测试环境
该benchmark用到了六台机器,机器配置如下
Intel Xeon 2.5 GHz processor with six cores
Six 7200 RPM SATA drives
32GB of RAM
1Gb Ethernet
这6台机器其中3台用来搭建Kafka broker集群,另外3台用来安装Zookeeper及生成测试数据。6个drive都直接以非RAID方式挂载。实际上kafka对机器的需求与Hadoop的类似。
该项测试只测producer的吞吐率,也就是数据只被持久化,没有consumer读数据。
在这一测试中,创建了一个包含6个partition且没有replication的topic。然后通过一个线程尽可能快的生成50 million条比较短(payload100字节长)的消息。测试结果是821,557 records/second(78.3MB/second)。
之所以使用短消息,是因为对于消息系统来说这种使用场景更难。因为如果使用MB/second来表征吞吐率,那发送长消息无疑能使得测试结果更好。
整个测试中,都是用每秒钟delivery的消息的数量乘以payload的长度来计算MB/second的,没有把消息的元信息算在内,所以实际的网络使用量会比这个大。对于本测试来说,每次还需传输额外的22个字节,包括一个可选的key,消息长度描述,CRC等。另外,还包含一些请求相关的overhead,比如topic,partition,acknowledgement等。这就导致我们比较难判断是否已经达到网卡极限,但是把这些overhead都算在吞吐率里面应该更合理一些。因此,我们已经基本达到了网卡的极限。
初步观察此结果会认为它比人们所预期的要高很多,尤其当考虑到Kafka要把数据持久化到磁盘当中。实际上,如果使用随机访问数据系统,比如RDBMS,或者key-velue store,可预期的最高访问频率大概是5000到50000个请求每秒,这和一个好的RPC层所能接受的远程请求量差不多。而该测试中远超于此的原因有两个。
Kafka确保写磁盘的过程是线性磁盘I/O,测试中使用的6块廉价磁盘线性I/O的最大吞吐量是822MB/second,这已经远大于1Gb网卡所能带来的吞吐量了。许多消息系统把数据持久化到磁盘当成是一个开销很大的事情,这是因为他们对磁盘的操作都不是线性I/O。
在每一个阶段,Kafka都尽量使用批量处理。如果想了解批处理在I/O操作中的重要性,可以参考David Patterson的”Latency Lags Bandwidth“
该项测试与上一测试基本一样,唯一的区别是每个partition有3个replica(所以网络传输的和写入磁盘的总的数据量增加了3倍)。每一个broker即要写作为leader的partition,也要读(从leader读数据)写(将数据写到磁盘)作为follower的partition。测试结果为786,980 records/second(75.1MB/second)。
该项测试中replication是异步的,也就是说broker收到数据并写入本地磁盘后就acknowledge producer,而不必等所有replica都完成replication。也就是说,如果leader crash了,可能会丢掉一些最新的还未备份的数据。但这也会让message acknowledgement延迟更少,实时性更好。
这项测试说明,replication可以很快。整个集群的写能力可能会由于3倍的replication而只有原来的三分之一,但是对于每一个producer来说吞吐率依然足够好。
该项测试与上一测试的唯一区别是replication是同步的,每条消息只有在被in sync集合里的所有replica都复制过去后才会被置为committed(此时broker会向producer发送acknowledgement)。在这种模式下,Kafka可以保证即使leader crash了,也不会有数据丢失。测试结果为421,823 records/second(40.2MB/second)。
Kafka同步复制与异步复制并没有本质的不同。leader会始终track follower replica从而监控它们是否还alive,只有所有in sync集合里的replica都acknowledge的消息才可能被consumer所消费。而对follower的等待影响了吞吐率。可以通过增大batch size来改善这种情况,但为了避免特定的优化而影响测试结果的可比性,本次测试并没有做这种调整。
该测试相当于把上文中的1个producer,复制到了3台不同的机器上(在1台机器上跑多个实例对吞吐率的增加不会有太大帮忙,因为网卡已经基本饱和了),这3个producer同时发送数据。整个集群的吞吐率为2,024,032 records/second(193,0MB/second)。
Producer Throughput Vs. Stored Data
消息系统的一个潜在的危险是当数据能都存于内存时性能很好,但当数据量太大无法完全存于内存中时(然后很多消息系统都会删除已经被消费的数据,但当消费速度比生产速度慢时,仍会造成数据的堆积),数据会被转移到磁盘,从而使得吞吐率下降,这又反过来造成系统无法及时接收数据。这样就非常糟糕,而实际上很多情景下使用queue的目的就是解决数据消费速度和生产速度不一致的问题。
但Kafka不存在这一问题,因为Kafka始终以O(1)的时间复杂度将数据持久化到磁盘,所以其吞吐率不受磁盘上所存储的数据量的影响。为了验证这一特性,做了一个长时间的大数据量的测试,下图是吞吐率与数据量大小的关系图。
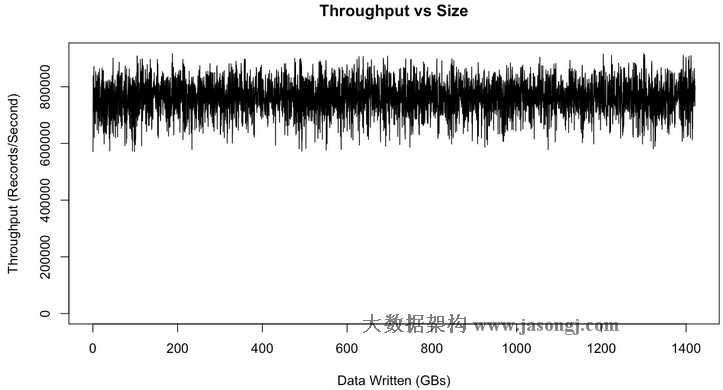
上图中有一些variance的存在,并可以明显看到,吞吐率并不受磁盘上所存数据量大小的影响。实际上从上图可以看到,当磁盘数据量达到1TB时,吞吐率和磁盘数据只有几百MB时没有明显区别。
这个variance是由Linux I/O管理造成的,它会把数据缓存起来再批量flush。上图的测试结果是在生产环境中对Kafka集群做了些tuning后得到的,这些tuning方法可参考这里。
需要注意的是,replication factor并不会影响consumer的吞吐率测试,因为consumer只会从每个partition的leader读数据,而与replicaiton factor无关。同样,consumer吞吐率也与同步复制还是异步复制无关。
该测试从有6个partition,3个replication的topic消费50 million的消息。测试结果为940,521 records/second(89.7MB/second)。
