Deep Learning
上一篇主要是讲了全连接神经网络,这里主要讲的就是深度学习网络的一些设计以及一些权值的设置。神经网络可以根据模型的层数,模型的复杂度和神经元的多少大致可以分成两类:Shallow Neural Network和Deep Neural Network。比较一下两者:
| Network Name | Time | complexity | theoretical |
|---|---|---|---|
| Shallow Neural Network | more efficient to train | simple | powerful enough |
| Deep Nerual Network | need more time | sophisticated | more meaningful |
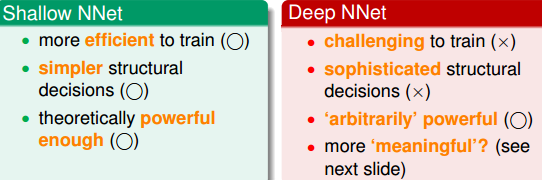
虽然说简单的神经网络训练时间短,但是目前常用的还是deep,因为多层的神经网络有利于提取图像或者是语音的一些特征,取TensorFlow的minist数据集为例,一个手写字体的识别就是需要从图像中提取特征:
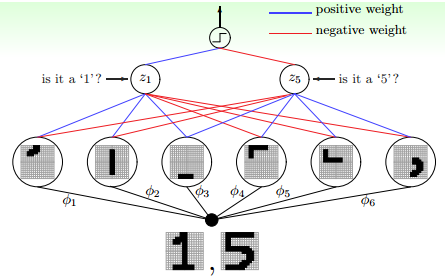
比如想要识别数字1和5,可以把数字的特征分开,每一个不同的神经元识别一部分,然后综合结果。这些都是像素点,所以每经过一层神经元就会从图像中提取特征。再对图片进行匹配和识别。层数越多,就能提取更加复杂的特征,解决一些sophisticated的问题能力也就越强。
①The challenge of deep learning
深度学习的挑战主要有这么几个问题:
1.difficult structural decisions。对于网络结构的设计很难把握,但是这是可以使用一些相关领域的知识来做选择的。比如,做图像的识别,我们可以使用convolutional Network,因为卷积神经网络对于两个相邻的像素联系会很大,也就是说,对于一个像素,如果是用卷积神经网络,那么只会考察它周围的像素点的特征,而离他很远的像素是不会处理。对于语音识别,LSTM,RNN这些神经网络用的就比较多,因为他们可以保留之前的信息。
2.high model complexity。如果网络的层数很多,很可能会出现过拟合的情况,如果是数据量非常大的话,这种情况可以忽略。但如果数据量不大,那么有可能会出现过拟合。常用的解决过拟合的方法:drop out。训练神经网络的时候不全部训练,只是训练一部分,比如训练百分之70.denoising。这种方法后面会详解,主要就是假如一下杂讯一起训练。
3.hard optimization problem。对于神经网络的训练也有很多需要注意的,因为神经网络经过了多层的非线性转换,不再是一个山谷状了,可能是凹凹凸凸的,这样就导致有可能你只是到达了某一个山谷而不是全局的最优。这个时候我们就要选择一个比较好的初始值了,如果我们选择的初始值恰好就是在全局最优的旁边,那就稳了。有一种方法就是pre-train。
4.huge computational complexity。层数这么多,计算机复杂度看到很大。这里已经可以使用硬件解决了,GPU的计算得到。

