0. 项目背景
基于阿里云ECS云服务器进行搭建私有的大数据平台,采用Apache Hadoop生态,为大数据提供存储及处理。
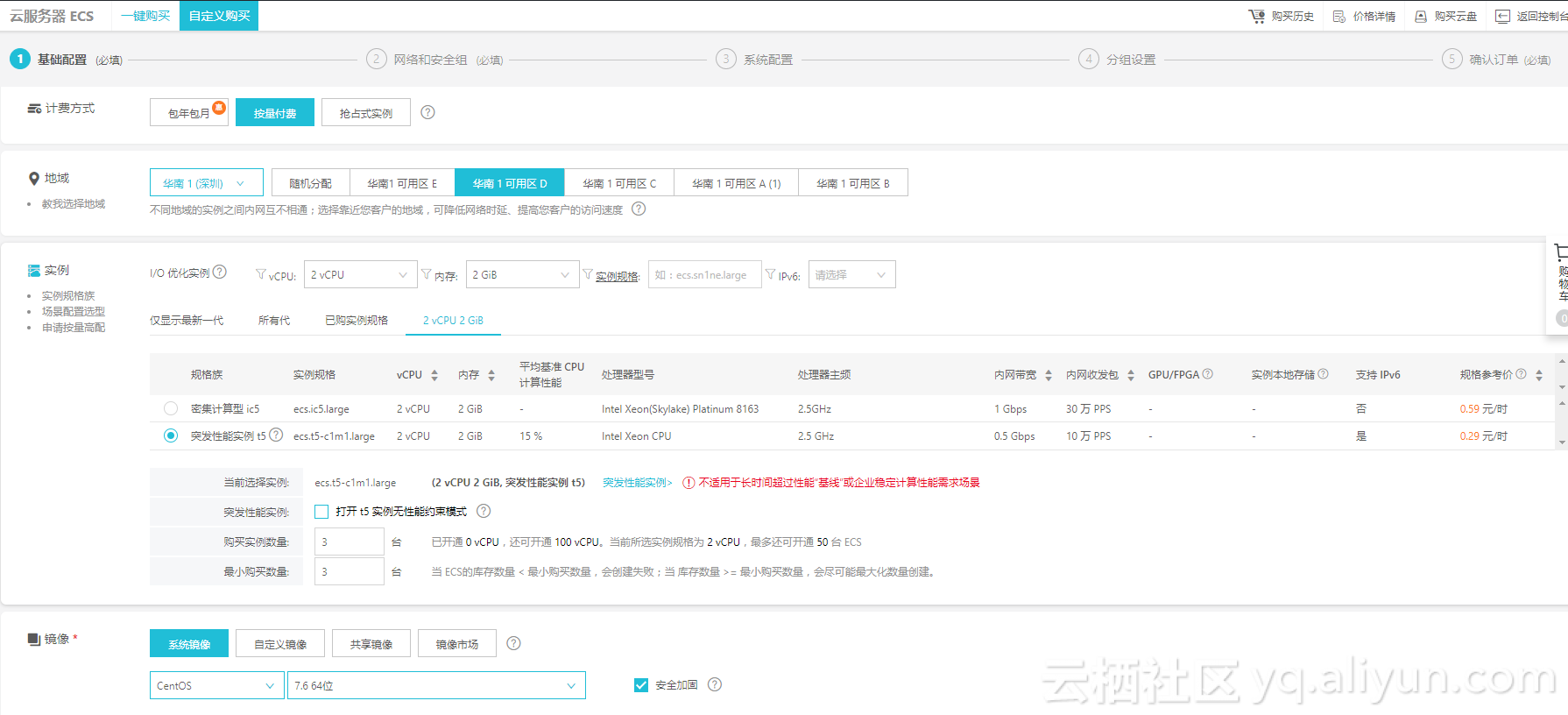
1. 购买ECS云服务器实例
在这里,因为实验需要3个节点,所以我们购买3台ECS实例。

2. 远程登录服务器,进行基础环境的配置。
# 工欲善其事,必先利其器
# 前提准备
# 安装系统命令
yum -y install wget vim ntpdate net-tools ntpdate
2.1 节点信息
172.18.53.98 master
172.18.53.99 slave1
172.18.53.100 slave2
2.2 修改主机名,每一个节点都需要修改。

2.3 配置主机文件(每一个节点都需要执行)
vi /etc/hosts
172.18.53.98 master
172.18.53.99 slave1
172.18.53.100 slave2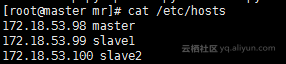
2.4 系统防火墙和内核防火墙配置(每一个节点都需要执行)
# 临时关闭内核防火墙
setenforce 0# 永久关闭内核防火墙
vi /etc/selinux/config
SELINUX=disabled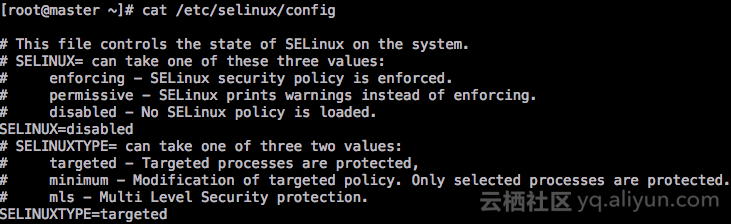
