
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "apps", Version: "v1", Resource: "deployments"}] {
return nil, false, nil
}
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
}
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}看到这里,如果看过上一篇针对Client-go Informer 文章的肯定不陌生,这里又使用了InformerFactory,而且是好几个。其实kube Controller Manager 里面大量使用了Informer,Controller 就是使用 Informer 来通知和观察所有的资源。可以看到,这里Deployment Controller 主要关注Deployment ReplicaSet Pod 这三个资源。
Deployment Controller 资源初始化
下面来看一下Deployemnt Controller 初始化需要的资源
// NewDeploymentController creates a new DeploymentController.
func NewDeploymentController(dInformer appsinformers.DeploymentInformer, rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, client clientset.Interface) (*DeploymentController, error) {
eventBroadcaster := record.NewBroadcaster()
eventBroadcaster.StartLogging(klog.Infof)
eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: client.CoreV1().Events("")})
if client != nil && client.CoreV1().RESTClient().GetRateLimiter() != nil {
if err := metrics.RegisterMetricAndTrackRateLimiterUsage("deployment_controller", client.CoreV1().RESTClient().GetRateLimiter()); err != nil {
return nil, err
}
}
dc := &DeploymentController{
client: client,
eventRecorder: eventBroadcaster.NewRecorder(scheme.Scheme, v1.EventSource{Component: "deployment-controller"}),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "deployment"),
}
dc.rsControl = controller.RealRSControl{
KubeClient: client,
Recorder: dc.eventRecorder,
}
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
dc.syncHandler = dc.syncDeployment
dc.enqueueDeployment = dc.enqueue
dc.dLister = dInformer.Lister()
dc.rsLister = rsInformer.Lister()
dc.podLister = podInformer.Lister()
dc.dListerSynced = dInformer.Informer().HasSynced
dc.rsListerSynced = rsInformer.Informer().HasSynced
dc.podListerSynced = podInformer.Informer().HasSynced
return dc, nil
}是不是这里的代码似曾相识,如果接触过Client-go Informer 的代码,可以看到这里如出一辙,基本上就是对创建的资源分别触发对应的Add Update Delete 函数,同时所有的资源通过Lister获得,不需要真正的Query APIServer。
先来看一下针对Deployment 的Handler
func (dc *DeploymentController) addDeployment(obj interface{}) {
d := obj.(*apps.Deployment)
klog.V(4).Infof("Adding deployment %s", d.Name)
dc.enqueueDeployment(d)
}
func (dc *DeploymentController) updateDeployment(old, cur interface{}) {
oldD := old.(*apps.Deployment)
curD := cur.(*apps.Deployment)
klog.V(4).Infof("Updating deployment %s", oldD.Name)
dc.enqueueDeployment(curD)
}
func (dc *DeploymentController) deleteDeployment(obj interface{}) {
d, ok := obj.(*apps.Deployment)
if !ok {
tombstone, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
utilruntime.HandleError(fmt.Errorf("Couldn't get object from tombstone %#v", obj))
return
}
d, ok = tombstone.Obj.(*apps.Deployment)
if !ok {
utilruntime.HandleError(fmt.Errorf("Tombstone contained object that is not a Deployment %#v", obj))
return
}
}
klog.V(4).Infof("Deleting deployment %s", d.Name)
dc.enqueueDeployment(d)
}不论是Add Update Delete,处理方法如出一辙,都是一股脑的塞到Client-go 提供的worker Queue里面。 再来看看ReplicaSet
func (dc *DeploymentController) addReplicaSet(obj interface{}) {
rs := obj.(*apps.ReplicaSet)
if rs.DeletionTimestamp != nil {
// On a restart of the controller manager, it's possible for an object to
// show up in a state that is already pending deletion.
dc.deleteReplicaSet(rs)
return
}
// If it has a ControllerRef, that's all that matters.
if controllerRef := metav1.GetControllerOf(rs); controllerRef != nil {
d := dc.resolveControllerRef(rs.Namespace, controllerRef)
if d == nil {
return
}
klog.V(4).Infof("ReplicaSet %s added.", rs.Name)
dc.enqueueDeployment(d)
return
}
// Otherwise, it's an orphan. Get a list of all matching Deployments and sync
// them to see if anyone wants to adopt it.
ds := dc.getDeploymentsForReplicaSet(rs)
if len(ds) == 0 {
return
}
klog.V(4).Infof("Orphan ReplicaSet %s added.", rs.Name)
for _, d := range ds {
dc.enqueueDeployment(d)
}
}func (dc *DeploymentController) updateReplicaSet(old, cur interface{}) {
curRS := cur.(*apps.ReplicaSet)
oldRS := old.(*apps.ReplicaSet)
if curRS.ResourceVersion == oldRS.ResourceVersion {
// Periodic resync will send update events for all known replica sets.
// Two different versions of the same replica set will always have different RVs.
return
}
curControllerRef := metav1.GetControllerOf(curRS)
oldControllerRef := metav1.GetControllerOf(oldRS)
controllerRefChanged := !reflect.DeepEqual(curControllerRef, oldControllerRef)
if controllerRefChanged && oldControllerRef != nil {
// The ControllerRef was changed. Sync the old controller, if any.
if d := dc.resolveControllerRef(oldRS.Namespace, oldControllerRef); d != nil {
dc.enqueueDeployment(d)
}
}
// If it has a ControllerRef, that's all that matters.
if curControllerRef != nil {
d := dc.resolveControllerRef(curRS.Namespace, curControllerRef)
if d == nil {
return
}
klog.V(4).Infof("ReplicaSet %s updated.", curRS.Name)
dc.enqueueDeployment(d)
return
}
// Otherwise, it's an orphan. If anything changed, sync matching controllers
// to see if anyone wants to adopt it now.
labelChanged := !reflect.DeepEqual(curRS.Labels, oldRS.Labels)
if labelChanged || controllerRefChanged {
ds := dc.getDeploymentsForReplicaSet(curRS)
if len(ds) == 0 {
return
}
klog.V(4).Infof("Orphan ReplicaSet %s updated.", curRS.Name)
for _, d := range ds {
dc.enqueueDeployment(d)
}
}
}总结一下Add 和 Update
- 根据ReplicaSet ownerReferences 寻找到对应的Deployment Name
- 判断是否Rs 发生了变化
- 如果变化就把Deployment 塞到Wokrer Queue里面去
最后看一下针对Pod 的处理
func (dc *DeploymentController) deletePod(obj interface{}) {
pod, ok := obj.(*v1.Pod)
// When a delete is dropped, the relist will notice a pod in the store not
// in the list, leading to the insertion of a tombstone object which contains
// the deleted key/value. Note that this value might be stale. If the Pod
// changed labels the new deployment will not be woken up till the periodic resync.
if !ok {
tombstone, ok := obj.(cache.DeletedFinalStateUnknown)
if !ok {
utilruntime.HandleError(fmt.Errorf("Couldn't get object from tombstone %#v", obj))
return
}
pod, ok = tombstone.Obj.(*v1.Pod)
if !ok {
utilruntime.HandleError(fmt.Errorf("Tombstone contained object that is not a pod %#v", obj))
return
}
}
klog.V(4).Infof("Pod %s deleted.", pod.Name)
if d := dc.getDeploymentForPod(pod); d != nil && d.Spec.Strategy.Type == apps.RecreateDeploymentStrategyType {
// Sync if this Deployment now has no more Pods.
