目前市面上已经有很多开源的缓存框架,比如Redis、Memcached、Ehcache等,那为什么还要自己动手写缓存?本章将带领大家从0到1写一个简单的缓存框架,目的是让大家对缓存的类型、缓存的标准、缓存的实现以及原理方面有一个系统的了解,做到知其然,知其所以然。
3.1 缓存定义的规范
JSR是JavaSpecification Requests的缩写,意思是Java规范提案,它已成为Java界的一个重要标准。在2012年10月26日JSR规范委员会发布了JSR 107(JCache API)的首个早期规范,该规范定义了一种对Java对象临时在内存中进行缓存的方法,包括对象的创建、访问、失效、一致性等。
3.1.1 新规范的主要内容及特性
新规范的主要内容如下:
l 为应用程序提供缓存Java对象的功能。
l 定义了一套通用的缓存概念和工具。
l 最小化开发人员使用缓存的学习成本。
l 最大化应用程序在使用不同缓存实现之间的可移植性。
l 支持进程内和分布式的缓存实现。
l 支持by-value和by-reference的缓存对象。
l 定义遵照JSR-175的缓存注解;定义一套Java编程语言的元数据。
从规范的设计角度来看,在javax.cache包中有一个CacheManager接口负责保存和控制一系列的缓存,主要特性包括:
l 能从缓存中读取数据
l 能将数据写入到缓存中
l 缓存具有原子性操作
l 具有缓存事件监听器
l 具有缓存注解
l 保存缓存的KEY和VALUE类型应该为泛型
3.1.2 新规范的API介绍
在JSR107规范中将Cache API(javax.cache)作为实现的类库,通过如下的Maven进行引入。
<dependency>
<groupId>javax.cache</groupId>
<artifactId>cache-api</artifactId>
<version>1.0.0</version>
</dependency>
1. 核心概念
Cache API定义了4个核心概念:
l CachingProvider:定义了创建、配置、获取、管理和控制多个CacheManager。一个应用可以在运行期访问多个CachingProvider。
l CacheManager:定义了创建、配置、获取、管理和控制多个唯一命名的Cache,这些Cache存在于CacheManager的上下文中。一个CacheManager仅被一个CachingProvider所拥有。
l Cache:是一个类似Map的数据结构并临时存储以Key为索引的值。一个Cache仅被一个CacheManager所拥有。
l Entry:是一个存储在Cache中的key-value对。
每一个存储在Cache中的条目有一个定义的有效期,即Expiry Duration。一旦超过这个时间,条目为过期的状态。一旦过期,条目将不可访问、更新和删除。缓存有效期可以通过ExpiryPolicy设置。
2. Store-By-Value和Store-By-Reference
Store-By-Value和Store-By-Reference是两种不同的缓存实现。
l Store-By-Value:指在key/value存入缓存时,将其值拷贝一份存入缓存。避免在其他程序修改key或value的值时,污染缓存内存储的内容。
l Store-By-Reference:指在key/value存入缓存时,直接将其引用存入缓存。
java常见的堆内缓存,一般使用Store-By-Reference方式,提升缓存性能。常见的堆外缓存和进程外缓存,一般由于使用引用在技术上比较复杂,通常使用Store-By-Value方式。
3. 缓存过期策略
如果缓存中的数据已经过期,那它将不能从缓存返回。如果缓存没有配置过期政策,默认是永久有效的策略(Eternal)。
过期策略可以在配置时提供一个ExpiryPolicy实现的设置,见下面的定义
publicinterface ExpiryPolicy<K, V> {
Duration getExpiryForCreatedEntry(Entry<?extends K, ? extends V>entry);
DurationgetExpiryForAccessedEntry(Entry<? extends K, ? extends V>entry);
Duration getExpiryForModifiedEntry(Entry<?extends K, ? extends V>entry);
