centos 安装clickhouse
curl -s https://packagecloud.io/install/repositories/altinity/clickhouse/script.rpm.sh | sudo bash
sudo yum list 'clickhouse*'
sudo yum -y install clickhouse*
docker安装可以直接克隆
https://gitee.com/pyzy/cloudcompute
clickhouse 数据类型
数据类型没有boolean其他基本和hive一样,详细的看官网
clickhouse 引擎
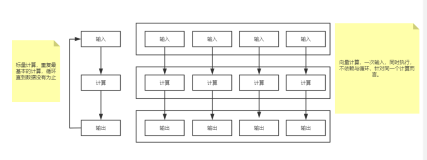
clickhouse有很多引擎,最常用的是 MergeTree家族 还有Distributed引擎
clickhouse 创建表
clickhouse可以创建本地表,分布式表,集群表
create table test()为本地表
CREATE TABLE image_label_all AS image_label ENGINE = Distributed(distable, monchickey, image_label, rand()) 分布式表
create table test on cluster()为集群表
贴一个完整的建表语句,使用ReplicatedMergeTree引擎
CREATE TABLE metro.metro_mdw_pcg ( storekey Int32, custkey Int32, cardholderkey Int32, pcg_main_cat_id Int32, pcg_main_cat_desc String, count Int32, quartly String ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/metro/metro_mdw_pcg', '{replica}') PARTITION BY (quartly, pcg_main_cat_id) ORDER BY (storekey, custkey, cardholderkey)
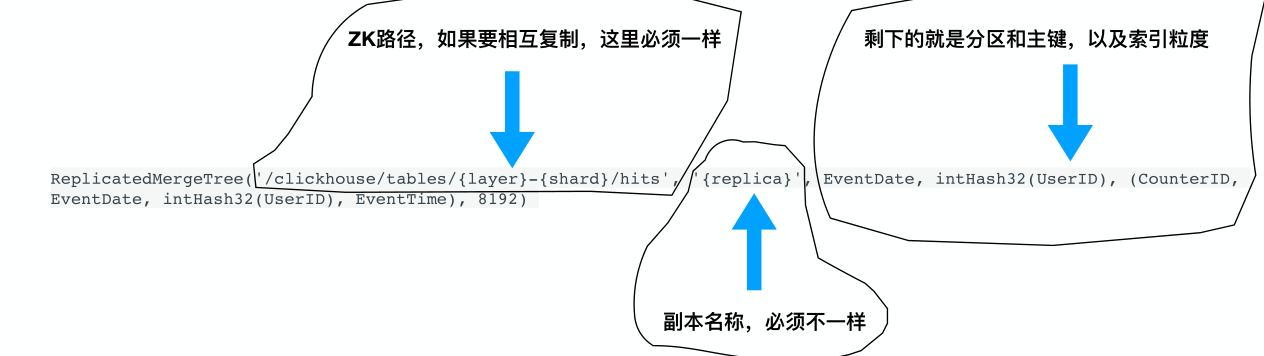
保证数据复制
clickhouse数据操作
增加可以使用insert;
不能修改,也不能指定删除;
可以删除分区,会删除对应的数据 我使用--help看了一下有truncate table,但是没有具体使用过,如果要全部删除数据可以删除表,然后在建表查数据
可以使用脚本操作
database=$1 table=$2 echo "Truncate table "$2 create=`clickhouse-client --database=$1 --query="SHOW CREATE TABLE $table" | tr -d '\\'` clickhouse-client --database=$1 --query="DROP TABLE $table" clickhouse-client --database=$1 --query="$create"
再导入数据就可以了
导入数据,clickhouse支持很多文件类型 详细的看官方文档,文件导入导出
贴两个经常用的文件的导入
tsv,以"\t"隔开
clickhouse-client -h badd52c42f08 --input_format_allow_errors_num=1 --input_format_allow_errors_ratio=0.1 --query="INSERT INTO tablename FORMAT TSV"<file
csv 以","或者"|"隔开
clickhouse-client -h adc3eaba589c --format_csv_delimiter="|" --query='INSERT INTO tablename FORMAT CSV' < file
数据查询
clickhouse的 查询sql 表单查询基本和标准sql一样,也支持limit 分页,但是inner join 的查询写法不一样,而且我用4亿+2000万inner join的速度很慢
两个sql对比 inner join要花费将近一分钟,使用in子查询仅3秒, 建议都使用in查询,clickhouse的单表查询速度很快,3亿数据count distinct 仅1秒左右
其它的技巧和知识,本人占时未做了解,希望大家能一起学习,一起进步