Spark 同时可以建立在虚拟化的基础上,例如Vagrant 和Docker, 这样的虚拟化环境很容易部署到各种云服务上,例如AWS。
Vagrant的虚拟化环境
为了创建Python和Spark 环境,便于分享和复制, 整个开发环境可以生成一个 vagrantfile.我们参考Berkeley University 和 Databrick 发布的 Massive Open Online Courses (MOOCs) :
• Introduction to Big Data with Apache Spark, Professor Anthony D. Joseph 网址
https://www.edx.org/course/introduction-big-data-apache-spark-uc-berkeleyx-cs100-1x• Scalable Machine Learning, Professor Ameet Talwalkar 网址
https://www.edx.org/course/scalable-machine-learning-uc-berkeleyx-cs190-1x
课程实现使用了 IPython Notebooks和PySpark. 在GitHub repository的位置: https://github.com/spark-mooc/mooc-setup/. 一旦在你的机器中建立了Vagrant, 从这里的引导开始: https://docs.vagrantup.com/v2/getting-started/index.html.
在你的工作目录Clone spark-mooc/mooc-setup/ 的github仓库,在cloned的目录中启动命令:
$ vagrant up
注意一下spark的版本可能过期了而 vagrantfile可能没有过期.
可以看到类似的输出:
C:\Programs\spark\edx1001\mooc-setup-master>vagrant up
Bringing machine 'sparkvm' up with 'virtualbox' provider...
==> sparkvm: Checking if box 'sparkmooc/base' is up to date...
==> sparkvm: Clearing any previously set forwarded ports...
==> sparkvm: Clearing any previously set network interfaces...
==> sparkvm: Preparing network interfaces based on configuration...
sparkvm: Adapter 1: nat
==> sparkvm: Forwarding ports...
sparkvm: 8001 => 8001 (adapter 1)
sparkvm: 4040 => 4040 (adapter 1)
sparkvm: 22 => 2222 (adapter 1)
==> sparkvm: Booting VM...
==> sparkvm: Waiting for machine to boot. This may take a few minutes...
sparkvm: SSH address: 127.0.0.1:2222
sparkvm: SSH
username: vagrant
sparkvm: SSH auth method: private key
sparkvm: Warning: Connection timeout. Retrying...
sparkvm: Warning: Remote connection disconnect. Retrying...
==> sparkvm: Machine booted and ready!
==> sparkvm: Checking for guest additions in VM...
==> sparkvm: Setting hostname...
==> sparkvm: Mounting shared folders...
sparkvm: /vagrant => C:/Programs/spark/edx1001/mooc-setup-master
==> sparkvm: Machine already provisioned. Run `vagrant provision` or use the `--provision`
==> sparkvm: to force provisioning. Provisioners marked to run always will still run.
C:\Programs\spark\edx1001\mooc-setup-master>
这里在localhost:8001启动Python Notebooks和PySpark:

移动到云端
我们需要在分布系统中处理数据,而已经建立的开发环境是在单台电脑上的虚拟机,这对于探索和学习都非常受限。为了体验Spark 分布框架的规模扩展和强大,我们将在云上操作.
在AWS上部署应用
一旦要规模化我们的应用, 我们可以把我开发环境迁移到 Amazon Web Services (AWS).
这里清楚的描述了如何在EC2上运行 Spark,网址:https://spark.apache.org/docs/latest/ec2-scripts.html.
我们着重在构建 AWS Spark 环境的5个关键步骤:
1. 通过AWS console创建AWS EC2 key pair,网址:http://aws.amazon.com/console/.
2. 将key pair 导出到自己的环境:
export AWS_ACCESS_KEY_ID=accesskeyid
export AWS_SECRET_ACCESS_KEY=secretaccesskey
3. 启动集群:
~$ cd $SPARK_HOME/ec2
ec2$ ./spark-ec2 -k <keypair> -i <key-file> -s <num-slaves> launch
<cluster-name>
4. SSH 到集群运行 Spark jobs:
ec2$ ./spark-ec2 -k <keypair> -i <key-file> login <cluster-name>
5. 使用后销毁集群:
ec2$ ./spark-ec2 destroy <cluster-name>
Docker的虚拟化环境
为了创建Python 和 Spark环境,便于分享和复制, 开发环境还可以构建在 Docker 的容器中.希望充分利用 Docker的两个主要功能:
* 生成独立的容器便于部署在不同的操作系统和云端.
* 使用DockerHub 可以方便的分享开发环境的镜像和相关依赖,这样便于复制和版本控制,配置好的环境镜像作为将来功能增强的基线.
下图介绍了一个 Docker环境,使用了 Spark, Anaconda, 数据库服务器和相关的数据卷.
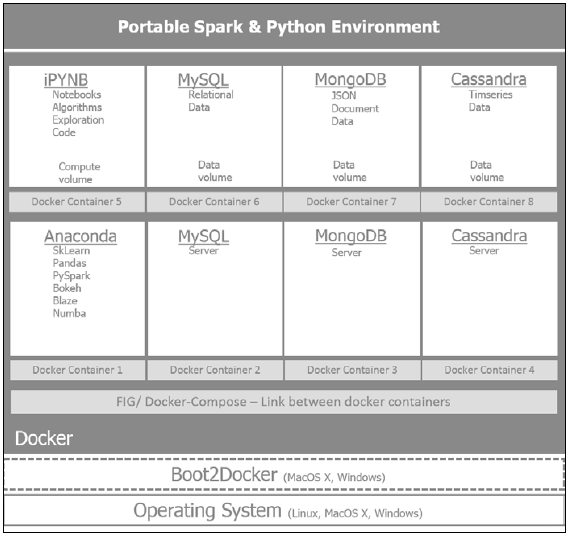
Docker 提供了从Dockerfile 复制和部署环境的能力.可以从该地址找到一个用PySpark和Anaconda 构建Dockerfile的例子: https://hub.docker.com/r/thisgokeboysef/pyspark-docker/~/dockerfile/.
安装 Docker的指导链接如下:
• http://docs.docker.com/mac/started/ if you are on Mac OS X
• http://docs.docker.com/linux/started/ if you are on Linux
• http://docs.docker.com/windows/started/ if you are on Windows
从Dockerfile 中安装Docker 容器的命令如下:
$ docker pull thisgokeboysef/pyspark-docker
可以从Lab41 获得有关如何将环境 dockerize的信息资源. GitHub repository包含了所需代码:
https://github.com/Lab41/ipython-spark-docker
技术支持的blog也有丰富的信息: http://lab41.github.io/blog/2015/04/13/
ipython-on-spark-on-docker/.
小结
我们明确了构建数据密集型应用的场景,阐明了系统架构包括基础设施, 持久化,集成,分析和参与层,也探讨了Spark和Anaconda的组成. 进而在VirtualBox中搭建了Anaconda 和的开发环境,并使用第一章的文本内容作为输入,展示了一个词频统计应用。
下一章, 将深入挖掘数据密集型应用的架构,并利用witter, GitHub, 和Meetup 的APIs体验一下用Spark挖掘数据的感觉。