可以看到,Kafkar的consumer是非常高效的。它直接从broker的文件系统里读取文件块。Kafka使用sendfile API来直接通过操作系统直接传输,而不用把数据拷贝到用户空间。该项测试实际上从log的起始处开始读数据,所以它做了真实的I/O。在生产环境下,consumer可以直接读取producer刚刚写下的数据(它可能还在缓存中)。实际上,如果在生产环境下跑I/O stat,你可以看到基本上没有物理“读”。也就是说生产环境下consumer的吞吐率会比该项测试中的要高。
将上面的consumer复制到3台不同的机器上,并且并行运行它们(从同一个topic上消费数据)。测试结果为2,615,968 records/second(249.5MB/second)。
正如所预期的那样,consumer的吞吐率几乎线性增涨。
上面的测试只是把producer和consumer分开测试,而该项测试同时运行producer和consumer,这更接近使用场景。实际上目前的replication系统中follower就相当于consumer在工作。
该项测试,在具有6个partition和3个replica的topic上同时使用1个producer和1个consumer,并且使用异步复制。测试结果为795,064 records/second(75.8MB/second)。
可以看到,该项测试结果与单独测试1个producer时的结果几乎一致。所以说consumer非常轻量级。
上面的所有测试都基于短消息(payload 100字节),而正如上文所说,短消息对Kafka来说是更难处理的使用方式,可以预期,随着消息长度的增大,records/second会减小,但MB/second会有所提高。下图是records/second与消息长度的关系图。
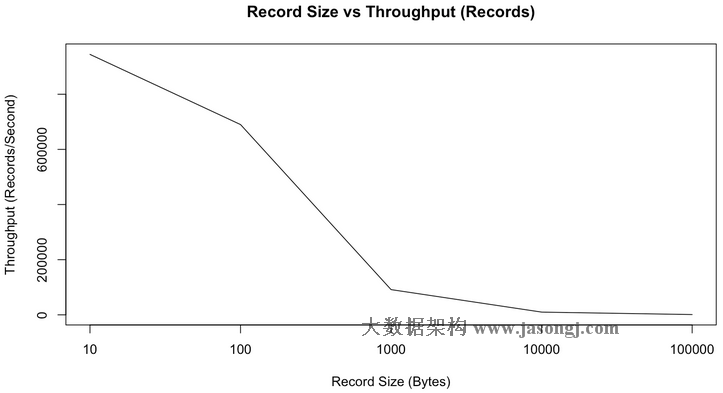
正如我们所预期的那样,随着消息长度的增加,每秒钟所能发送的消息的数量逐渐减小。但是如果看每秒钟发送的消息的总大小,它会随着消息长度的增加而增加,如下图所示。
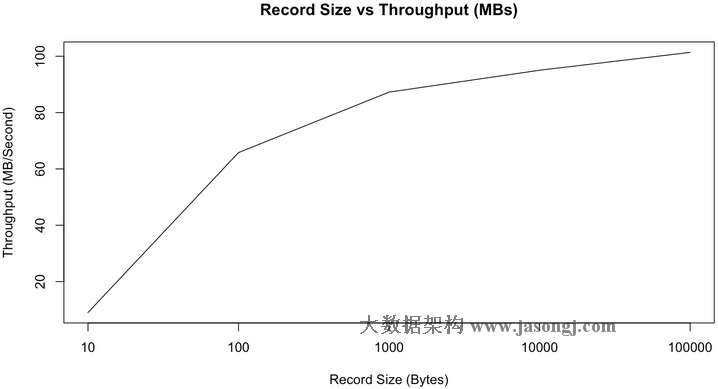
从上图可以看出,当消息长度为10字节时,因为要频繁入队,花了太多时间获取锁,CPU成了瓶颈,并不能充分利用带宽。但从100字节开始,我们可以看到带宽的使用逐渐趋于饱和(虽然MB/second还是会随着消息长度的增加而增加,但增加的幅度也越来越小)。
上文中讨论了吞吐率,那消息传输的latency如何呢?也就是说消息从producer到consumer需要多少时间呢?该项测试创建1个producer和1个consumer并反复计时。结果是,2 ms (median), 3ms (99th percentile, 14ms (99.9th percentile)。
(这里并没有说明topic有多少个partition,也没有说明有多少个replica,replication是同步还是异步。实际上这会极大影响producer发送的消息被commit的latency,而只有committed的消息才能被consumer所消费,所以它会最终影响端到端的latency)
如果读者想要在自己的机器上重现本次benchmark测试,可以参考本次测试的配置和所使用的命令。
实际上Kafka Distribution提供了producer性能测试工具,可通过bin/kafka-producer-perf-test.sh脚本来启动。所使用的命令如下
Producer
Setup
bin/kafka-topics.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --create --topictest-rep-one --partitions 6 --replication-factor 1
bin/kafka-topics.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --create --topictest--partitions 6 --replication-factor 3
Single thread, no replication
bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformancetest7 50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196
Single-thread, async 3x replication
bin/kafktopics.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --create --topictest--partitions 6 --replication-factor 3
bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformancetest6 50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196
Single-thread, sync 3x replication
bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformancetest50000000 100 -1 acks=-1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=64000
Three Producers, 3x async replication
bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformancetest50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196
Throughput Versus Stored Data
bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformancetest50000000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196
Effect of message size
foriin10 100 1000 10000 100000;
do
echo""
echo$i
bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformancetest$((1000*1024*1024/$i))$i-1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=128000
done;
Consumer
Consumer throughput
bin/kafka-consumer-perf-test.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --messages 50000000 --topictest--threads 1
