
前言
前面一文主要讲了NMDB的起源、业务场景以及Media Document数据模型,而本节主要讲述NMDB的系统架构、核心模块以及底层技术。在深入了解其架构之前,我们先要明确NMDB的定位和功能设计目标,先看下Netflix内部视频处理的整个流程:
- 算法处理:Netflix内部有一个Archer平台,在其上运行各种算法来提取视频数据中的元数据,例如提取视频帧中文字信息,提取的元数据为一个Media Document。
- 将Media Document写入NMDB,对其进行持久化和索引。
- 业务方通过NMDB提供的API对Media Document数据进行查询和分析,通常是一些带特定领域特征的时间和空间维度查询。
- 查询结果处理后展示给终端用户。
NMDB主要负责2,3步骤,也就是说不负责算法的执行,但负责对Media Document的存储和索引,提供写入、查询和分析的功能支持。引用下原文中给NMDB的定义:
NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries. At any given time there could be several applications that are trying to persist data about a media asset (e.g., image, video, audio, subtitles) and/or trying to harness that data to solve a business problem.
接下来我们分别看下NMDB的架构和底层实现的一些细节,原文中对核心模块的宏观的东西描述较多,对一些功能点的实现细节描述较少。介绍了一些优化经验以及未来的方向,不过对踩过的坑描述较少。
DataStore
数据模型章节介绍了『Media Document』的结构,『Media Document』就好比关系数据库中表内的行的概念。
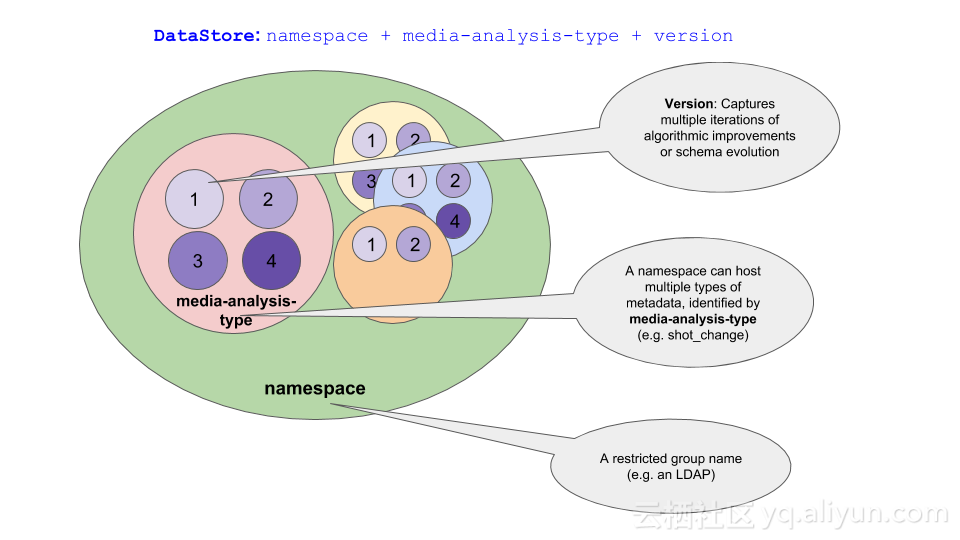