}
其中:
l getExpiryForCreatedEntry():当数据创建后的到期持续时间
l getExpiryForAccessedEntry(): 当数据访问后的到期持续时间
l getExpiryForModifiedEntry():当数据修改后的到期持续时间
当这些方法被调用时,ExpiryPolicy将返回下列值之一:
l 持续时间等于缓存配置的过期时间
l Duration.ZERO表明数据目前已经是过期的
在特定的缓存操作执行后的一段时间后数据需要进行回收,该时间由Duration类定义。Duration是由一个由java.util.concurrent.TimeUnit和时长durationAmount组成,TimeUnit的最小值为TimeUnit.MILLISECONDS。
3.2 缓存框架的实现
基于3.1节缓存定义的规范,我们可以自己动手写一个简单的缓存框架,我们先对缓存框架做一个初步的规划,实现一个具有如表3-1所描述的特性的简单缓存。
表3-1缓存框架特性
特性点 |
特性描述 |
类型 |
进程内缓存 |
实现语言 |
JAVA |
内存使用 |
JAVA堆内存 |
内存管理 |
使用LRU淘汰算法 支持Weak key |
缓存标准 |
JCache(JSR 107) |
下面,我们将遵循我们的规划,由简入繁逐步迭代我们的缓存组件,我们给组件取名叫做CsCache(Cache Study)。
3.2.1 前期准备
参考开源缓存组件EhCache和Guava,提取它们的公共方法,可以得到最核心的,也是我们最关心的一些方法,见表3-2。
表3-2简单缓存的常用方法
接口 |
说明 |
EhCache |
Guava |
CsCache |
clear |
清空缓存 |
√ |
√ |
√ |
get |
根据Key获取 |
√ |
√ |
√ |
getAll(keys) |
根据Key列表获取,如果未命中可能触发加载动作 |
√ |
√ |
|
getAllPresent(keys) |
根据Key列表获取,如果未命中不会触发加载动作 |
|
√ |
|
keySet() |
获取所有key列表 |
|
|
|
put(K,V) |
写入一个k/v |
√ |
√ |
√ |
putAll(entries) |
将entries写入缓存 |
√ |
√ |
|
putIfAbsent |
如果缓存中没有则写入 |
√ |
√ |
|
remove |
删除一个key |
√ |
√ |
√ |
remove(K,V) |
匹配k/v删除 |
√ |
√ |
|
removeAll(keys) |
根据key列表删除 |
√ |
√ |
|
replace(K,V) |
替换一个key |
√ |
√ |
|
replace (K,V,V) |
匹配k/v替换 |
√ |
√ |
|
我们的缓存框架选取了最基本的get(获取缓存)、put(放入缓存)、remove(根据key值删除缓存)、clear(清空缓辈子)方法,这些方法是实际工作中当中最常用的功能。
3.2.2 缓存的架构介绍
通过上一小节的前期准备,我们确定了缓存框架的几个基本的使用方法,那么从这一小节,我们就由浅入深的介绍CsCache缓存框架。
通过JSR107规范,我们将框架定义为客户端层、缓存提供层、缓存管理层、缓存存储层。其中缓存存储层又分为基本存储层、LRU存储层和Weak存储层,如图3-1所示。
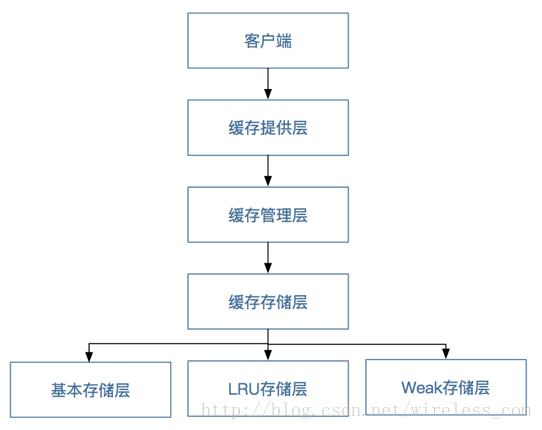
图3-1 缓存分层图
其中:
l 客户端层:使用者直接通过该层与数据进行交互。
l 缓存提供层:主要对缓存管理层的生命周期进行维护,负责缓存管理层的创建,保存、获取以及销毁。
l 缓存管理层:主要对缓存客户端的生命周期进行维护,负责缓存客户端的创建,保存、获取以及销毁
l 缓存存储层:负责数据以什么样的形式进行存储。
l 基本存储层:是以普通的ConcurrentHashMap为存储核心,数据不淘汰。
l LRU存储层:是以最近最少用为原则进行的数据存储和缓存淘汰机制。
l Weak存储层:是以弱引用为原则的数据存储和缓存淘汰机制。
3.2.3 设计思路以及知识点详解
本节开始深入介绍缓存框架的类图以及相关知识点。图3-2所示列出了缓存框架的工程结构。
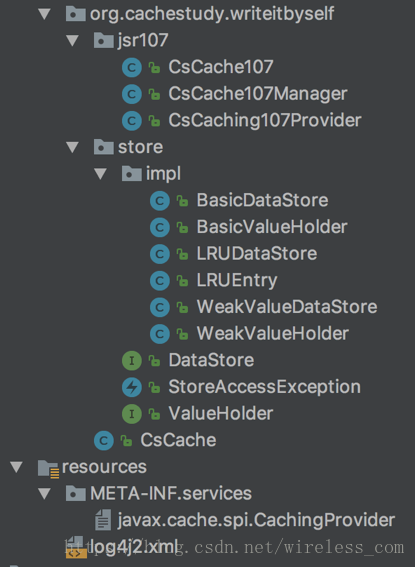
图3-2 框架工程结构图
