去年9月份的时候,我发表过一份技术报告,阐述了我认为人工智能最重要的挑战,大概有以下四个方面:
·可伸缩性(Scalability)计算或存储的成本不与神经元的数量成二次方或线性比例的神经网络;
·持续学习(Continual Learning)那些必须不断地从环境中学习而不忘记之前获得的技能和重置环境能力的代理;
·元学习(Meta-Learning)为了改变自己的学习算法而进行自我参照的代理;
·基准(Benchmarks)具有足够复杂的结构和多样性的环境,这样智能代理就可以派上用场了,而无需对强感应偏差进行硬编码;
在2018年NeurIPS会议期间,我调查了目前其他研究人员关于这些问题的方法和观点,以下是报告的具体内容:
可伸缩性
很明显,如果我们用人工神经网络来实现人类大脑中所发现的1000亿个神经元,标准的二维矩阵乘积并没有多大的用处。
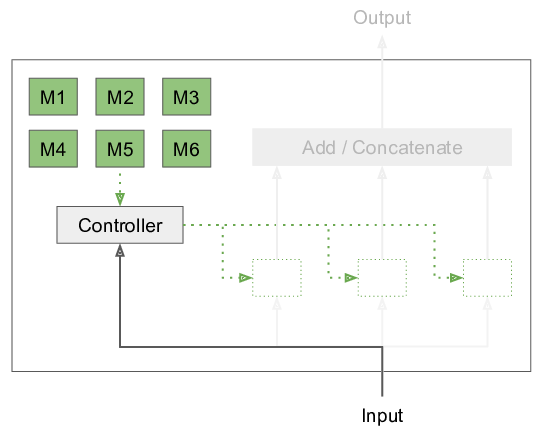
模块层由一个模块池和一个控制器组成,控制器根据输入来选择要执行的模块
为了解决这个问题,我在2018年的NeurIPS上发表了研究性论文《模块化网络:学习分解神经计算》。不评估对于每个输入元素的整个ANN,而是将网络分解为一组模块,其中只使用一个子集,这要取决于输入。这个过程是受人脑结构的启发,在其中我们使用了模块化,这也是为了改善对环境变化的适应能力和减轻灾难性的遗忘。在这个方法中,我们学习到了这些模块的参数,以及决定哪些模块要一起使用。以往有关条件计算的文献都记载着许多模块崩溃的问题,即优化过程忽略了大部分可用的模块,从而导致没有用最优的解决办法。我们基于期望最大化的方法可以防止这类问题的发生。
遗憾的是,强行将这种分离划分到模块有其自身的问题,我们在《模块化网络:学习分解神经计算》中相继讨论了这些问题。相反地,我们可能会像我在关于稀疏性的技术报告中讨论的那样,设法在权重和激活中利用稀疏性和局部性。简而言之,我们只想对少数非零的激活执行操作,丢弃权重矩阵中的整行。此外,如果连通性是高度稀疏的,那么我们实际上可以将二次方成本降到一个很小的常数。这种的条件计算和未合并的权值访问在当前的GPU上实现的成本非常的高,通常来说不太值得操作。
Nvidia处理条件计算和稀疏性
NVIDIA一个软件工程师说,目前还没有计划建造能够以激活稀疏性的形式而利用条件计算的硬件。主要原因似乎是通用性与计算速度之间的权衡。为这个用例搭建专用硬件所花费的成本太高了,因为它有可能会限制其它机器学习的应用。相反,NVIDIA目前从软件的角度更加关注权重的稀疏性。
GraphCore处理的条件计算和稀疏性
GraphCore搭建的硬件允许在靠近处理单元的缓存中向前迁移期间存储激活,而不是在GPU上的全局存储内存中。它还可以利用稀疏性和特定的图形结构,在设备上编译并建立一个计算图形。遗憾的是,由于编译成本太高,这个结构是固定的,不允许条件计算。
作为一个整体的判断,对于范围内的条件计算似乎没有对应的硬件解决方案,目前来说我们在很大程度上必须坚持多机器并行的方式。在这方面,NeurIPS发布了一种全新的分配梯度计算方法—Mesh-Tensorflow,该方法不仅可以横跨多机进行计算,还可以跨模型计算,甚至允许更大的模型以分布式的方式进行训练。
持续学习
长期以来,我一直主张基于深度学习的持续学习系统,即它们能够不断地从经验中学习并积累知识,当新任务出现的时候,这些系统可以提供之前积累的知识以帮助学习。本身,它们需要能够向前迁移,以及防止灾难性的遗忘。NeurIPS的持续学习研讨会正是讨论这些问题的。虽然这两个标准也许是不完整的,但是多个研究者(Mark Ring,Raia Hadsell)提出了一个更大的列表:
·向前迁移
·向后迁移
·无灾难性的遗忘
·无灾难性的冲突
·可扩展(固定的存储和计算)
·可以处理未标记的任务边界
·能够处理偏移
·无片段
·无人控制
·无可重复状态
在我看来,解决这个问题的方法有六种:
·(部分)重放缓冲区
·重新生成以前经验的生成模型
·减缓重要权重的训练
·冻结权重
·冗余(更大的网络->可伸缩性)
·条件计算(->可扩展性)
以上这些方法的任何一个都不能处理上述持续学习列表里的所有问题。遗憾的是,这在实践中也是不可能的。在迁移和内存或计算之间总是有一个权衡,在灾难性遗忘和迁移或者内存或者计算之间也总是有一个权衡。因此,很难完全地、定量地衡量一个代理的成功与否。相反,我们应该建立基准环境,要求持续学习代理具备我们所需要的能力,例如,在研讨会上展示的基于星际争霸(Starcraft)的环境。
此外,Raia Hadsell认为,持续学习涉及到从依赖i.i.d.(Independent and Identically distributed)数据的学习算法转向从非平稳性分布中学习。尤其是,人类擅长逐步地学习而不是IID。因此,当远离IID需求时,我们有可能能够解锁一个更强大的机器学习范式。
论文《通过最大限度地迁移和最小化干扰的持续学习(Continual Learning by Maximizing Transfer and Minimizing Interference)》表明REPTILE(MAML继承者)和减少灾难性遗忘之间有着一个有趣的联系。从重放缓冲区中提取的数据点的梯度(显示在REPTILE)之间的点积导致梯度更新,从而最小化干扰并减少灾难性遗忘。
讨论小组内有人认为,我们应该在控制设置环境中进行终身学习实验,而不是监督学习和无监督学习,以防止算法的开发与实际应用领域之间的任何不匹配。折现系数虽然对基于贝尔曼方程(Bellman Equation)的学习是有帮助的,但对于更现实的增强学习环境设置来说可能存在问题。此外,任何学习,特别是元学习,都会由于学分分配而受到固有的限制。因此,开发具有低成本学分分配的算法是智能代理的关键。
元学习
元学习就是关于改变学习算法其本身。这可能是改变一个内部优化循环的外部优化循环,一个可以改变自身的自引用算法。许多研究人员还关注着快速适应性,即正向迁移,到新的任务或者环境等等。如果我们将一个学习算法的初始参数看作它自己的一部分,则可以将其视为迁移学习或者元学习。Chelsea Finn的一个最新算法—MAML(未知模型元学习法),他对这种快速适应性算法产生了极大的兴趣。例如,MAML可以用于基于模型的强化学习,其中的模型可以快速地进行动态改变。
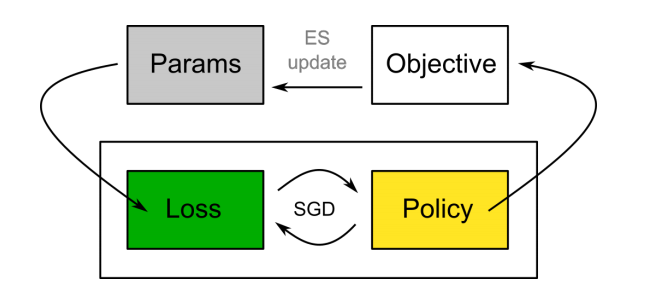
在进化策略梯度(Evolved Policy Gradients ,EPG)中,损失函数使用随机梯度下降法优化策略的参数,同时损失函数的参数也改进了。
一个有趣的想法是代理轨迹和策略输出的可区分损失函数的学习。这允许在使用SGD来训练策略时,对损失函数的几个参数进行改进。与此同时,进化策略梯度的作者们表明了,学习到的损失函数通过回报函数进行了泛化,并允许有快速适应性。它的一个主要问题是学分分配非常缓慢:代理必须使用损失函数进行完全地训练,以获得元学习者的平均回报(适合度)。
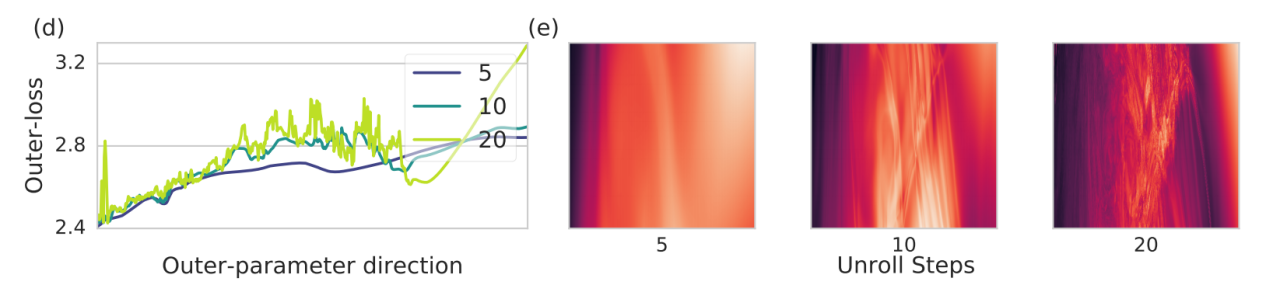
对于学习过的优化器的损失情况变得更加难以控制