# 临时关闭系统防火墙
systemctl stop firewalld.service
# 永久关闭内核防火墙
systemctl disable firewalld.service

2.5 SSH互信配置
ssh-keygen -t rsa# 三次回车生成密钥(每一个节点都需要执行)
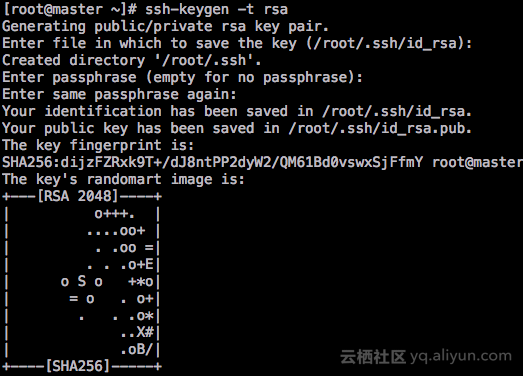
# 生成公钥(主节点执行)
cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys
chmod 600 /root/.ssh/authorized_keys# 复制其他节点的公钥(主节点执行)
ssh slave1 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
ssh slave2 cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys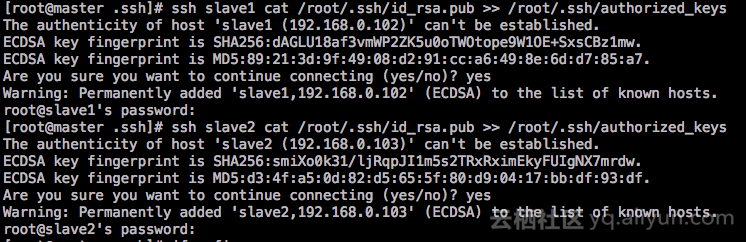
# 复制公钥到其他节点(主节点执行)
scp /root/.ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys
# 免密SSH测试
ssh slave1 ip addr
ssh slave2 ip addr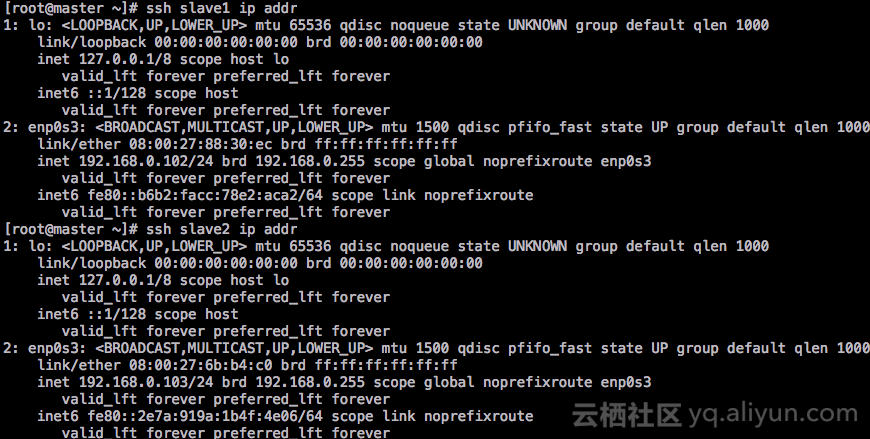