整个工程结构的包结构分为JSR107包和store包,JSR107是与规范相关的一些类的封装,store包是与数据存储相关类的封装。
1. 设计类图
通过分析3.2.2节的缓存架构介绍和图3-2工程结构图,我们能够对框架的整体情况有一个概览,本小节将以类图的方式展现框架的设计理念,如图3-3所示。
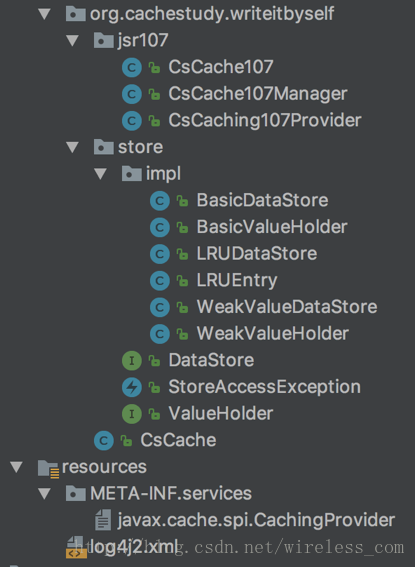
图3-3 类图
根据规范,CacheProvider、CacheManager、Cache是抽象出来的最基础的缓存接口。其中Cache是提供最终缓存实现的基础接口,其实现类是CsCache107,初始化时即持有一个BasicDataStore对象。完整的类列表见表3-3所示。
表3-3 框架核心类列表
类名 |
类型 |
说明 |
CsCache |
类 |
直接使用CsCache的时候,接口类 |
DataStore |
接口 |
存储数据的规范定义 |
BasicDataStore |
类 |
使用ConcurrentHashMap实现的简单数据存储 |
WeakValueDataStore |
类 |
使用ConcurrentHashMap实现的弱引用数据存储 |
LRUDataStore |
类 |
使用ConcurrentHashMap实现LRU算法的数据存储 |
ValueHolder |
接口 |
具体存储值的规范定义 |
BasicValueHolder |
类 |
简单的强引用值存储类 |
WeakValueHolder |
类 |
简单的弱引用值存储类 |
LRUEntry |
类 |
实现了简单LRU的数据存储类 |
*CsCache107 |
类 |
用于适配JSR107标准 |
*CsCache107Manager |
类 |
用于实现JSR107标准中的CacheManager,管理多个cache实例 |
*CsCaching107Provider |
类 |
实现了JSR107标准中的CacheProvider,用于提供SPI服务 |
2. 缓存框架的SPI机制
在工程结构中的META-INF/services/下面有一个javax.cache.spi.CachingProvider配置文件,里面有一个org.cachestudy.writeitbyself.jsr107.CsCaching107Provider实现类,这个配置文件实际上是利用的JAVA SPI机制进行组件的发现与加载。
(1)什么是SPI
SPI的全名为Service Provider Interface,是JDK内置的一种服务提供发现机制,在Java.util.ServiceLoader的文档里有比较详细的介绍。
JAVA SPI机制的思想简单来说是:在面向的对象的设计里,我们一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。JAVA SPI就是提供了这样的一个机制,为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。
(2)SPI的使用约定
当服务的提供者,提供了服务接口的一种实现之后,在jar包的META-INF/services/目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该jar包META-INF/services/里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定。而在jdk里面提供服查找工具类:java.util.ServiceLoader,如图3-4所示。
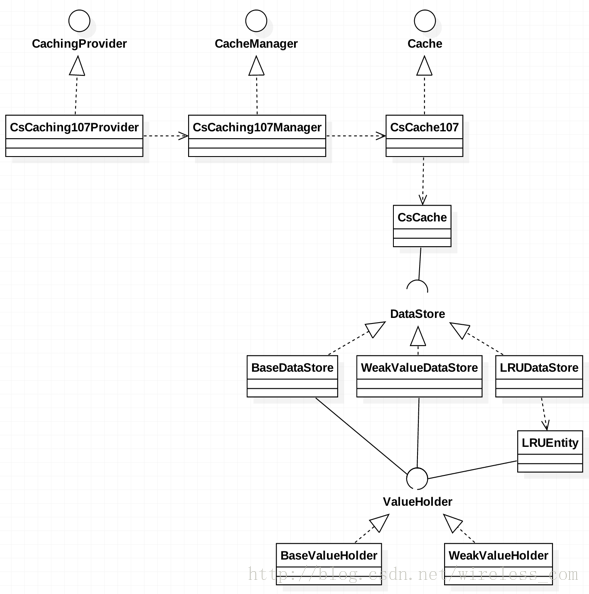
图3-4 SPI约定结构图
3. 解读缓存数据层
缓存数据层实际承担的责任主要是缓存数据的存储和缓存的淘汰机制,在图3-2中可以看到数据的存储和淘汰是基于DataStore这个接口来实现的,而这一实现也正是图3-1提到的数据存储层。目前框架一共实现了三个实现类分别是:LRUDataStore、WeakDataStore和BaseDataStore。
我们先来分析一下LRUDataStore的设计原理:
(1)基于引用的淘汰算法
基于引用的淘汰算法,是一种简单有效的算法,由JVM的GC进行回收。Java的引用主要分为强引用、软引用、弱引用、虚引用。
l 强引用(StrongReference):强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。当内存空间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足的问题。