我在元学习研讨会上的另一个有趣发现是元学习者损失情况的结构。Luke Metz在一篇关于学习优化器的论文中指出,随着更新步骤的展现,优化器参数的损失函数变得更加复杂。我怀疑这是元学习算法的普遍行为,参数值的微小改变可以关系到最终表现中的巨大变化。我对这种分析非常感兴趣。在学习优化的案例中,Luke通过变分优化(Variational Optimization)—进化策略的一种原则性解释,以此缓和损失情况来解决这个问题。
基准
目前大多数强化学习算法都是以游戏或模拟器为基准环境的,比如ATARI 或者是Mujoco。这些是简单的环境,与现实世界中的复杂性几乎没什么相似之处。研究人员经常唠叨的一个主要问题是,我们的算法来自低效的样本。通过非策略优化和基于模型的强化学习,可以更有效地利用现有数据,从而部分解决这一问题。然而,一个很大的因素是我们的算法没有之前在这些基准中使用过的经验。我们可以通过在算法中手工归纳偏差来避开这一问题,这些算法反映了某些先验知识,但是搭建允许在未来可以利用知识积累的环境有可能更有趣。据我所知,直到现在还没有这种基准环境。雷艇(Minecraft)模拟器可能是最接近这些要求的了。
持续学习星际争霸(Starcraft)环境是一个以非常简单的任务开始的课程。对于如此丰富的环境,另外一种选择是建立明确的课程,如前面提到的星际争霸环境,它是由任务课程组成的。这在一定程度上也是Shagun Sodhani在他的论文《Environments for Lifelong Reinforcement Learning》。他在清单上列出了:
·环境多样性
·随机性
·自然性
·非平稳性
·多形式
·短期和长期目标
·多代理
·因果相互影响
游戏引擎开发商Unity3D发布了一个ML-Agents工具包,用于在使用Unity的环境搭建中进行训练和评估代理。一般来说,现实环境搭建的一个主要问题是需求与游戏实际设计有本质的不同:为了防止过拟合,重要的是,在一个广阔的世界里,物体看起来都是不一样的,因此不能像在电脑游戏中经常做的那样被复制。这意味着为了真正的泛化,我们需要生成的或精心设计的环境。
最后,我相信可以使用计算来生成非平稳环境,而不是通过手动来搭建。例如,这有可能是一个具有与现实世界类似环境的物理模拟器。为了节省计算资源,我们也可以从基于三维像素的简化工作开始。如果这个模拟过程呈现了正确的特性,我们有可能可以模拟一个类似于进化的过程,来引导一个非平稳的环境,开发出许多相互影响的生命形式。这个想法很好地拟合了模拟假设(simulation hypothesis)理论,并且与Conway’s Game of Life有一定的联系。这种方法的主要问题是产生的复杂性与人类已知的概念没有相似点。与此同时,由此产生的智能代理将无法迁移到现实世界中。最近,我发现Stanley和Clune的团队在他们的论文《假想:不断地生成越来越复杂和多样化的学习环境(POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments)》中已经部分地实现了这个想法。环境是非平稳性的,可以被看作是一个用于最大化复杂性和代理学习进程的代理。他们将这一观点称为开放式学习,我建议你阅读一下这篇文章。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《NeurIPS 2018, Updates on the AI road map | Louis Kirsch》
译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文