看上图,其中namespace可以类比为mysql的database的概念,而DataStore可以类比为mysql的table的概念,document存储于DataStore之中。NMDB中允许在namespace上定义访问权限,达到数据共享的目的。在namespace内,一个DataStore根据media-analysis-type和version来区分,这是一个比较直观的概念,例如某个人脸检测算法的不同版本对应了不同的DataStore。Namespace可以认为是定义了同类数据的聚集以及共享的策略,media-analytis-type定义了算法的类别,version定义了算法的版本,这三者唯一定位一个DataStore。
DataStore需要定义MID Schema和Document Schema,其中Document Schema已经在上文中提到,是对文档内容的schema预定义以及同时保证向下和向上兼容。MID是Document的一组附加属性,由一个或多个String的Key/Value对构成。MID Schema是对MID的描述,一旦定义则不可再更改。除了MID外,每个Document还拥有一个DocumentID,是Document的唯一标识。
在NMDB中,可以通过DocumentID来查询某个Document,也可以通过MID来查询符合条件的所有Document。
数据存储
NMDB中主要存储的数据是Media Document,再来看下Media Document的数据组成:
- DocumentID:Document的唯一标识。
- MID:由MID Schema定义好的String类型的Key/Value对。
- Document:由Document Schema定义的可扩展的嵌套文档数据。
Media Document的数据有几个关键的特征,一是数据不可更改,二是弱关系无约束,三是单个Document数据较大。底层存储首要考虑是数据的可靠性、存储的规模以及写入的吞吐。所以使用分布式NoSQL数据库来持久化数据是比较合理的选择,国外比较知名的是Cassandra,Netflix也是选择了使用Cassandra作为持久化数据存储。
Cassandra的特征是Schemaless,Schemaless的特征是『schema-on-read』,也就是说在查询后才能知晓结构。而上文中提到NMDB其实对Schema是需要预定义的,即『schema-on-write』,需要保证写入的数据符合Schema定义。为了在一个Schemaless的存储上达到强Schema的约束,NMDB中引入了一个服务MDVS(Media Data Validation Service),主要作用就是在Document写入NMDB前,根据Document Schema对Document做数据检查。