l 软引用(SoftReference):如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
l 弱引用(WeakReference):弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
l 虚引用(PhantomReference):“虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
我们的引用淘汰算法是基于弱引用来实现的,在图3-5中展示了store包的类列表
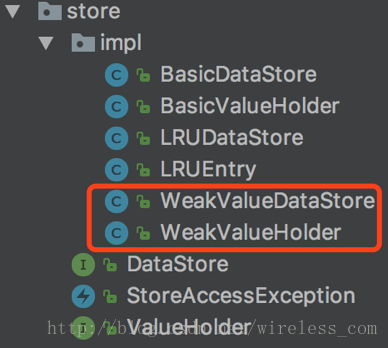
图3-5弱引用淘汰算法
其中WeakValueDataStore和WeakValueHoler是弱引用实现所需要的实现类。WeakValueDataStore实现了DataStore接口,提供基于弱引用的数据存储,WeakValueHolder实现ValueHolder接口,提供基于弱引用的实际值存储逻辑。
WeakValueDataStore类的代码及实现原理如下:
//定义了使用简单弱引用的数据存储器,代码经过剪裁,完整代码请参考github
public classWeakValueDataStore<K, V> implements DataStore<K, V> {
ConcurrentHashMap<K,ValueHolder<V>> map = new ConcurrentHashMap<K,ValueHolder<V>>();
@Override
public ValueHolder<V> get(K key)throws StoreAccessException {
return map.get(key);
}
@Override
public PutStatus put(K key, V value)throws StoreAccessException {
ValueHolder<V> v = newWeakValueHolder<V>(value);
map.put(key, v);
return PutStatus.PUT;
}
@Override
public ValueHolder<V> remove(K key)throws StoreAccessException {
return map.remove(key);
}
@Override
public void clear() throwsStoreAccessException {
map.clear();
}
}
WeakValueHolder的代码及实现原理如下:
//简单的弱引用实现
public classWeakValueHolder<V> implements ValueHolder<V> {
public WeakValueHolder(V value) {
/* 使用JDK提供的WeakReference,建立对象的弱引用
* 在没有强引用时,JVM GC将回收对象,调用WeakReference.get时
* 返回null
*/
this.v = new WeakReference<V>(value);
}
privateWeakReference<V> v;
@Override
public V value() {
return this.v.get();
}
}
测试用例验证方法如下:
@Test
public voidTestWeakValue() throws InterruptedException {
CsCache<String, User> cache = newCsCache<String, User>(new WeakValueDataStore<String, User>());
String key = "leo";
User user = new User();
user.setName("leo");
cache.put(key, user);
/* 释放对象的强引用,等待JVM GC */
user = null;
System.out.println("Hello " + cache.get(key).getName());
System.gc();
Thread.sleep(10000);
/* JVM调度显式GC后,回收了name是leo的user
