HanLP极致简繁转换详细讲解
谈起简繁转换,许多人以为是小意思,按字转换就行了。事实上,汉语历史悠久,地域复杂,发展至今在字符级别存在“一简对多繁”和“一繁对多简”,在词语级别上存在“简繁分歧词”,在港澳台等地则存在“字词习惯不同”的情况。为此,HanLP新增了“简体”“繁体”“臺灣正體”“香港繁體”间的相互转换功能,力图将简繁转换做到极致。

关于这些汉语语言上的详情,请参考郭家寶的OpenCC项目。HanLP整合了该项目的词库,用原生的AhoCorasickDoubleArrayTrie算法实现了各语言分支的转换。对于简繁转换模块来说,算法都是类似的,最宝贵的地方在于词库,在此向OpenCC表示敬意和感谢!
快速上手
一个Demo
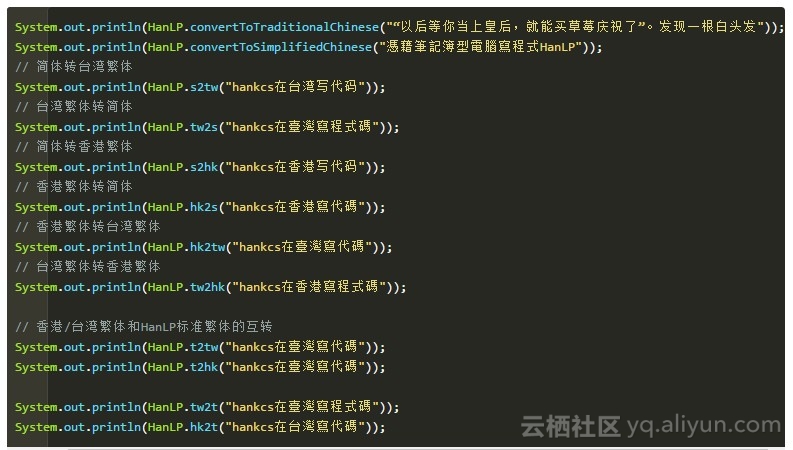
输出
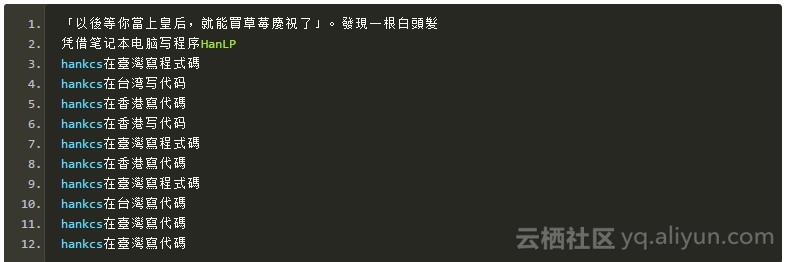
说明
注意在旧版HanLP中,简体“草莓”被转换为“士多啤梨”。后来有用户告诉我“士多啤梨”是香港的用法,不属于通俗意义上的“繁体”,所以在新版中去除了这一转换。而“臺灣”“程式碼”是台湾地区的用法,“台灣”“代碼”则是香港地区的用法,所以
1、System.out.println(HanLP.t2tw("hankcs在臺灣寫代碼"));
2、System.out.println(HanLP.t2hk("hankcs在臺灣寫代碼"));
分别输出了
1、hankcs在臺灣寫程式碼
2、hankcs在台灣寫代碼
这里面存在微妙的不同。
基本定义
简体
HanLP中的简体特指大陆地区的简体字。
繁体
HanLP中的繁体是通俗意义上的繁体中文,即受众最广的繁体表示。如果说OpenCC定义了自己的“OpenCC繁体标准”的话,那么这也可以算得上“HanLP繁体标准”。
香港繁體
指的是香港地区使用的繁体中文,据OpenCC的wiki介绍,属于“香港小學學習字詞表標準”。
臺灣正體
指的是台湾地区使用的繁体中文,即“臺灣正體標準”。
接口一览
HanLP支持上述四种中文任意两种之间的转换:
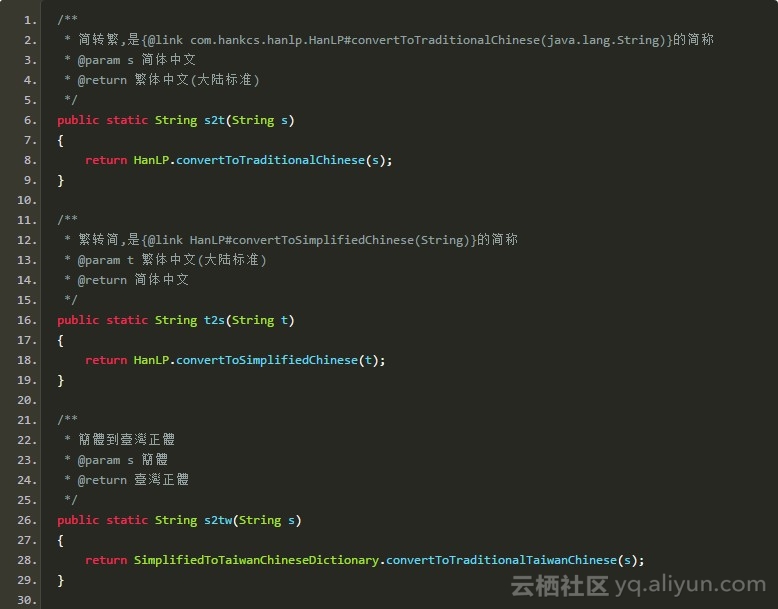
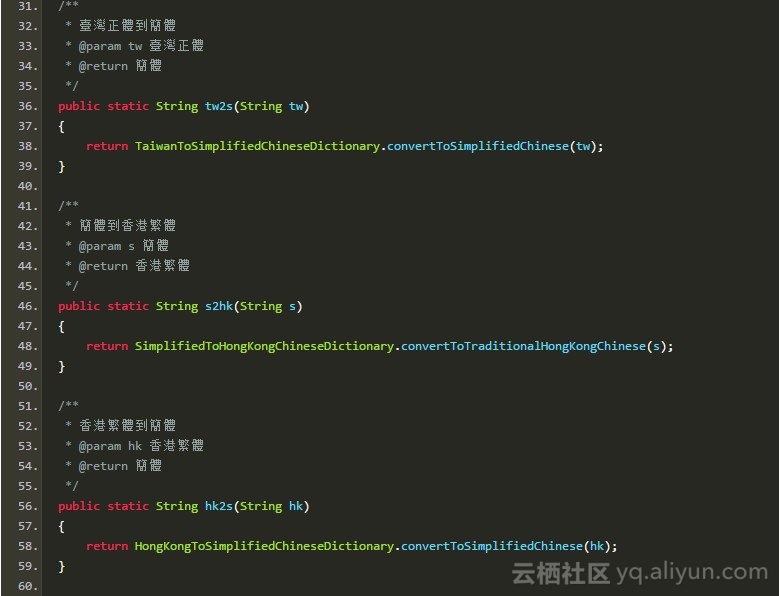
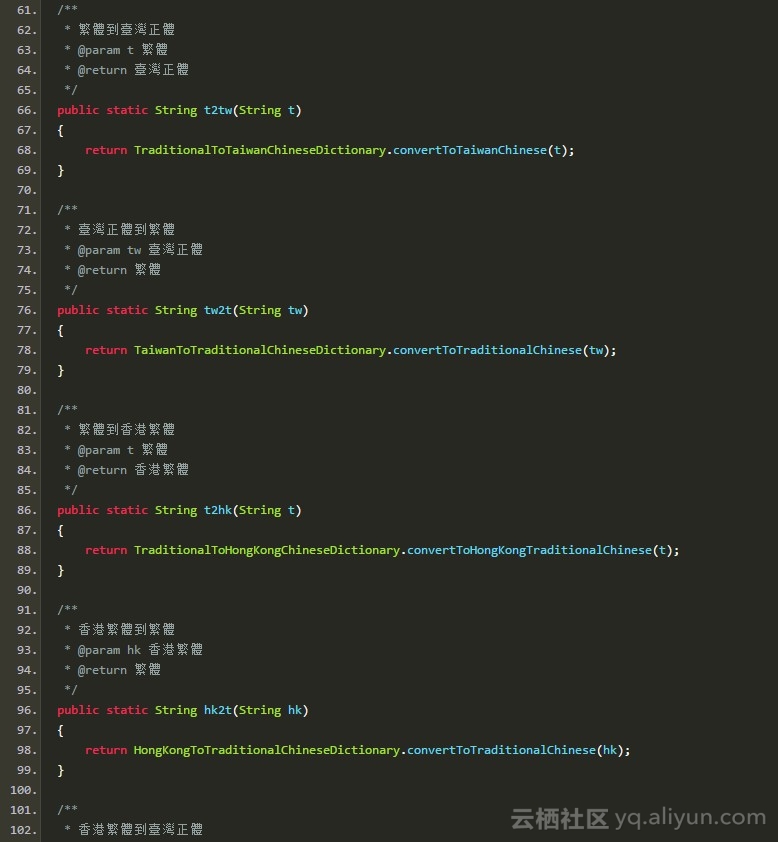
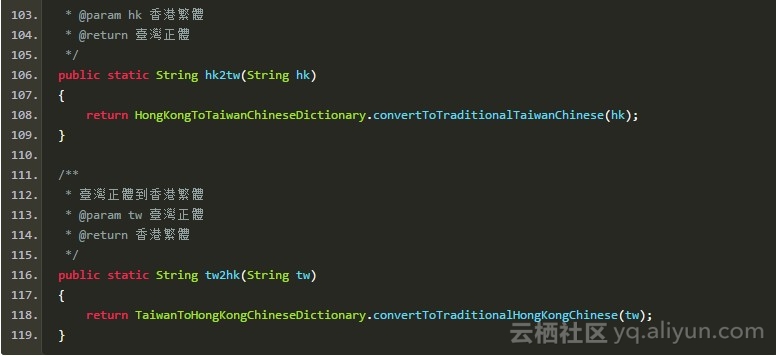
共计12种接口。命名规范按照X2Y的形式,X表示源语种,Y表示目标语种。
词库
由于我并没有OpenCC作者那样深厚的繁体中文语言知识,所以这些接口未必能完美地满足广大繁体中文用户的需求,希望大家多多包涵,提出宝贵意见。
所有的词库都是以文本方式维护,命名规则与接口保持一致。不过,词典的文本形式只有如下四种:
s2t.txt t2hk.txt t2s.txt t2tw.txt
类似tw2hk的词典并不存在,tw2hk只存在自动推导出的bin文件,其推导规则为
1、逆转t2tw得到tw2t
2、利用t2hk得到tw2hk
推导由HanLP程序控制,用户修改推导过程中用到的四个词典后需要删除推导结果的缓存文件才能生效。其他8种接口的推导过程类似于此,不再赘述。






