时间序列是日常生活中最常见的数据类型之一。股票价格、销售信息、气候数据、能源使用,甚至个人身高体重都是可以用来定期收集的数据样本。几乎每个数据科学家在工作中都会遇到时间序列,能够有效地处理这些数据是数据科学领域之中的一项非常重要的技能。
本文简要介绍了如何从零开始使用Python中的时间序列。这包括对时间序列的简单定义,以及对利用pandas访问伦敦市居民智能电表所获取数据的处理。可以点击此处获取本文中所使用的数据。还提供了一些我认为有用的代码。
让我们从基础开始,时间序列的定义是这样的:
时间序列是按时间的顺序进行索引、排列或者绘制的数据点的集合。最常见的定义是,一个时间序列是在连续的相同间隔的时间点上取得的序列,因此它是一个离散时间数据的序列。
时间序列数据是围绕相对确定的时间戳而组织的。因此,与随机样本相比,可能包含我们将要尝试提取的一些相关信息。
加载和控制时间序列
数据集
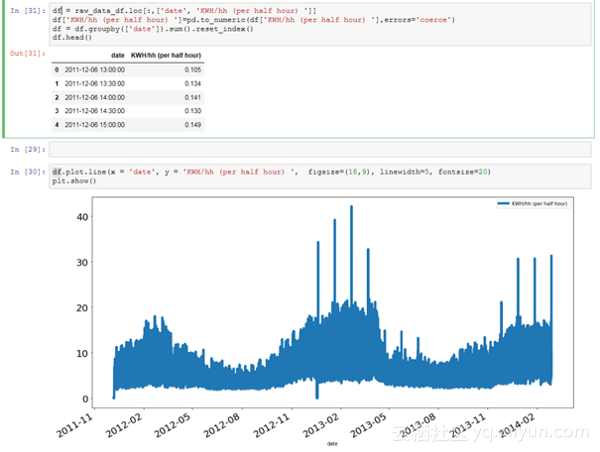
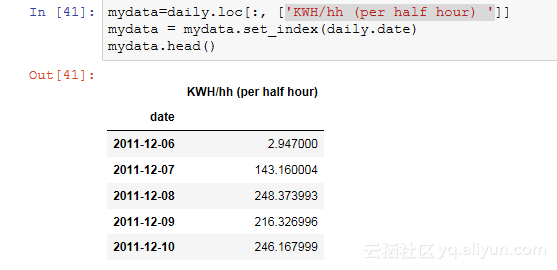
让我们使用一些关于能源消耗计费的数据作为例子,以kWh(每半小时)为单位, 在2011年11月至2014年2月期间,对参与英国电力网络领导的低碳伦敦项目的伦敦居民样本数据进行分析。我们可以从绘制一些图表开始,最好了解一下样本的结构和范围,这也将允许我们寻找最终需要纠正的缺失值。
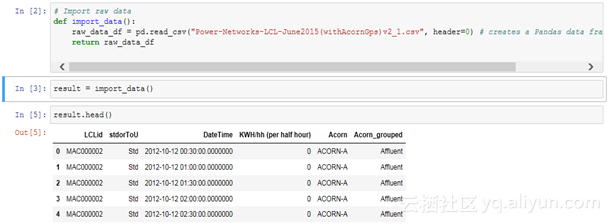
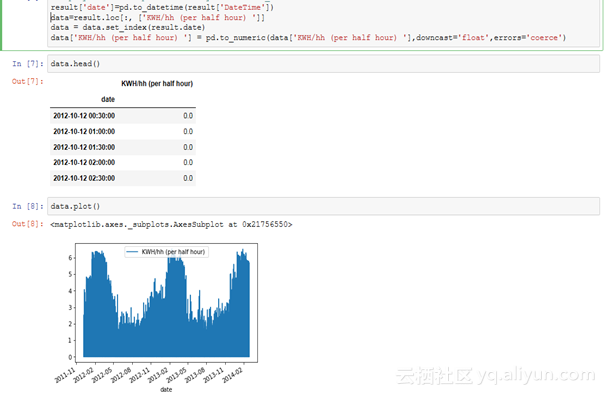
对于本文的其余部分,我们只关注DateTime和kWh两列。
重采样
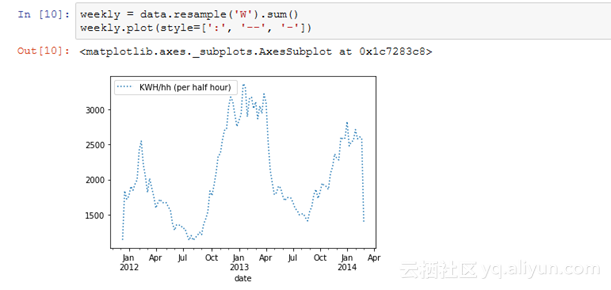
让我们从较简单的重采样技术开始。重采样涉及到更改时间序列观测的频率。特征工程可能是你对重新采样时间序列数据感兴趣的一个原因。实际上,它可以用来为监督学习模型提供额外的架构或者是对学习问题的领会角度。pandas中的重采样方法与GroupBy方法相似,因为你基本上是按照特定时间间隔进行分组的。然后指定一种方法来重新采样。让我们通过一些例子来把重采样技术描述的更具体些。我们从每周的总结开始:
·data.resample()方法将用于对DataFrame的kWh列数据重新取样;
·“W”表示我们要按每周重新取样;
·sum()方法用于表示在此时间段计算kWh列的总和;
我们可以对每日的数据也这么做处理,并且可以使用groupby和mean函数进行按小时处理:
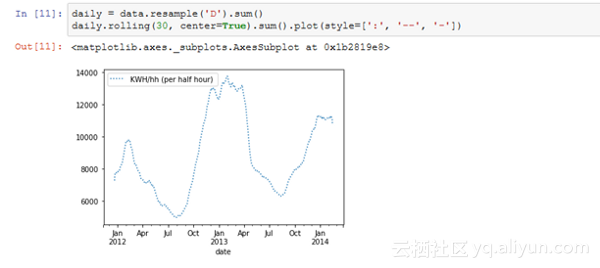
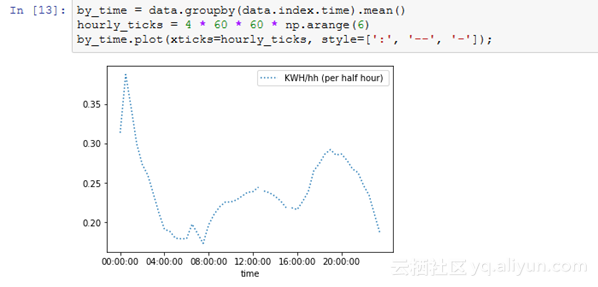
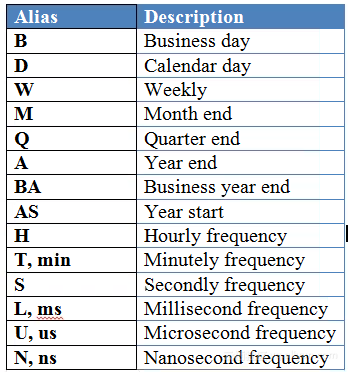
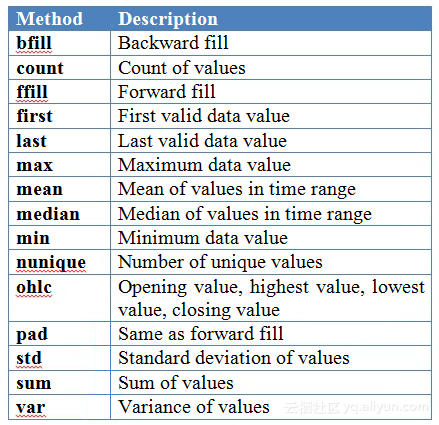
为了进一步进行重新采样,pandas有许多内置的选项,你甚至还可以定义自己的方法。下面两个表分别显示了时间周期选项及其缩写别名和一些可能用于重采样的常用方法。
其它探索
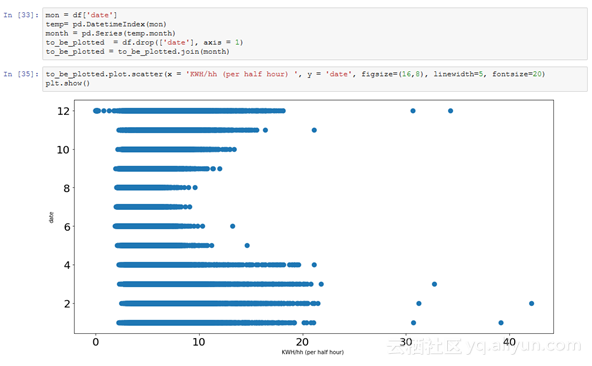
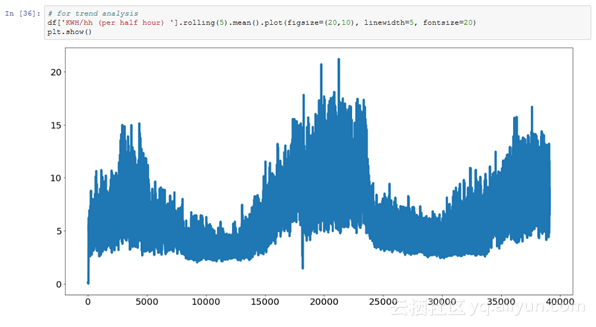
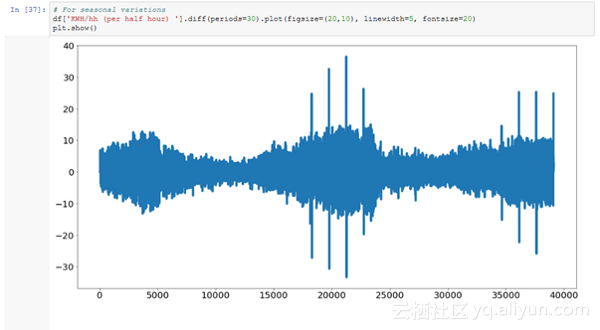
这里还有一些你可以用于处理数据而进行的其它探索:
用Prophet建模

Facebook Prophet于2017年发布的,可用于Python,而R.Prophet是设计用于分析在不同时间间隔上显示模式的日观测时间序列。Prophet对于数据丢失情况和趋势的变化具有很强的鲁棒性,并且通常能够很好地处理异常值。它还具有高级的功能,可以模拟假日在时间序列上产生的影响并执行自定义的变更点,但我将坚持使用基本规则来启动和运行模型。我认为Prophet可能是生产快速预测结果的一个好的选择,因为它有直观的参数,并且可以由有良好领域知识背景的但缺乏预测模型的技术技能的人来进行调整。有关Prophet的更多信息,大家可以点击这里查阅官方文档。
在使用Prophet之前,我们将数据里的列重新命名为正确的格式。Date列必须称为“ds”和要预测值的列为“y”。我们在下面的示例中使用了每日汇总的数据。

然后我们导入Prophet,创建一个模型并与数据相匹配。在Prophet中,changepoint_prior_scale参数用于控制趋势对变化的敏感度,越高的值会更敏感,越低的值则敏感度越低。在试验了一系列值之后,我将这个参数设置为0.10,而不是默认值0.05。

为了进行预测,我们需要创建一个称为未来数据框(future dataframe)的东西。我们需要指定要预测的未来时间段的数量(在我们的例子中是两个月)和预测频率(每天)。然后我们用之前创建的Prophet模型和未来数据框进行预测。

非常简单!未来数据框包含了未来两个月内的预估居民使用电量。我们可以用一个图表来进行可视化预测展示:
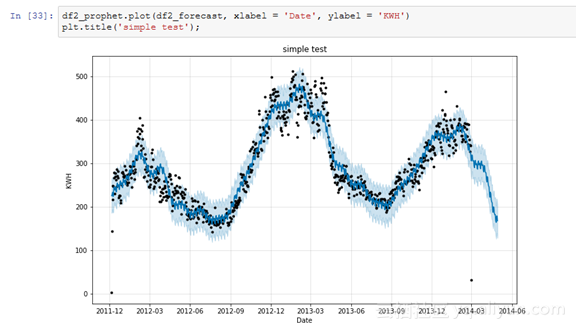
图中的黑点代表了实际值,蓝线则代表了预测值,而浅蓝色阴影区域代表不确定性。
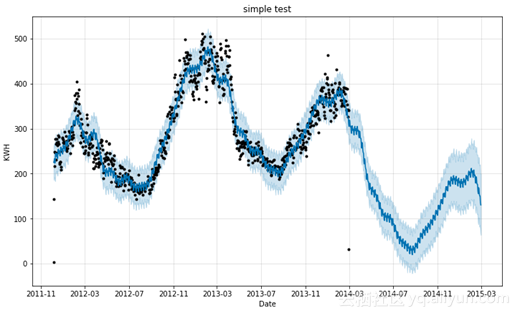
如下图所示,不确定性区域随着我们在之后的进一步变化而扩大,因为初始的不确定性随着时间的推移而扩散和增多。
Prophet还可以允许我们轻松地对整体趋势和组件模式进行可视化展示:
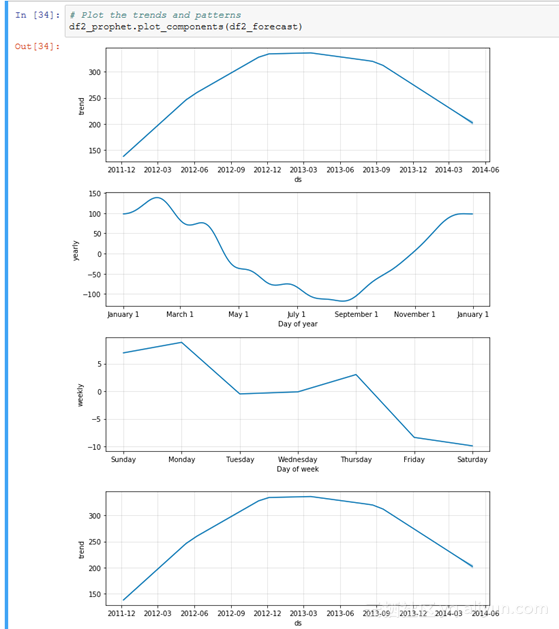
每年的模式很有趣,因为它看起来表明了居民的电量使用在秋季和冬季会增加,而在春季和夏季则会减少。直观地说,这正是我们期望要看到的。从每周的趋势来看,周日的使用量似乎比一周中其它时间都要多。最后,总体的趋势表明,使用量增长了一年,然后才缓慢地下降。需要进行进一步的调查来解释这一趋势。在下一篇文章中,我们将尝试找出是否与天气有关。
LSTM(Long Short-Term Memory,长短期记忆网络)预测
LSTM循环神经网络具有学习长序列观测值的前景。博客文章《了解LSTM网络》,在以一种易于理解的方式来解释底层复杂性方面做的非常出色。以下是一个描述LSTM内部单元体系结构的示意图:
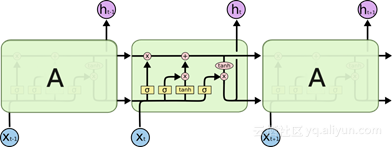
来源:Understanding LSTM Networks
LSTM似乎非常适合于对时间序列的预测。让我们再次使用一下每日汇总的数据。
LSTM对输入数据的大小很敏感,特别是当使用Sigmoid或Tanh这两个激活函数的时候。通常,将数据重新调整到[0,1]或[-1,1]这个范围是一个不错的实践,也称为规范化。我们可以使用scikit-learn库中的MinMaxScaler预处理类来轻松地规范化数据集。

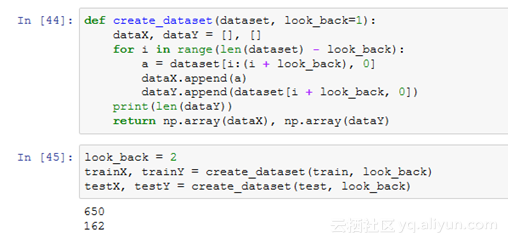
现在我们可以将已排好序的数据集拆分为训练数据集和测试数据集。下面的代码计算出了分割点的索引,并将数据拆分为多个训练数据集,其中80%的观测值可用于训练模型,剩下的20%用于测试模型。

我们可以定义一个函数来创建一个新的数据集,并使用这个函数来准备用于建模的训练数据集和测试数据集。
LSTM网络要求输入的数据以如下的形式提供特定的数组结构:[样本、时间间隔、特征]。
数据目前都规范成了[样本,特征]的形式,我们正在为每个样本设计两个时间间隔。可以将准备好的分别用于训练和测试的输入数据转换为所期望的结构,如下所示:
![]()
就是这样,现在已经准备好为示例设计和设置LSTM网络了。

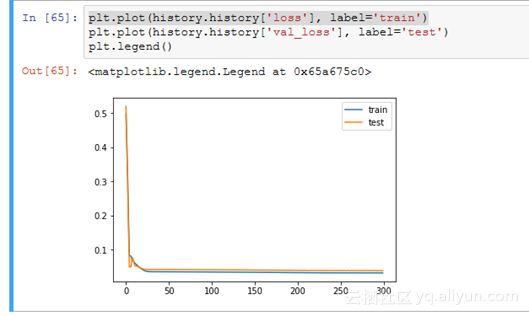
从下面的损失图可以看出,该模型在训练数据集和测试数据集上都具有可比较的表现。
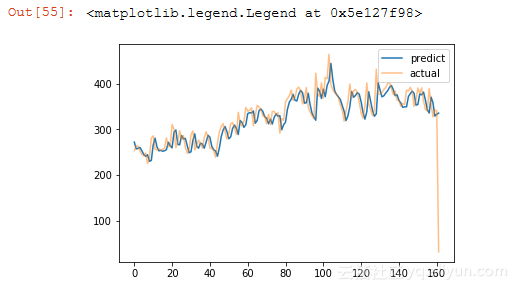
在下图中,我们看到LSTM在拟合测试数据集方面做得非常好。
聚类(Clustering)
最后,我们还可以使用示例的数据进行聚类。执行聚类有很多不同的方式,但一种方式是按结构层次来形成聚类。你可以通过两种方式形成一个层次结构:从顶部开始来拆分,或从底部开始来合并。我决定先看看后者。
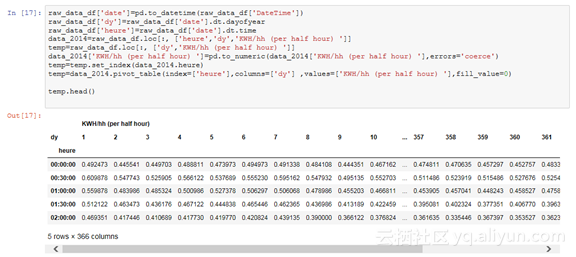
让我们从数据开始,只需简单地导入原始数据,并为某年中的某日和某日中的某一小时添加两列。
Linkage和Dendrograms
linkage函数根据对象的相似性,将距离信息和对象对分组放入聚类中。这些新形成的聚类随后相互连接,以创建更大的聚类。这个过程将会进行迭代,直到在原始数据集中的所有对象在层次树中都连接在了一起。
对数据进行聚类:

完成了!!!这难道不是很简单吗?
当然很简单了,但是上面代码中的“ward”在那里意味着什么呢?这实际上是如何执行的?正如scipy linkage文档上告诉我们的那样,“ward”是可以用来计算新形成的聚类之间距离的一个方法。关键字“ward”让linkage函数使用Ward方差最小化算法。其它常见的linkage方法,如single、complete、average,还有不同的距离度量标准,如euclidean、manhattan、hamming、cosine,如果你想玩玩的话也可以使用一下。
现在让我们来看看这个称为dendogram的分层聚类图。dendogram图是聚类的层次图,其中那些条形的长度表示到下一个聚类中心的距离。
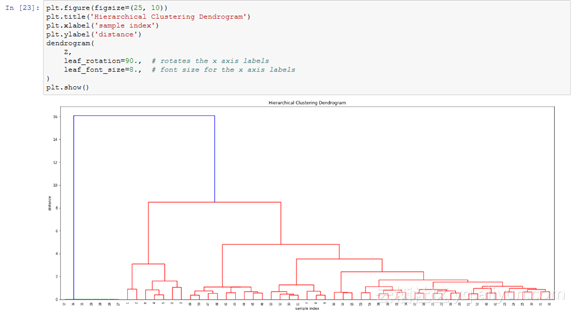
如果这是你第一次看到dendrogram图,那看起来挺复杂的,但是别担心,让我们把它分解来看:
·在x轴上可以看到一些标签,如果你没有指定任何其它内容,那么这些标签就是X上样本的索引;
·在y轴上,你可以看到那些距离长度(在我们的例子中是ward方法);
·水平线是聚类的合并;
·那些垂线告诉你哪些聚类或者标签是合并的一部分,从而形成了新的聚类;
·水平线的高度是用来表示需要被“桥接”以形成新聚类的距离;
即使有解释说明,之前的dendogram图看起来仍然不明显。我们可以减少一点,以便能更好地查看数据。
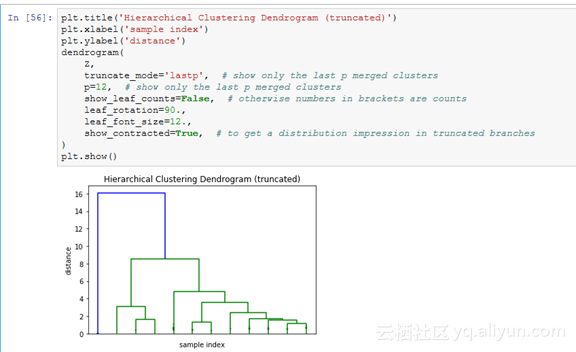
建议查找聚类文档以便能了解更多内容,并尝试使用不同的参数。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Playing with time series data in python》
译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文

