每日数十亿级业务下的计数器如何扩展Redis?
在Feed系统中,有简单数据类型的缓存,有集合类数据的。还有一些个性业务的缓存。比如大量的计数器场景,存在性判断场景等。微博解决存在性判断业务的缓存层叫EXISTENCE 缓存层,解决计算器场景的缓存叫COUNTER缓存。
EXISTENCE 缓存层主要用于缓存各种存在性判断的业务,诸如是否已赞(liked)、是否已阅读(readed)这类需求。
Feed系统内部有大量的计数场景,如用户维度有关注数、粉丝数、feed发表数,feed维度有转发数、评论数、赞数以及阅读数等。前面提到,按照传统Redis、Memcached计数缓存方案,单单存每日新增的十亿级的计数,就需要新占用百G级的内存,成本开销巨大。因此微博开发了计数服务组件CounterService。下面以计数场景来管中窥豹。
提出问题
对于计数业务,经典的构建模型有两种:1 db+cache模式,全量计数存在db,热数据通过cache加速;2全量存在Redis中。方案1 通用成熟,但对于一致性要求较高的计数服务,以及在海量数据和高并发访问场景下,支持不够友好,运维成本和硬件成本较高,微博上线初期曾使用该方案,在Redis面世后很快用新方案代替。方案2基于Redis的计数接口INCR、DECR,能很方便的实现通用的计数缓存模型,再通过hash分表,master-slave部署方式,可以实现一个中小规模的计数服务。
但在面对千亿级的历史海量计数以及每天十亿级的新增计数,直接使用Redis的计数模型存在严重的成本和性能问题。首先Redis计数作为通用的全内存计数模型,内存效率不高。存储一个key为8字节(long型id)、value为4字节的计数,Redis至少需要耗费65字节。1000亿计数需要100G*65=6.5T以上的内存,算上一个master配3个slave的开销,总共需要26T以上的内存,按单机内存96G计算,扣掉Redis其他内存管理开销、系统占用,需要300-400台机器。如果算上多机房,需要的机器数会更多。其次Redis计数模型的获取性能不高。一条微博至少需要3个计数查询,单次feed请求如果包含15条微博,仅仅微博计数就需要45个计数查询。
解决问题
在Feed系统的计数场景,单条feed的各种计数都有相同的key(即微博id),可以把这些计数存储在一起,就能节省大量的key的存储空间,让1000亿计数变成了330亿条记录;近一半的微博没有转、评论、赞,抛弃db+cache的方案,改用全量存储的方案,对于没有计数为0的微博不再存储,如果查不到就返回0,这样330亿条记录只需要存160亿条记录。然后又对存储结构做了进一步优化,三个计数和key一起一共只需要8+4*3=20字节。总共只需要16G*20=320G,算上1主3从,总共也就只需要1.28T,只需要15台左右机器即可。同时进一步通过对CounterService增加SSD扩展支持,按table滚动,老数据落在ssd,新数据、热数据在内存,1.28T的容量几乎可以用单台机器来承载(当然考虑访问性能、可用性,还是需要hash到多个缓存节点,并添加主从结构)。
计数器组件的架构如图13-14,主要特性如下:
1) 内存优化:通过预先分配的内存数组Table存储计数,并且采用 double hash 解决冲突,避免Redis 实现中的大量指针开销。
2) Schema支持多列:一个feed id对应的多个计数可以作为一条计数记录,还支持动态增减计数列,每列的计数内存使用精简到bit;
3) 冷热数据分离,根据时间维度,近期的热数据放在内存,之前的冷数据放在磁盘,降低机器成本;
4) LRU缓存:之前的冷数据如果被频繁访问则放到LRU缓存进行加速;
5) 异步IO线程访问冷数据:冷数据的加载不影响服务的整体性能。
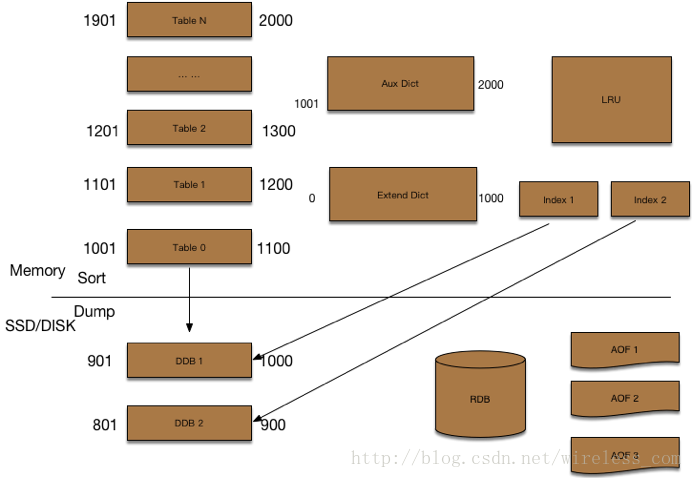
通过上述的扩展,内存占用降为之前的5-10%以下,同时一条feed的评论/赞等多个计数、一个用户的粉丝/关注/微博等多个计数都可以一次性获取,读取性能大幅提升,基本彻底解决了计数业务的成本及性能问题。
欲了解更多有关分布式缓存方面的内容,请阅读《深入分布式缓存:从原理到实践》一书。

京东购书,扫描二维码: