聚类算法:
聚类算法属于无监督学习,没有给出分类,通过相似度得到种类。
主要会讲四种:Kmeans均值,层次聚类,DBSCAN,谱聚类。
再讲算法前先讲一下几种衡量相似度的方法:
1.欧氏距离:
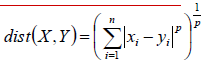
p=2时就说平时计算的几何距离,当p趋向于正无穷的时候,其实求的就不是x,y的距离了,而是求x y中最长的一个了。因为如果x大于y,在指数增长下x回远大于y,所以y会被忽略的。这也是比较常用的了。
2.杰卡得相似度:
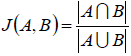
这个一般用于是推荐系统的应用,比如推荐的是A,用户选的是B,那么就可以用这个来衡量了。
3.余弦相似度:
余弦相似度一般用于对词向量的相似度判断,他会省略刻度的变化,正好符合向量的判断方法。
4.Pearson相似度:
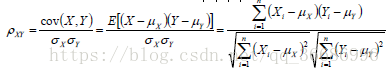
pearson相似度和cos相似度其实很像,其实就是平移到原点求余弦
5.相对熵:
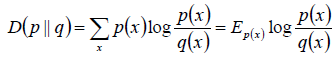
这个在决策树会用到判断熵增变化
一下的算法中我们只会用到欧氏距离,想用其他的改一下distance函数就OK了。
==================================================================================================================
Kmeans均值算法:
算是比较简单而且实用的方法了。
实现步骤:
1.选定k个类别中心点,u1,u2......un
2.对于每个样本点,选定离他最近的那个类别作为一个类别。
3.将类别中心更新为所有样本点的均值
4.重复步骤,只到均值点不再更新为止。
简单python实现Kmeans均值:
首先是数据的准备:
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sea
import pandas as pd
import random
def read_file(filename):
df = pd.read_csv(filename)
df.drop('编号' , axis=1 , inplace=True)
return df
导包,文件读取方法。
这是数据:
编号,密度,含糖率
1,0.697,0.46
2,0.774,0.376
3,0.634,0.264
4,0.608,0.318
5,0.556,0.215
6,0.403,0.237
7,0.481,0.149
8,0.437,0.211
9,0.666,0.091
10,0.243,0.267
11,0.245,0.057
12,0.343,0.099
13,0.639,0.161
14,0.657,0.198
15,0.36,0.37
16,0.593,0.042
17,0.719,0.103
18,0.359,0.188
19,0.339,0.241
20,0.282,0.257
21,0.784,0.232
22,0.714,0.346
23,0.483,0.312
24,0.478,0.437
25,0.525,0.369
26,0.751,0.489
27,0.532,0.472
28,0.473,0.376
29,0.725,0.445
30,0.446,0.459
需要的复制到Data.txt文件里面就可以了。
dataFile = read_file('Data.txt')
data = dataFile.values
mean_data = np.mean(data , axis=0)
data -= mean_data
data = list(data)
k = 3
mean_vectors = random.sample(data , k)
'''
计算距离
'''
def dist(p1 , p2):
return np.sqrt(sum(np.square(p1 - p2)))
这是读取文件,去均值化的操作。mean_vectors = random.sample(data , k)选取k个点作为均值。下面的就是计算欧氏距离的了。
聚类过程:
while True:
clusters = list(map((lambda x : [x]) , mean_vectors))
for sample in data:
distances = list(map((lambda m : dist(sample , m)) , mean_vectors))
min_indexs = distances.index(min(distances))
clusters[min_indexs].append(sample)
new_mean_vectors = []
for c , v in zip(clusters , mean_vectors):
new_mean_vector = sum(c)/len(c)
if all(np.divide((new_mean_vector-v),v) < np.array([0.0001,0.0001]) ):
new_mean_vectors.append(v)
else:
new_mean_vectors.append(new_mean_vector)
if np.array_equal(mean_vectors,new_mean_vectors):
break
else:
mean_vectors = new_mean_vectors
print(mean_vectors)
print(new_mean_vectors)
pass
先把中心点变成一个有三个list的大list
clusters = list(map((lambda x : [x]) , mean_vectors))
对于每一个点,计算他和三个中心点的距离,然后取最小的作为分类,放进对应的list里面。
for sample in data:
distances = list(map((lambda m : dist(sample , m)) , mean_vectors))
min_indexs = distances.index(min(distances))
clusters[min_indexs].append(sample)
new_mean_vectors = []
计算新的中心点,如果差距不大的话就作为新的中心点
for c , v in zip(clusters , mean_vectors):
new_mean_vector = sum(c)/len(c)
if all(np.divide((new_mean_vector-v),v) < np.array([0.0001,0.0001]) ):
new_mean_vectors.append(v)
else:
new_mean_vectors.append(new_mean_vector)
if np.array_equal(mean_vectors,new_mean_vectors):
break
else:
mean_vectors = new_mean_vectors
print(mean_vectors)
接下来就是画图了。
total_colors = ['r','y','g','b','c','m','k']
shapes = ['p','o','v','^','s']
colors = random.sample(total_colors,k)
index = 0
x = list(map((lambda x : x[0]) , mean_vectors))
y = list(map((lambda x : x[1]) , mean_vectors))
for cluster,color in zip(clusters,colors):
density = list(map(lambda arr:arr[0],cluster))
sugar_content = list(map(lambda arr:arr[1],cluster))
plt.scatter(density,sugar_content,c = color,marker=shapes[index])
index += 1
plt.scatter(x , y , c = 'blue' , marker='x')
plt.show()
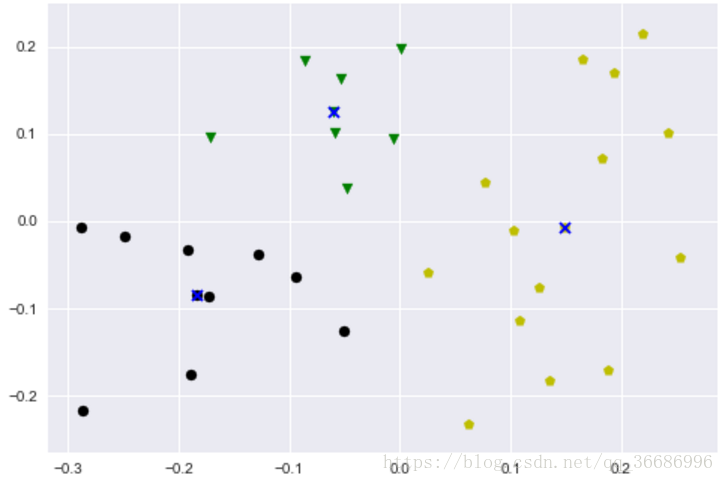
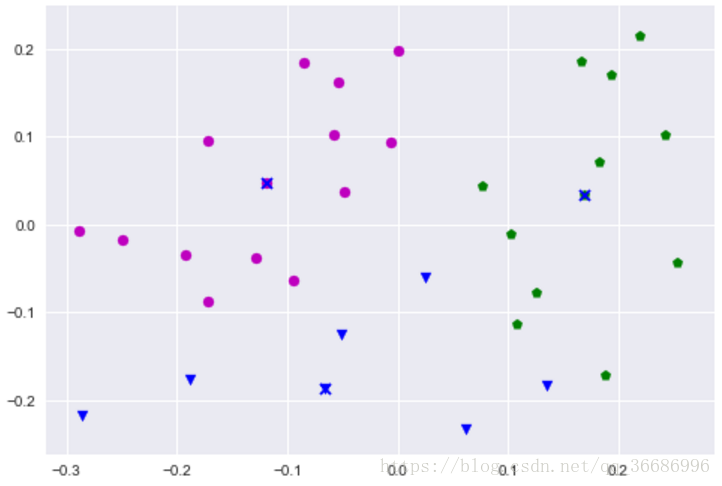
说实话效果还是不错的。
这就是一个比较简单python实现了。
Kmeans的公式化解释:

改进:
1.Kmeans算法如果是遇到均值偏离严重的,可能会导致均值不准确,可以选择中值点。
2.如果是初始的均值点选择不好,可能达不到全局的收敛,只能达到局部收敛。而Kmeans就是一直改进方法:改进了选择K初始值的方法,假设已经选取了n个初始聚类中心(0<n<K),则在选取第n+1个聚类中心时:距离当前n个聚类中心越远的点会有更高的概率被选为第n+1个聚类中心。在选取第一个聚类中心(n=1)时同样通过随机的方法。可以说这也符合我们的直觉:聚类中心当然是互相离得越远越好。这个改进虽然直观简单,但是却非常得有效。
Kmeans选择的时候注意不要选择最大距离的点做为下一个初始值,因为可以最大的这个点是噪音,所以只是要求远的点有很多概率会被选择到。
Kmeans方法总结:
优点:
1.简单,快速,计算很方便。
2.处理大数据的时候,算法可以保持伸缩性和高效性
3.当簇近似于高斯发布时,效果最好。事实上如果涉及到减去均值然后平方都是有关于高斯发布的。因为这个就是高斯分布推出来的。
缺点:
1.在簇的平均值可被定义的情况下才有用,所以不适用于某种情况。
2.必须给出初始值的K值,对初始很敏感。
3.不适合发现非凸形状或者是大小差别很大的形状。
4.对噪声点和孤立点敏感。
==================================================================================================================
层次聚类方法:
层次聚类分为两种,一种是凝聚层次聚类,一种是分裂层次聚类。这里主要讲凝聚的。
算法很简单:一开始每一个点都是一个类别,然后计算每一个所有点里面两个距离最小的,合并一个类,直到合并到K个类别为止,不阻止他会合并到1的。
python实现:
import numpy as np
import sklearn.datasets as datasets
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import math
from sklearn.decomposition import PCA
def get_data():
df = datasets.load_iris()
data = df.data
label = df.target
data_matrix = np.matrix(data)
label_matrix = np.matrix(label)
return data , label
def ou_distance(vec1 , vec2):
distance = 0.0
for a, b in zip(vec1, vec2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
pass
导包,得到数据,计算欧氏距离,使用的数据集是sklearn的iris数据集。
class Node(object):
def __init__(self ,
vec=None ,
left = None ,
right = None ,
distance = -1 ,
id = None ,
count = 1):
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id
self.count = count
pass
定义一个节点,这个节点包括了中心向量,做节点,右节点,id号(方便找到对应的点)
class Hierarchical(object):
def __init__(self , k = 1):
assert k > 0
self.k = k
self.labels = None
self.nodesList = []
pass
def fit(self , x):
#一开始一个点就是一个类别
nodes = [Node(vec=v , id=i) for i ,v in enumerate(x)]
self.nodesList.append(nodes.copy())
distance = {}
point_num , features_num = np.shape(x)
self.labels = [-1] * point_num
currentClusterid = -1
while len(nodes) > self.k:
if len(nodes) == 30:
self.nodesList.append(nodes.copy())
elif len(nodes) == 20:
self.nodesList.append(nodes.copy())
elif len(nodes) == 15:
self.nodesList.append(nodes.copy())
elif len(nodes) == 10:
self.nodesList.append(nodes.copy())
elif len(nodes) == 5:
self.nodesList.append(nodes.copy())
min_distance = math.inf
nodes_lenght = len(nodes)
closet_part = None
for i in range(nodes_lenght - 1):
for j in range(i + 1 , nodes_lenght):
d_key = (nodes[i].id , nodes[j].id)
if d_key not in distance:
distance[d_key] = ou_distance(nodes[i].vec , nodes[j].vec)
d = distance[d_key]
if d < min_distance:
min_distance = d
closet_part = (i , j)
part1 , part2 = closet_part
node1 , node2 = nodes[part1] , nodes[part2]
new_vec = [(node1.vec[i]*node1.count + node2.vec[i]*node2.count)/
(node1.count + node2.count) for i in range(features_num)]
new_node = Node(vec=new_vec ,
left=node1,
right=node2,
distance=min_distance,
id=currentClusterid,
count=node1.count + node2.count)
currentClusterid -= 1
del nodes[part2], nodes[part1]
nodes.append(new_node)
self.nodes = nodes
self.nodesList.append(self.nodes.copy())
self.calc_label()
pass
nodes = [Node(vec=v , id=i) for i ,v in enumerate(x)]
self.nodesList.append(nodes.copy())
distance = {}
point_num , features_num = np.shape(x)
self.labels = [-1] * point_num
currentClusterid = -1
这里开始解释。首先一开始都是一个类别,每一个类别没有做节点右节点,那么他们自己就是一个中心了。nodeList是为了画图的,不用管,point_num,features_num得到点的数量和特征数量。label一开始都是-1。currentClusterid就是集合的id,因为他不是数据,只是一个中间值。反正画图是用不到的。不要也行,这里加了有点难理解,但是我乐意。
while len(nodes) > self.k:
if len(nodes) == 30:
self.nodesList.append(nodes.copy())
elif len(nodes) == 20:
self.nodesList.append(nodes.copy())
elif len(nodes) == 15:
self.nodesList.append(nodes.copy())
elif len(nodes) == 10:
self.nodesList.append(nodes.copy())
elif len(nodes) == 5:
self.nodesList.append(nodes.copy())
while()里面这段都是画图准备的。不用管。
min_distance = math.inf
nodes_lenght = len(nodes)
closet_part = None
for i in range(nodes_lenght - 1):
for j in range(i + 1 , nodes_lenght):
d_key = (nodes[i].id , nodes[j].id)
if d_key not in distance:
distance[d_key] = ou_distance(nodes[i].vec , nodes[j].vec)
d = distance[d_key]
if d < min_distance:
min_distance = d
closet_part = (i , j)
这里是计算这个数据里面最小距离的点。整个类别里面距离最小最小的点。先设置min_ditance距离为无限大。代码很简单,应该能看懂。
最后得到的closet_part就是距离最小的两个编号了。
part1 , part2 = closet_part
node1 , node2 = nodes[part1] , nodes[part2]
new_vec = [(node1.vec[i]*node1.count + node2.vec[i]*node2.count)/
(node1.count + node2.count) for i in range(features_num)]
new_node = Node(vec=new_vec ,
left=node1,
right=node2,
distance=min_distance,
id=currentClusterid,
count=node1.count + node2.count)
currentClusterid -= 1
print(currentClusterid)
del nodes[part2], nodes[part1]
nodes.append(new_node)
计算出新的节点,vec为两个点的中心,然后放进数据点中,再删掉原来的。
self.nodes = nodes
self.nodesList.append(self.nodes.copy())
self.calc_label()
pass
最后这些是为了返回的,calclabel()是得到分类的函数,后面讲到。
def calc_label(self):
for i, node in enumerate(self.nodes):
self.leaf_traversal(node, i)
def leaf_traversal(self, node: Node, label):
if node.left == None and node.right == None:
self.labels[node.id] = label
if node.left:
self.leaf_traversal(node.left, label)
if node.right:
self.leaf_traversal(node.right, label)
这里是递归遍历出来所有的叶子给label值。
最后还有一个画图函数:
然而画图前要进行PCA的姜维:
pca = PCA(n_components=2)
pca.fit(data)
PCA(copy=True, n_components=2, whiten=False)
data = pca.transform(data)
def leaf_print(node , j):
if node.left == None or node.right == None:
plt.scatter(data[node.id][0] , data[node.id][1] , color = colors[j] , marker=markers[j])
if node.left:
leaf_print(node.left , j)
if node.right:
leaf_print(node.right , j)
def draw(nodes):
for i , j in zip(nodes , range(len(nodes))):
leaf_print(i,(j+1)%len(markers))
plt.title(len(nodes))
plt.show()
应该很好理解的。
另外还有一些颜色啊,,形状啊等等的,也给出来:
colors = {
'burlywood': '#DEB887',
'cadetblue': '#5F9EA0',
'chartreuse': '#7FFF00',
'chocolate': '#D2691E',
'cornflowerblue': '#6495ED',
'cornsilk': '#FFF8DC',
'crimson': '#DC143C',
'cyan': '#00FFFF',
'darkblue': '#00008B',
'darkcyan': '#008B8B',
'darkgoldenrod': '#B8860B',
'darkgray': '#A9A9A9',
'darkgreen': '#006400',
'darkkhaki': '#BDB76B',
'darkmagenta': '#8B008B',
'darkolivegreen': '#556B2F',
'darkorange': '#FF8C00',
'darkorchid': '#9932CC',
'darkred': '#8B0000',
'darksalmon': '#E9967A',
'darkseagreen': '#8FBC8F',
'darkslateblue': '#483D8B',
'darkslategray': '#2F4F4F',
'darkturquoise': '#00CED1',
'darkviolet': '#9400D3',
'deeppink': '#FF1493',
'deepskyblue': '#00BFFF',
'dimgray': '#696969',
'dodgerblue': '#1E90FF',
'firebrick': '#B22222',
'floralwhite': '#FFFAF0',
'forestgreen': '#228B22',
'fuchsia': '#FF00FF',
'gainsboro': '#DCDCDC',
'ghostwhite': '#F8F8FF',
'gold': '#FFD700',
'goldenrod': '#DAA520',
'gray': '#808080',
'green': '#008000',
'greenyellow': '#ADFF2F',
'honeydew': '#F0FFF0',
'hotpink': '#FF69B4',
'indianred': '#CD5C5C',
'indigo': '#4B0082',
'ivory': '#FFFFF0',
'khaki': '#F0E68C',
'lavender': '#E6E6FA',
'lavenderblush': '#FFF0F5',
'lawngreen': '#7CFC00',
'lemonchiffon': '#FFFACD',
'mediumpurple': '#9370DB',
'mediumseagreen': '#3CB371',
'mediumslateblue': '#7B68EE',
'mediumspringgreen': '#00FA9A',
'mediumturquoise': '#48D1CC',
'mediumvioletred': '#C71585',
'midnightblue': '#191970',
'mintcream': '#F5FFFA',
'mistyrose': '#FFE4E1',
'moccasin': '#FFE4B5',
'navajowhite': '#FFDEAD',
'navy': '#000080',
'oldlace': '#FDF5E6',
'olive': '#808000',
'olivedrab': '#6B8E23',
'orange': '#FFA500',
'orangered': '#FF4500',
'orchid': '#DA70D6',
'palegoldenrod': '#EEE8AA',
'palegreen': '#98FB98',
'paleturquoise': '#AFEEEE',
'palevioletred': '#DB7093',
'papayawhip': '#FFEFD5',
'peachpuff': '#FFDAB9',
'peru': '#CD853F',
'pink': '#FFC0CB',
'plum': '#DDA0DD',
'powderblue': '#B0E0E6',
'purple': '#800080',
'red': '#FF0000',
'rosybrown': '#BC8F8F',
'royalblue': '#4169E1',
'saddlebrown': '#8B4513',
'salmon': '#FA8072',
'sandybrown': '#FAA460',
'seagreen': '#2E8B57',
'seashell': '#FFF5EE',
'sienna': '#A0522D',
'silver': '#C0C0C0',
'skyblue': '#87CEEB',
'slateblue': '#6A5ACD',
'slategray': '#708090',
'snow': '#FFFAFA',
'springgreen': '#00FF7F',
'steelblue': '#4682B4',
'tan': '#D2B48C',
}
colors = list(colors.values())
不要标签只要值。
markers = ['.' , ',' , 'o' , 'v' , '^', '<' , '>' , '1','2','3','4','s' , 'p' , '*' , 'h' , 'H' , 'd' , '|' , '+' , 'x']
这个是形状。
运行:
my = Hierarchical(4)
data , label = get_data()
my.fit(data)
上面的fit数据,喂给它姜维之后或者是不姜维都可以的。
刚刚的self.nodelist就是保存过程的,分别保存了最开始的150个类别的,30,20,15,10,5个类别的过程。
for nodes in my.nodesList:
draw(nodes)
pass
效果:
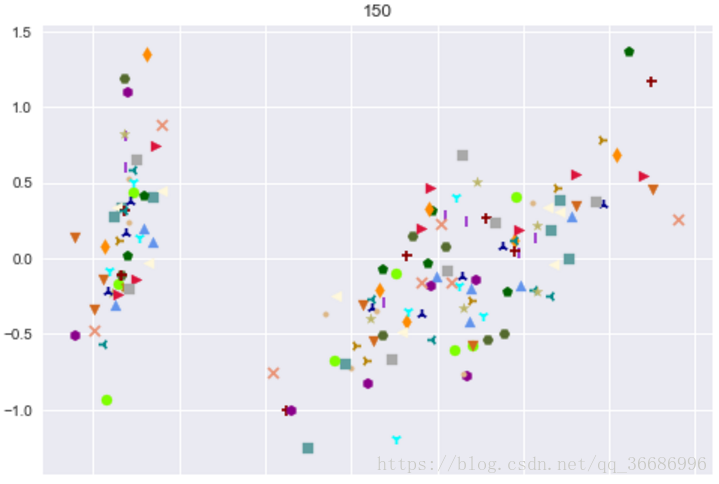
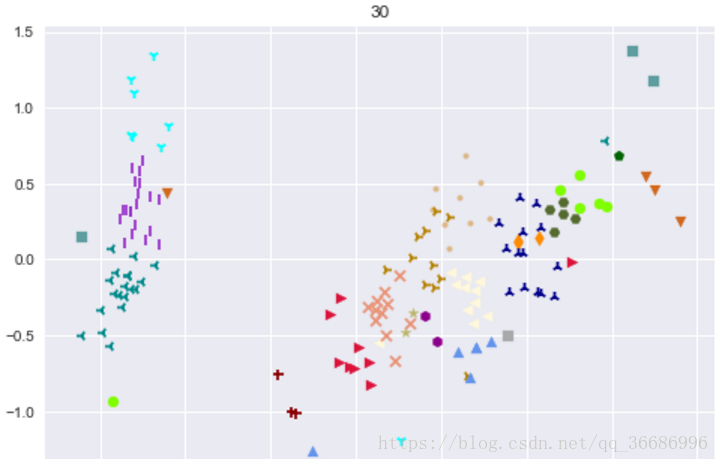
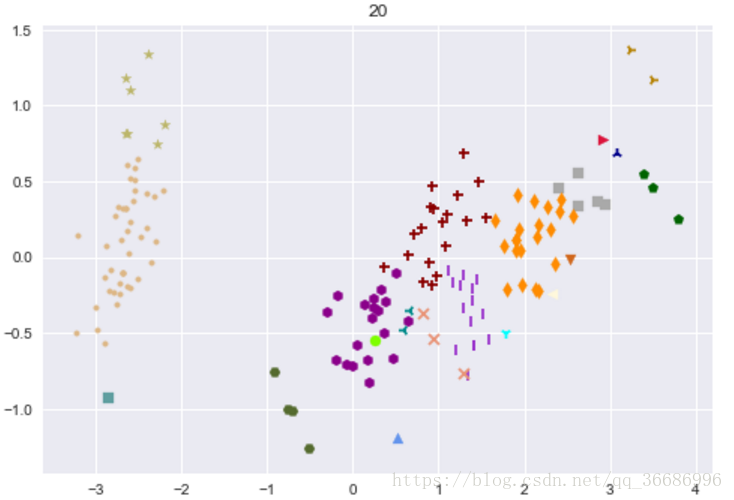
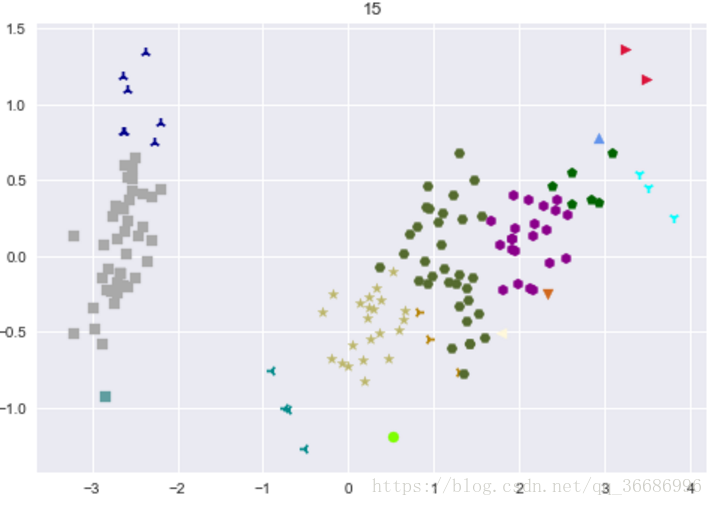
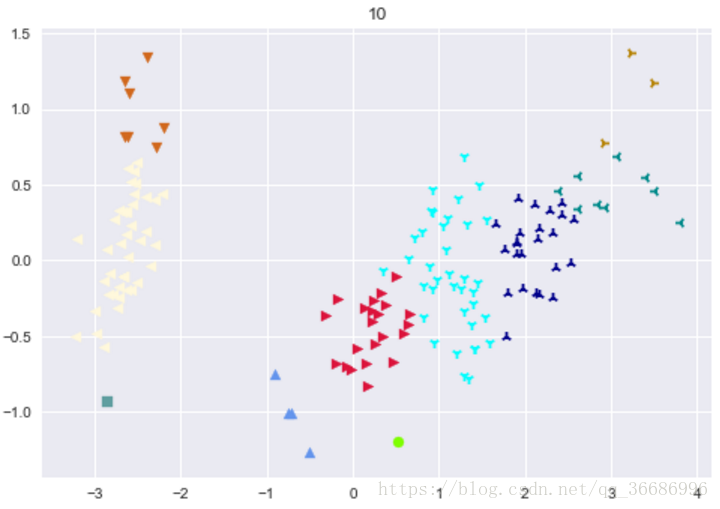
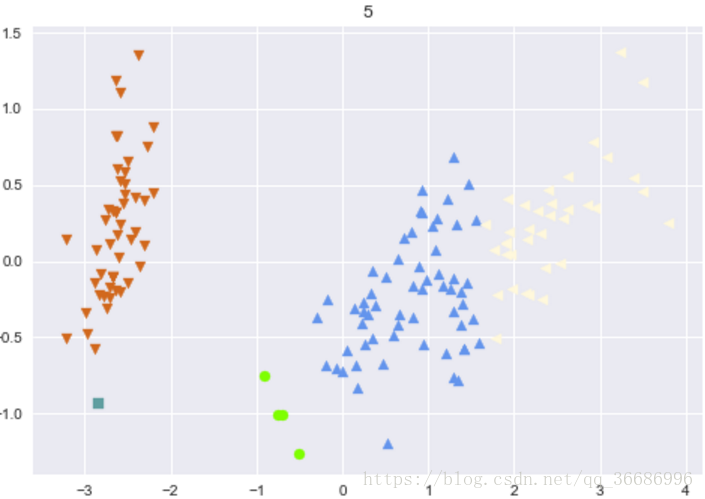
最后分出来的类别:
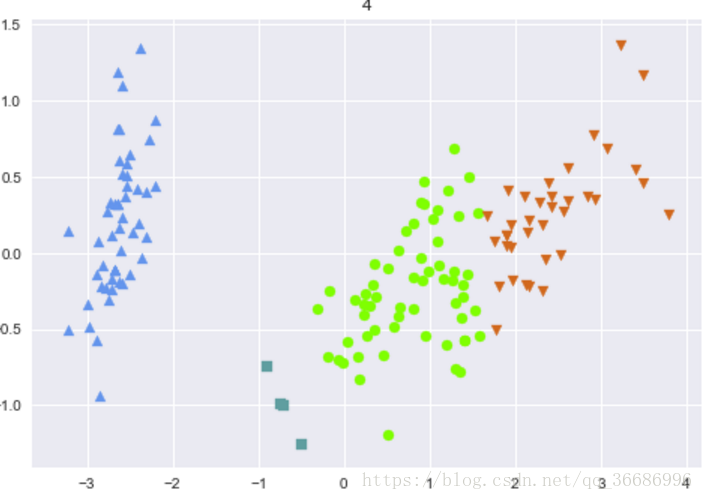
可以看到效果其实很好的,和原分类对比其实差不了多少。随着整个过程下来可以看到分类效果是越来越明显了。其实距离的选择有很多种:

==================================================================================================================================
DBSCAN密度聚类算法:
这种算法的指导思想是只要密度大于某个阈值就把他加入到附近的簇中。不必要知道要多少个分类,可以发现任意形状的簇,包括非凸的,而且都噪音数据不敏感。
密度聚类概念:

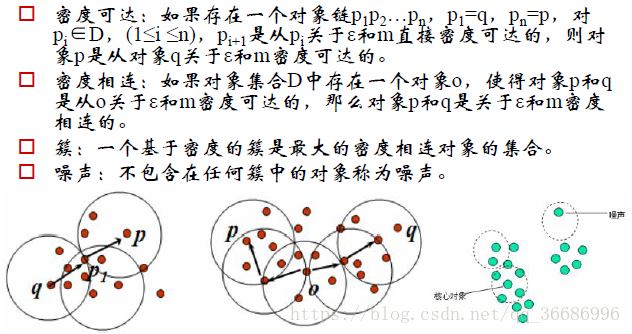
算法流程:
1.如果一个点的领域包括了多于m个点的对象,那么就把他作为一个核心对象。
2.寻找直接密度可达的对象
3.没有更新时结束
包含过少对象的会被认为是噪声。
python实现:
还是使用iris数据集:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import sklearn.datasets as datasets
import math
def get_data():
data = datasets.load_iris().data
dataset = []
for d in data:
d1 = (d[0] , d[1] , d[2] , d[3])
dataset.append(d1)
return dataset
得到数据集。
#计算欧氏距离
def dist(vec1 , vec2):
distance = 0.0
for a, b in zip(vec1, vec2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
pass
计算欧氏距离
def DBSCAN(D, e, Minpts):
#初始化核心对象集合T,聚类个数k,聚类集合C, 未访问集合P,
T = set()
k = 0
C = []
P = set(D)
for d in D:
if len([ i for i in D if dist(d, i) <= e]) >= Minpts:
T.add(d)
#开始聚类
while len(T):
P_old = P
#随机选择一个核心对象
o = list(T)[np.random.randint(0, len(T))]
Q = []
#加入集合
Q.append(o)
while len(Q):
q = Q[0]
Nq = [i for i in D if dist(q, i) <= e]
if len(Nq) >= Minpts:
S = P & set(Nq)
Q += (list(S))
P = P - S
Q.remove(q)
k += 1
Ck = list(P_old - P)
T = T - set(Ck)
C.append(Ck)
return C , P
聚类算法的实现,解释一下主要步骤:
for d in D:
if len([ i for i in D if dist(d, i) <= e]) >= Minpts:
T.add(d)
选择出所有的核心对象。
while len(T):
P_old = P
#随机选择一个核心对象
o = list(T)[np.random.randint(0, len(T))]
Q = []
#加入集合 Q集合是待选择的密度可达核心点
Q.append(o)
while len(Q):
q = Q[0]
Nq = [i for i in D if dist(q, i) <= e]要计算里面的点是不是核心点,因为里面存的不仅仅是核心点,而是核心点周围的点
if len(Nq) >= Minpts:是核心点
S = P & set(Nq)p是没有被选择的点 set(Nq是核心对象周围的点) 那么S就是类别了。
Q += (list(S))重复上诉步骤,看看周围的点哪些是核心对象点,把他周围的点拉进来,在不断扩张
P = P - S选出去了,可以不要了
Q.remove(q)用了 不要了
k += 1
Ck = list(P_old - P)剩下的就是被选取的
T = T - set(Ck)这些核心点已经被用过了,可以丢弃,要不永远都不会结束的
C.append(Ck)分出来的一个类别
上面的注释已经解释的很清楚了。。。。。。
C , P= DBSCAN(data, 0.6, 4)
C是分类,P是噪音点,没有被选择的
接下来就是画图了:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(data)
data2 = pca.transform(data)
def Draw(C):
for c , i in zip(C , range(len(C))):
for s in c:
s = data.index(s)
s = data2[s]
plt.scatter(s[0] , s[1] , color = colors[i])
pass
for i in P:
i = data.index(i)
i = data2[i]
plt.scatter(i[0] , i[1] , color = 'black')
pass
plt.show()
pass
使用的colors颜色是刚刚层次聚类的那个。
Draw(C)
效果:
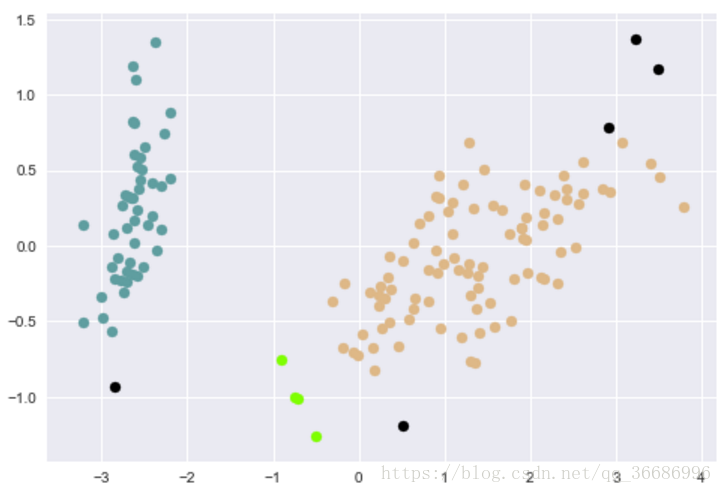
效果其实不够刚刚的好。其实在实现的过程中发现一个很重要的问题,参数选择不好做什么都是假的。一开始不知道怎么选半径和个数,每次出来都是1,最后是上网看了别人用的这个数据才知道选0.6和5的。试一个晚上了,还以为是代码错误。

==================================================================================================================================
谱聚类
谱聚类是一种基于拉普拉斯矩阵的特征向量的聚类算法。

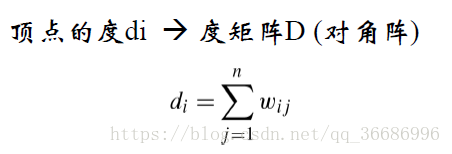


计算过程:

注意在选取特征的时候,要选择前k小的特征,而不是最大的。
原因:

python实现:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import sklearn.datasets as dataset
import seaborn as sns
import math
def pca(data):
pca = PCA(n_components=2)
pca.fit(data)
return pca.transform(data)
def get_data():
data = dataset.load_iris().data
data = pca(data)
return data
data = get_data()
def dist(vec1 , vec2):
distance = 0.0
for a, b in zip(vec1, vec2):
distance += math.pow(a - b, 2)
return math.sqrt(distance)
降维,得到数据,欧氏距离。
def getWbyKNN(data , K):
point_num = len(data)
dis_num = np.zeros((point_num , point_num))
W = np.zeros((point_num , point_num))
for i in range(point_num):
for j in range(i+1 , point_num):
dis_num[i][j] = dis_num[j][i] = dist(data[i] , data[j])
for idx , each in enumerate(dis_num):
index_distance = np.argsort(each)
W[idx][index_distance[1 : K+1]] = 1
tmp_W = np.transpose(W)
W = (tmp_W + W)/2
return W
pass
得到W相似矩阵。首先计算出一个距离矩阵,包含了所以的距离。然后排序,第一个小的点肯定是自己,所以1开始,前k小的设为1,其他的设为0。这时候得到的这个矩阵并一定是对称的,所以加上转置除2来对称化。
#得到度矩阵
def getD(W):
point_num = len(W)
D = np.diag(np.zeros(point_num))
for i in range(point_num):
D[i][i] = sum(W[i])
return D
pass
通过W相似矩阵得到D。
#得到游走拉普拉斯矩阵 I - D-1W
def getLPLSmatrix(W , D):
D = np.linalg.inv(D)
I = np.eye(len(W[0]) , 1)
return (I - D.dot(W))
pass
得到拉普拉斯矩阵
W = getWbyKNN(data , 5)
D = getD(W)
L = getLPLSmatrix(W , D)
之后就是获得特征值特征向量了。
def getEigVec(L,cluster_num): #从拉普拉斯矩阵获得特征矩阵
eigval,eigvec = np.linalg.eig(L)
dim = len(eigval)
dictEigval = dict(zip(eigval,range(0,dim)))
kEig = np.sort(eigval)[0:cluster_num]
ix = [dictEigval[k] for k in kEig]
return eigval[ix],eigvec[:,ix]
eigval , eigvec = getEigVec(L , 5)
得到前5个
最后用Kmeans来计算
clk = KMeans(4)
clk.fit(eigvec)
C = clk.labels_
这是最后得到的标签:
效果差不多吧。
colors = ['r' , 'b' , 'g' , 'y']
markers = ['x' , '^' , '+' , 's']
def draw(data , label):
for i , j in zip(data , label):
plt.scatter(i[0] , i[1] , color = colors[j] , marker=markers[j])
plt.show()
pass
画图:
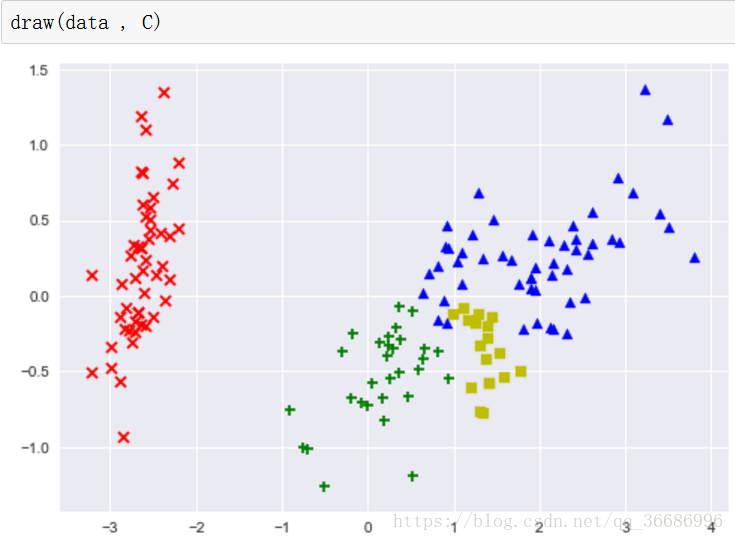
这就是最后的效果了。
总体来说还是凝聚层次聚类好些。还有一些聚类判断指标没有写,等看书了再不全吧,现在还是理论阶段。
还有其他的距离模型,比如som神经网络,GMM高斯混合模型等等,学到在说吧。