3 Consumers
On three servers, run:
bin/kafka-consumer-perf-test.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --messages 50000000 --topictest--threads 1
End-to-end Latency
bin/kafka-run-class.sh kafka.tools.TestEndToEndLatency esv4-hcl198.grid.linkedin.com:9092 esv4-hcl197.grid.linkedin.com:2181test5000
Producer and consumer
bin/kafka-run-class.sh org.apache.kafka.clients.tools.ProducerPerformancetest50000000 100 -1 acks=1 bootstrap.servers=esv4-hcl198.grid.linkedin.com:9092 buffer.memory=67108864 batch.size=8196
bin/kafka-consumer-perf-test.sh --zookeeper esv4-hcl197.grid.linkedin.com:2181 --messages 50000000 --topictest--threads 1
broker配置如下
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The port the socket server listens on
port=9092
# Hostname the broker will bind to and advertise to producers and consumers.
# If not set, the server will bind to all interfaces and advertise the value returned from
# from java.net.InetAddress.getCanonicalHostName().
#host.name=localhost
# The number of threads handling network requests
num.network.threads=4
# The number of threads doing disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=1048576
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=1048576
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# The directory under which to store log files
log.dirs=/grid/a/dfs-data/kafka-logs,/grid/b/dfs-data/kafka-logs,/grid/c/dfs-data/kafka-logs,/grid/d/dfs-data/kafka-logs,/grid/e/dfs-data/kafka-logs,/grid/f/dfs-data/kafka-logs
# The number of logical partitions per topic per server. More partitions allow greater parallelism
# for consumption, but also mean more files.
num.partitions=8
############################# Log Flush Policy #############################
# The following configurations control the flush of data to disk. This is the most
# important performance knob in kafka.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data is at greater risk of loss in the event of a crash.
# 2. Latency: Data is not made available to consumers until it is flushed (which adds latency).
# 3. Throughput: The flush is generally the most expensive operation.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# Per-topic overrides for log.flush.interval.ms
#log.flush.intervals.ms.per.topic=topic1:1000, topic2:3000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
# segments don't drop below log.retention.bytes.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=536870912
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.cleanup.interval.mins=1
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=esv4-hcl197.grid.linkedin.com:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=1000000
# metrics reporter properties
kafka.metrics.polling.interval.secs=5
kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter
kafka.csv.metrics.dir=/tmp/kafka_metrics
# Disable csv reporting by default.
kafka.csv.metrics.reporter.enabled=false
replica.lag.max.messages=10000000
转载请务必将下面这段话置于文章开头处(保留超链接)。