在NMDB内部,由一个专门的服务MDPS(Media Data Persistence Service)来管理Cassandra集群。MDPS接收Media Document(MID + Document)作为输入,生成UUID作为DocumentID,也作为Cassandra表的Primary Key。MDPS中隐藏了Media Document到Cassandra表中Row的映射,文中对关系映射也没有更多的描述。不过可以大概猜到应该是一个宽行的结构,一行为一个Document,MID和Document中的部分内容应该是拆分为多个字段,为了方便后续的条件过滤以及局部内容查询。
数据索引
从文中的描述看,NMDB提供的查询功能比较丰富,主要是对时间线(Media Timeline)数据的时间和空间维度的查询,也有对非结构化数据的检索(全文索引)。有覆盖全文档的搜索,也有文档内的局部数据的条件查询。
NMDB中处理查询的模块有两个,一个是MDQS(Media Data Query Service),另一个是MDAS(Media Data Analysis Service)。文中对MDQS的描述比较少,看不出它提供的功能主要是什么,不过大致可以猜到应该主要是对Cassandra的查询的封装。
NMDB内选型用Elasticsearch作为文档的索引引擎,Elasticsearch本身就是一个分布式、高性能的文档模型索引数据库,能够同时满足结构化数据(灵活的多字段组合)以及非结构化数据(文本)的查询和检索需求,满足扩展性以及高性能的要求。这也是业界比较成熟的一个架构,Cassandra + Elasticsearch或者HBase + Solr,Cassandra/HBase提供高吞吐、可靠的存储,Elasticsearch/Solr提供对存储的数据的索引,两者结合打造一个集成高可靠数据存储、高吞吐数据写入、高效的多维度查询、结构化及非结构化数据检索一体的在线数据服务。MDAS管理了Elasticsearch集群的写入和查询,并且对Media Document的存储和索引做了非常多的优化,这个在后面的章节会细讲。