到这一步,我们已经搞定了基础环境的配置,主要是针对时间、主机名、防火墙等服务进行配置。
3. JDK环境的安装
cd /usr/local/src
tar zxvf jdk-8u191-linux-x64.tar.gz# 配置环境变量,在配置最后加入
vim /etc/profile
JAVA_HOME=/usr/local/src/jdk1.8.0_191
JAVA_BIN=/usr/local/src/jdk1.8.0_191/bin
JRE_HOME=/usr/local/src/jdk1.8.0_191/jre
CLASSPATH=/usr/local/src/jdk1.8.0_191/jre/lib:/usr/local/src/jdk1.8.0_191/lib:/usr/local/src/jdk1.8.0_191/jre/lib/charsets.jar
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin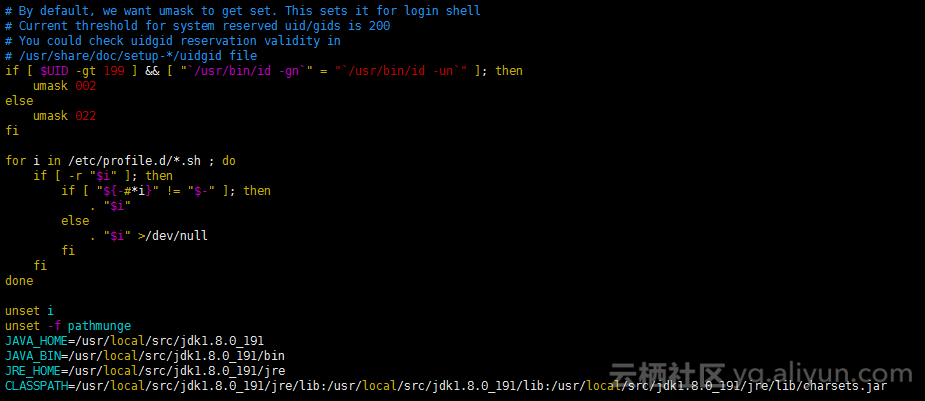
# 复制环境变量到其他节点
scp /etc/profile root@slave1:/etc/profile
scp /etc/profile root@slave2:/etc/profile# 复制JDK包到其他节点
scp -r /usr/local/src/jdk1.8.0_191 root@slave1:/usr/local/src/jdk1.8.0_191
scp -r /usr/local/src/jdk1.8.0_191 root@slave2:/usr/local/src/jdk1.8.0_191
# 重新加载环境变量
source /etc/profile# 测试环境是否配置成功
java -version
到这一步,我们已经安装和配置了JAVA运行环境,因为Hadoop是Java开发的,所以我们必须需要在JAVA环境上运行Hadoop。
5. Hadoop环境安装
# 解压Hadoop包
cd /usr/local/src
tar zxvf hadoop-2.6.5.tar.gz # 修改配置文件 在第24行添加Java的环境变量
cd hadoop-2.6.5/etc/hadoop/
vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191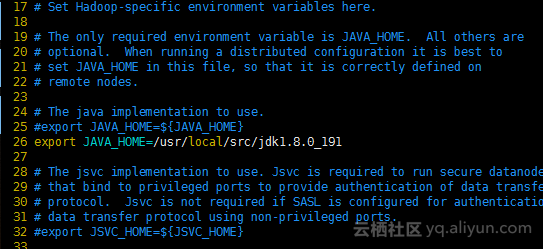
# 修改配置文件 在第24行添加Java的环境变量
vim yarn-env.sh
export JAVA_HOME=/usr/local/src/jdk1.8.0_191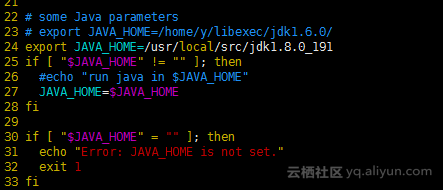
# 修改配置文件 添加从节点主机名
vim slaves
slave1
slave2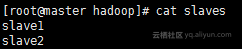
# 修改配置文件 添加RPC配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.18.53.98:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/tmp</value>
</property>
</configuration>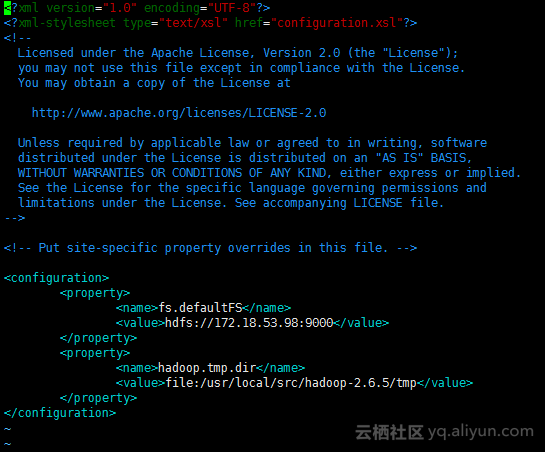
# 修改配置文件 添加DFS配置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.6.5/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>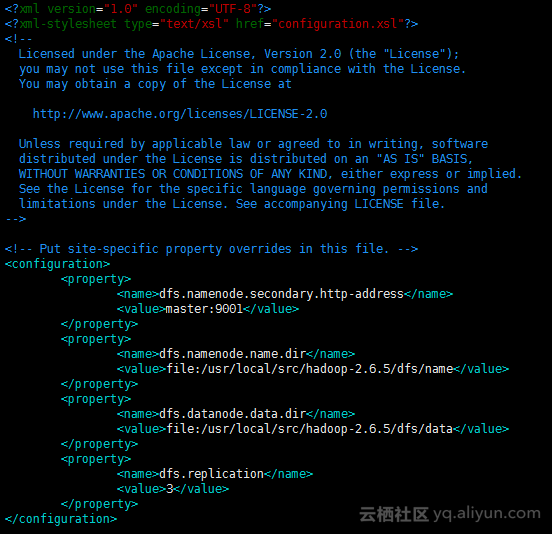
# 修改配置文件 添加MR配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>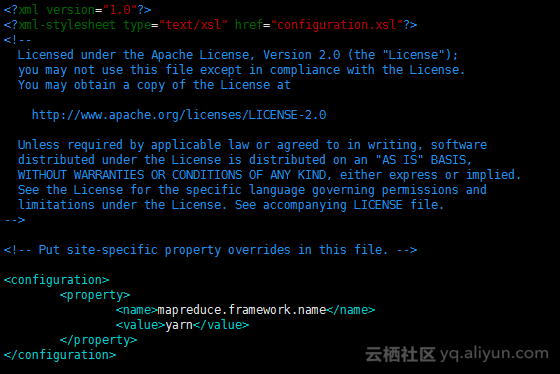
# 修改配置文件 添加资源管理配置
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>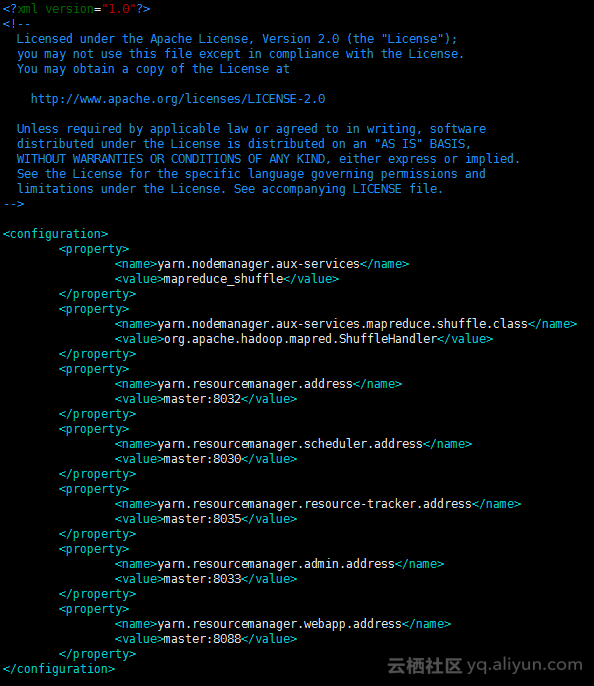
mkdir /usr/local/src/hadoop-2.6.5/tmp
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/name
mkdir -p /usr/local/src/hadoop-2.6.5/dfs/data
vim /etc/profile
HADOOP_HOME=/usr/local/src/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/binscp /etc/profile root@slave1:/etc/profile
scp /etc/profile root@slave2:/etc/profile
scp -r /usr/local/src/hadoop-2.6.5 root@slave1:/usr/local/src/hadoop-2.6.5
scp -r /usr/local/src/hadoop-2.6.5 root@slave2:/usr/local/src/hadoop-2.6.5source /etc/profilehadoop namenode -format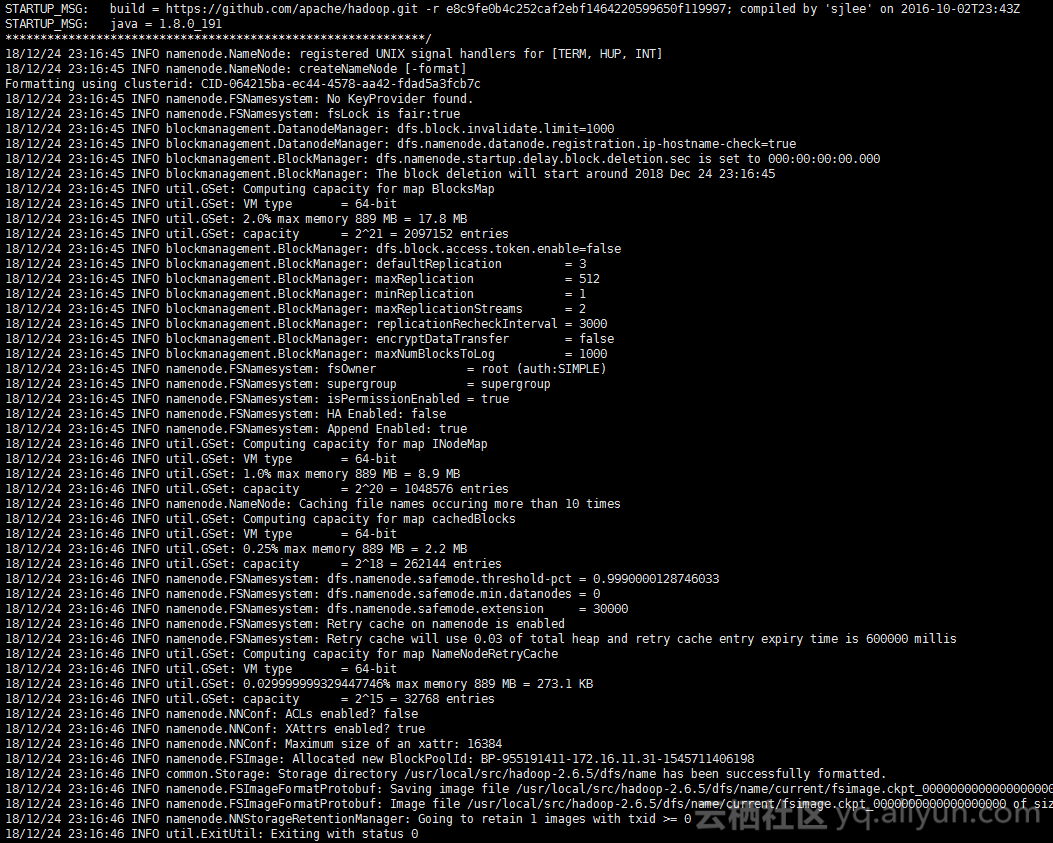
# 提示下列内容即是成功完成格式化
common.Storage: Storage directory /usr/local/src/hadoop-2.6.5/dfs/name has been successfully formatted