* get返回null
*/
System.out.println("Hello " + cache.get(key));
}
(2)基于LRU的淘汰算法
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
CsCache的LRU简单实现逻辑如下:我们通过维护entry的列表,在get、put时维护entry列表实现,使最少访问的键值对维持在entry列表的最尾部。在数据量超过缓存容量需要做LRU淘汰时,我们通过删除链表尾部的数据,来实现简单的LRU数据淘汰机制,如图3-6所示。
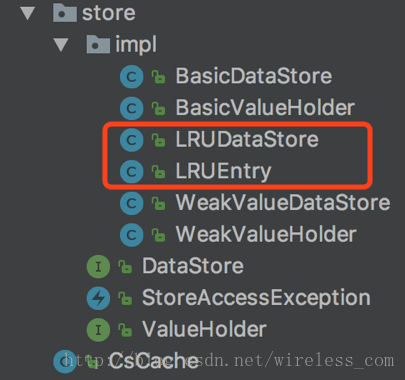
图3-6 LRU淘汰算法
其中LRUDataStore和LRUEntry是弱引用实现所需要的实现类。LRUDataStore实现了DataStore接口。LRUEntry对象则是LRU的数据存储类
LRUDataStore类的关键代码及实现原理如下:
@Override
public ValueHolder<V> get(K key)throws StoreAccessException {
LRUEntry<K, ValueHolder<?>>entry = (LRUEntry<K, ValueHolder<?>>) getEntry(key);
if (entry == null) {
return null;
}
/**
在获取数据的时候,将该entity节点数据移动到列表头。
moveToFirst(entry);
return (ValueHolder<V>)entry.getValue();
}
@Override
public PutStatus put(K key, V value)throws StoreAccessException {
LRUEntry<K,ValueHolder<?>> entry = (LRUEntry<K, ValueHolder<?>>)getEntry(key);
PutStatus status =PutStatus.NOOP;
if (entry == null) {
/**
数据缓存列表中的数据已经超过预定值,则删除列表中
尾的节点数据,以实现LRU算法
**/
if (map.size() >=maxSize) {
map.remove(last.getKey());
removeLast();
}
entry = newLRUEntry<K, ValueHolder<?>>(key, newBasicValueHolder<V>(value));
status = PutStatus.PUT;
} else {
entry.setValue(newBasicValueHolder<V>(value));
status =PutStatus.UPDATE;
}
/**
新添加的数据要加到列表的头部
**/
moveToFirst(entry);
map.put(key, entry);
return status;
}
这段关键代码的核心意思是,在LRUDataStore类中维护了一个LRUEntity的数据链表,当执行put操作的时,则将数据封装成LRUEntity数据节点,加入到链表的头部以表示数据是最新的,如果数据超出链表的设定的大小范围,则从链表的尾部删除最不活跃的数据节点。当执行get操作的时,首先将LRUEntity数据节点移到到链表的头部,以表示该数据被最新请求访问,然后将数据返回。
4. 解读缓存管理层(CacheManager)
在上面图3-1中我们介绍了框架的分层结构,其中接口类CacheManager所对应的正是缓存管理层,在CsCache框架中CacheManager的实现类是CsCache107Manager,它主要负责管理多个Cache客户端实例,以及负责缓存客户端实例的创建、销毁、获取等。
下面具体介绍CsCache107Manager类的关键代码及实现原理。
(1)缓存实例的创建
缓存实例创建的实现代码如下:
//缓存客户端实例的创建
//缓存池是用ConcurrentMap来实现的,用以缓存已经创建好的缓存实例
synchronizedpublic <K, V, C extends Configuration<K, V>> Cache<K, V>createCache(String cacheName, C configuration)
throwsIllegalArgumentException {