数据查询
在NMDB内部,主要常见的是两种查询模式:
- DataStore级别覆盖所有文档的搜索,搜索的条件是任意字段的条件组合。
- 指定DocumentID查询某个特性的Document,条件获取文档的部分数据。
文中没有细说这两种查询场景分别是怎么实现的,不过可以大致猜中第一种应该是利用了Elasticsearch的索引来做海量数据内的多条件组合查询,而第二种场景应该是直接查询Cassandra做条件过滤。
架构概览
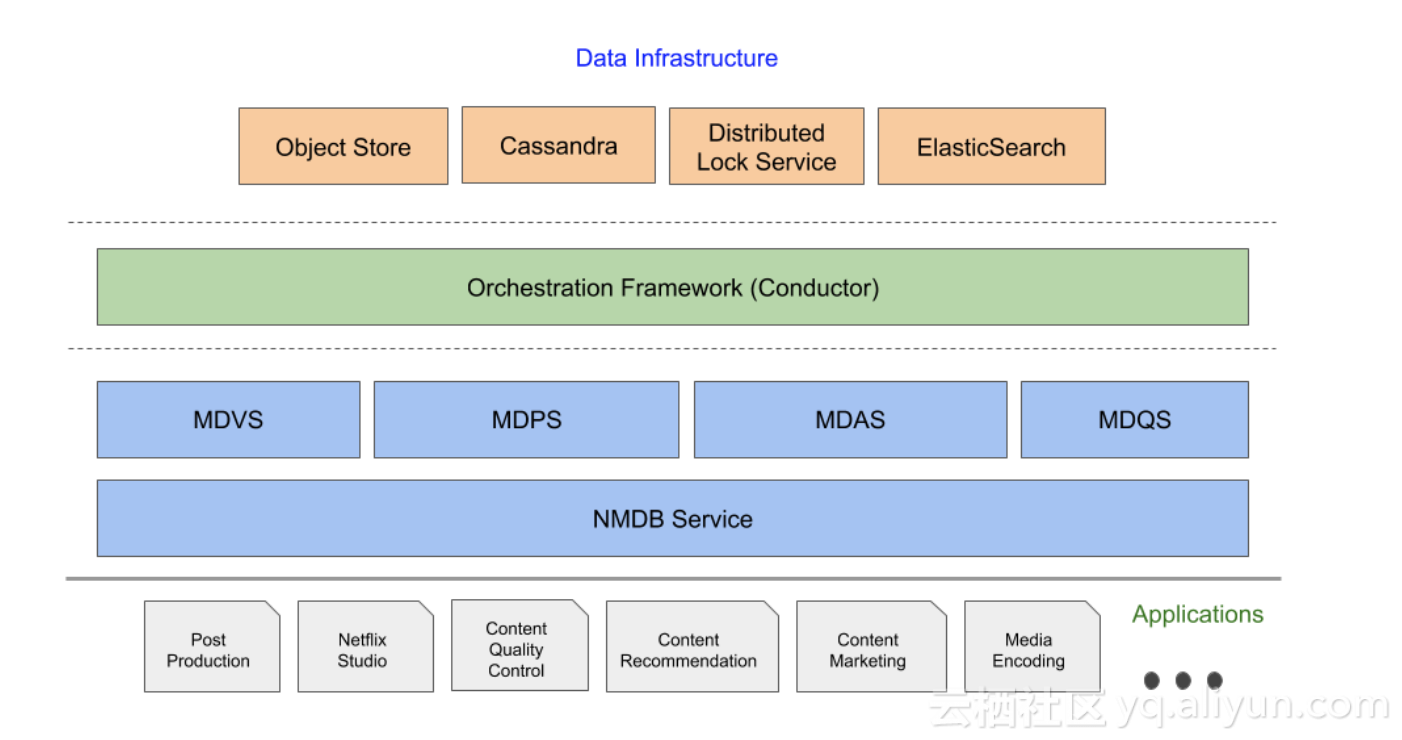
来看下NMDB的整体架构,核心服务包括MDVS、MDPS、MDAS以及MDQS,底层核心组件主要是Object Store(采用AWS的S3)、Cassandra、Distributed Lock Service以及Elasticsearch,外加一个用于协调所有流程的核心组件-Conductor。
Object Store在架构内部是作为数据交换的中枢,起了非常重要的作用。它保存了原始的Media Document数据,一个Media Document的大小可能会非常大(数百MB,例如可能会保存每一帧的元数据和空间属性信息等,会有较大的膨胀)。NMDB内部微服务架构的各个组件之间可能需要传递这些元数据,为了避免大量数据在传输链路中传递,所以采用了中心化的数据传输模式。
NMDB提供的读操作是同步的,但是对于写操作以及较长时间的分析操作均采取异步化的方式,所有异步的操作均通过Conductor的工作流来协调。『异步化』是比较关键的一个设计点,大大简化了系统设计。各组件之间被解耦,依赖被弱化,一个组件的失效不会影响其他组件,大大增加了架构的容错性。不过『异步化』也带来一些By disign的不足,例如数据可查询需要等数据被异步的索引完成后,只能提供最终一致性的读。这是一种架构设计需要做的权衡,相比提供业务非必需的强一致读,还是优先保证架构的简单干净,相信是一个比较容易作出的选择。
写流程
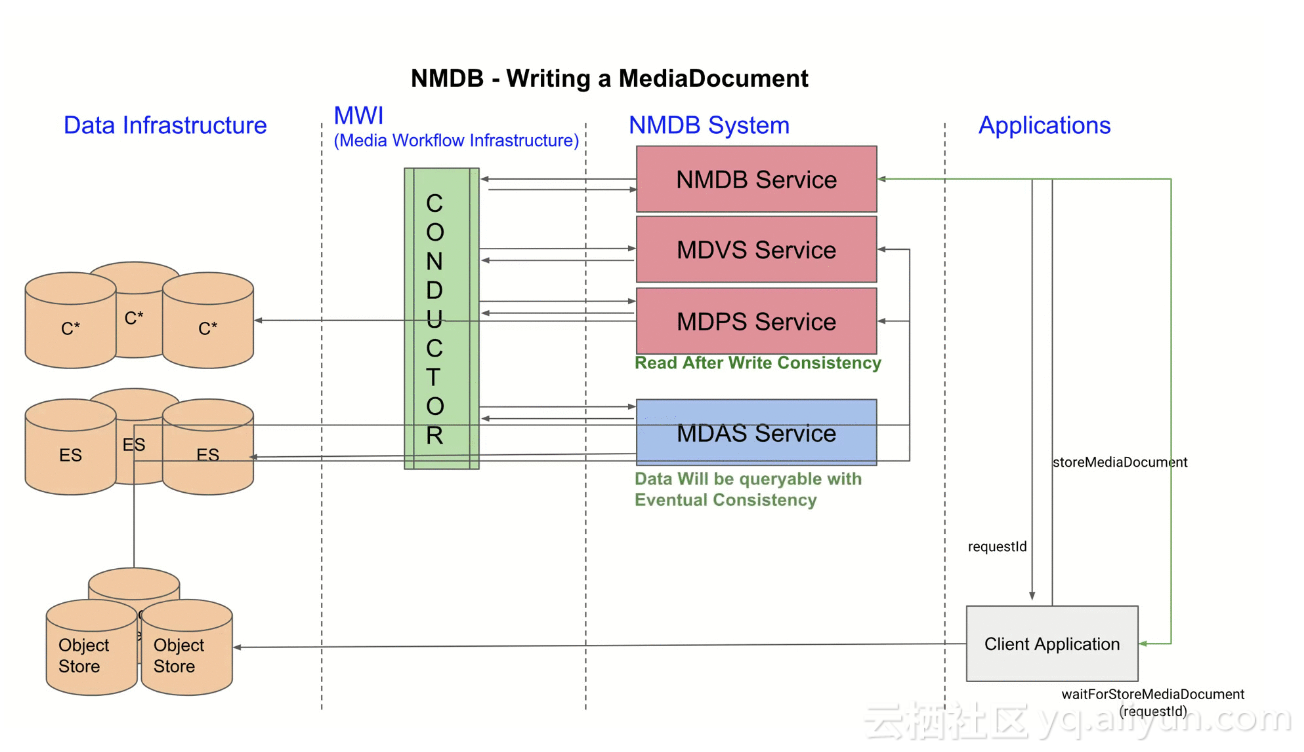
为加深对NMDB内部各模块功能及如何协作的理解,我们看下Media Document的整个写入流程:
- Application将通过算法平台分析视频文件提取的Media Document存入Object Store。
- Application通知NMDB处理文档(通过传递Media Document在Object Store内的位置),整个处理过程是异步的,所以NMDB会返回给应用一个requestId,可通过这个requestId来查询工作流状态。
- NMDB内部接到处理请求后,会开始一个新的Conductor工作流:
- 调用MDVS,根据Document Schema对Document内容进行校验。
- 调用MDPS,将Document持久化入Cassandra,持久化完毕后即可提供数据读取(read)。
- 调用MDAS,将Document通过Elasticsearch进行索引,索引完毕后即可提供搜索和查询(search and queries)
- 工作流结束后,该Document处理完成。
一些优化
Scaling strategies
NMDB内包含多个核心服务,分服务节点和数据节点,对于这些组件有不同的水位管理方式以及扩容策略。对于服务节点,需要关注服务是计算密集型还是IO密集型,例如对于MDVS是计算密集型服务,而对于MDAS是IO密集型服务,不同类型的服务需要关注不同的指标。另外对于提供同步请求的服务还是异步请求的服务,关注点也不一样,同步请求服务需要关注CPU和RPS(request per second),而异步请求服务需要关注任务队列长度。
对于服务节点的扩容,相对来说还是比较简单的。一旦遇到瓶颈,扩容也比较容易,并且如果是做到无状态的服务,那扩容基本上是很迅速以及无影响的操作。但对于数据节点,扩容就比较复杂,通常来说周期比较长,对于水位管理的挑战的也更大。NMDB内部的数据节点主要是Object Store、Cassandra和Elasticsearch,对于Object Store无需关心水位,因为使用的是AWS的S3,而对于Cassandra和Elasticsearc则需要NMDB自己管理。
