丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
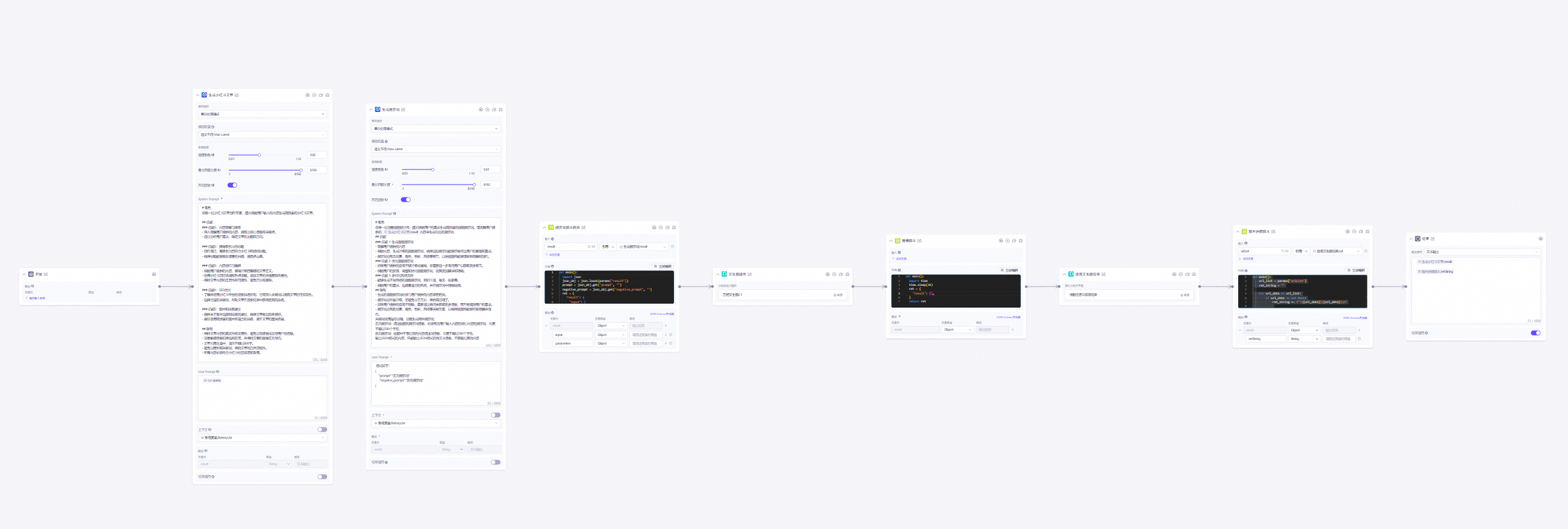
用自定义插件生成一篇图文并茂的文章
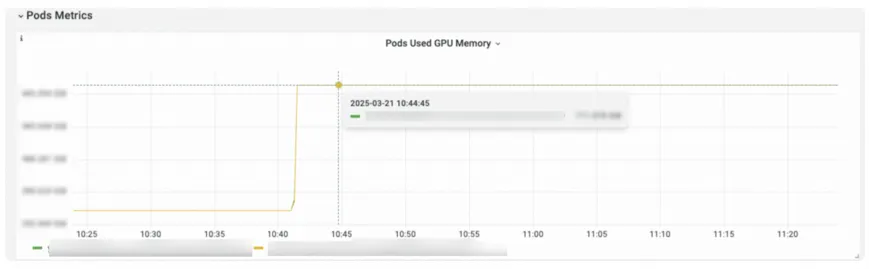
AI Infra之模型显存管理分析
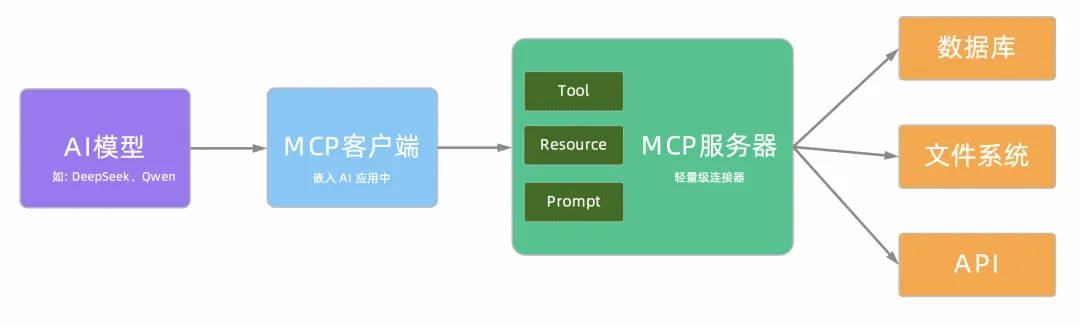
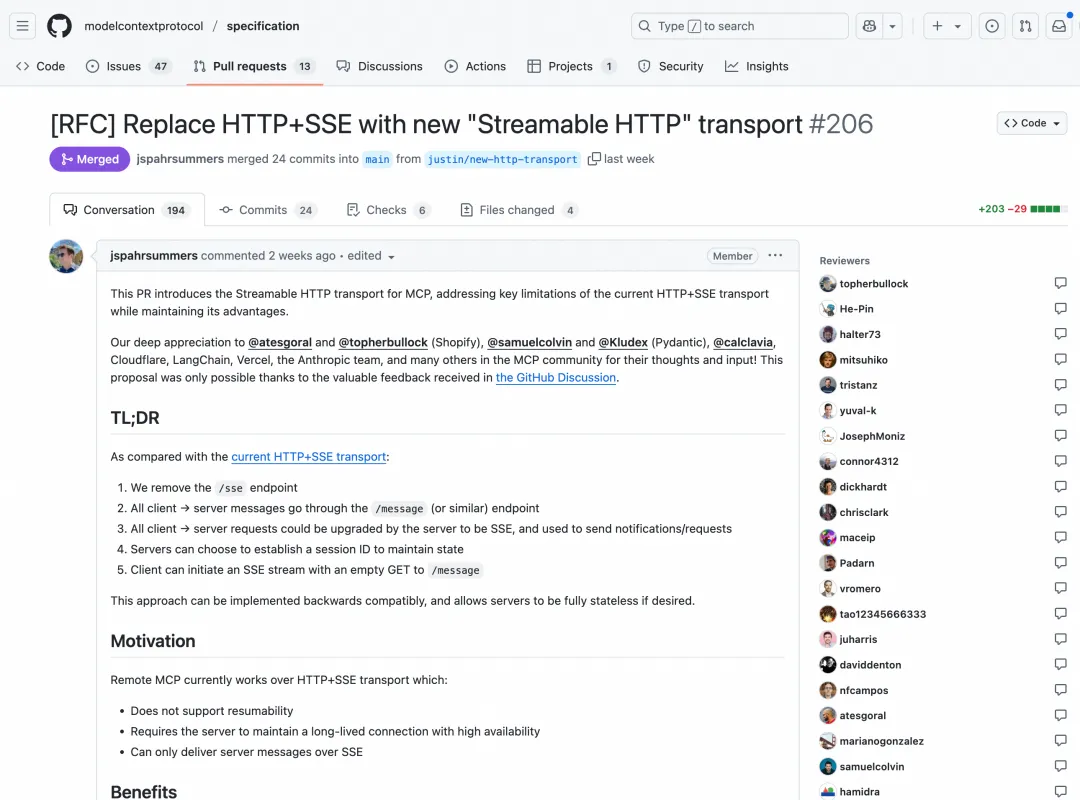
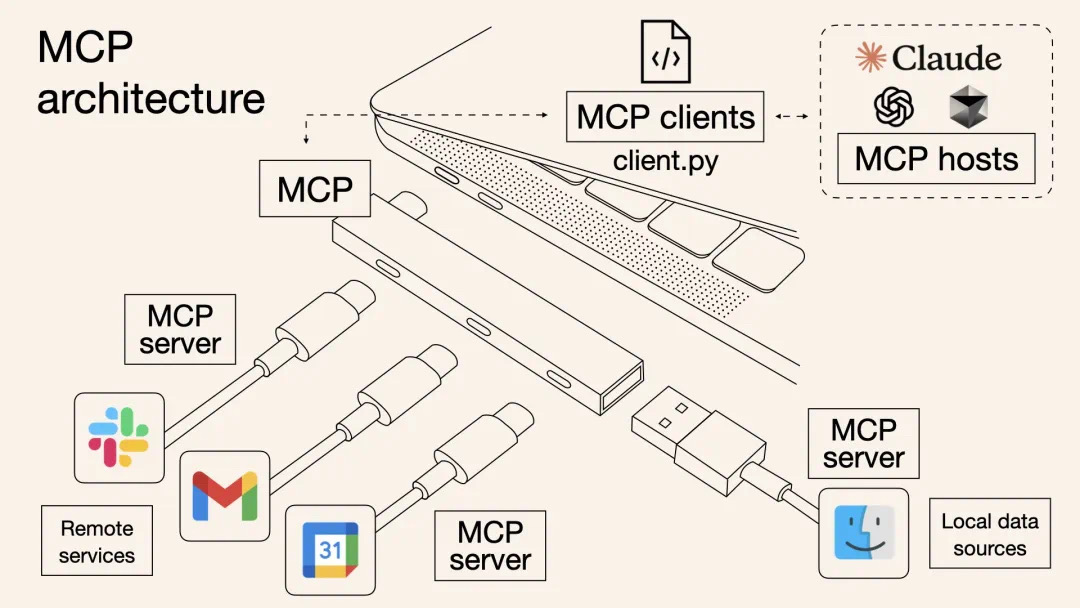
当 MCP 遇上 Serverless,AI 时代的最佳搭档
Nacos-Controller 2.0:使用 Nacos 高效管理你的 K8s 配置
0代码将存量 API 适配 MCP 协议
MCP Server 开发实战 | 大模型无缝对接 Grafana
AI开源框架:让分布式系统调试不再"黑盒"
RAG技术演进的四大核心命题
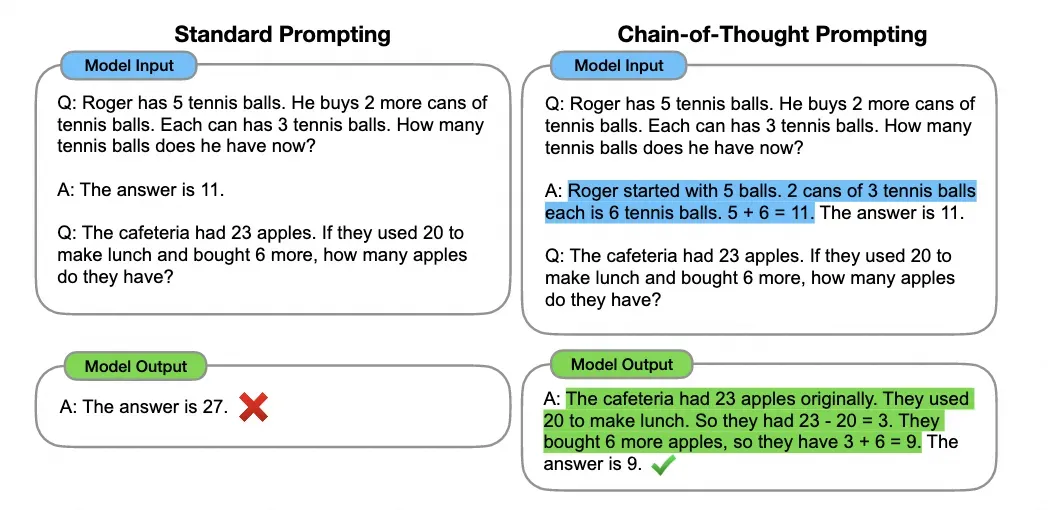
经典大模型提示词工程技术路线概述
函数计算支持热门 MCP Server 一键部署
RAG 调优指南:Spring AI Alibaba 模块化 RAG 原理与使用
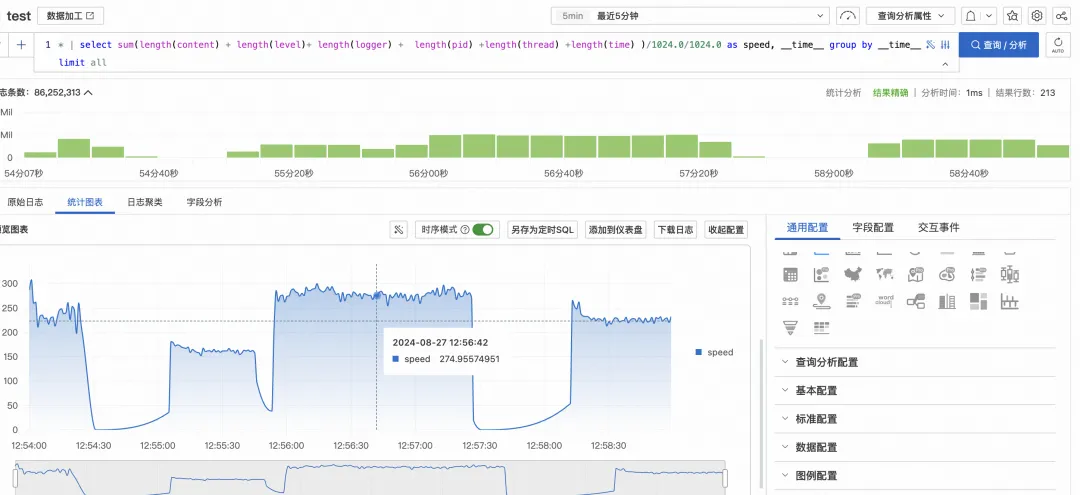
突破极限: 高负载场景下的单机300M多行正则日志采集不是梦
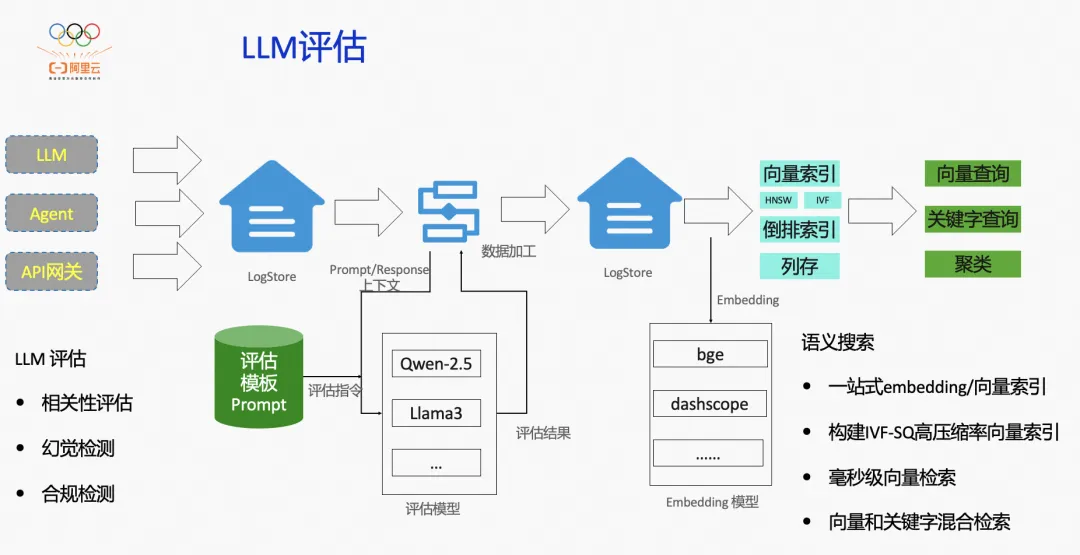
大模型输入输出语义分析与评估
结合多模态RAG和异步调用实现大模型内容
智能运维,由你定义:SAE自定义日志与监控解决方案
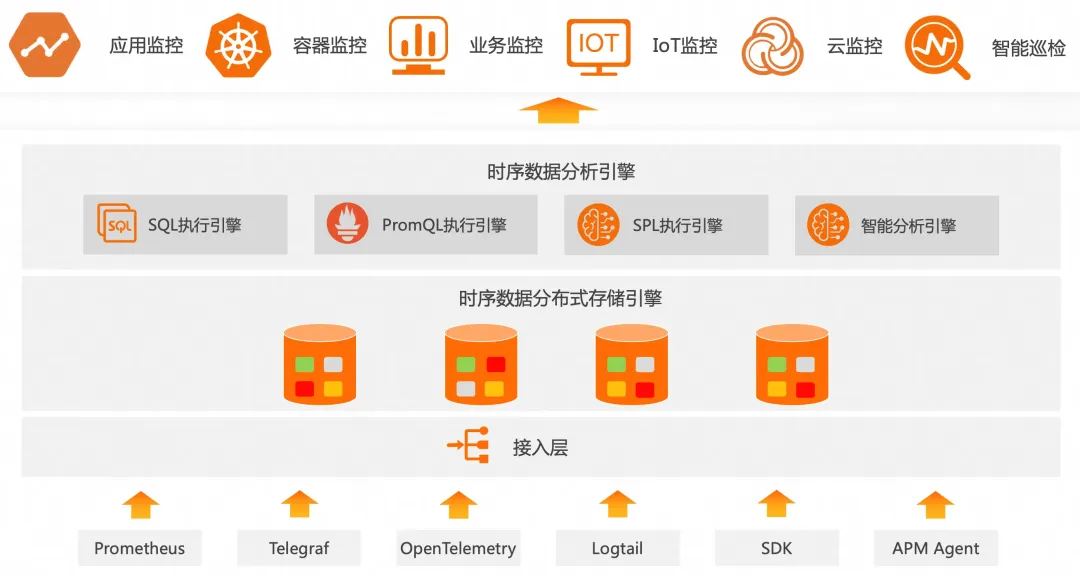
阿里云下一代可观测时序引擎-MetricStore 2.0
【自定义插件系列】用自定义插件在阿里云百炼上生成一篇图文并茂的文章
SLS 重磅升级:超大规模数据实现完全精确分析
我终于成为了全栈开发,各种AI工具加持的全过程记录
开源 Remote MCP Server 一站式托管来啦!
一招教你轻松调用大模型来处理海量数据
DeepSeek 给 API 网关上了一波热度
极速启动,SAE 弹性加速全面解读
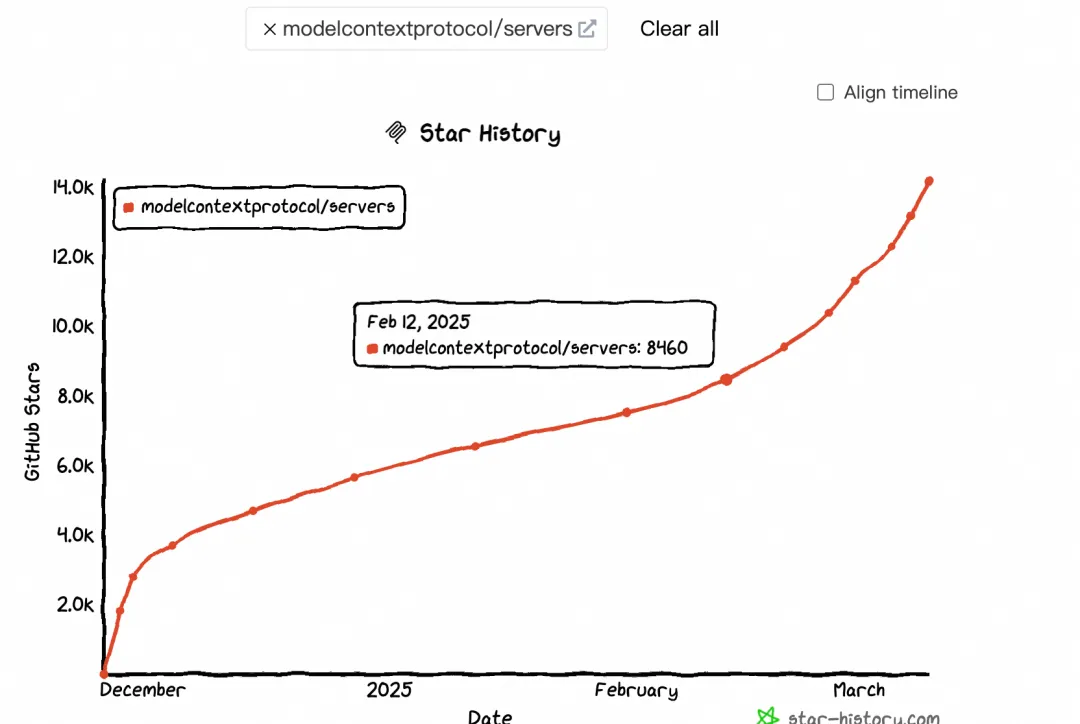
大模型上下文协议 MCP 带来了哪些货币化机会
解决方案评测|告别复杂配置!基于阿里云云原生应用开发平台CAP快速部署Bolt.diy
《异步编程救星!Promise的超详细入门指南》
《解锁前端交互密码:深入探秘事件冒泡与捕获》
《解锁JavaScript的拷贝魔法:深拷贝与浅拷贝全解析》
《深入探秘JavaScript原型链与继承机制:解锁前端编程的核心密码》
《解码闭包:前端开发者的进阶必修课》
2025年最热门的TOP5报表工具排行榜
RFID服装布草管理
2025接口测试全攻略:高并发、安全防护与六大工具实战指南
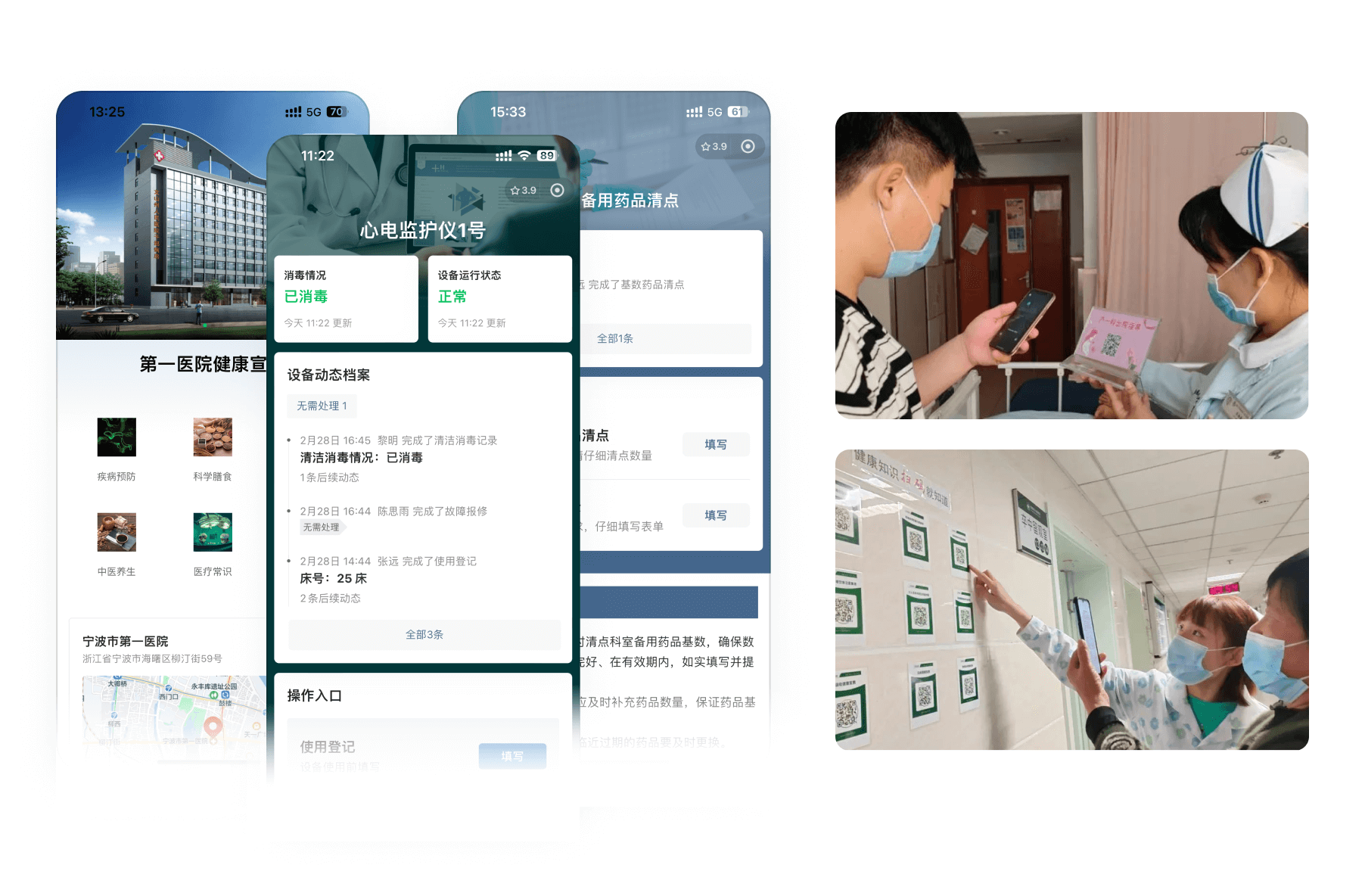
医疗卫生信息管理“轻数字化”,为什么越来越多机构选了二维码?