if (isClosed()) {
throw newIllegalStateException();
}
//检查缓存实例名称是否为空
checkNotNull(cacheName,"cacheName");
//检查配置信息是否为空
checkNotNull(configuration,"configuration");
//根据cacheName获取缓存客户端实例
CsCache107<?, ?> cache =caches.get(cacheName);
if (cache == null) {
//如果无法从事先创建好的缓存池中获取,则创建一个新的实例
cache = newCsCache107<K, V>(this, cacheName, configuration);
//将新创建的缓存实例加到缓存池中
caches.put(cache.getName(),cache);
return (Cache<K,V>) cache;
} else {
throw newCacheException("A cache named " + cacheName + " alreadyexists.");
}
}
上面的代码只是针对CsCache107Manager类的createCache方法的代码进行了解读,完整的缓存实例的创建流程,如图3-7所示。
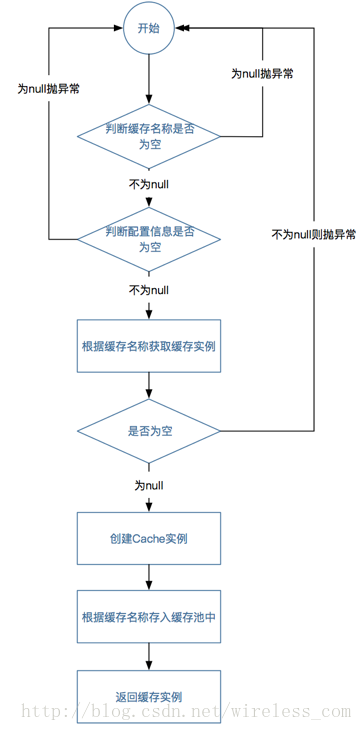
图3-7 缓存实例创建
(2)缓存实例的获取
缓存实例获取的实现代码如下:
public<K, V> Cache<K, V> getCache(String cacheName, Class<K>keyClazz, Class<V> valueClazz) {
if (isClosed()) {
throw newIllegalStateException();
}
//判断key类型是否为空
checkNotNull(keyClazz, "keyType");
//判断值类型是否为空
checkNotNull(valueClazz,"valueType");
//从缓存池中获取缓存实例
CsCache107<K,V> cache = (CsCache107<K, V>) caches.get(cacheName);
//如果获取为空则返回null
if (cache == null) {
return null;
} else {
//判断传入的对象和值类型是否与设定的类型一致
Configuration<?,?> configuration = cache.getConfiguration(Configuration.class);
if(configuration.getKeyType() != null &&configuration.getKeyType().equals(keyClazz)) {
//如果一致则返回实例
return cache;
} else {
//如果不一致则抛出类型不一致异常
throw new ClassCastException("Incompatiblecache key types specified, expected "
+configuration.getKeyType() + " but " + valueClazz + " wasspecified");
}
}
}
完整的缓存实例获取流程图,如图3-8所示。
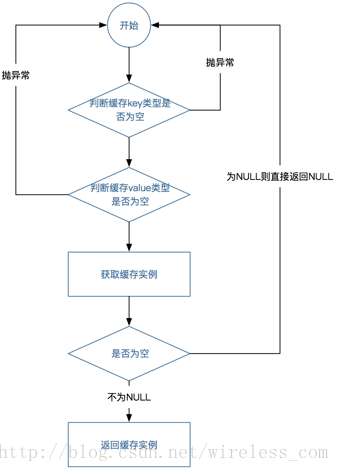
图3-8 缓存实例的获取
缓存实例的创建和获取实际上主要是基于一个缓存池来实现的,在代码中使用的是一个ConcurrentHashMap类,可以根据多个不同的缓存名称创建多个缓存实例,从而可以并发的读取。
5. 解读数据客户端层
缓存客户端层主要是针对实际使用者的,在工程结构中主要涉及二个类,分别是:CsCache和CsCache107,而CsCache107使用的代理模式对CsCache进行的包装,如图3-8所示。用户在使用的时候,通过缓存管理层的CacheManager对象就可以获得CsCache107客户端对象,从而可以实现对缓存的直接操作。
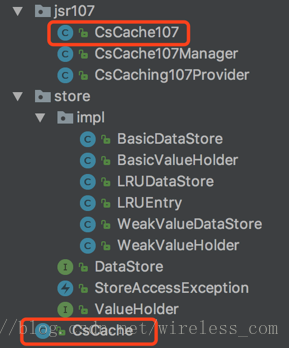
图3-8 数据客户端层
CsCache关键代码和实现原理如下:
privatefinal DataStore<K, V> store;