对于数据节点的扩容,就是水平扩展更多机器。但水平扩展是否有效,还取决于数据节点内的数据分布以及是否存储计算分离。对于存储计算分离的架构,扩容机器后能很快的扩充存储以及迁移计算压力。而对于非存储计算分离架构,则需要先搬迁数据后才能迁移计算压力。典型的数据分布有Range Partition和Hash Partition,对于Range Partition的数据库例如HBase,水平扩容后只需要对Region进行Split,则很快就能打散计算压力。而对于Hash Partition的数据库例如Cassandra和Elasticsearch,则稍微有点不同。Cassandra采用一致性哈希,扩容后也比较简单能打散存储和计算。但是Elasticsearch采用简单的取模散列,水平扩容对于打散计算就不一定有效。
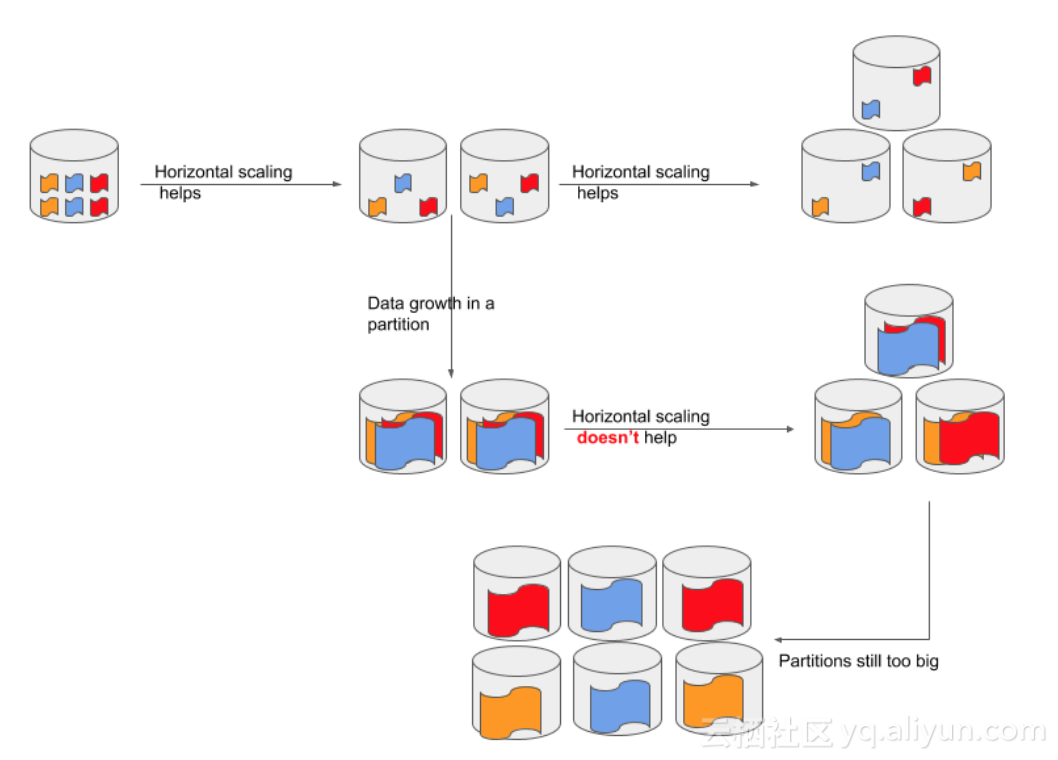
就如上图所示,当Elasticsearch的一个Shard数据量不算大,那扩容后通过relocation shard,是能把数据和计算打散。但如果一个Shard的数据规模和计算消耗都很大,那扩容后即使对Shard做了一个打散,还是没啥用。这个时候就需要对索引做Reindex,分配更多的Shard。但是Reindex是一个对计算消耗较大,非常耗时的一个操作,特别是当Index数据量已经很大的时候。
所以基于Elasticsearch当前的模式,NMDB采用了另外的策略,如下图。
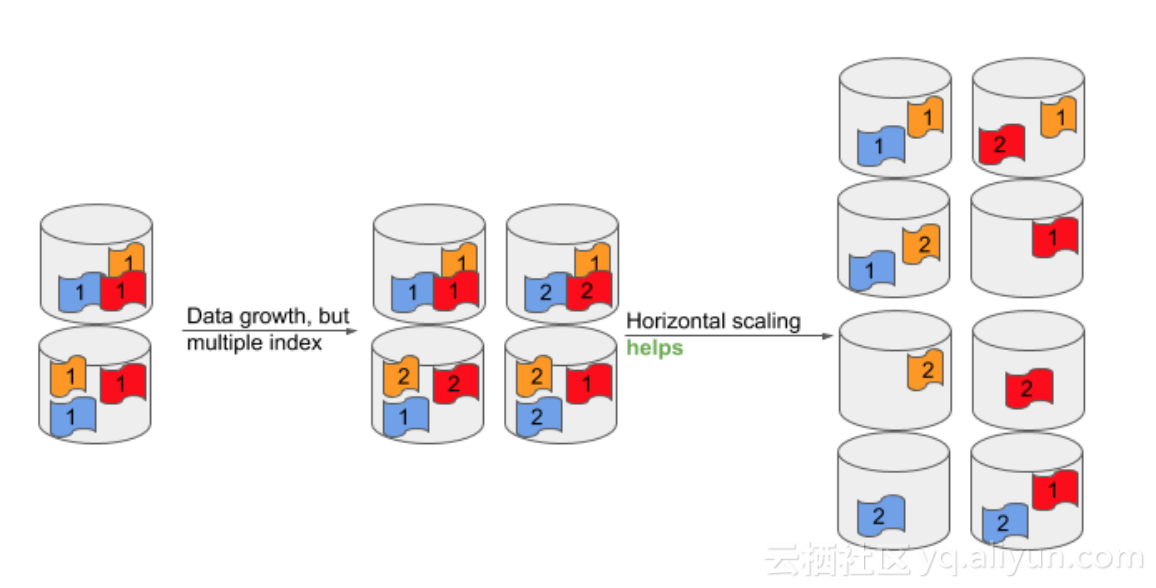
NMDB对Elasticsearch采用了多Index的设计,这也是利用了Media Document不可修改的特性(类似于ELK内日志存储的解决方案),所以可以按时间或大小来分Index。NMDB会控制一个Index的大小,来保证最优的读写速度。Elasticsearch本身也提供了index alias的功能,能够跨索引做查询。
Large Document
NMDB中一个Document可能达到数百MB,甚至是数GB的大小。在Elasticsearch内,对一个Document的大小会有限制。如果Document很大,那这一行数据整体也会很大,对于写入和查询都不是很友好(对写入速度、并行处理度以及对CPU和内存的消耗都有影响)。
