本期分享专家:隽勇, 曾就职微软,擅长网络、Windows相关技术,网络问题的终结者,现就职阿里云专注于弹性计算方面的技术研究,“对技术负责,更对用户负责”
针对客户反馈的问题,不但要解决,还要总结分析,隽勇针对SLB问题进行了分析总结,发现大家遇到的很多负载均衡(简称 SLB)异常问题都与健康检查配置相关。不合理的健康检查策略可能会导致很多问题出现:
例如:
· 健康检查间隔设置过长,无法准确发现后端 ECS 出现服务不可用,造成业务中断。
· 使用 HTTP 模式健康检查,未合理配置后端,导致后端日志内容记录大量健康检查 HEAD 日志,造成磁盘负载压力。
如何解决这些问题,为了让大家走出常见的误区,隽勇今天带大家来了解下健康检查的原理、常见的误区以及最佳实践。从此 SLB 健康检查用起来得心应手,再也不用踩坑了。
原理要点
对于健康检查的原理,详情请参考官网知识点:负载均衡健康检查原理浅析
文章重点阐述了如下几个方面:
· 健康检查处理过程
· 健康检查策略配置说明
· 健康检查机制说明
· 健康检查状态切换时间窗
总结要点如下:
1、4层TCP健康检查通过TCP 3次握手检查后端 ECS 端口是否监听。与普通的TCP连接使用TCP FIN方式销毁过程不同,健康检查的连接在3次握手建立成功后,以TCP Reset方式主动将连接断开。
2、7层健康检查通过HTTP HEAD 请求检查指定URL路径的返回值,如果返回值与自定义的健康检查成功返回值相匹配,则判定检查成功。
3、负载均衡使用 TCP 协议监听时,健康检查方式可选 TCP协议 或 HTTP协议。
4、UDP协议的健康检查是通过ICMP Port Unreachable消息来判断,可能存在服务真实状态与健康检查不一致的问题,我们后续会持续产品改进解决该问题。
5、健康检查机制的引入,有效提高了承载于负载均衡的业务服务的可用性。但是,为了避免频繁的健康检查失败引发的切换,对系统可用性带来的冲击,健康检查只有在【连续】多次检查成功或失败后,才会进行状态切换(判定为健康检查成功或失败)。
使用误区
以下是通过客户问题反馈进行的梳理,我们总结的常见健康检查的理解和使用配置误区:
误区1 : 怀疑SLB健康检查形成DDoS攻击,导致服务器性能下降。
例如,某用户误认为SLB服务端使用上百台机器进行健康检查,大量的TCP请求会形成DDoS攻击,造成后端机器性能低下。但实际上,无论是TCP/UDP/HTTP协议的健康检查,其根本无法形成DDoS攻击。
原理上,SLB集群会利用多台机器(假定M个,个位数级别)对后端 ECS 的每个服务监听端口 (假定N个) ,按照配置的健康检查间隔(假定O秒,一般建议最少2秒)进行健康检查。以TCP协议为例,每秒的TCP连接建立数为:M*N/O。
因此,健康检查带来的每秒TCP并发数,主要取决于创建的监听端口数量。除非监听端口达到巨量,否则健康检查对后端ECS的TCP并发连接请求,根本无法达到SYN Flood的攻击级别,实际对后端ECS的网络压力极低。
误区2 : 用户为了避免SLB健康检查的影响,将健康检查间隔设置很长。
该配置会导致当后端ECS出现异常时,负载均衡需要较长时间才能侦测到后端ECS不可用。尤其当后端ECS间断不可用时,由于SLB需要【连续】检测失败时才会移除异常ECS,较长的检查间隔会导致负载均衡集群可能根本无法发现后端ECS不可用。
举一个实际案例:
背景信息:
某用户1个公网负载均衡, 后端有2台ECS对外提供服务,TCP协议的健康检查间隔设置为50秒。某天用户做了应用代码改进后,发布到1台测试ECS,而后将该ECS加入负载均衡。但是由于应用问题以及不合理的健康检查的设置,出现了连续2次业务不可用。
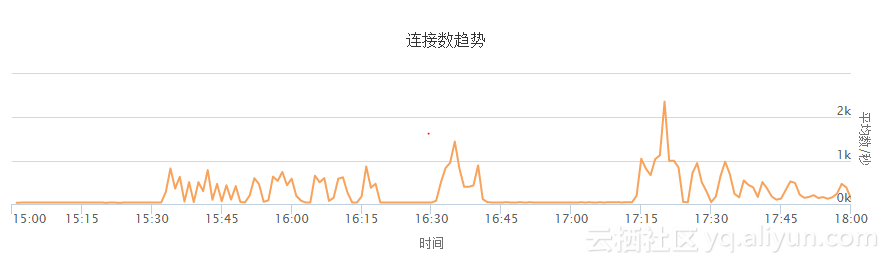
图示. 失败连接数趋势
上图"连接数趋势"代表负载均衡失败连接数的变化趋势。从图中可以看到,出现了2次负载均衡业务间断不可用的情况。
阶段1: 15:29 - 16:44: 该问题由于应用代码的原因导致。
阶段2: 17:12起 : 该问题由于单台ECS无法承担业务量导致。
如下是复盘的详细过程:
【15:26】 用户创建ECS机器(假定名称i-test), 部署最新的应用代码,加入负载均衡集群中。