比较关键的其实就是 regularization和initialization。
②initialization
权值的初始值很重要,好的权值初始化是可以避免局部最优解的出现。比较常用的方法就是pre-train。先用pre-train训练得到一层权值,这些权值就作为初始值,之后在backprob训练。
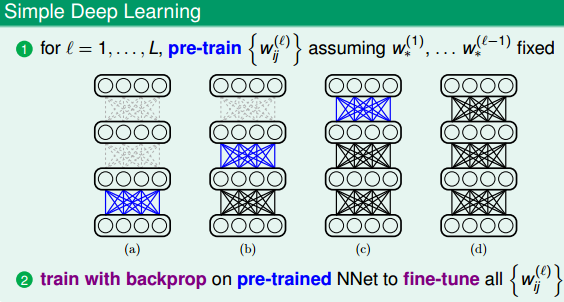
一层一层的来,第一层的出来了第二层的依次决定。
首先要介绍一个概念是 Autoencoder,自编码器。
Autoencoder
什么是权重?在神经网络的模型里面权重代表的就是特征转换(feature transform)。从编码方面来说,权重也可以看成是一种编码方式,把一个数据编码成另一种数据。神经网络是一层一层的进行的,所以如果是一个好的权重的话,是应该可以提取出数据的特征的,也就是information-preserving encoding,一种可以保留有用信息的编码。第i层提取了特征,传到了i+1层,i+1层在i层的基础上再提取一些更加复杂的特征,传到i+2层。最后每一次都可以提取出特征来,这样就可以最大限度的把数据的特征保留下来。上面讲到的手写数字识别是可以把一个数字划分成很多个笔画,反过来,也可以由特征转换回数字。这种可逆的转换叫做information-preserving,通过神经网络转换的特征最后是可以转换回原来的输入,这也正是pre-train要做到的。所以pre-train要满足的特征就是要求information-preserving。因为拿到了特征又可以用得到的特征得到原输入,证明得到的特征是可以代表整个数据的,没有遗漏。
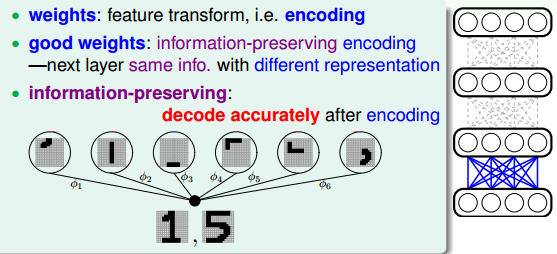
想要得到这样的效果,只需要建立一个三层的神经网络即可。
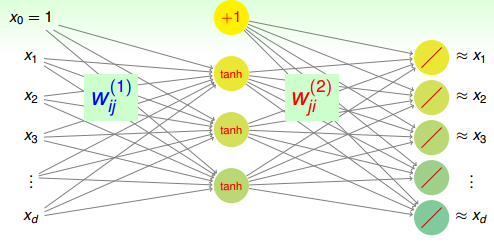
这个神经网络经过权重得到的结果就是encode之后的数据,也就是通过feature transform提取特征的过程,经过
的就是解码过程,要求输出层输出的数据要和原数据差不多接近。整个网络是
的结构,重点就在重构,输入层到隐含层是特征转换,隐含层到输出层是重构。这种结构我们叫autoencode,对应编码和解码,整个过程就是在逼近indentity function(恒等函数)

但是这样好像多此一举,既然输出都是差不多的为什么要多此一举?对于监督式学习,隐藏层其实就是特征转换,乘上一些权值转换成对应特征的值。就好像手写数字识别得到每一个数字的特征,包含了一些提取出有用的特征,可以得到一些数据具有代表性的信息。对于非监督的学习,也可以使用autoencode来做density estimation,密度估计,如果密度较大,说明可以提取到的特征很多,否则就是密度很小。也可以做outlier detection,异常值的检测,也就是孤立点,噪音。找出哪些是典型的资料,哪些不是。

对于编码器,我们更加关心的其实是中间的隐藏层,也就是特征转换权重自然对应的error function:
%20-%20x_i)%5E2)

三层的autoencode也叫basic autoencode 因为它是最简单的了。通常限定方便数字的编码,数据集可以表示为
所以可以看成是一个非监督式的学习,一个重要的限制条件是
解码权重等于编码权重,这起到了regularization的作用。

深度学习中,basic autoencoder的过程也就对应着pre-training的过程,使用这种方法,对无label的原始数据进行编码和解码,得到的编码权重

