关于hadoop的分享此前一直都是零零散散的想到什么就写什么,整体写的比较乱吧。最近可能还算好的吧,毕竟花了两周的时间详细的写完的了hadoop从规划到环境安装配置等全部内容。写过程不是很难,最烦的可能还是要给每一步配图,工程量确实比较大。
原计划准备接上一篇内容写dkhadoop的监控页面的参数,突然觉得还是有必要把上两周写的内容做一个汇总,这样方便需要的朋友浏览。上两周写的五篇内容,汇总到一起就算是hadoop新手入门的一个基础性教程吧(持续更新中)。

五篇文章讲什么?
前两周时间写的五篇文章,其实都在讲一件事情——hadoop运行环境安装部署!可能口头描述几分钟就可以把整个过程说完了,但一旦使用文字来表述就发现每一个部分都写的好长。五篇文章分别介绍了集群管理系统的搭建规划、虚拟机安装、Linux操作系统安装、操作系统服务器配置、DKhadoop下载安装。这五篇文章按照上面的顺序汇总到一起才是完整。
1. 《hadoop集群管理系统搭建规划说明》
2. 《最新虚拟机搭建hadoop环境详细图文教程》
3. 《Hadoop伪分布式环境搭建之Linux系统安装教程》
4. 《hadoop服务器基础环境搭建之Hadoop服务器配置教程》
5. 《超详细hadoop下载安装教程(附图文)》
适合什么人?
Hadoop的大神们可以直接忽略翻过的,当然对于能够无意中看完并且提供宝贵意见的甚是感谢!分享的这些内容只能说是适合hadoop新手入门以及hadoop爱好者吧!而且可能由于使用的hadoop发行版不同的原因,如果你直接按照分享的步骤操作可能也会有“惊喜”!毕竟所有的文章也是我个人操作时的步骤截图整理出来的,而且可能会在后续整理码字的时候忘掉了某些细微的设置,影响最终的执行效果!
Hadoop用的什么发行版
Hadoop版本是比较多的,目前用的是国产的一款发行版(免费的)DKHadoop。3月份的时候在大快搜索站点上下载的3节点的一个版本。好像大快网站在改版,下载链接目前不能用了。应该在改版完成后就可以正常申请下载了。如果有朋友要的可以留言说一下,我把下载的这个版本打包给你!
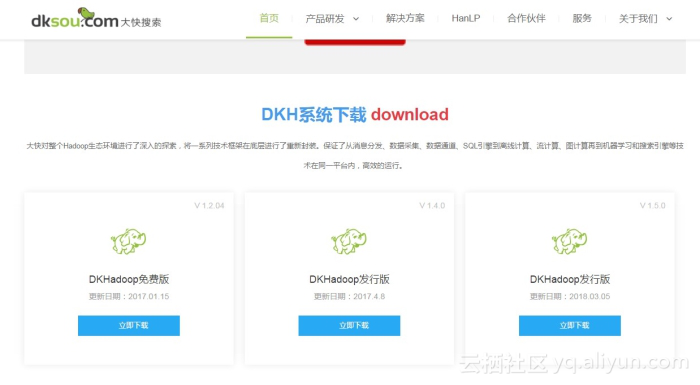
DKhadoop给我的感觉是对新手入门级的算是很友好的,简单来说就是易用性做的很好!你不需要每次用到一个新东西的时候就可能要重新配置环境。置于易用性到何种程度,以后有空写一篇对比的文章吧!