机器学习可行性
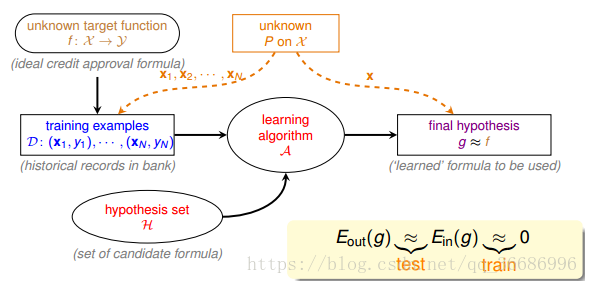
在银行评估贷款申请人的授信请求前,会进行风险评估。符合申请则通过,反之驳回。长时间的数据和申请使得银行从中找到了一些规律并开始learning,所以风险评估就是一个learning的过程,流程图如下:
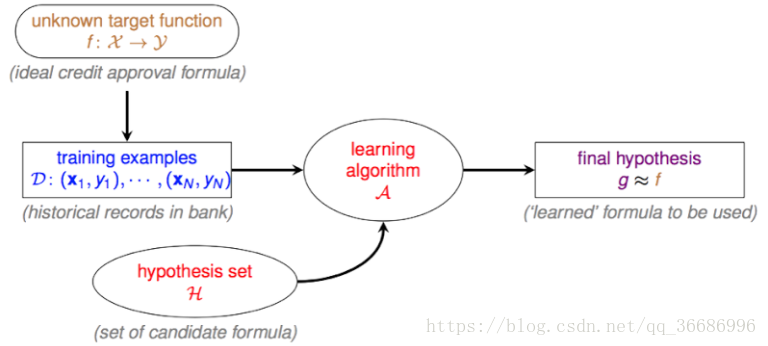
首先target function我们是未知的,需要求解的。D就是我们的训练数据,hypothesis set就是我们的假设集合,也就是说我们的最佳函数g就是要从里面选择,learing algorithm我们称为演算法,使用这个演算法来选择最好的g,最后达到g ≈ f的结果。
先介绍一个Perceptron Algorithm---感知机
为每一个特征向量设置一个w,所以的wx相加如果大于某一个阈值,我们就设置为正例,approve credit;否则就deny了。

但其实我们一般会把阈值加进来一起预测,因为如果分开的话求导计算或者其实算法计算要分两部分。
如下变换:
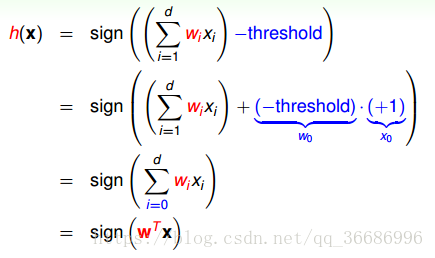
设置一个X0,我们称为是1。
对于这个perceptron,对于不同的权值集合,我们就有多少种不同的线段,而这些不同的线段,其实就是假设集合,刚刚所说的hypothesis set。
perceptron的学习
一开始我们的权值肯定是一个随机值,那么学习的过程就是一个转变方向的过程了。我们通过第一个错误进行逐步的修正:

当发现了一个错误,那么这个错误肯定和我们预知的范围是相反的,比如一个mistake,wx < 0 ,意味着是在图像的下方,而w是法向量,那么就会出现w和mistake的夹角就是大于90度的了,所以需要小于90度,则只需要加上yx即可,y代表要旋转的方向。
但是每一次的改变有可能使得correct的点变成mistake,但是没有关系,迭代下去总可以找到最好的一个g。
perceptron的停止条件
对于一个集合D,如果是线性可分的,自然就分开了,但如果是线性不可分的,你们感知机就不会停止,一直迭代下去,因为只要有错误就一直进行迭代而不会找到最佳的g ≈ f。
当然对于非线性的情况我们不考虑,对于线性可分的情况,我们可以用公式表明W在变化的过程中确实是越来越接近Wf的。
当一个向量越接近一个向量的时候,如果这两个向量是单位向量,那么越接近自然越大,所以如果W*Wf变大,就可以证明percetron确实是可以学习的。
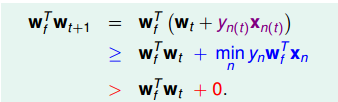
YnWfXn>0。因为y就是根据WX来分类的,这两的正负号肯定是一样的。
但是增大的可能性其实还有可能是这逼长度变化了,导致增大,所以我们要证明
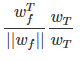
是不断增大的。
推导流程如下:

所以可以证明W是随着时间的增长不断的靠近Wf的,perceptron的学习就被证明是有效的了。
回到我们要讲的机器学习可行性
举一个例子,现在有一个九宫格要我们来找规律推测出第三个九宫格里面的内容:

不同的学习方法找到的规律是不一样的,得到的g(x)也不一样。给出的这个例子里面的六个九宫格其实就是机器学习里面的数据D,我们可以找到并且看见的,而那个我们需要预测的就是我们看不见并且要预测的大数据。比如刚刚的credit card,我们要预测的其实就是所有人,而不是仅仅的只是数据集里面的。
在机器学习基石里面老师用了一个bin的例子:
在训练集D以外的样本上,机器学习的模型是很难,似乎做不到正确预测或分类的。那是否有一些工具或者方法能够对未知的目标函数f做一些推论,让我们的机器学习模型能够变得有用呢?
比如装有一个很多球的罐子:
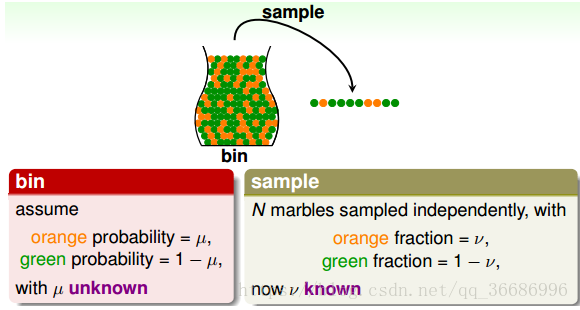
其实这个罐子就是hypothesis set里面的一个h(x) 。罐子里面的球其实本来是没有颜色的,我们依照h(x) 的分布,把这里面的求都用油漆涂成orange and green。orange代表错误,而green代表正确。抽样抽出来的小球其实就是我们的数据集set,就是已经拿到并且是带了label那种。
我们现在就是要确定能否用抽样的比例来确定罐子里面的比例呢?
u是罐子里面orange的比例,而v则是抽样抽到的orange的比例。那么根据霍夫丁不等式有:
P[|v−u|>ϵ]≤2exp(−2ϵ2N)
当N很大的时候其实两个都是差不多的。
我们把u ≈ v称为probably approximately correct(PLA),近似相等。
联系到机器学习上面
我们将罐子的内容对应到机器学习的概念上来。机器学习中hypothesis与目标函数相等的可能性,类比于罐子中橙色球的概率问题;罐子里的一颗颗弹珠类比于机器学习样本空间的x;橙色的弹珠类比于h(x)与f不相等;绿色的弹珠类比于h(x)与f相等;从罐子中抽取的N个球类比于机器学习的训练样本D,且这两种抽样的样本与总体样本之间都是独立同分布的。所以呢,如果样本N够大,且是独立同分布的,那么,从样本中h(x)≠f(x)的概率就能推导在抽样样本外的所有样本中h(x)≠f(x)的概率是多少。

理解的关键是我们需要通过抽样来知道h(x)的错误概率是多少,通过局部推广到全局。
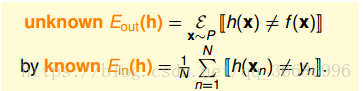
这里要引入两个值:Ein值的是抽样的错误率,Eout指的是全局的错误率,这里就是指h的错误率了。
使用霍夫丁不等式:
P[|Ein(h)−Eout(h)|>ϵ]≤2exp(−2ϵ2N)
inequalty表明:在h确定了,N很打的情况下,Ein ≈ Eout,但这并不代表g≈f,因为我们后面还要知道Ein ≈ 0才行。
类比到机器学习上面
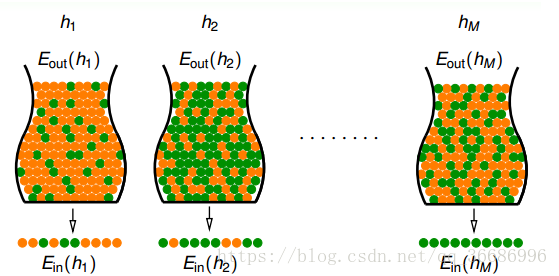
hypothesis set里面有多少个h就有多少个罐子。
但是在抽样过程中还有可能抽到坏的数据,bad sample。比如你丢一个硬币,三次向上一次向下,这并不能说明这个硬币正反面不均匀。
所以抽样也有可能抽到坏样本。
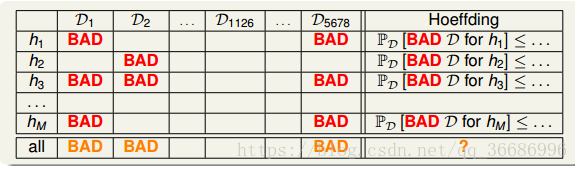
这么多个数据集,根据霍夫丁不等式,在大多数情况下,抽样得到的数据其实都是好数据,Ein ≈ Eout的,但是会有极小的情况下会出现Ein 和 Eout相差很大的情况。也就是说,不同的数据集Dn,对于不同的hypothesis,有可能成为Bad Data。只要Dn在某个hypothesis上是Bad Data,那么Dn就是Bad Data。只有当Dn在所有的hypothesis上都是好的数据,才说明Dn不是Bad Data,可以自由选择演算法A进行建模。那么,根据Hoeffding’s inequality,Bad Data的上界可以表示为连级(union bound)的形式:

意味着,如果M是有限的,N很大,那么我们出现bad sample的概率会很小,Ein ≈ Eout就可以成立,再选取一个合理的演算法,就可以得到g ≈ f,机器学习就有效了。这样就有了不错的泛化能力。
要解决的问题已经M的处理
上面的讲解过后机器学习的流程:
于是就回归到了两个问题:

①Ein ≈ Eout
②Ein ≈ 0

M就是代表hypothesis set里面h的数量,M小,可以达到bad sample概率小但是选择就少了,而大的话就有可能变成大概率了。所以M需要不大不小的。
但事实上很多机器学习的hypothesis set都是M无限大的,比如SVM,linear regression,logitic regression他们的M都是无限大的,但他们的学习都是有效的,所以,很明显这里的M是可以被替换掉的。替换成一个有限的mH。
对M的处理
hypothesis set是无限的,但他的种类肯定是有限的,比如2D-perceptron要分类一个数据点:
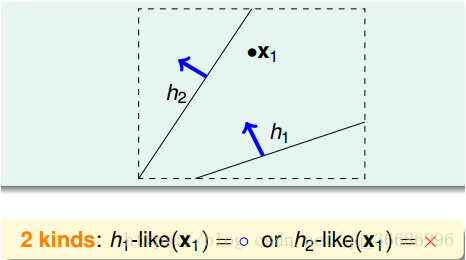
在这个分类里面,hypothesis set是无限多个的,因为不同的w集合就不同的直线,但他的分类种数却只有两种,要不X要不O,就两种,所以可见,很多的H是有重叠的。
如果有两个点:
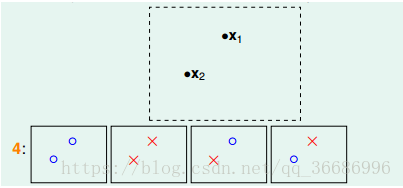
就四种情况。
到了三个点的时候,情况有所不一样:
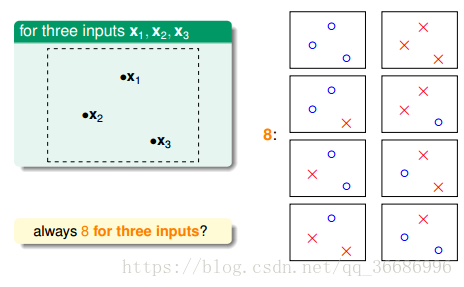
这样是8种情况。
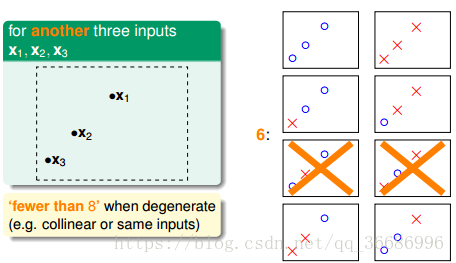
我们自然是要找最多的了,所以3个点2分类就是8种情况。
四个点就是14种情况。

所以我们的M其实可以被有限个替代的。如果可以保证是小于2^n次方,也就算是无限大的,他的种类也是有限的。
成长函数
成长函数的定义是:对于由N个点组成的不同集合中,某集合对应的dichotomy最大,那么这个dichotomy值就是mH(H),它的上界是2N:
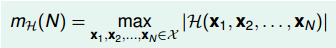
而我们刚刚的例子:

我们现在要做的就是要讨论如何限制成长函数,得到表达式或者是找到上界。
成长函数的讨论
对于一维的positive rays(正射线):

当N = 1
mH(1) = 2
当N = 2
mH(2) = 3
所以他的mH(N) = N + 1
对于一维的positive intervals:

下面推导可以得到:
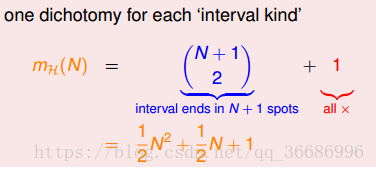
而对于一个凸集合:
他的成长函数就是2^n次方了。

所以可以看到在某些情况下,成长函数增长到一定情况下,会被限制,也就是在那个地方会小于2^n。
而这个点,我们就称为 break point。在这个点和这个点以后,任何两点都不能被shatter。
shatter的意思:比如你有一把散弹枪,要求你每一关都要一枪打死所有人,第一关的时候,你一枪可以打死所有人,第二关也可以,第三关不行了,那么3就是break point了。
positive rays:N = 1的时候,shatter的情况就是 这个点等于x,o,而很明显可以达到。N = 2的时候,shatter的情况就是xx ,oo,xo ,ox,而ox是达不到的,所以2就是break point了,而N = 3的时候,就更加不能被shatter了。如果是三分类,那就要求任何三个点都不能被shatter。
其他的情况也是一样:

能不能shatter,就是看他能不能有2 n种分类,三分类就是3n种了。
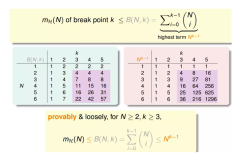
mH(N)的限制
现在我们确定了,break point绝逼是mH(N)的一个限制,因为在那个点开始就不再是2^n的规律了。

我们现在要证明的就是,上界是plot(N)。
对于mH(N),因为不同的模型对应的mH(N)不一样的,所以直接讨论mH(N)是很困难的,我们可以找一个上界,要讨论mH(N)就直接讨论上界就好了。上界我们设为B(N , K)。
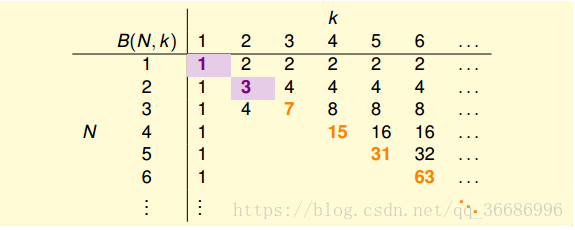
第一列肯定是1了。
当N < K的时候,肯定是2^n次方
当N = k的时候,这个时候是第一次不能被shatter的情况,小于2 n,那就设为2n-1吧。其实就是算在N个点K个点不能被shatter的情况下,有多少种mH(N)。
填上三角其实很简单,现在填下三角了。
先写出B(4,3)的所以情况:
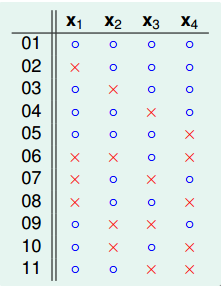
把他划分下:

上面橙色的作为a,下面紫色的作为b,有:
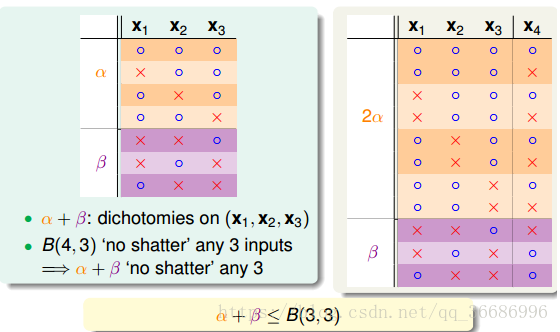
所以我们可以得到:

进一步推广:

所以整个就是:
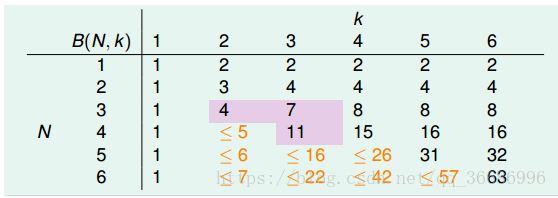
最后根据递推公式,可以得到:
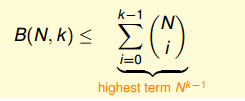
所以B(N ,K)的上界满足多项式。
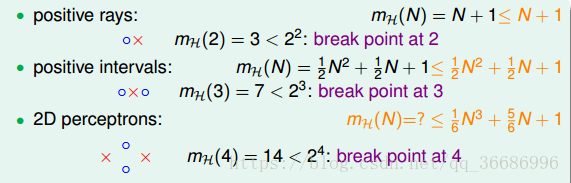
最后我们就得到M的上界是一个多项式。
正常的想法是带回原式:

但这样是不行的,因为一个M就对应这一个Ein,但是Eout是无限个的,而替换了M成mH(N)之后,这个Ein就是有限的了,两个级数不同是不可以进行计算的。所以正确的公式:

怎么证明就不说了。最后的结果我们叫做 VC bound:
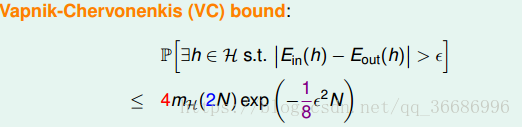
总结一下流程:首先,我们的M是无限的,现在想要替换成有限个,于是我们找上界,找到了break point,发现这个点可以打破指数增长的规律;而对于不同的维度模型mH(N)是不同的,于是,准备一个上界函数B(N , K),这样就不用再考虑维度问题了,直接找上界函数即可;之后又找到B(N , K)的上界函数是一个多项式。于是就保证了这个M是可控制的。
VC dimension

顺便说一下边界。
这样,不等式就只和K,N有关系了。 根据VCbound理论:如果空间H有break point k,且N足够大,则根据VC bound理论,算法有良好的泛化能力;如果在H空间中有一个g可以使得Ein ≈ 0,则全集数据集的错误率会偏低。
下面介绍一个新名词:VC dimension
VC Dimension就是某假设集H能够shatter的最多inputs的个数,即最大完全正确的分类能力。其实就break point - 1。因为break point是最小任何两个点都不可被shatter的点。
来看一下之前的几个例子,他们的VC dimension是多少:

现在我们用VC dimension来代替K,那么VC bound的问题就转换成了VC dimension和N的问题,自然就解决了第一个问题——Eout ≈ Ein。
VC dimension of perceptron
已知Perceptrons的k=4,即dvc=3。根据VC Bound理论,当N足够大的时候,Eout(g) ≈ Ein(g)。如果找到一个g,使Ein(g)≈0,那么就能证明PLA是可以学习的。

这是在2D的情况的情况下,如果是多维的呢?
1D perceptron , dvc = 2;2D perceptron , dvc = 3,我们假设,和维度有关,d维,那就是d+1。
要证明只要分两步:
dvc >= d+1
dvc <= d+1
证明dvc >= d+1
在d维里面,我们只要找到某一类的d+1个输入可以被shatter就可以了。因为找到一个符合的,其他就可以得到dvc >= d+1。
我们构造一个可逆的X矩阵:

shatter的本质是假设空间H对X的所有情况的判断都是对的,意味着可以找到权值W满足W*X = Y,而W = X^-1 * Y,所以可以得到对于d+1个输入是可以被shatter的。
证明dvc <= d+1
在d维里,如果对于任何的d+2个inputs,一定不能被shatter,则不等式成立。
我们构造一个任意的矩阵X,其包含d+2个inputs,该矩阵有d+1列,d+2行。这d+2个向量的某一列一定可以被另外d+1个向量线性表示,例如对于向量Xd+2,可表示为: Xd+2=a1∗X1+a2∗X2+⋯+ad+1∗Xd+1。所以他的自由度只有d+1,因为确定了d+1个,d+2个就知道了。
所以综上所述dvc = d+1
VC dimension的理解
在perceptron中的W,被称为是features。W就像按钮一样可以随意调节,所以也叫自由度。VC Dimension代表了假设空间的分类能力,即反映了H的自由度,产生dichotomy的数量,也就等于features的个数。

比如,2D的perceptron,VC dimension是3,而W就是{W0,W1,W2}。
回到VC bound
上面的VC维告一段落了,回到VC bound。

这是我们之前推导得到的VC bound。
根据之前的霍夫丁不等式,如果|Ein−Eout|>ϵ,那么他发生的概率就不会超过δ;反过来,发生好的概率就是1-δ。
我们重新推导一下:
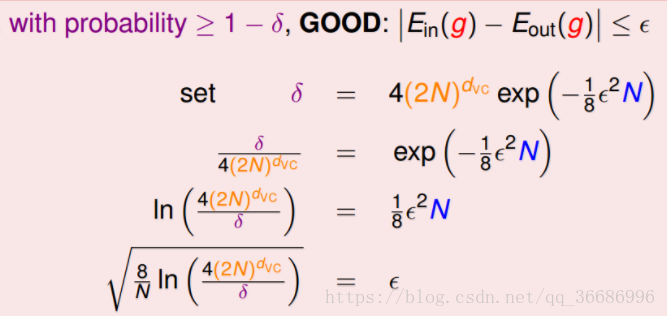
于是我们可以得到:

事实上前面的那个我们并不会太关注他,所以有:

Ω我们称为是模型的复杂度,其模型复杂度与样本数量N、假设空间H(dvc)、ϵ有关。下面是他们的图像:

该图可以得到如下结论:
dvc越大,Ein越小,Ω越大(复杂)。
dvc越小,Ein越大,Ω越小(简单)。
随着dvc增大,Eout会先减小再增大。
所以并不是越复杂的模型越好,这其实就是 过拟合的理论基础,在训练集上表现的很好,但是在测试集上就很糟糕。看到这我就知道差不多理解了,舒服!
理解实际问题linear regression to linear lassification
线性回归是用来做回归拟合的,能不能做分类呢?学习过程也就是找到g ≈ f的过程可以不用担心,因为regression已经证明是可行的了,现在要解决的就是第一个问题---Eout ≈ Ein。
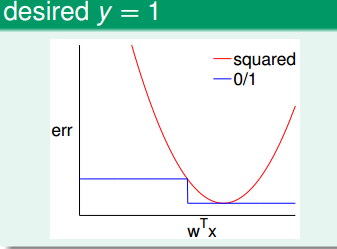
回归模型的错误是err = (y - y)2,而分类模型的错误无非就是0和1。

当y = 1:
当y = -1
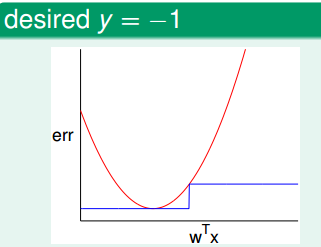
很明显,回归错误大于分类错误。
原来的有:

自然根据VC bound原理了。
当然上界更加宽松一点了,效果可以没有之前的好,但是保证了Eout ≈ Ein的概率。