辞旧迎新之际,更是钻研技术的最佳时机......秉持这一原则,咱们依然诚意十足,特线上墨迹天气与东润环能玩转数据的姿势;此外,小编还特别给大家准备了数据导入的技巧。PS,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
案例篇
一、 轻松处理每天2TB的日志数据,支撑运营团队进行大数据分析挖掘,随时洞察用户个性化需求
墨迹天气的API每天产生的日志量大约在2TB左右,主要的日志分析场景是天气查询业务和广告业务。整个过程中数据量庞大,且计算复杂,这对云平台的大数据能力、生态完整性和开放性提出了很高的要求。之前墨迹使用国外某云计算服务公司的云服务器存储这些数据,利用Hadoop的MapReducer和Hive对数据进行处理分析,但是存在以下问题:
- 成本:包括存储、计算及大数据处理服务成本对比阿里云成本很高;
- 网络带宽:移动端业务量大,需要大量的网络带宽资源支持,但数据上传也需要占用网络带宽,彼此之间相互干扰造成数据传输不稳定。
解决方案及架构
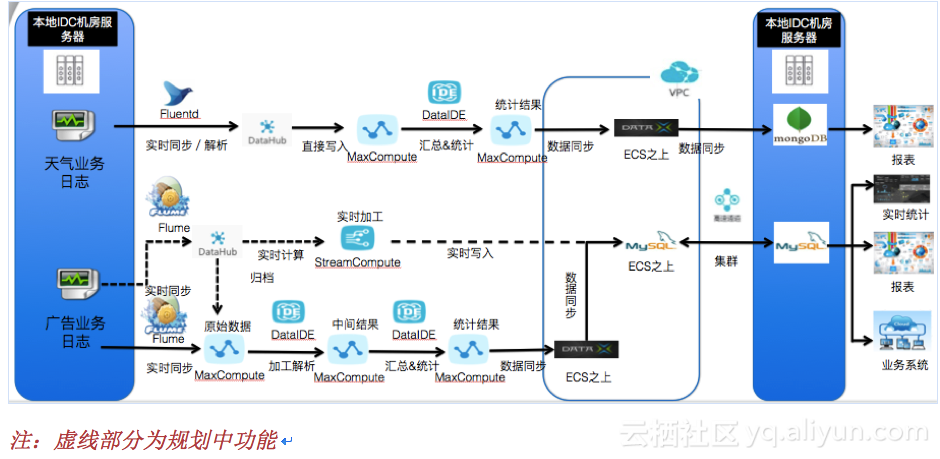
针对上述情况,墨迹将日志分析业务逐步迁移到阿里云大数据平台-数加平台之上。新的日志分析架构如页面下方架构图所示。
由于每天产生的数据量较大,上传数据会占用带宽,为了不影响业务系统的网络资源,客户开通了阿里云高速通道,用于数据上传。通过此种手段解决了网络带宽的问题。通过阿里云数加日志分析解决方案,墨迹的业务得到以下提升:
- 充分利用移动端积累下来的海量日志数据;
- 对用户使用情况和广告业务进行大数据分析;
- 利用阿里云数加大数据技术,基于对日志数据的分析,支持运营团队和广告团队优化现有业务。
更多详情:https://yq.aliyun.com/articles/68211
二、 阿里云数加让企业更专注于业务,助力东润环能高效利用大数据资源
东润环能作为新三板首批进入创新层的上市企业,基于专业的气象环境技术、空间环境技术及大数据技术每天为全国数千家新能源电站提供风光项目现场功率预测,为省级及地级调度部门提供专业气象服务和大数据应用;并通过电网侧为全国500余家新能源子站提供控制策略并执行控制命令。旗下产品及业务开拓均基于对大数据的挖掘应用。
问题及挑战
作为是东润环能全资子公司北京能量魔方数据技术有限公司开发的“能量魔方”,将大数据为代表的互联网创新理念与新能源发展当中的切实应用需求结合起来,推动虚拟世界和现实世界融合发展,但在研发过程中东润环能却遇到了不小的问题:
- 投资成本过高:自建大数据平台要充分考虑物理投入、人力运维投入、研发投入、业务波动等多方面的影响;
- 运维复杂:自建大数据平台基础设施对于东润环能现有的人力物力而言风险较大,同时还需兼顾不同系统间的版本兼容性问题。无形中不仅增加运维成本,更增加了稳定风险。
解决方案及架构