rsList, err := util.ListReplicaSets(d, util.RsListFromClient(dc.client.AppsV1()))
if err != nil {
return
}
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return
}
numPods := 0
for _, podList := range podMap {
numPods += len(podList.Items)
}
if numPods == 0 {
dc.enqueueDeployment(d)
}
}
}可以看到,基本思路差不多,当检查到Deployment 所有的Pod 都被删除后,将Deployment name 塞到Worker Queue 里面去。
Deployment Controller Run 函数
资源初始化完毕后,就开始真正的Run 来看一下Run 函数
func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer dc.queue.ShutDown()
klog.Infof("Starting deployment controller")
defer klog.Infof("Shutting down deployment controller")
if !controller.WaitForCacheSync("deployment", stopCh, dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh)
}
<-stopCh
}
func (dc *DeploymentController) worker() {
for dc.processNextWorkItem() {
}
}
func (dc *DeploymentController) processNextWorkItem() bool {
key, quit := dc.queue.Get()
if quit {
return false
}
defer dc.queue.Done(key)
err := dc.syncHandler(key.(string))
dc.handleErr(err, key)
return true
}可以看到 这个代码就是Client-go 里面标准版的Worker 消费者,不断的从Queue 里面拿Obj 然后调用syncHandler 处理,一起来看看最终的Handler如何处理
dc.syncHandler
func (dc *DeploymentController) syncDeployment(key string) error {
startTime := time.Now()
klog.V(4).Infof("Started syncing deployment %q (%v)", key, startTime)
defer func() {
klog.V(4).Infof("Finished syncing deployment %q (%v)", key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
deployment, err := dc.dLister.Deployments(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(2).Infof("Deployment %v has been deleted", key)
return nil
}
if err != nil {
return err
}
// Deep-copy otherwise we are mutating our cache.
// TODO: Deep-copy only when needed.
d := deployment.DeepCopy()
everything := metav1.LabelSelector{}
if reflect.DeepEqual(d.Spec.Selector, &everything) {
dc.eventRecorder.Eventf(d, v1.EventTypeWarning, "SelectingAll", "This deployment is selecting all pods. A non-empty selector is required.")
if d.Status.ObservedGeneration < d.Generation {
d.Status.ObservedGeneration = d.Generation
dc.client.AppsV1().Deployments(d.Namespace).UpdateStatus(d)
}
return nil
}
// List ReplicaSets owned by this Deployment, while reconciling ControllerRef
// through adoption/orphaning.
rsList, err := dc.getReplicaSetsForDeployment(d)
if err != nil {
return err
}
// List all Pods owned by this Deployment, grouped by their ReplicaSet.
// Current uses of the podMap are:
//
// * check if a Pod is labeled correctly with the pod-template-hash label.
// * check that no old Pods are running in the middle of Recreate Deployments.
podMap, err := dc.getPodMapForDeployment(d, rsList)
if err != nil {
return err
}
if d.DeletionTimestamp != nil {
return dc.syncStatusOnly(d, rsList)
}
// Update deployment conditions with an Unknown condition when pausing/resuming
// a deployment. In this way, we can be sure that we won't timeout when a user
// resumes a Deployment with a set progressDeadlineSeconds.
if err = dc.checkPausedConditions(d); err != nil {
return err
}
if d.Spec.Paused {
return dc.sync(d, rsList)
}
// rollback is not re-entrant in case the underlying replica sets are updated with a new
// revision so we should ensure that we won't proceed to update replica sets until we
// make sure that the deployment has cleaned up its rollback spec in subsequent enqueues.
if getRollbackTo(d) != nil {
return dc.rollback(d, rsList)
}
scalingEvent, err := dc.isScalingEvent(d, rsList)
if err != nil {
return err
}
if scalingEvent {
return dc.sync(d, rsList)
}
switch d.Spec.Strategy.Type {
case apps.RecreateDeploymentStrategyType:
return dc.rolloutRecreate(d, rsList, podMap)
case apps.RollingUpdateDeploymentStrategyType:
return dc.rolloutRolling(d, rsList)
}
return fmt.Errorf("unexpected deployment strategy type: %s", d.Spec.Strategy.Type)
}
- 根据Worker Queue 取出来的Namespace & Name 从Lister 内Query到真正的Deployment 对象
- 根据Deployment label 查询对应的ReplicaSet 列表
- 根据ReplicaSet label 查询对应的 Pod 列表,并生成一个key 为ReplicaSet ID Value 为PodList的Map 数据结构
- 判断当前Deployment 是否处于暂停状态
- 判断当前Deployment 是否处于回滚状态
- 根据更新策略
Recreate还是RollingUpdate决定对应的动作
这里我们以Recreate为例来看一下策略动作
func (dc *DeploymentController) rolloutRecreate(d *apps.Deployment, rsList []*apps.ReplicaSet, podMap map[types.UID]*v1.PodList) error {
// Don't create a new RS if not already existed, so that we avoid scaling up before scaling down.
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
activeOldRSs := controller.FilterActiveReplicaSets(oldRSs)
// scale down old replica sets.
scaledDown, err := dc.scaleDownOldReplicaSetsForRecreate(activeOldRSs, d)
if err != nil {
return err
}
if scaledDown {
// Update DeploymentStatus.
return dc.syncRolloutStatus(allRSs, newRS, d)
}
// Do not process a deployment when it has old pods running.
if oldPodsRunning(newRS, oldRSs, podMap) {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
// If we need to create a new RS, create it now.
if newRS == nil {
newRS, oldRSs, err = dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
if err != nil {
return err
}
allRSs = append(oldRSs, newRS)
}
// scale up new replica set.
if _, err := dc.scaleUpNewReplicaSetForRecreate(newRS, d); err != nil {
return err
}
if util.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
// Sync deployment status.
return dc.syncRolloutStatus(allRSs, newRS, d)
}- 根据ReplicaSet 获取当前所有的新老ReplicaSet
- 如果有老的ReplicaSet 那么先把老的ReplicaSet replicas 缩容设置为0,当然第一次创建的时候是没有老ReplicaSet的
- 如果第一次创建,那么需要去创建对应的ReplicaSet
- 创建完毕对应的ReplicaSet后 扩容ReplicaSet 到对应的值
- 等待新建的创建完毕,清理老的ReplcaiSet
- 更新Deployment Status
下面我们看看第一次创建Deployment 的代码
func (dc *DeploymentController) getNewReplicaSet(d *apps.Deployment, rsList, oldRSs []*apps.ReplicaSet, createIfNotExisted bool) (*apps.ReplicaSet, error) {
existingNewRS := deploymentutil.FindNewReplicaSet(d, rsList)
// Calculate the max revision number among all old RSes
maxOldRevision := deploymentutil.MaxRevision(oldRSs)
// Calculate revision number for this new replica set
newRevision := strconv.FormatInt(maxOldRevision+1, 10)
// Latest replica set exists. We need to sync its annotations (includes copying all but
// annotationsToSkip from the parent deployment, and update revision, desiredReplicas,
// and maxReplicas) and also update the revision annotation in the deployment with the
// latest revision.
if existingNewRS != nil {
rsCopy := existingNewRS.DeepCopy()
// Set existing new replica set's annotation
annotationsUpdated := deploymentutil.SetNewReplicaSetAnnotations(d, rsCopy, newRevision, true)
minReadySecondsNeedsUpdate := rsCopy.Spec.MinReadySeconds != d.Spec.MinReadySeconds
if annotationsUpdated || minReadySecondsNeedsUpdate {
rsCopy.Spec.MinReadySeconds = d.Spec.MinReadySeconds
return dc.client.AppsV1().ReplicaSets(rsCopy.ObjectMeta.Namespace).Update(rsCopy)
}
// Should use the revision in existingNewRS's annotation, since it set by before
needsUpdate := deploymentutil.SetDeploymentRevision(d, rsCopy.Annotations[deploymentutil.RevisionAnnotation])
// If no other Progressing condition has been recorded and we need to estimate the progress
// of this deployment then it is likely that old users started caring about progress. In that
// case we need to take into account the first time we noticed their new replica set.
cond := deploymentutil.GetDeploymentCondition(d.Status, apps.DeploymentProgressing)
if deploymentutil.HasProgressDeadline(d) && cond == nil {
msg := fmt.Sprintf("Found new replica set %q", rsCopy.Name)
condition := deploymentutil.NewDeploymentCondition(apps.DeploymentProgressing, v1.ConditionTrue, deploymentutil.FoundNewRSReason, msg)
deploymentutil.SetDeploymentCondition(&d.Status, *condition)
needsUpdate = true
}
if needsUpdate {
var err error
if d, err = dc.client.AppsV1().Deployments(d.Namespace).UpdateStatus(d); err != nil {
return nil, err
}
}
return rsCopy, nil
}
if !createIfNotExisted {
return nil, nil
}
// new ReplicaSet does not exist, create one.
newRSTemplate := *d.Spec.Template.DeepCopy()
podTemplateSpecHash := controller.ComputeHash(&newRSTemplate, d.Status.CollisionCount)
newRSTemplate.Labels = labelsutil.CloneAndAddLabel(d.Spec.Template.Labels, apps.DefaultDeploymentUniqueLabelKey, podTemplateSpecHash)
// Add podTemplateHash label to selector.
newRSSelector := labelsutil.CloneSelectorAndAddLabel(d.Spec.Selector, apps.DefaultDeploymentUniqueLabelKey, podTemplateSpecHash)
// Create new ReplicaSet
newRS := apps.ReplicaSet{
ObjectMeta: metav1.ObjectMeta{
// Make the name deterministic, to ensure idempotence
Name: d.Name + "-" + podTemplateSpecHash,
Namespace: d.Namespace,
OwnerReferences: []metav1.OwnerReference{*metav1.NewControllerRef(d, controllerKind)},
Labels: newRSTemplate.Labels,
},
Spec: apps.ReplicaSetSpec{
Replicas: new(int32),
MinReadySeconds: d.Spec.MinReadySeconds,
Selector: newRSSelector,
Template: newRSTemplate,
},
}
allRSs := append(oldRSs, &newRS)
newReplicasCount, err := deploymentutil.NewRSNewReplicas(d, allRSs, &newRS)
if err != nil {
return nil, err
}
*(newRS.Spec.Replicas) = newReplicasCount
// Set new replica set's annotation
deploymentutil.SetNewReplicaSetAnnotations(d, &newRS, newRevision, false)
// Create the new ReplicaSet. If it already exists, then we need to check for possible
// hash collisions. If there is any other error, we need to report it in the status of
// the Deployment.
alreadyExists := false
createdRS, err := dc.client.AppsV1().ReplicaSets(d.Namespace).Create(&newRS)这里截取了部分重要代码
- 首先查询一下当前是否有对应的新的ReplicaSet
- 如果有那么仅仅需要更新Deployment Status 即可
- 如果没有 那么创建对应的ReplicaSet 结构体
- 最后调用Client-go 创建对应的ReplicaSet 实例
后面还有一些代码 这里就不贴了,核心思想就是,根据ReplicaSet的情况创建对应的新的ReplicaSet,其实看到使用Client-go 创建ReplicaSet Deployment 这里基本完成了使命,剩下的就是根据watch 改变一下Deployment 的状态了,至于真正的Pod 的创建,那么就得ReplicaSet Controller 来完成了。
ReplicaSet Controller
ReplicaSet Controller 和Deployment Controller 长得差不多,重复的部分我们就不多说,先看一下初始化的时候,ReplicaSet 主要关注哪些资源
func NewBaseController(rsInformer appsinformers.ReplicaSetInformer, podInformer coreinformers.PodInformer, kubeClient clientset.Interface, burstReplicas int,
gvk schema.GroupVersionKind, metricOwnerName, queueName string, podControl controller.PodControlInterface) *ReplicaSetController {
if kubeClient != nil && kubeClient.CoreV1().RESTClient().GetRateLimiter() != nil {
metrics.RegisterMetricAndTrackRateLimiterUsage(metricOwnerName, kubeClient.CoreV1().RESTClient().GetRateLimiter())
}
rsc := &ReplicaSetController{
GroupVersionKind: gvk,
kubeClient: kubeClient,
podControl: podControl,
burstReplicas: burstReplicas,
expectations: controller.NewUIDTrackingControllerExpectations(controller.NewControllerExpectations()),
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), queueName),
}
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: rsc.enqueueReplicaSet,
UpdateFunc: rsc.updateRS,
// This will enter the sync loop and no-op, because the replica set has been deleted from the store.
// Note that deleting a replica set immediately after scaling it to 0 will not work. The recommended
// way of achieving this is by performing a `stop` operation on the replica set.
DeleteFunc: rsc.enqueueReplicaSet,
})
rsc.rsLister = rsInformer.Lister()
rsc.rsListerSynced = rsInformer.Informer().HasSynced
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: rsc.addPod,
// This invokes the ReplicaSet for every pod change, eg: host assignment. Though this might seem like
// overkill the most frequent pod update is status, and the associated ReplicaSet will only list from
// local storage, so it should be ok.
UpdateFunc: rsc.updatePod,
DeleteFunc: rsc.deletePod,
})
rsc.podLister = podInformer.Lister()
rsc.podListerSynced = podInformer.Informer().HasSynced
rsc.syncHandler = rsc.syncReplicaSet
return rsc
}可以看到ReplicaSet Controller 主要关注所有的ReplicaSet Pod的创建,他们的处理逻辑是一样的,都是根据触发函数,找到对应的ReplicaSet实例后,将对应的ReplicaSet 实例放到Worker Queue里面去。
syncReplicaSet
这里我们直接来看ReplicaSet Controller 的真正处理函数
func (rsc *ReplicaSetController) syncReplicaSet(key string) error {
startTime := time.Now()
defer func() {
klog.V(4).Infof("Finished syncing %v %q (%v)", rsc.Kind, key, time.Since(startTime))
}()
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)
if errors.IsNotFound(err) {
klog.V(4).Infof("%v %v has been deleted", rsc.Kind, key)
rsc.expectations.DeleteExpectations(key)
return nil
}
if err != nil {
return err
}
rsNeedsSync := rsc.expectations.SatisfiedExpectations(key)
selector, err := metav1.LabelSelectorAsSelector(rs.Spec.Selector)
if err != nil {
utilruntime.HandleError(fmt.Errorf("Error converting pod selector to selector: %v", err))
return nil
}
// list all pods to include the pods that don't match the rs`s selector
// anymore but has the stale controller ref.
// TODO: Do the List and Filter in a single pass, or use an index.
allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())
if err != nil {
return err
}
// Ignore inactive pods.
var filteredPods []*v1.Pod
for _, pod := range allPods {
if controller.IsPodActive(pod) {
filteredPods = append(filteredPods, pod)
}
}
// NOTE: filteredPods are pointing to objects from cache - if you need to
// modify them, you need to copy it first.
filteredPods, err = rsc.claimPods(rs, selector, filteredPods)
if err != nil {
return err
}
var manageReplicasErr error
if rsNeedsSync && rs.DeletionTimestamp == nil {
manageReplicasErr = rsc.manageReplicas(filteredPods, rs)
}
rs = rs.DeepCopy()
newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)- 根据从Worker Queue 得到的Name 获取真正的ReplicaSet 实例
- 根据ReplicaSet Label 获取对应的所有的Pod List
- 将所有的Running Pod 遍历出来
- 根据Pod 情况判断是否需要创建 Pod
- 将新的状态更新到ReplicaSet Status 字段中
manageReplicas
我们主要来看一眼创建Pod 的函数
func (rsc *ReplicaSetController) manageReplicas(filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
rsKey, err := controller.KeyFunc(rs)
if err != nil {
utilruntime.HandleError(fmt.Errorf("Couldn't get key for %v %#v: %v", rsc.Kind, rs, err))
return nil
}
if diff < 0 {
diff *= -1
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
// TODO: Track UIDs of creates just like deletes. The problem currently
// is we'd need to wait on the result of a create to record the pod's
// UID, which would require locking *across* the create, which will turn
// into a performance bottleneck. We should generate a UID for the pod
// beforehand and store it via ExpectCreations.
rsc.expectations.ExpectCreations(rsKey, diff)
klog.V(2).Infof("Too few replicas for %v %s/%s, need %d, creating %d", rsc.Kind, rs.Namespace, rs.Name, *(rs.Spec.Replicas), diff)
// Batch the pod creates. Batch sizes start at SlowStartInitialBatchSize
// and double with each successful iteration in a kind of "slow start".