所以,pre-train的训练过程:首先,autoencoder会对深度学习网络第一层(即原始输入)进行编码和解码,得到编码权重,autoencoder中的d˘应与下一层(即l层)的神经元个数相同。
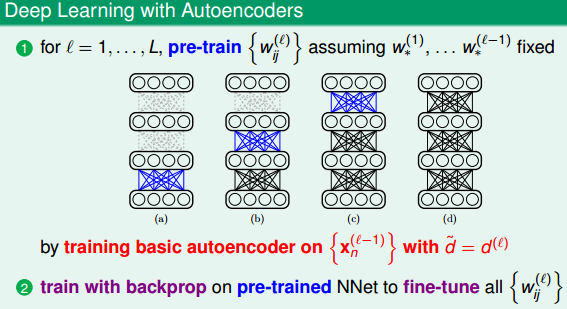
这里介绍的只是一种最简单的,还有很多的编码器,稀疏编码器,去燥编码器等等。
②regularization
控制模型的复杂度就是使用正则化了。
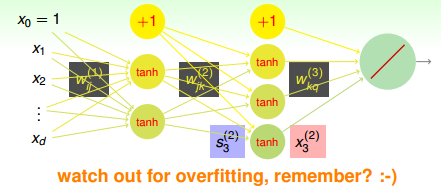
神经网络每一层都有很多的权重和神经元,这就导致了模型的复杂度会很大,regularization是必要的。
我们之前介绍过一些方法:
1.structural decisions。架构可以设计的简单点,但是深度学习神经网络的结构是不可能简单的,这辈子的不可能。只能是相对来说用dropout减轻一些压力。2.weight decay or weight elimination regularizers。可以使用正则化来减小权值。
3.early stop。不要训练的这么准确,差不多差不多就够了。

下面是一种新的regularization的方式:
Denoising Autoencoder
回顾一下之前的overfit的原因:
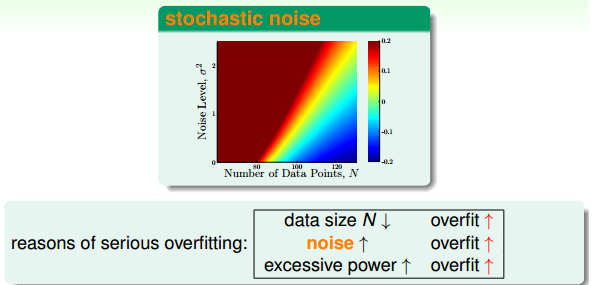
和样本数量,噪声大小都有关系,如果数据量是不变的,那么noise的影响就会非常大。那么这个时候实现regularization的一个方法就是消除noise的影响。
有一种方法是对数据clean操作,但是这样费时费力。有一种更加牛逼的做法,就是在数据中添加一些noise再训练。

这种做法的初衷是想建立一个比较健壮,容错性高的autoencode。在一个已经训练好的autoencode中,g(x) ≈ x的,对于已经容错性很高,比较健壮的autoencode,得到的输出是和x很接近的。比如手写数字识别,一个很规范很正的6输进去可以得到一个6,但是如果原始的图片是歪歪的6,然后还是可以得到6的话那么这个自编码器就是一个健壮的自编码器了。比较不是每一个人写6都是写的正正,这就使得这个自编码器的抗噪能力很强。
所以,最后我们要训练的样本集%2C(x_2'%2Cy_2%20%3D%20x_2)%2C(x_3'%2Cy_3%20%3D%20x_3)......)
其中
所以使用这种autoencode的目的就是使得加入了有噪音的x都可以得到纯净的x。不仅能从纯净的样本中编解码得到纯净的样本,还能从混入noise的样本中编解码得到纯净的样本。这样得到的权重初始值更好,因为它具有更好的抗噪声能力,即健壮性好。实际应用中,denoising autoencoder非常有用,在训练过程中,输入混入人工noise,输出纯净信号,让模型本身具有抗噪声的效果,让模型健壮性更强,最关键的是起到了regularization的作用。这也是之前说的去燥自编码器。