新能源产业互联网大数据应用服务云平台是东润环能应用能源互联网大数据理念开发建设的新能源电力大数据应用服务平台,此平台定位为大数据信息SaaS服务平台,提供在大数据基础上建设的各种服务和应用工具,目前规划有八个模块,分别为:资源评估、气象服务、设备选型、运营管理、设计规划、专业技术、项目评估、金融服务。
原解决方案如下:
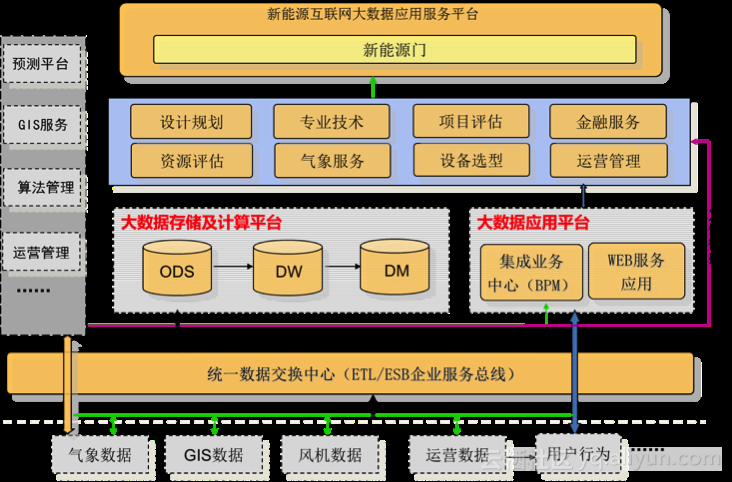
为了摸索出一套真正适合中国国情的新能源数据应用服务方案,云计算和大数据技术成为了东润环能创新的重要手段。而经过了各方面测试和挑选,东润环能最终选择了阿里云作为自己的合作伙伴。东润环能基于阿里云数加搭建的大数据服务平台架构如下方架构图所示:
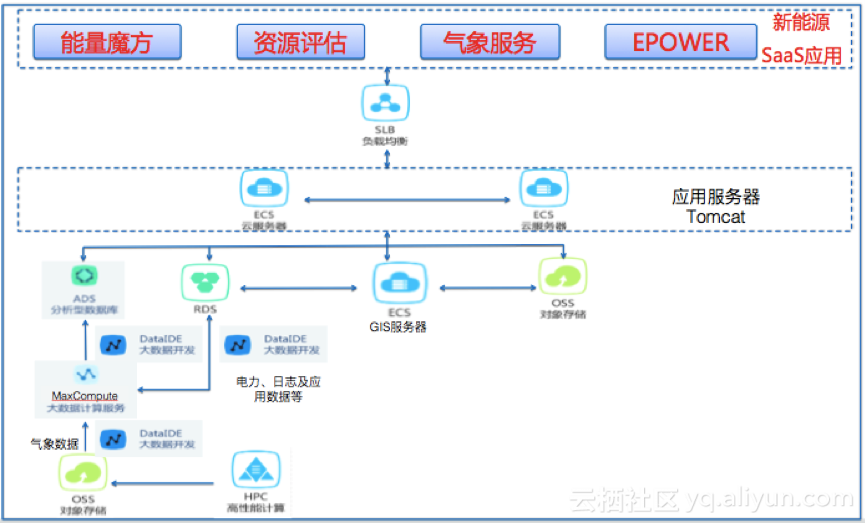
另外,双方联合推出针对新能源的专属数据服务产品:资源评估、气象服务、高精度数据下载三项气象数据产品;部分产品已经通过阿里云数加数据服务市场对外售卖。在让企业专注业务的同时,也达到了安全稳定的目的。
更多详情:https://yq.aliyun.com/articles/67275
技术篇
一、 数据进入阿里云数加-大数据计算服务MaxCompute(原ODPS)的N种方式
想用阿里云大数据计算服务(MaxCompute),对于大多数人首先碰到的问题就是数据如何迁移到MaxCompute中。按照数据迁移场景,大致可以分为批量数据、实时数据、本地文件、日志文件等的迁移,下面我们针对每种场景分别介绍几种常用方案。
1. 异构数据源批量数据迁移到MaxCompute
方法一,通过大数据开发套件(DataIDE)- 数据开发做数据同步。
适用场景:这种方式通过界面向导逐步配置,操作简单容易上手,对于大数据开发套件(DataIDE)已经支持的数据源之间同步数据非常方便,但是要确保数据源连通性,同时对数据同步的速度也有限制,最高10M/s。
方法二,通过DataX实现数据同步。
适用场景:DataX通过plugin的方式实现对异构数据源的支持,支持的数据源种类更丰富,对于暂不支持的数据源用户也可以自己扩展plugin实现。另外这种方式通过配置文件做源和目标的映射非常灵活,同时也很容易跟其他的任务做集成。
方法三通过Sqoop实现数据同步
2. 本地文件上传到MaxCompute
方法一,通过大数据开发套件(DataIDE)导入本地文件。
适用场景:这种方式适用于一些简单场景验证,通过向导方式上传本地文件简单易用,但是对于文件大小限制不能超过10M。
方法二,通过MaxCompute客户端上传数据。
适用场景:通过Tunnel上传数据适合数据文件大小适中的场景(比如单表上百GB可能会由于数据本身或者网络不稳定导致数据导入失败),并且可以指定线程数等来提升效率,充分发挥硬件性能。
3. 实时数据归档到MaxCompute
- 通过DataHub将流式数据归档到MaxCompute;
- 通过DTS将数据实时同步到MaxCompute;
- 通过OGG将数据实时同步到MaxCompute。
4. 日志数据同步到MaxCompute
目前日志类型的数据实时同步到MaxCompute的需求也非常强。市面上也有很多成熟的日志收集工具,比如Fluentd、Logstash。日志数据实时同步到MaxCompute的方案也是要借助于这些成熟的日志收集工具,将日志数据同步到DataHub中后,再通过DataHub将数据归档到MaxCompute。
- 通过Logstash采集日志数据到MaxCompute;
- 通过Fluentd采集日志数据到MaxCompute。
更多详情:https://yq.aliyun.com/articles/65376
二、 数据进入阿里云数加-分析型数据库AnalyticDB(原ADS)的N种方法
分析型数据库(AnalyticDB)是阿里巴巴自主研发的海量数据实时高并发在线分析(Realtime OLAP)云计算服务,用户可以在毫秒级针对千亿级数据进行即时的多维分析透视和业务探索。
想使用阿里云分析型数据,对于大多数人首先碰到的问题就是数据如何进入到分析型数据库中。按照分析型数据库数据表的更新类型,大致可以分为批量导入和实时写入两种,下面我们针对两种写入方式分别介绍几种常用方案。
1. 数据批量导入到分析型数据库
批量导入是利用分析型数据库内置的导入接口,将数据从MaxCompute导入到分析型数据库,因此批量导入方式必须有MaxCompute资源的支持。如果源端为非MaxCompute数据源,那么都需要通过MaxCompute进行中转。批量导入方式适合一次导入比较大量的数据(TB级别)。 下边分别介绍如何将MaxCompute数据源和非MaxCompute数据源批量导入分析型数据库。
MaxCompute数据源批量导入分析型数据库- 通过DataIDE实现批量数据导入;
- 通过数据集成(Data Integration)实现批量数据导入;
- 通过DataX 实现批量数据导入;
- 通过分析型数据库LOAD命令实现批量数据导入。
非MaxCompute数据源批量导入分析型数据库
- 通过DateIDE实现批量数据导入;
- 通过数据集成(Data Integration)实现批量数据导入;
- 通过DataX 实现批量数据导入;
- 通过分析型数据库LOAD命令实现批量数据导入。
正如前面所说,外部数据批量进入分析型数据库,最终都是通过LOAD命令从MaxCompute将数据导入,因此理论上讲,只要数据能够进入MaxCompute,就可以继续进入分析型数据库。所以只要分别完成这两个步骤,数据也就最终进入了分析型数据库。
2. 数据实时写入分析型数据库
实时写入是为了满足使用者需要数据实时进入分析型数据库而开发的功能。实时写入的本质是利用insert语句将数据一条一条的插入目标表。
- 利用应用程序实时写入;
- 通过DataIDE实时写入;
- 通过数据集成(Data Integration)实时写入;
- 通过DataX实时写入;
- 利用Kettle实时写入数据;
- 利用DataHub和流计算实时写入;
- 通过数据传输(Data Transmission)的分析型数据库插件将RDS MySQL增量数据实时写入分析型数据库。