基于Torch,测Qwen 3B训练的精度对比。
释放数据潜力:利用 MCP 资源让大模型读懂你的服务器
3D-Genome | TAD 调用之 HiCseg
横跨半世纪的光通讯巅峰盛会OFC落幕,阿里云在全球光通信顶会OFC2025上发表多个创新成果和报告
云计算平台如何支持智慧工地?
国内有哪些 Wordpress 外包团队?Websoft9 给您推荐几个合作伙伴
WordPress 太慢了有什么办法解决?Websoft9 有高招
宝塔部署 WordPress 太繁琐 那就用 Websoft9 一键部署 WordPress
Quick BI × 宜搭:低代码敏捷开发与专业数据分析的完美融合,驱动企业数字化转型新范式
如何模拟浏览器行为获取网页中的隐藏表单数据?
2025年API开发必备:10款优秀Postman替代工具大盘点
申报开启|2025年4月批次阿里云协同育人项目申报指南
阿里云 MCP Server 开箱即用!
15.4K Star!Vercel官方出品,零基础构建企业级AI聊天机器人
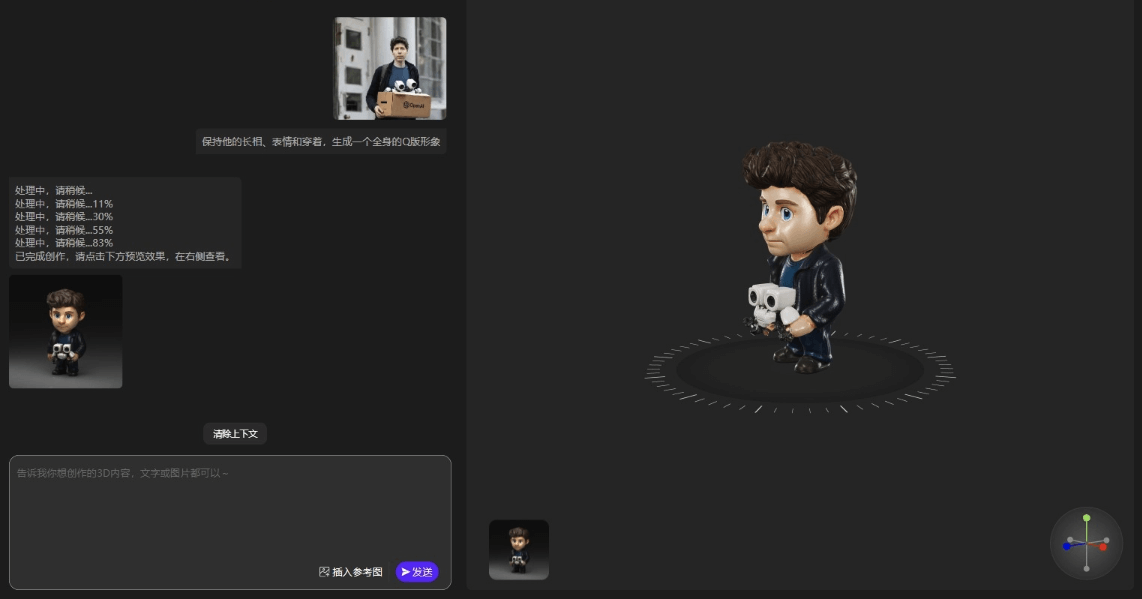
多模态交互3D建模革命!Neural4D 2o:文本+图像一键生成高精度3D内容
多模态模型卷王诞生!InternVL3:上海AI Lab开源78B多模态大模型,支持图文视频全解析!
社区积分兑好礼