linear autoencode
刚刚介绍的自编码器是非线性的,因为中间的tanh(x)函数就是非线性的。常见的autoencode常用于在深度学习中,这里要介绍的是线性的自编码器,linear autoencode。对于一个线性的自编码器,只需要不包括非线性转换就好了。
所以,就变成
这里有三个限制条件:
①移除bias项,保持维度一致。
②编码权重与解码权重一致:
③
由于两个权重是一样的,W的维度是dxd',x的维度是dx1,所以整个公式可以变为:
但是要求
所以error function
对于那个协方差矩阵首先可以进行特征值分解其中Γ是一个对角矩阵,V矩阵满足
而I矩阵有一个很重要的性质,由于W是dxd'的,d < d’。有I的非零元素的数量是不大于d'的。
证明
对于一个矩阵W(dxd',d < d'),那么有Rank(W) <= d'。这个结论直接给出,不用证明。假设有两个矩阵A,B,C = AB,那么AX = C的解就是B,也就是唯一解,也就是说Rank(A, C) = Rank(A )。证明:对于Rank(A,C)和Rank(A)无非就是两种情况,=和>。<是没有的,Rank(A)是不可能大于Rank(A,C)的。如果是Rank(A) < Rank(A,C),那么这个增广矩阵(A,C)变换成初等矩阵之后,最后一行就会出现
的情况,0 != a,自然就是无解了。所以证明了上诉情况一定是有Rank(A) = Rank(A,C)
而由于R(C) <= R(A,C),所以R(C) <= R(A),同理,也可以证明得R(C) <= R(B),而在这里所以,
是不大于d'的,因为一个矩阵的秩是不可以大于它最小的维度的。
综上所诉,
更重要的是,秩就是这个矩阵特征值的数量,而I矩阵的斜对角线就是WW^T矩阵的特征值,所以才有I的非零元素的数量是不大于d'的。
回到正文。那么就可以推出

这样就把表达式转换成了一个求解V和Γ的方程:
所以第一个要解决的就是

到这里Γ的最优解已经知道了
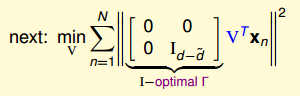
最小化问题有点复杂,转换一下:
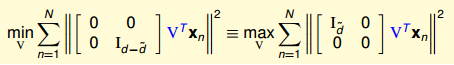
当d' = 1的时候,那就只有V的第一行是有用,所以
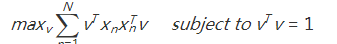
条件是在做特征分解的时候得到的,这里也要继承下来。
有条件的自然是拉格朗日乘子法了:
求导得0
仔细看一下,这个λ其实就是
既然d' = 1是这样了,那么当d' > 1的时候,就是依次把d'个特征值求出来就好了,所以这个就是linear autoencoder的过程了。