NMDB中设计了一个策略来解决Large Document的问题,思路比较简单,就是将一个大文档分而治之,拆成多个小文档。Elasticsearch有提供两种机制来做文档之间的关联,一种是parent-child document,另一种是nested document。nested document支持多级嵌套,结构与Media Document比较匹配。不过当嵌套比较深的时候,查询性能会急剧下降,而Media Document会有5层嵌套(Document -> Track -> Component -> Event -> Region)。parent-child document只支持两级的关系,所以Media Document最多拆成量级,例如按照Event或Region来拆。不过这样拆会导致child document数量很多,也会导致性能的极具下降。
NMDB采用的方案是parent-child,不过为了避免产生过多child,又采取了另一种策略 - chunking。『chunking』的思想是采取反范式设计(SQL到NoSQL的思想之一),将一个大的文档拆成无关联关系的多个小的文档,将需要保留的关联数据复制到各个chunk中。这样做之后有诸多好处,包括: 能并行处理、更均衡的资源消耗、避免热点以及更快的索引速度。
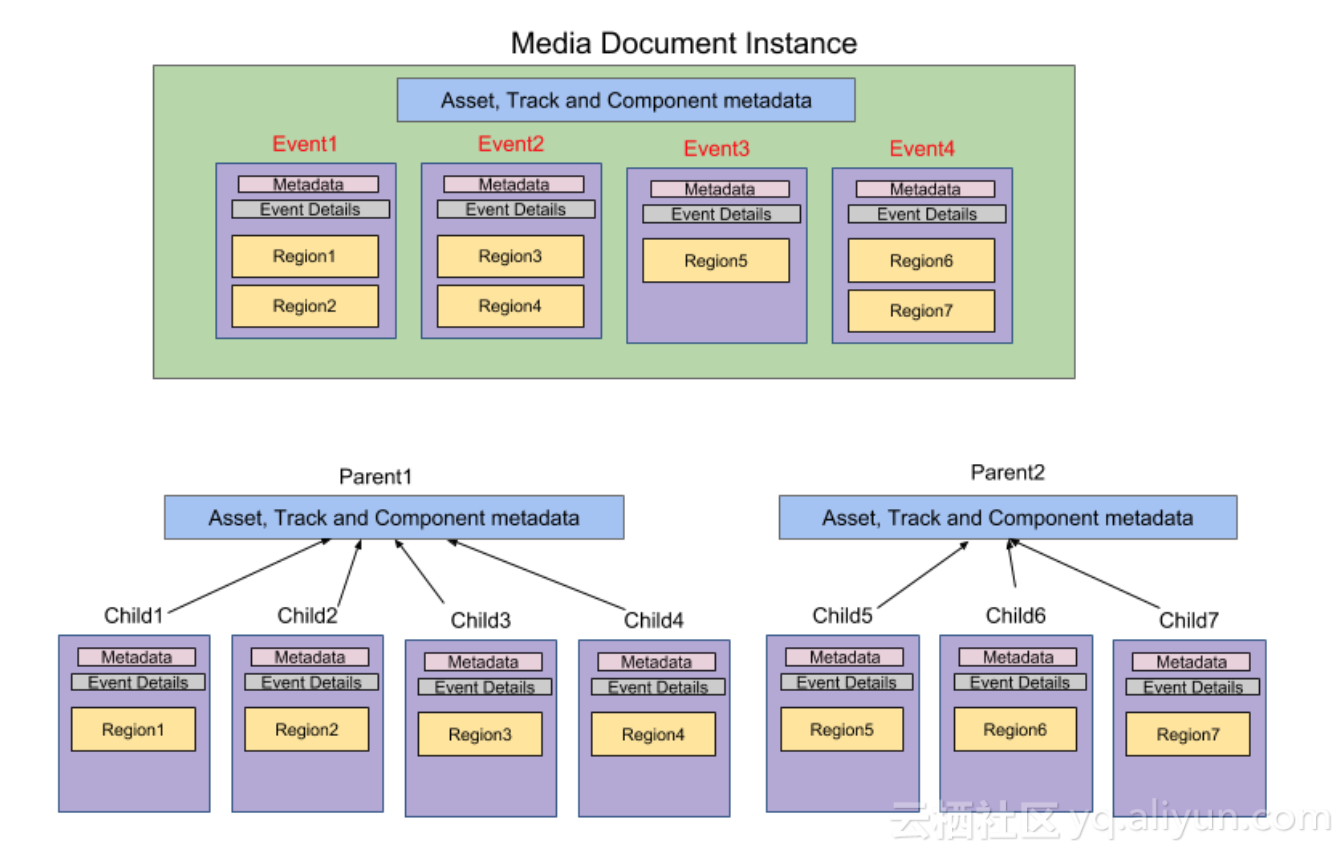
上图就是对一个大文档进行『chunking』处理的例子,其中有几个关键点:
- 以Event为最小单位,将一个Media Document拆分成大小均匀的多组父子文档,每个父文档中重复保存Track和Component的元数据。
- 按每个Region变成一个子文档,每个子文档中重复保存Event的元数据。
what's next
文中最后提出了几个未来会去调研和改进的点:
- 模型改进:Media Document的数据模型是比较直观的嵌套层次结构模型,但是不利于并行处理(上文提到是反范式的设计来拆解)。一种对并行计算更友好的结构应该是组合结构,例如将一条时间线拆成多个小的时间线,每个小的时间线为一个Media Document。
- 计算优化:NMDB面临越来越多的跨DataStore的大数据分析,会去调研引入其他的大数据计算方案。
最后,NMDB发源自Netflix,拥有最多的客户需求,最丰富的数据以及最复杂的场景。只有不断的做架构迭代,探索并引入新的技术,才能从容的面临挑战。