// This handles attempts to start large numbers of pods that would
// likely all fail with the same error. For example a project with a
// low quota that attempts to create a large number of pods will be
// prevented from spamming the API service with the pod create requests
// after one of its pods fails. Conveniently, this also prevents the
// event spam that those failures would generate.
successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
boolPtr := func(b bool) *bool { return &b }
controllerRef := &metav1.OwnerReference{
APIVersion: rsc.GroupVersion().String(),
Kind: rsc.Kind,
Name: rs.Name,
UID: rs.UID,
BlockOwnerDeletion: boolPtr(true),
Controller: boolPtr(true),
}
err := rsc.podControl.CreatePodsWithControllerRef(rs.Namespace, &rs.Spec.Template, rs, controllerRef)
if err != nil && errors.IsTimeout(err) {
// Pod is created but its initialization has timed out.
// If the initialization is successful eventually, the
// controller will observe the creation via the informer.
// If the initialization fails, or if the pod keeps
// uninitialized for a long time, the informer will not
// receive any update, and the controller will create a new
// pod when the expectation expires.
return nil
}
return err
})
// Any skipped pods that we never attempted to start shouldn't be expected.
// The skipped pods will be retried later. The next controller resync will
// retry the slow start process.
if skippedPods := diff - successfulCreations; skippedPods > 0 {
klog.V(2).Infof("Slow-start failure. Skipping creation of %d pods, decrementing expectations for %v %v/%v", skippedPods, rsc.Kind, rs.Namespace, rs.Name)
for i := 0; i < skippedPods; i++ {
// Decrement the expected number of creates because the informer won't observe this pod
rsc.expectations.CreationObserved(rsKey)
}
}
return err
} else if diff > 0 {
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
klog.V(2).Infof("Too many replicas for %v %s/%s, need %d, deleting %d", rsc.Kind, rs.Namespace, rs.Name, *(rs.Spec.Replicas), diff)
// Choose which Pods to delete, preferring those in earlier phases of startup.
podsToDelete := getPodsToDelete(filteredPods, diff)
// Snapshot the UIDs (ns/name) of the pods we're expecting to see
// deleted, so we know to record their expectations exactly once either
// when we see it as an update of the deletion timestamp, or as a delete.
// Note that if the labels on a pod/rs change in a way that the pod gets
// orphaned, the rs will only wake up after the expectations have
// expired even if other pods are deleted.
rsc.expectations.ExpectDeletions(rsKey, getPodKeys(podsToDelete))
errCh := make(chan error, diff)
var wg sync.WaitGroup
wg.Add(diff)
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
defer wg.Done()
if err := rsc.podControl.DeletePod(rs.Namespace, targetPod.Name, rs); err != nil {
// Decrement the expected number of deletes because the informer won't observe this deletion
podKey := controller.PodKey(targetPod)
klog.V(2).Infof("Failed to delete %v, decrementing expectations for %v %s/%s", podKey, rsc.Kind, rs.Namespace, rs.Name)
rsc.expectations.DeletionObserved(rsKey, podKey)
errCh <- err
}
}(pod)
}
wg.Wait()这里的逻辑就非常简单的,基本上就是根据当前Running Pod 数量和真正的replicas 声明比对,如果少了那么就调用Client-go 创建Pod ,如果多了就调用CLient-go 去删除 Pod。
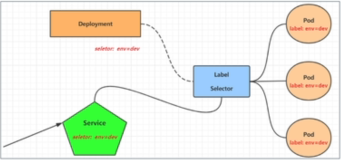
总结
至此,一个Deployment -> ReplicaSet -> Pod 就真正的创建完毕。当Pod 被删除时候,ReplicaSet Controller 就会把 Pod 拉起来。如果更新Deployment 就会创建新的ReplicaSet 一层层嵌套多个Controller 结合完成最终的 Pod 创建。 当然,这里其实仅仅完成了Pod 数据写入到ETCD,其实真正的 Pod 实例并没有创建,还需要scheduler & kubelet 配合完成,我们会在后面的章节继续介绍。