【15:29】由于新应用代码的问题,该ECS i-test上线后,负载均衡将业务转发至该ECS后,其CPU飙升至100%。

图示. ECS CPU
从前图"失败连接数趋势"可以看出,15:30分,负载均衡报出4层TCP转发失败的连接数开始飙升,原因就是新加入的ECS i-test机器在CPU 100%的情况下,出现业务不可用。而且从15:34分开始,后端的ECS健康检查日志中开始出现健康检查失败的信息,但是由于用户设置的间隔为50秒,而后端ECS i-test也不是完全不响应,偶尔的TCP 三次握手健康检查还可以成功,因此未出现【连续】健康检查失败,所以该负载均衡的监听端口未报出异常状态。
用户接到终端客户反馈,业务出现断续不可用的情况,用户开始紧急自查。但由于负载均衡状态未报出异常,用户将排查集中在应用侧。
【16:44】用户紧急将ECS i-test从负载均衡中下线,更换为老版本的应用。
【16:56】用户将装有老版本应用的ECS i-test上线到负载均衡集群。此时,负载均衡集群有3个ECS在提供服务,业务恢复正常。从前图"失败连接数趋势"中,可以看到失败的数量降到0。
【17:12】业务恢复后,用户认为之前问题是由于业务代码的问题导致。此时用户通过将权重设置为0将2台原先的ECS下线,由新上线的那台ECS i-test承担所有业务。此时,ECS i-test由于业务量陡增,IP Conntrack表耗尽,大量新建TCP连接失败。所以看到从17:12分起,负载均衡大量的连接建立失败。由于健康检查间隔高,我们从负载均衡的日志中看到,该ECS的健康检查状态在很长一段时间内保持正常,负载均衡集群无法及时判断后端ECS实际状态,当前端用户反馈后,才发现实际业务影响,导致业务中断时间较长。
从该示例可以看出,合理的配置健康检查间隔对于及时发现业务不可用问题非常重要。
误区3 : 使用HTTP模式健康检查,未合理配置后端,导致后端日志内容记录大量健康检查HEAD日志,造成磁盘负载压力。
我们确实遇到过一例健康检查配置,导致后端ECS的性能低下的案例。用户购买低配(1核1G) ECS,使用7层HTTP健康检查,健康检查间隔低,同时配置多个监听,后端ECS的Web服务记录大量的HEAD请求日志,导致IO占用高,引起性能低下。
解决方案请参考知识点"健康检查导致大量日志的处理"。
最佳实践
结合负载均衡健康检查的技术要点和实际中所遇到的使用误区,我们提供如下最佳实践:
1、根据业务需要合理选择TCP 或 HTTP的健康检查模式。
如果使用HTTP 健康检查模式,请合理配置后端日志配置,避免健康检查HEAD请求过多对IO的影响。
HTTP健康检查请不要对根目录进行检查,可以配置为对某个HTML文件检查以确认Web服务正常。
2、合理配置健康检查间隔
根据实际业务需求配置健康检查间隔,避免因为健康检查间隔过长导致无法及时发现后端ECS出现问题。具体请参考:
3、合理配置负载均衡架构,监听、虚拟服务器组合转发策略。
为满足用户的复杂场景需求,目前负载均衡可以配置虚拟服务器组和转发策略。详情请参考文档:
对于虚拟服务器组、转发策略,其与监听对健康检查并发的影响相同,如下图:
| 维度 |
健康检查配置 |
健康检查目标服务器 |
| 后端服务器 |
使用配置监听时的健康检查配置 |
所有后端 ECS |
| 虚拟服务器组 |
使用配置监听时的健康检查配置 |
相应虚拟服务器组包含的服务器 |
| 转发策略 |
使用配置监听时的健康检查配置 |
相应虚拟服务器组包含的服务器 |
建议用户根据实际业务需求,合理配置监听、虚拟服务器组和转发策略。
a、对于4层TCP协议,由于虚拟服务器组可以是有后端ECS不同的端口承载业务,因此在配置4层TCP的健康检查时不要设置检查端口,而"默认使用后端服务器的端口进行健康检查", 否则可能导致后端ECS健康检查失败。
b、对于7层HTTP协议,使用虚拟服务器组合转发策略时,确保健康检查配置策略中的URL在后端每台机器上都可以访问成功。
C、避免过多的配置监听、虚拟服务器组和转发策略,以免对后端ECS形成一定的健康检查压力。
经过上边原理、误区和最佳实践,是不是有种恍然大悟的感觉,那说明你认真看完了整篇文章。小编给你一个大大的赞。关于SLB健康检查还有哪些想了解的,欢迎留言讨论。本期就到这里了,我们下期再见。
