-- 执行计划释义
注意:
计划动作执行时遵循最上最右先执行的原则
执行计划相关视图
--------------------------------------------------------------------------------
v$sql
v$sqlarea
v$sql_cs_histogram
v$sql_cs_statistics
v$sql_cs_selectivity
v$sql_shared_cursor
v$sql_bind_metadata
--------------------------------------------------------------------------------
捕获查看执行计划方式
--------------------------------------------------------------------------------
-- 方式一:explain plan for
explain plan for select * from t1;
select * from table(dbms_xplan.display());
-- 方式二 set autotrace on
步骤1:set autotrace
set autotrace on (得到执行计划,输出运行结果,最后打印执行计划和统计信息)
set autotrace traceonly (得到执行计划,不输出运行结果)
set autotrace traceonly explain (得到执行计划,不输出运行结果和统计信息部分,仅展现执行计划部分)
set autotrace traceonly statistics (不输出运行结果和执行计划部分,仅展现统计信息部分)
set autotrace off; --关闭打印
set timing on; --打印执行时间
set autotrace on explain; --只显示执行计划路径报告
set autotrace on statistics; --只显示统计信息
-- 常见问题:
SQL> set autotrace on;
SP2-0618: 无法找到会话标识符。启用检查 PLUSTRACE 角色
SP2-0611: 启用 STATISTICS 报告时出错
SQL> conn /as sysdba
SQL> @D:\app\Administrator\product\11.2.0\dbhome_1\sqlplus\admin\plustrce.sql; /*这个是数据库安装路径下的sql文件*/
SQL> conn ahern/oracle
SQL> set autotrace on;
SP2-0618: 无法找到会话标识符。启用检查 PLUSTRACE 角色
SP2-0611: 启用 STATISTICS 报告时出错
SQL> conn sys / as sysdba
SQL> grant plustrace to public;
SQL> conn ahern/oracle
SQL> set autotrace on; --成功
步骤2:在此处执行你的SQL即可,后续自然会有结果输出
优点:
1. 可以输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况)
2. 虽然必须要等语句执行完毕后才可以输出执行计划,但是可以有traceonly开关来控制返回结果不打屏输出。
缺陷:
1. 必须要等到语句真正执行完毕后,才可以出结果;
2. 无法看到表被访问了多少次。
-- 方式三 statistics_level=all;
步骤1:alter session set statistics_level=all;
步骤2:在此处执行你的SQL
步骤3:select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
优点:
1. 可以清晰的从STARTS得出表被访问多少。
2. 可以清晰的从E-ROWS和A-ROWS中得到预测的行数和真实的行数,从而可以准确判断Oracle评估是否准确。
3. 虽然没有专门的输出运行时的相关统计信息,但是执行计划中的 BUFFERS 就是真实的逻辑读的多少
缺陷:
1. 必须要等到语句真正执行完毕后,才可以出结果。
2. 无法控制记录输屏打出,不像 autotrace 有 traceonly 可以控制不将结果打屏输出。
3. 看不出递归调用的次数,看不出物理读的多少(不过逻辑读才是重点)
-- 方式四-通过 dbms_xplan.display_cursor 输入 sql_id 参数直接获取
步骤1:
select * from table(dbms_xplan.display_cursor('&sq_id')); -- 该方法是从共享池里得到)
select * from table(dbms_xplan.display_awr('&sq_id')); -- 这是awr性能视图里获取到的)
select * from table(dbms_xplan.display_awr(sql_id,null,null,'ALL')); -- 通过视图 dba_hist_sqlbind 找到语句对应的绑定变量
-- 如果有多个执行计划,可以用类似方法查出
select * from table(dbms_xplan.display_cursor('5320a2qq3m03x',0));
select * from table(dbms_xplan.display_cursor('cyzznbykb509s',1));
优点:
1. 知道sql_id立即可得到执行计划,和 explain plan for 一样无需执行;
2. 可以得到真实的执行计划。
缺陷:
1. 没有输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况);
2. 无法判断是处理了多少行;
3. 无法判断表被访问了多少次。
-- 方式五 -10046 trace 跟踪
alter session set statistics_level=typical;
步骤1:alter session set events '10046 trace name context forever,level 12'; -- 开启跟踪
步骤2:执行你的语句
步骤3:alter session set events '10046 trace name context off'; -- 关闭跟踪
步骤4:找到跟踪后产生的文件位置 -- 仅仅提供当前会话跟踪信息 v$diag_info
SELECT VALUE FROM V$DIAG_INFO WHERE NAME = 'Default Trace File'; -- 当前会话跟踪文件
步骤5:tkprof trc文件 目标文件 sys=no sort=prsela,exeela,fchela -- 格式化命令
优点:
1. 可以看出SQL语句对应的等待事件
2. 如果SQL语句中有函数调用,SQL中有SQL,将会都被列出,无处遁形。
3. 可以方便的看出处理的行数,产生的物理逻辑读。
4. 可以方便的看出解析时间和执行时间。
5. 可以跟踪整个程序包
缺陷:
1. 步骤繁琐,比较麻烦
2. 无法判断表被访问了多少次。
3. 执行计划中的谓词部分不能清晰的展现出来。
-- 方式六 awrsqrpt.sql (@$ORACLE_HOME/rdbms/admin/awrsqrpt.sql)
步骤1:@?/rdbms/admin/awrsqrpt.sql
步骤2:选择你要的断点(begin snap 和end snap)
步骤3:输入你的sql_id
-- 总结:
生成完整的执行信息,还包括数据在运行期间的各种信息。实在找不到优化的点,可以打开这个awr报表进行查看。
-- 6种方式适用场景的总结
1. 如果某SQL执行非常长时间才会出结果,甚至慢到返回不了结果,这时候看执行计划就只能用方法1;(explain plan for "SQL")
2. 跟踪某条SQL最简单的方法是方法1,其次就是方法2;(set autotace on ...)
3. 如果想观察到某条SQL有多条执行计划的情况,只能用方法4(dbms_xplan.display_cursor)和方法6(awrsqrpt.sql)
4. 如果SQL中含有多函数,函数中套有SQL等多层递归调用,想准确分析,只能使用方法5;(10046 trace)
5. 注意:要想确保看到真实的执行计划,不能用方法1和方法2;
6. 要想获取表被访问的次数,只能使用方法3;dbms_xplan.display_cursor (statistics_level=all)
--------------------------------------------------------------------------------
查看SQL语句所属用户
--------------------------------------------------------------------------------
-- 查看SQL属于哪个用户
SELECT A.SQL_TEXT, B.USERNAME
FROM V$SQL A, V$SESSION B
WHERE A.HASH_VALUE = B.SQL_HASH_VALUE AND A.SQL_ID='96677tuqfbs6d';
-- 获取指定SQL在内存中的执行计划:
SELECT SQL_ID, CHILD_NUMBER, SQL_TEXT
FROM V$SQL
WHERE SQL_TEXT LIKE 'select count(1) from emp a where a.dept_no =%';
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR('sql_id', 0));
-- 查询SQL所有执行计划
SELECT * FROM TABLE(SYS.DBMS_XPLAN.DISPLAY_CURSOR('aca4xvmz0rzup',null))
SELECT * FROM TABLE(SYS.DBMS_XPLAN.DISPLAY_CURSOR('9x4fggs2mzu0m',0))
-- 查看数据库里面有多个执行计划的SQL语句的SQL_ID
SELECT SQL_ID, COUNT(1) AS PLAN_NUM
FROM V$SQL
GROUP BY SQL_ID
HAVING COUNT(1) >=2
ORDER BY 2 DESC;
-- 可以通过下面SQL语句查询对应SQL的所有执行计划或部分执行计划,分析出现多个执行计划的原因
-- 查询SQL所有执行计划
SELECT * FROM TABLE(SYS.DBMS_XPLAN.DISPLAY_CURSOR('9x4fggs2mzu0m',null))
-- 查询SQL的CHILD NUMBER为0的执行计划
SELECT * FROM TABLE(SYS.DBMS_XPLAN.DISPLAY_CURSOR('9x4fggs2mzu0m',0))
-- 查询SQL的CHILD NUMBER为1的执行计划
SELECT * FROM TABLE(SYS.DBMS_XPLAN.DISPLAY_CURSOR('9x4fggs2mzu0m',1))
-- 查看用户 AHERN 最近执行的SQL语句
select /*recentsql*/
s.SQL_ID,
s.CHILD_NUMBER,
s.HASH_VALUE,
s.ADDRESS,
s.EXECUTIONS,
s.SQL_TEXT
from v$sql s
where s.PARSING_USER_ID =
(select u.user_id from all_users u where u.username = 'AHERN')
and s.COMMAND_TYPE in (2, 3, 6, 7, 189)
and upper(s.SQL_TEXT) not like upper('%recentsql%')
-- 注意:
若 dbms_xplan.display_cursor 要以 ALLSTATS LAST 格式输出的话,/*+gather_plan_statistics*/ 这个提示信息放到查询语句中是必须的。
select /*+gather_plan_statistics*/ /*plan_statistics1*/ name ,salary from test where name = 'hh';
select s.SQL_ID,s.CHILD_NUMBER,s.HASH_VALUE,s.ADDRESS,s.EXECUTIONS,s.SQL_TEXT
from v$sql s
where upper(s.SQL_TEXT) like upper('%plan_statistics1%' )
and upper(s.SQL_TEXT) not like upper( '%v$sql%');
select * from table (dbms_xplan.display_cursor('4wktu80k1xy5k' , 0, 'ALLSTATS LAST cost' ));
-- 获取表定义
select dbms_metadata.get_ddl('TABLE','EMPLOYEE_LIST_LIST_PART','AHERN') FROM dual;
select dbms_metadata.get_ddl('TABLE','TEST_PARTITION','AHERN') FROM dual;
--------------------------------------------------------------------------------
执行计划中各字段的描述以及执行计划中各模块的描述与举例
--------------------------------------------------------------------------------
1、基本字段(总是可用的)
Id 执行计划中每一个操作(行)的标识符。如果数字前面带有星号,意味着将在随后提供这行包含的谓词信息
Operation 对应执行的操作。也叫行源操作
Name 操作的对象名称
2、查询优化器评估信息
Rows(E-Rows) 预估操作返回的记录条数
Bytes(E-Bytes) 预估操作返回的记录字节数
TempSpc 预估操作使用临时表空间的大小
Cost(%CPU) 预估操作所需的开销。在括号中列出了CPU开销的百分比。注意这些值是通过执行计划计算出来的。换句话说,父操作的开销包含子操作的开销
Time 预估执行操作所需要的时间(HH:MM:SS)
3、分区(仅当访问分区表时下列字段可见)
Pstart 访问的第一个分区。如果解析时不知道是哪个分区就设为KEY,KEY(I),KEY(MC),KEY(OR),KEY(SQ)
Pstop 访问的最后一个分区。如果解析时不知道是哪个分区就设为KEY,KEY(I),KEY(MC),KEY(OR),KEY(SQ)
4、并行和分布式处理(仅当使用并行或分布式操作时下列字段可见)
Inst 在分布式操作中,指操作使用的数据库链接的名字
TQ 在并行操作中,用于从属线程间通信的表队列
IN-OUT 并行或分布式操作间的关系
PQ Distrib 在并行操作中,生产者为发送数据给消费者进行的分配
5、运行时统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)
Starts 指定SQL操作执行的次数
A-Rows 操作返回的真实记录数
A-Time 操作执行的真实时间(HH:MM:SS.FF)
6、I/O 统计(当设定参数statistics_level为all或使用gather_plan_statistics提示时,下列字段可见)
Buffers 执行期间进行的逻辑读操作数量 (为每一步实际执行的逻辑读或一致性读)
Reads 执行期间进行的物理读操作数量
Writes 执行期间进行的物理写操作数量
7、内存使用统计
OMem 最优执行所需内存的预估值
1Mem 一次通过(one-pass)执行所需内存的预估值
0/1/M 最优/一次通过/多次通过(multipass)模式操作执行的次数
Used-Mem 最后一次执行时操作使用的内存量
Used-Tmp 最后一次执行时操作使用的临时空间大小。这个字段必须扩大1024倍才能和其他衡量内存的字段一致(比如,32k意味着32MB)
Max-Tmp 操作使用的最大临时空间大小。这个字段必须扩大1024倍才能和其他衡量内存的字段一致(比如,32k意味着32MB)
----------------------------------------
OMem 当前操作完成所有内存工作区(Work Aera)操作所总共使用私有内存(PGA)中工作区的大小,
这个数据是由优化器统计数据以及前一次执行的性能数据估算得出的
1Mem 当工作区大小无法满足操作所需的大小时,需要将部分数据写入临时磁盘空间中(如果仅需要写入一次就可以完成操作,
就称一次通过,One-Pass;否则为多次通过,Multi_Pass).该列数据为语句最后一次执行中,单次写磁盘所需要的内存大小,
这个由优化器统计数据以及前一次执行的性能数据估算得出的
User-Mem 语句最后一次执行中,当前操作所使用的内存工作区大小,括号里面为(发生磁盘交换的次数,1次即为One-Pass,
----------------------------------------
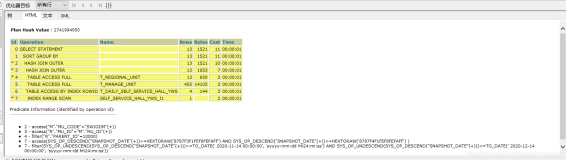
-- 执行计划中各模块的描述与举例
1、预估的执行计划中的各字段与模块
SQL> explain plan for
2 select * from emp e,dept d
3 where e.deptno=d.deptno
4 and e.ename='SMITH';
Explained.
SQL> set linesize 180
SQL> set pagesize 0
SQL> select * from table(dbms_xplan.display(null,null,'advanced')); --使用dbms_xplan.display函数获得语句的执行计划
Plan hash value: 351108634 --SQL语句的哈希植
---------------------------------------------------------------------------------------- /*执行计划部分*/
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 117 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 117 | 4 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL | EMP | 1 | 87 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 30 | 1 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id): --这部分显示的为查询块名和对象别名
-------------------------------------------------------------
1 - SEL$1 --SEL$为select 的缩写,位于块1,相应的还有DEL$,INS$,UPD$等
2 - SEL$1 / E@SEL$1 --E@SEL$1,对应到执行计划中的操作ID为2上,即在表E上的查询,E为别名,下面类同
3 - SEL$1 / D@SEL$1
4 - SEL$1 / D@SEL$1
Outline Data --提纲部分,这部分将执行计划中的图形化方式以文本形式来呈现,即转换为提示符方式
-------------
/*+
BEGIN_OUTLINE_DATA
USE_NL(@"SEL$1" "D"@"SEL$1") --使用USE_NL提示,即嵌套循环
LEADING(@"SEL$1" "E"@"SEL$1" "D"@"SEL$1") --指明前导表
INDEX_RS_ASC(@"SEL$1" "D"@"SEL$1" ("DEPT"."DEPTNO")) --指明对于D上的访问方式为使用索引
FULL(@"SEL$1" "E"@"SEL$1") --指明对于E上的访问方式为全表扫描
OUTLINE_LEAF(@"SEL$1")
ALL_ROWS
OPTIMIZER_FEATURES_ENABLE('10.2.0.3')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
Predicate Information (identified by operation id): --谓词信息部分,在执行计划中ID带有星号的每一行均对应到下面中的一行
---------------------------------------------------
2 - filter("E"."ENAME"='SMITH')
4 - access("E"."DEPTNO"="D"."DEPTNO")
Column Projection Information (identified by operation id): --执行时每一步骤所返回的列,下面的不同步骤返回了不同的列
-----------------------------------------------------------
1 - (#keys=0) "E"."EMPNO"[NUMBER,22], "E"."ENAME"[VARCHAR2,10],
"E"."JOB"[VARCHAR2,9], "E"."MGR"[NUMBER,22], "E"."HIREDATE"[DATE,7],
"E"."SAL"[NUMBER,22], "E"."COMM"[NUMBER,22], "E"."DEPTNO"[NUMBER,22],
"D"."DEPTNO"[NUMBER,22], "D"."DNAME"[VARCHAR2,14], "D"."LOC"[VARCHAR2,13]
2 - "E"."EMPNO"[NUMBER,22], "E"."ENAME"[VARCHAR2,10], "E"."JOB"[VARCHAR2,9],
"E"."MGR"[NUMBER,22], "E"."HIREDATE"[DATE,7], "E"."SAL"[NUMBER,22],
"E"."COMM"[NUMBER,22], "E"."DEPTNO"[NUMBER,22]
3 - "D"."DEPTNO"[NUMBER,22], "D"."DNAME"[VARCHAR2,14], "D"."LOC"[VARCHAR2,13]
4 - "D".ROWID[ROWID,10], "D"."DEPTNO"[NUMBER,22]
Note --注释与描述部分,下面的描述中给出了本次SQL语句使用了动态采样功能
-----
- dynamic sampling used for this statement
58 rows selected.
2、实际执行计划中的各字段与模块
SQL> select /*+ gather_plan_statistics */ * --注意此处增加了提示gather_plan_statistics并且该语句被执行
2 from emp e,dept d
3 where e.deptno=d.deptno
4 and e.ename='SMITH';
7369 SMITH CLERK 7902 17-DEC-80 800 20 20 RESEARCH DALLAS
SQL> select * from table(dbms_xplan.display_cursor(null,null,'iostats last')); --使用display_cursor获取实际的执行计划
SQL_ID fpx7zw59f405d, child number 0 --这部分给出了SQL语句的SQL_ID,子游标号以及原始的SQL语句
-------------------------------------
select /*+ gather_plan_statistics */ * from emp e,dept d where e.deptno=d.deptno and
e.ename='SMITH'
Plan hash value: 351108634 --SQL 语句的哈希值
--SQL 语句的执行计划,可以看到下面显示的字段一部分不同于预估执行计划中的字段
----------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
----------------------------------------------------------------------------------
| 1 | NESTED LOOPS | | 1 | 1 | 1 |00:00:00.01 | 10 | 1 |
|* 2 | TABLE ACCESS FULL | EMP | 1 | 1 | 1 |00:00:00.01 | 8 | 0 |
| 3 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 1 | 1 |00:00:00.01 | 2 | 1 |
|* 4 | INDEX UNIQUE SCAN | PK_DEPT | 1 | 1 | 1 |00:00:00.01 | 1 | 1 |
----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("E"."ENAME"='SMITH')
4 - access("E"."DEPTNO"="D"."DEPTNO")
Note
-----
- dynamic sampling used for this statement
26 rows selected.
-- 总结
-- 由上可知在不同的情形下可以获得执行计划的不同信息,而不同信息则展现了SQL语句对应的不同情况,因此应根据具体的情形具体分析。
--------------------------------------------------------------------------------
执行计划各种扫描释义
--------------------------------------------------------------------------------
SORT GROUP BY
TABLE ACCESS FULL
-- Oracle会读取表中所有的行,并检查每一行是否满足SQL语句中的 Where 限制条件;
-- 全表扫描时可以使用多块读(即一次I/O读取多块数据块)操作,提升吞吐量;
-- 使用建议:数据量太大的表不建议使用全表扫描,除非本身需要取出的数据较多,占到表数据总量的 5% ~ 10% 或以上
TABLE ACCESS BY ROWID
-- ROWID是由Oracle自动加在表中每行最后的一列伪列,既然是伪列,就说明表中并不会物理存储ROWID的值;
-- 你可以像使用其它列一样使用它,只是不能对该列的值进行增、删、改操作;
-- 一旦一行数据插入后,则其对应的ROWID在该行的生命周期内是唯一的,即使发生行迁移,该行的ROWID值也不变。
-- 让我们再回到 TABLE ACCESS BY ROWID 来:
-- 行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID可以快速定位到目标数据上,这也是Oracle中存取单行数据最快的方法;
TABLE ACCESS BY INDEX SCAN
-- 在索引块中,既存储每个索引的键值,也存储具有该键值的行的ROWID。
-- 索引扫描其实分为两步:
-- Ⅰ:扫描索引得到对应的ROWID
-- Ⅱ:通过ROWID定位到具体的行读取数据
-- 索引扫描又分五种:
1、INDEX UNIQUE SCAN
-- 针对唯一性索引(UNIQUE INDEX)的扫描,每次至多只返回一条记录;
-- 表中某字段存在 UNIQUE、PRIMARY KEY 约束时,Oracle常实现唯一性扫描;
2、INDEX RANGE SCAN
-- 使用一个索引存取多行数据;
-- 发生索引范围扫描的三种情况:
-- 在唯一索引列上使用了范围操作符(如:> < <> >= <= between)
-- 在组合索引上,只使用部分列进行查询(查询时必须包含前导列,否则会走全表扫描)
-- 对非唯一索引列上进行的任何查询
3、INDEX FULL SCAN
-- 进行全索引扫描时,查询出的数据都必须从索引中可以直接得到(注意全索引扫描只有在CBO模式下才有效)
--------------------------------------------------------------------------------
-----------------------------------------------------------
-- Oracle优化器简述
-- Oracle中的优化器是SQL分析和执行的优化工具,它负责生成、制定SQL的执行计划。
-- Oracle的优化器有两种:
-- RBO(Rule-Based Optimization) 基于规则的优化器
-- CBO(Cost-Based Optimization) 基于代价的优化器
RBO:
-- RBO有严格的使用规则,只要按照这套规则去写SQL语句,无论数据表中的内容怎样,也不会影响到你的执行计划;
-- 换句话说,RBO对数据“不敏感”,它要求SQL编写人员必须要了解各项细则;RBO一直沿用至ORACLE 9i,从ORACLE 10g开始,RBO已经彻底被抛弃。
CBO:
CBO是一种比RBO更加合理、可靠的优化器,在ORACLE 10g中完全取代RBO;
CBO通过计算各种可能的执行计划的“代价”,即COST,从中选用COST最低的执行方案作为实际运行方案;
它依赖数据库对象的统计信息,统计信息的准确与否会影响CBO做出最优的选择,也就是对数据“敏感”。
-----------------------------------------------------------
4、INDEX FAST FULL SCAN
-- 扫描索引中的所有的数据块,与 INDEX FULL SCAN 类似,但是一个显著的区别是它不对查询出的数据进行排序(即数据不是以排序顺序被返回)
5、INDEX SKIP SCAN
-- Oracle 9i后提供,有时候复合索引的前导列(索引包含的第一列)没有在查询语句中出现,oralce也会使用该复合索引,这时候就使用的INDEX SKIP SCAN;
-- 什么时候会触发 INDEX SKIP SCAN 呢?
-- 前提条件:表有一个复合索引,且在查询时有除了前导列(索引中第一列)外的其他列作为条件,并且优化器模式为CBO时
-- 当Oracle发现前导列的唯一值个数很少时,会将每个唯一值都作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询
-- 例如:
-- 假设表emp有ename(雇员名称)、job(职位名)、sex(性别)三个字段,并且建立了如 create index idx_emp on emp (sex, ename, job) 的复合索引;
-- 因为性别只有 '男' 和 '女' 两个值,所以为了提高索引的利用率,Oracle可将这个复合索引拆成 ('男', ename, job),('女', ename, job) 这两个复合索引;
-- 当查询 select * from emp where job = 'Programmer' 时,该查询发出后:
-- Oracle先进入sex为'男'的入口,这时候使用到了 ('男', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
-- 再进入sex为'女'的入口,这时候使用到了 ('女', ename, job) 这条复合索引,查找 job = 'Programmer' 的条目;
-- 最后合并查询到的来自两个入口的结果集。
-- NESTED LOOPS … 描述的是表连接方式;
-- JOIN 关键字用于将两张表作连接,一次只能连接两张表,JOIN 操作的各步骤一般是串行的(在读取做连接的两张表的数据时可以并行读取);
-- 表(row source)之间的连接顺序对于查询效率有很大的影响,对首先存取的表(驱动表)先应用某些限制条件(Where过滤条件)以得到一个较小的row source,
-- 可以使得连接效率提高。
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
-- 驱动表(Driving Table)与匹配表(Probed Table)
驱动表(Driving Table):
-- 表连接时首先存取的表,又称外层表(Outer Table),这个概念用于 NESTED LOOPS(嵌套循环) 与 HASH JOIN(哈希连接)中;
-- 如果驱动表返回较多的行数据,则对所有的后续操作有负面影响,故一般选择小表(应用Where限制条件后返回较少行数的表)作为驱动表。
匹配表(Probed Table):
-- 又称为内层表(Inner Table),从驱动表获取一行具体数据后,会到该表中寻找符合连接条件的行。故该表一般为大表(应用Where限制条件后返回较多行数的表)。
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
-- 表连接的几种方式:
SORT MERGE JOIN (排序-合并连接)
NESTED LOOPS (嵌套循环)
HASH JOIN (哈希连接)
CARTESIAN PRODUCT (笛卡尔积)
-- 注:这里将首先存取的表称作 row source 1,将之后参与连接的表称作 row source 2;
1、SORT MERGE JOIN
-- 假设有查询:
select a.name, b.name from table_A a join table_B b on (a.id = b.id)
-- 内部连接过程:
-- a) 生成 row source 1 需要的数据,按照连接操作关联列(如示例中的a.id)对这些数据进行排序
-- b) 生成 row source 2 需要的数据,按照与 a) 中对应的连接操作关联列(b.id)对数据进行排序
-- c) 两边已排序的行放在一起执行合并操作(对两边的数据集进行扫描并判断是否连接)
-- 延伸:
-- 如果示例中的连接操作关联列 a.id,b.id 之前就已经被排过序了的话,连接速度便可大大提高,因为排序是很费时间和资源的操作,尤其对于有大量数据的表。
-- 故可以考虑在 a.id,b.id 上建立索引让其能预先排好序。不过遗憾的是,由于返回的结果集中包括所有字段,所以通常的执行计划中,即使连接列存在索引,
-- 也不会进入到执行计划中,除非进行一些特定列处理(如仅仅只查询有索引的列等)。
-- 排序-合并连接的表无驱动顺序,谁在前面都可以;
-- 排序-合并连接适用的连接条件有: < <= = > >= ,不适用的连接条件有: <> like
2、NESTED LOOPS
-- 内部连接过程:
-- a) 取出 row source 1 的 row 1(第一行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中
-- b) 取出 row source 1 的 row 2(第二行数据),遍历 row source 2 的所有行并检查是否有匹配的,取出匹配的行放入结果集中
-- c) ……
-- 若 row source 1 (即驱动表)中返回了 N 行数据,则 row source 2 也相应的会被全表遍历 N 次。
-- 因为 row source 1 的每一行都会去匹配 row source 2 的所有行,所以当 row source 1 返回的行数尽可能少并且能高效访问 row source 2(如建立适当的索引)时,效率较高。
-- 延伸:
-- 嵌套循环的表有驱动顺序,注意选择合适的驱动表。
-- 嵌套循环连接有一个其他连接方式没有的好处是:可以先返回已经连接的行,而不必等所有的连接操作处理完才返回数据,这样可以实现快速响应。
-- 应尽可能使用限制条件(Where过滤条件)使驱动表(row source 1)返回的行数尽可能少,同时在匹配表(row source 2)的连接操作关联列上建立唯一索引(UNIQUE INDEX)
-- 或是选择性较好的非唯一索引,此时嵌套循环连接的执行效率会变得很高。若驱动表返回的行数较多,即使匹配表连接操作关联列上存在索引,连接效率也不会很高。
3、HASH JOIN(
-- 哈希连接只适用于等值连接(即连接条件为 = )
-- HASH JOIN对两个表做连接时并不一定是都进行全表扫描,其并不限制表访问方式;
-- 内部连接过程简述:
-- a) 取出 row source 1(驱动表,在HASH JOIN中又称为Build Table) 的数据集,然后将其构建成内存中的一个 Hash Table(Hash函数的Hash KEY就是连接操作关联列),创建Hash位图(bitmap)
-- b) 取出 row source 2(匹配表)的数据集,对其中的每一条数据的连接操作关联列使用相同的Hash函数并找到对应的 a) 里的数据在 Hash Table 中的位置,在该位置上检查能否找到匹配的数据
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
-- Hash Table相关
-- 散列(hash)技术:
-- 在记录的存储位置和记录具有的关键字key之间建立一个对应关系 f ,使得输入key后,可以得到对应的存储位置 f(key),这个对应关系 f 就是散列(哈希)函数;
-- 采用散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间就是散列表(哈希表);
-- 不同的key经同一散列函数散列后得到的散列值理论上应该不同,但是实际中有可能相同,相同时即是发生了散列(哈希)冲突,解决散列冲突的办法有很多,
-- 比如HashMap中就是用链地址法来解决哈希冲突;
-- 哈希表是一种面向查找的数据结构,在输入给定值后查找给定值对应的记录在表中的位置以获取特定记录这个过程的速度很快。
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
-- HASH JOIN的三种模式:
OPTIMAL HASH JOIN
ONEPASS HASH JOIN
MULTIPASS HASH JOIN
1、OPTIMAL HASH JOIN:
-- OPTIMAL 模式是从驱动表(也称Build Table)上获取的结果集比较小,可以把根据结果集构建的整个Hash Table都建立在用户可以使用的内存区域里。optimal_hash_join
-- 连接过程简述:
-- Ⅰ:首先对Build Table内各行数据的连接操作关联列使用Hash函数,把Build Table的结果集构建成内存中的Hash Table。如图所示,可以把Hash Table看作内存中的一块大的方形区域,
-- 里面有很多的小格子,Build Table里的数据就分散分布在这些小格子中,而这些小格子就是Hash Bucket。
-- Ⅱ:开始读取匹配表(Probed Table)的数据,对其中每行数据的连接操作关联列都使用同上的Hash函数,定位Build Table里使用Hash函数后具有相同值数据所在的Hash Bucket。
-- Ⅲ:定位到具体的Hash Bucket后,先检查Bucket里是否有数据,没有的话就马上丢掉匹配表(Probed Table)的这一行。
-- 如果里面有数据,则继续检查里面的数据(驱动表的数据)是否和匹配表的数据相匹配。
2、ONEPASS HASH JOIN :
-- 从驱动表(也称Build Table)上获取的结果集较大,无法将根据结果集构建的Hash Table全部放入内存中时,会使用 ONEPASS 模式。one_pass_hash_join
-- 连接过程简述:
-- Ⅰ:对Build Table内各行数据的连接操作关联列使用Hash函数,根据Build Table的结果集构建Hash Table后,由于内存无法放下所有的Hash Table内容,
-- 将导致有的Hash Bucket放在内存里,有的Hash Bucket放在磁盘上,无论放在内存里还是磁盘里,Oracle都使用一个Bitmap结构来反映这些Hash Bucket的状态(包括其位置和是否有数据)。
-- Ⅱ:读取匹配表数据并对每行的连接操作关联列使用同上的Hash函数,定位Bitmap上Build Table里使用Hash函数后具有相同值数据所在的Bucket。
-- 如果该Bucket为空,则丢弃匹配表的这条数据。如果不为空,则需要看该Bucket是在内存里还是在磁盘上。
-- 如果在内存中,就直接访问这个Bucket并检查其中的数据是否匹配,有匹配的话就返回这条查询结果。
-- 如果在磁盘上,就先把这条待匹配数据放到一边,将其先暂存在内存里,等以后积累了一定量的这样的待匹配数据后,再批量的把这些数据写入到磁盘上。
-- Ⅲ:当把匹配表完整的扫描了一遍后,可能已经返回了一部分匹配的数据了。接下来还有Hash Table中一部分在磁盘上的Hash Bucket数据以及匹配表中部分被写入到磁盘上
-- 的待匹配数据未处理,现在Oracle会把磁盘上的这两部分数据重新匹配一次,然后返回最终的查询结果。
3、MULTIPASS HASH JOIN:
-- 当内存特别小或者相对而言Hash Table的数据特别大时,会使用 MULTIPASS 模式。MULTIPASS会多次读取磁盘数据,应尽量避免使用该模式。
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
-- … OUTER 描述的是表连接类型;
-- 表连接的两种类型:
INNER JOIN (内连接)
OUTER JOIN (外连接)
-- 示例数据说明:
-- 现有A、B两表,A表信息如下:
table_A
id name
---------------------
1 小明
2 小李
3 小红
4 小刘
-- B表信息如下:
table_B
id name
---------------------
2 小新
3 小美
5 小琳
6 小丽
-- 下面的例子都用A、B两表来演示。
1、INNER JOIN
-- 只返回两表中相匹配的记录。
-- INNER JOIN 又分为两种:
-- 等值连接(连接条件为 = )
-- 非等值连接(连接条件为 非 = ,如 > >= < <= 等)
-- 等值连接用的最多,下面以等值连接举例:
-- 内连接的两种写法:连接时只返回满足连接条件(a.id = b.id)的记录
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a inner join B b on (a.id = b.id)
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a join B b on (a.id = b.id)
2、OUTER JOIN
-- OUTER JOIN 分为三种:
LEFT OUTER JOIN (可简写为 LEFT JOIN,左外连接)
RIGHT OUTER JOIN( RIGHT JOIN,右外连接)
FULL OUTER JOIN ( FULL JOIN,全外连接)
-- a) LEFT JOIN
-- 返回的结果不仅包含符合连接条件的记录,还包含左边表中的全部记录。(若返回的左表中某行记录在右表中没有匹配项,则右表中的返回列均为空值)
-- 两种写法:
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a left outer join B b on (a.id = b.id)
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a left join B b on (a.id = b.id)
-- b) RIGHT JOIN(右连接):
-- 返回的结果不仅包含符合连接条件的记录,还包含右边表中的全部记录。(若返回的右表中某行记录在左表中没有匹配项,则左表中的返回列均为空值)
-- 两种写法:
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a right outer join B b on (a.id = b.id)
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a right join B b on (a.id = b.id)
-- c) FULL JOIN(全连接):
-- 返回左右两表的全部记录。(左右两边不匹配的项都以空值代替)
-- 两种写法:
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a full outer join B b on (a.id = b.id)
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a full join B b on (a.id = b.id)
--------------------------------------------------------------------------------
-- (+) 操作符
-- (+) 操作符是Oracle特有的表示法,用来表示外连接(只能表示 左外、右外 连接),需要配合Where语句使用。
-- 特别注意:(+) 操作符在左表的连接条件上表示右连接,在右表的连接条件上表示左连接。如:
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a, B b where a.id = b.id(+)
-- 实际与左连接 select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a left join B b on (a.id = b.id) 效果等价
select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a, B b where a.id(+) = b.id
-- 实际与右连接 select a.id A_ID, a.name A_NAME, b.id B_ID, b.name B_NAME from A a right join B b on (a.id = b.id) 效果等价
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
-- 总结 各连接方法试用的场景:
-- 排序-合并连接
对于非等值连接,这种方式效率比较高
如果在关联列上有索引,效果更好
对于将两个比较大的row source做连接,该连接方法比NL要好
如果sort merge返回的row source过大,则又会使用过多的rowid在表中查询数据时,数据库性能下降,因为过多的I/O
-- 嵌套循环
如果外部表比较小,并且在内部表上有唯一索引,或者高选择性索引
该方法有其它连接方法没有的优点:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这样可以实现快速的响应时间
-- 哈希连接
一般来说,其效率好于其它两种连接,但这种连接只能用在CBO优化中,而且需要设置合适的hash_area_size参数
只用于等值连接
--------------------------------------------------------------------------------