过程和PCA很相似,大致都是差不多的,但是PCA还需要减去一下平均值,也就是对x输入数据做去均值化的处理。


linear autoencode和PCA不完全一样,至少出发点不是一样的,linear autoencode是用来pre-train而被发明的,虽然机器学习不太需要,但是既然引出了非线性的autoencode那顺便把linear也探讨一下。但是,linear autoencode在公式的推导上是基本一致的,上面的推导其实也是可以做为PCA的推导。
Dimensionality Reduction——Principal Component Analysis
既然讲到了降维,那顺便把PCA也讲了,Deep Learning的部分已经讲完。
①数据降维
通常我们得到的数据有很多的维度,比如一个商店,可以有名字,年龄,出生日期,性别,成交量等等。而年龄和性别其实是表示一个东西,两个表示完全是多余的。当然我们也可以直接不做处理就使用这些数据来做机器学习。但是这样会耗费巨大的资源。在这种情况下自然就需要数据降维了。降维意味着会有数据丢失,丢失是一定会有的,所以只能保证丢失了多少而已。
举个例子,假如某学籍数据有两列M和F,其中M列的取值是如何此学生为男性取值1,为女性取值0;而F列是学生为女性取值1,男性取值0。此时如果我们统计全部学籍数据,会发现对于任何一条记录来说,当M为1时F必定为0,反之当M为0时F必定为1。在这种情况下,我们将M或F去掉实际上没有任何信息的损失,因为只要保留一列就可以完全还原另一列。
②向量和基
先看一个向量的运算:
这种乘积方式并不能看出有什么意义,换一种表达方式a为A和B的夹角。再进一步|B| = 1,那么就可以看出来,当向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度。这个结论很重要。
假设有一个点(3,2),那么在坐标系中的表示:
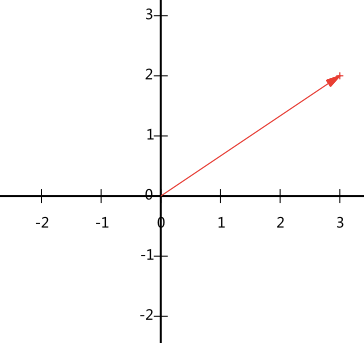
向量(3,2)就从原点发射到(3,2)这个点的有向线段。在x轴上的投影值是3,在y轴上的投影值是2。也就是说我们其实隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。所以向量(x,y)实际上是一种线性组合:
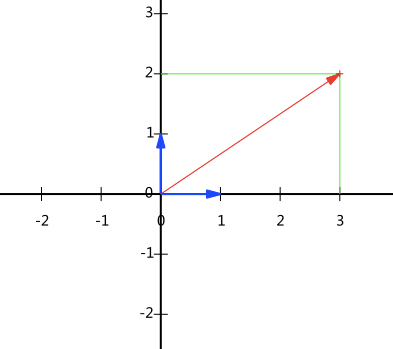
所以,可以用另外一种方法来描述,确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。不过一般直接忽略第一步,比较可靠维度就知道了。但是事实上,基并不是一个固定的东西,任何一个线性无关的向量都可以成为一组基。例如,(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了。
③基变换的矩阵表示
还是拿上面的(3,2)做为例子,比如我们现在有两个基
那么把(3,2)变为新的基上的坐标,则有
所以,一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
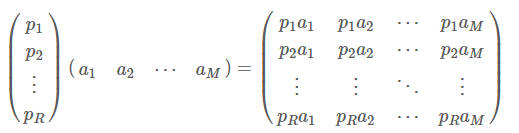
这里是R是要变换的维度,R是可以小于N的。 基于以上的理论,两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去
④协方差
上面讨论了基已经坐标基于基的变换,如果基的数量是小于数据维度的就可以达到降维的效果了。但是,问题来了,基是无限多个的,如何选择基是一个很大的问题。
举一个例子:为了处理方便,首先先减去每行的均值,这样做的原因后面再说。减去之后就是这样:
问题来了,这5个数据都是2维度的,现在想降到一维,如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
一种直观的看法是:希望投影后的投影值尽可能分散。同一个维度数据之间不"挤"在一起,因为挤在一起表达不了数据本身了。而表征数据之间离散程度,就考虑到了方差。具体做法就是 想办法让高维数据左乘一个矩阵,得到降维后的数据,降维后的数据的方差最大化。在线性代数中学过,一个矩阵可以看成是很多个列向量,每一个向量代表着一个物体的数据。要表达这个矩阵真的需要这么多数据吗,显然不一定,求解一个矩阵的秩R,看看R 的值,在绝大多数情况下,矩阵都不是满秩的,说明矩阵中的元素表达客观世界中的物体有一些是多余的。
既然是求离散程度,那么就是方差了,对于每一个字段的方差如果已经去除了均值那就可以直接转换