private static Logger logger =LoggerFactory.getLogger(CsCache.class);
//构造方法,参数是传入数据存储和淘汰策略对象
public CsCache(final DataStore<K, V>dataStore) {
store = dataStore;
}
//根据key值获取缓存数据
public V get(final K key) {
try {
//从数据存储和淘汰策略对象中获取缓存数据
ValueHolder<V>value = store.get(key);
if (null == value) {
return null;
}
//返回缓存数据
return value.value();
} catch (StoreAccessException e){
logger.error("storeaccess error : ", e.getMessage());
logger.error(e.getStackTrace().toString());
return null;
}
}
//缓存数据的存储
public void put(final K key, final Vvalue) {
try {
将数据直接存放到数据和淘汰策略对象中
store.put(key, value);
} catch (StoreAccessException e){
logger.error("storeaccess error : ", e.getMessage());
logger.error(e.getStackTrace().toString());
}
}
整个过程其实较为简单对象的构造方法中有一个DataStore对象,这个对象正是缓数据存储与淘汰策略对象,这个机制已经在解读缓存数据层小节中进行了详解,get方法则是从DataStore中获取缓存数据,put方法则是往DataStore对象中存入数据。
CscCache107对象实际上是对CsCache对象根据JSR107规范,使用了代理模式进行包装,下面将展示几个示例方法,原理与上面CsCache是一样的,本节就不在说明。CsCache107关键代码和实现原理如下:
//获取缓存数据
@Override
public V get(K key) {
return csCache.get(key);
}
//存放缓存数据
@Override
public void put(K key, V value) {
this.csCache.put(key, value);
}
//删除缓存数据
@Override
public boolean remove(K key) {
csCache.remove(key);
return true;
}
通过上面代码可以看到put、get、remove方法都是调用的CsCache对象的相关方法进行的操作,其目的主要是在有特殊需求的时候可以对这几个方法进行功能的扩展和增强。
3.2.3.5 缓存框架的使用示例
缓存框架的实现以及原理到这里就基本介绍完了,下面我们将以一个使用示例结束本章的讲解。
//获取缓存提供层对象
CachingProvidercachingProvider = Caching.getCachingProvider();
//获取缓存管理层对象
CacheManagermanager = cachingProvider.getCacheManager();
//创建缓存实例对象
Cache<String, User> cache =(Cache<String, User>) manager.<String, User, Configuration<String, User>>createCache("Test", new MutableConfiguration<String,User>());
Stringkey = "leo";
User user = new User();
user.setName("leo");
//将User数据对象存放到缓存中
cache.put(key, user);
System.out.println("Hello " +cache.get(key).getName());
为方便读者能够完整的学习CsCache框架,本章实例的完整代码放入在 https://github.com/mfcliu/demo_cache,读者可以自行下载学习。
欲了解更多有关分布式缓存方面的内容,请阅读《深入分布式缓存:从原理到实践》一书。

京东购书,扫描二维码: