你准备好要成为一名数据科学家,积极的参加Kaggle比赛和Coursera的讲座。虽然这一切都准备好了,但是一名数据科学家的实际工作与你所期望的却是大相径庭的。

本文研究了作为数据科学家新手的5个常见错误。这是由我在塞巴斯蒂安·福卡德(Dr. Sébastien Foucaud)博士的帮助下一起完成的,他在指导和领导学术界与行业领域的年轻数据科学家方面拥有20多年的经验。本文旨在帮助你更好地为今后的实际工作做准备。

1、Kaggle成才论
Source: kaggle.com on June 30 18.
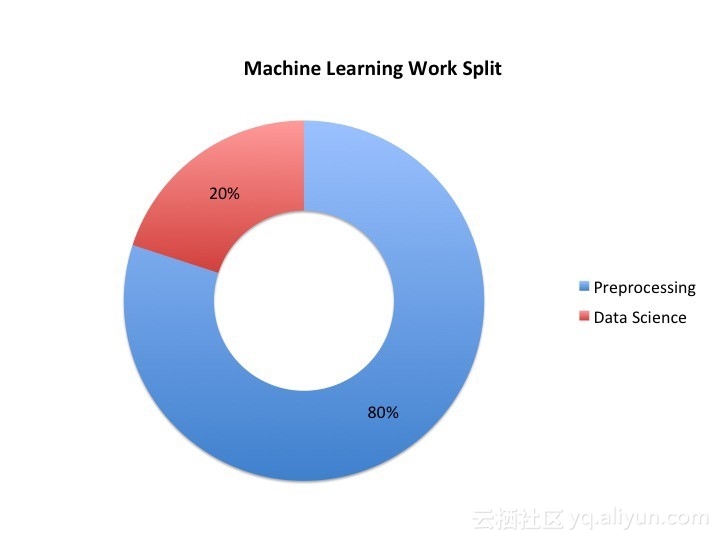
你通过参加Kaggle比赛,练习了数据科学领域的各项技能。如果你能把决策树和神经网络结合起来那就再好不过了。说实话,作为一个数据科学家,你不需要做那么多的模型融合。请记住,通常情况下,你将花80%的时间进行数据预处理,剩下的20%的时间用于构建模型。
作为Kaggle的一份子对你在很多方面都有帮助。所用到的数据一般都是彻底处理过的,因此你可以花更多的时间来调整模型。但在实际工作中,则很少会出现这种情况。一旦出现这种情况,你必须用不同的格式和命名规则来收集组装不同来源的数据。
做数据预处理这项艰苦的工作以及练习相关的技能,你将会花费80%的时间。抓取图像或从API中收集图像,收集Genius上的歌词,准备解决特定问题所需的数据,然后将其提供给笔记本电脑并执行机器学习生命周期的过程。精通数据预处理无疑会使你成为一名数据科学家,并对你的公司产生立竿见影的影响。
2、神经网络(Neural Networks)无所不能
在计算机视觉或自然语言处理的领域,深度学习模型优于其它机器学习模型,但它们也有很明显的不足。
神经网络需要依赖大量的数据。如果样本很少,那么使用决策树或逻辑回归模型的效果会更好。神经网络也是一个黑匣子,众所周知,它们很难被解释和说明。如果产品负责人或主管经理对模型的输出产生了质疑,那么你必须能够对模型进行解释。这对于传统模型来说要容易得多。
正如詹姆斯·勒(James Le)在一个伟大的邮件中所阐述的那样,有许多优秀的统计学习模型,自己可以学习一下,了解一些它们的优缺点,并根据用例的约束来进行模型的实际应用。除非你正在计算机视觉或自然语言识别的专业领域工作,否则最成功的模型很可能就是传统的机器学习算法。你很快就会发现,最简单的模型,如逻辑回归,通常是最好的模型。
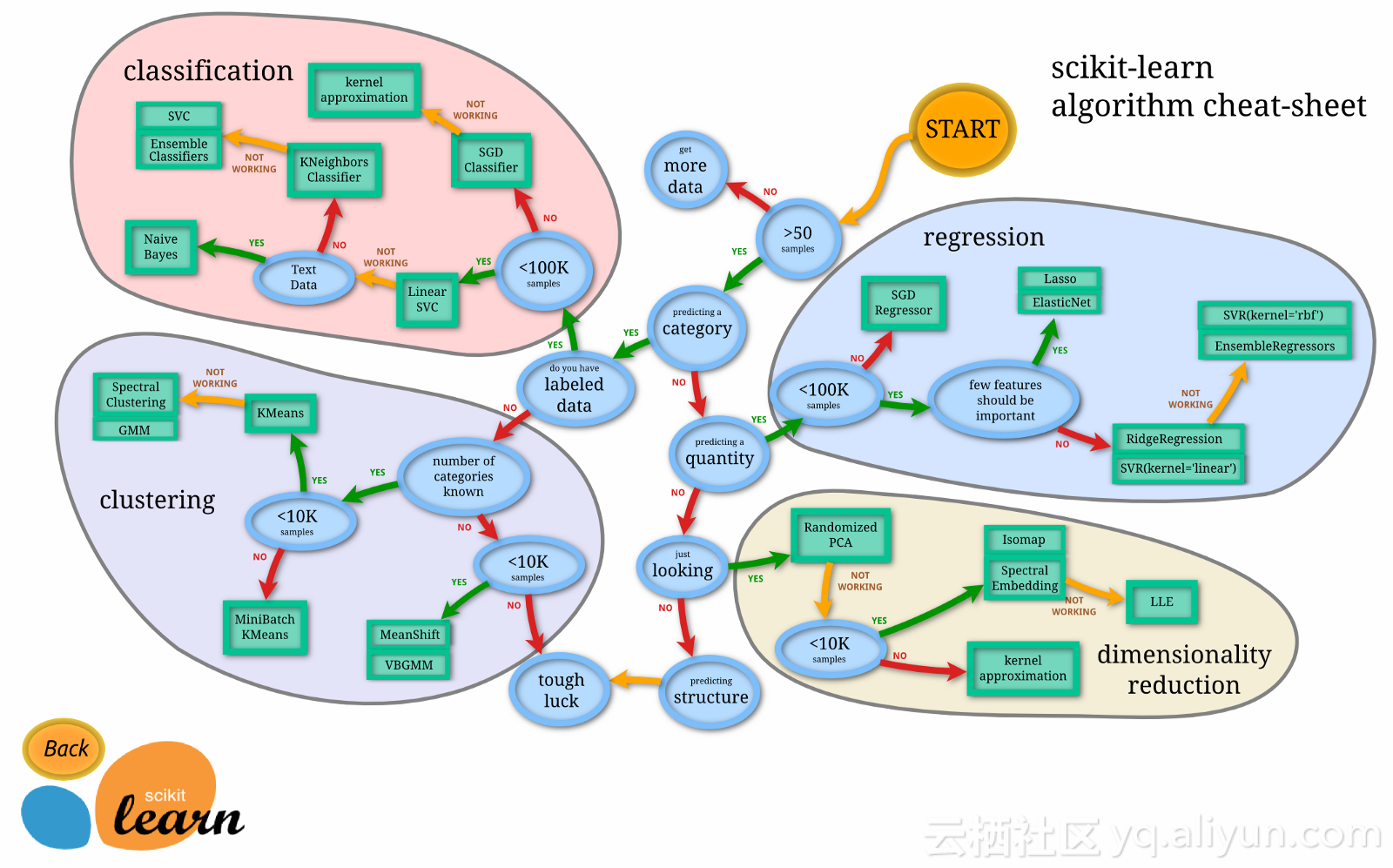
来源:算法来自scikit-learn.org.
3、机器学习是产品
在过去的十年里,机器学习既受到了极大的吹捧,也受到了很大的冲击。大多数的初创公司都宣称机器学习可以解决现实中遇到的任何问题。
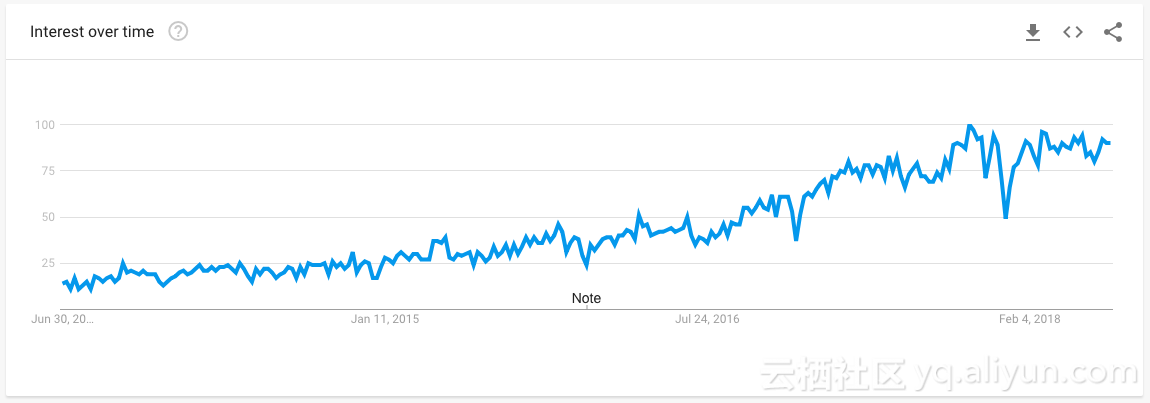
来源:过去5年谷歌机器学习的趋势
机器学习永远都不应该是产品。它是一个强大的工具,用于生产满足用户需求的产品。机器学习可以用于让用户收到精准的商品推荐,也可以帮助用户准确地识别图像中的对象,还可以帮助企业向用户展示有价值的广告。
作为一名数据科学家,你需要以客户作为目标来制定项目计划。只有这样,才能充分地评估机器学习是否对你有帮助。
4、混淆因果和相关
有90%的数据大约是在过去的几年中形成的。随着大数据的出现,数据对机器学习从业者来说已经变得越来越重要。由于有非常多的数据需要评估,学习模型也更容易发现随机的相关性。
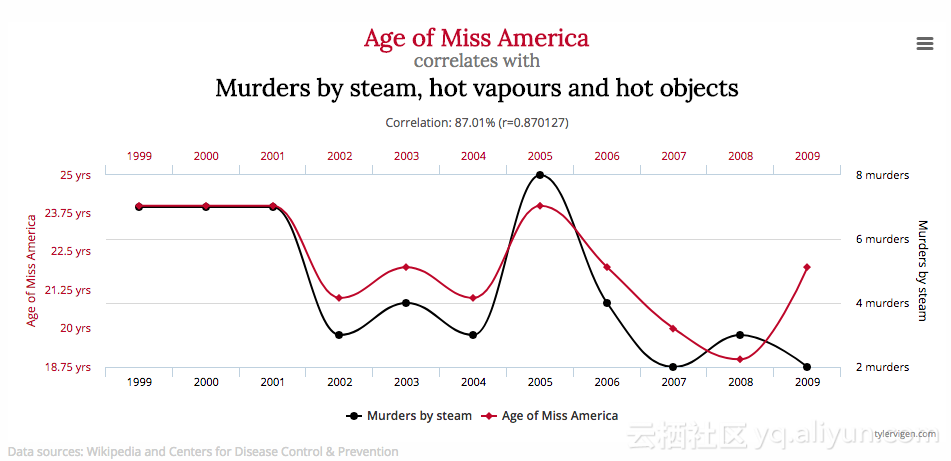
来源: http://www.tylervigen.com/spurious-correlations
上图显示的是美国小姐的年龄和被蒸汽、热气和发热物体导致的命案总人数。考虑到这些数据,一个学习算法会学习美国小姐的年龄影响特定对象命案数量的模式。然而,这两个数据点实际上是不相关的,并且这两个变量对其它的变量没有任何的预测能力。
当发现数据中的关系模式时,就要应用你的领域知识。这可能是一种相关性还是因果关系呢?回答这些问题是要从数据中得出分析结果的关键点。
5、优化错误的指标
机器学习模型通常遵循敏捷的生命周期。首先,定义思想和关键指标。之后,要原型化一个结果。下一步,不断进行迭代改进,直到得到让你满意的关键指标。
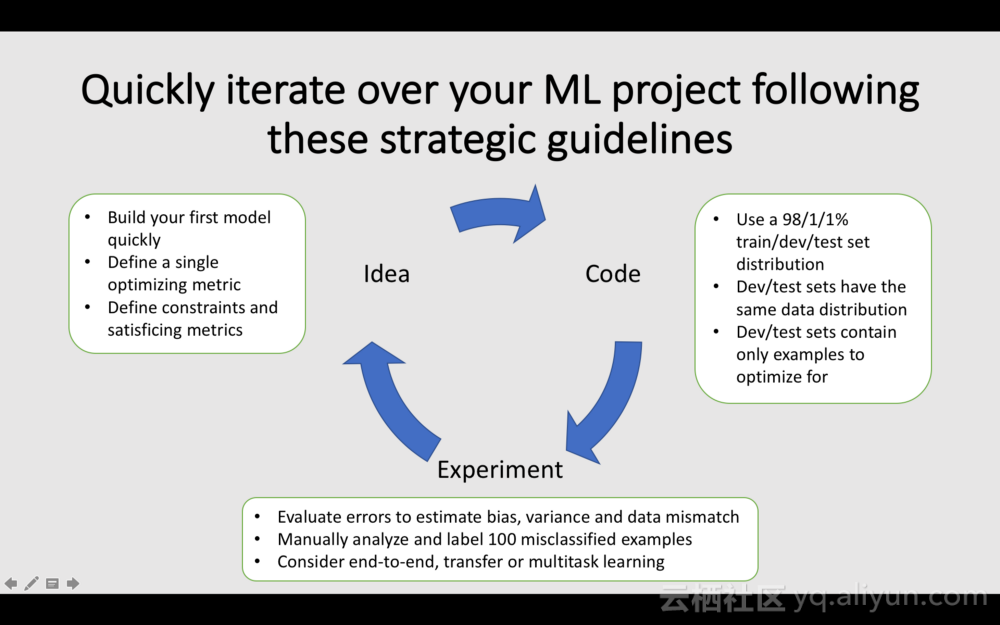
构建一个机器学习模型时,请记住一定要进行手动错误分析。虽然这个过程很繁琐并且比较费时费力,但是它可以帮助你在接下来的迭代中有效地改进模型。参考下面的文章,可以从Andrew Ng的Deep Learning Specialization一文中获得更多关于改进模型的技巧。
注意以下几个关键点:
•实践数据处理
•研究不同模型的优缺点
•尽可能简化模型
•根据因果关系和相关性检查你的结论
•优化最有希望的指标
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
文章原标题《Top 5 Mistakes of Greenhorn Data Scientists》
译者:Mags,审校:袁虎。
文章为简译,更为详细的内容,请查看原文