# 启动集群
/usr/local/src/hadoop-2.6.5/sbin/start-all.sh
# 查看服务进程
# Master: ResourceManager - Namenode - SecondaryNameNode
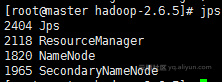
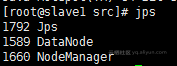
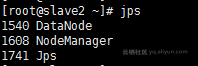
# Slave: NodeManager - DataNode
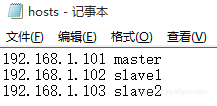
# 网页控制台 (需要修改本地hosts文件 添加主机记录)
# Windows C:\Windows\System32\drivers\etc
# Linux /etc/hosts
# Mac /etc/hosts
# Yarn管理界面
# 浏览器访问 http://master:8088/cluster
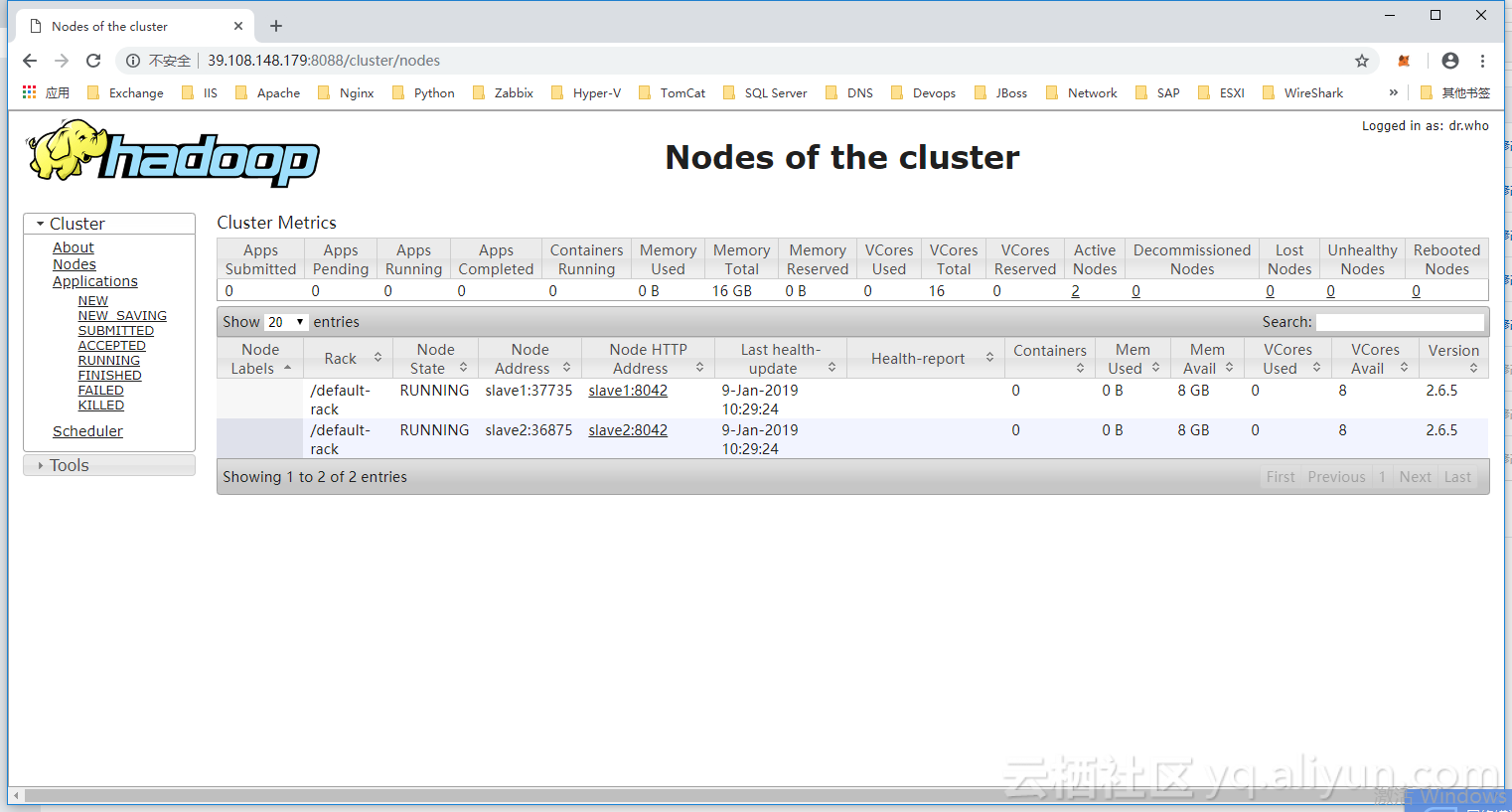
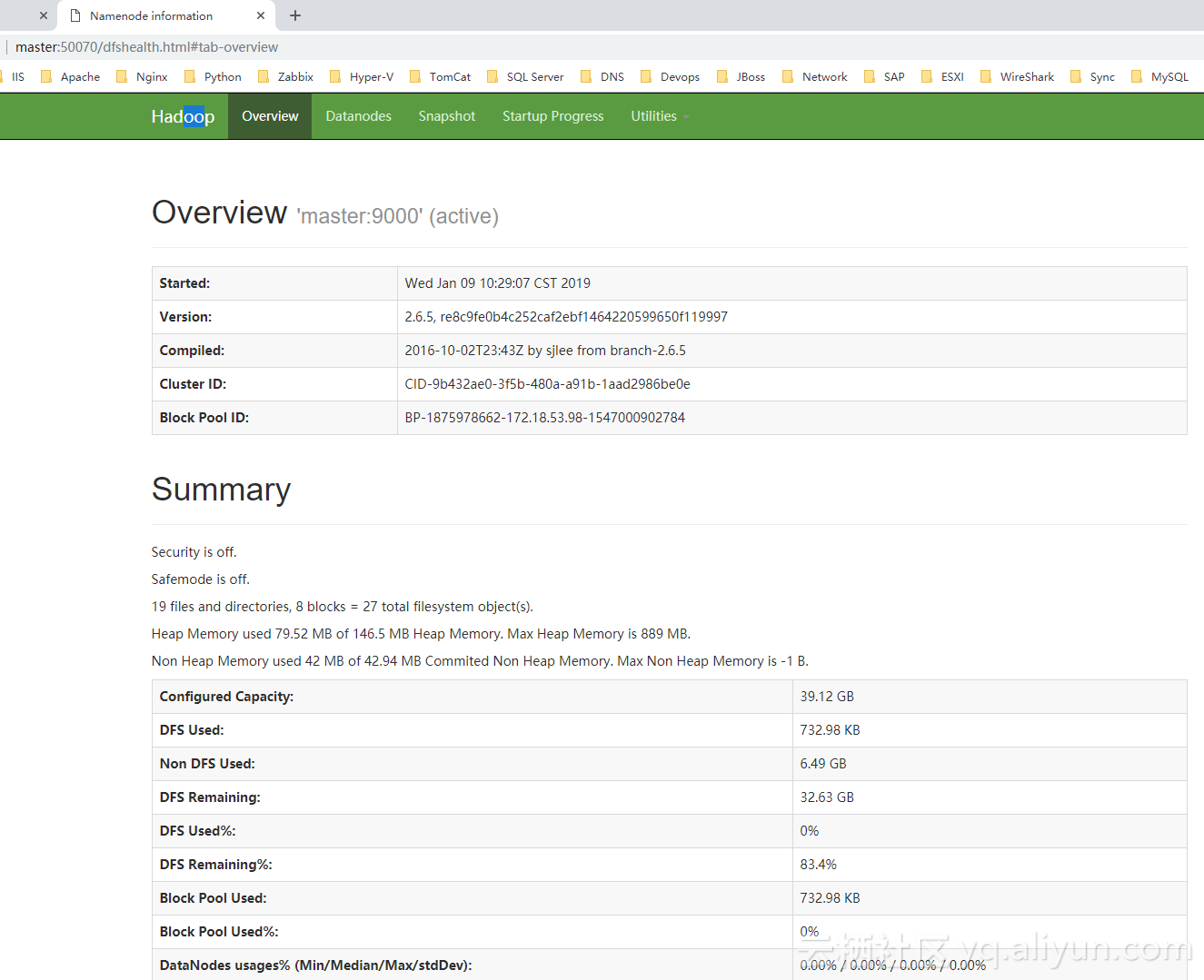
# HDFS管理界面
# 浏览器访问 http://master:50070