对于上面二维降成一维的问题来说,找到那个使得方差最大的方向就可以了。不过对于更高维,还有一个问题需要解决。考虑三维降到二维问题。与之前相同,首先我们希望找到一个方向使得投影后方差最大,这样就完成了第一个方向的选择,继而我们选择第二个投影方向。但是如果第二次还是坚持选择方差最大的方向,那么肯定还是会和第一个方向相同的,这样表达的信息很有可能重合,所以应该要加上一些限制。从直观上说,让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,因为相关性意味着两个字段不是完全独立,必然存在重复表示的信息。
事实上两个字段的相关性是可以用协方差来表示。协方差为0的时候,两个字段是互相独立的。协方差为0所以只能在一个基的正交方向选择第二个基。将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
⑤协方差矩阵的优化
协方差矩阵的对角线代表了原来样本在各个维度上的方差,其他元素代表了各个维度之间的相关关系。所以我们需要把协方差对角化,因为我们需要处理的就是维度中的关系,而不是维度之间的。设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,则有:
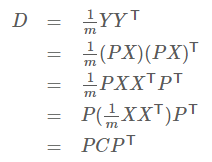
所以现在明白了,我们要找的P就是使得可以对角化C的矩阵,最后按照得到的对角矩阵从大到小排列,取P的前k行作为基进行转换即可。这其实就是求解特征值的过程。
总结:一开始对数据进行降维操作,我们想到的就是要使得数据投影之后方差最大,那么就需要寻找一组基使达成这个条件。但是发现如果只是找最大的方差是会有重复,比如第一个发现的基是最大的,那么第二个方向肯定也差不多是这个方向,这样信息就有重复,所以又相当数据维度之间是应该有非相关性的,于是就使用到了协方差来代表,但是我们需要的是数据里的非相关性最大化,数据间的最大化方差最大已经处理了,所以这个时候协方差只需要关注对角线,自然就是对角化了。又发现对角化其实就是特征分解的一个过程,最后求出结果。
另一个方面,W我们可以看做是基的组合,WX就是降维之后的数据就是要求了降维之后的数据要和原来的数据相差不远,为什么不是X-WX呢?首先这两个东西不是同纬度的,不可能计算,其次乘上一个转置其实就是转换回来的结果了。如果压缩之后转换回来的结果和原来差不多,那不就证明了这个降维是OK的吗?所以这就和Autoencode的思想一样了,所以上面linear autoencode的过程也可以看做就是PCA的公式化推导。
⑤PCA算法过程:
①将原始数据按列组成n行m列矩阵X
②均值化操作。
③求协方差
④求特征值特征向量
⑤排列取前k大的特征值对应的特征向量
⑥降维操作
Coding
Autoencode
编码器有几个很重要的特征:
①编码器是数据相关的,这就意味着只能压缩那些和训练数据相关的数据,比如用数字的图像训练了然后有跑去压缩人脸的图片,这样效果是很差的。
②编码器无论是训练多少次,都是有损的。
③自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作
Tool
先介绍一下工具类:
import numpy as np
from keras.datasets import mnist
import matplotlib.pyplot as plt
def get_dataSets():
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32')/255.
x_test = x_test.astype('float32')/255.
x_train = x_train.reshape(len(x_train), np.prod(x_train.shape[1:]))
x_test = x_test.reshape(len(x_test), np.prod(x_test.shape[1:]))
return x_train, x_test
pass
首先是引入数据,mnist.load_data()这个数据导入有点问题,上网百度了一下发现百分之90的博客都是有问题自己下的,所以不例外我也是自己下载了4个压缩包放在了当前目录data下面。
得到数据时候先进行归一化操作,然后reshape,因为后面一开始用到的是单层的编码器,用的全连接神经网络,所以应该变成是二维的数据。
def show(orignal, x):
n = 10 # how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(orignal[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(x[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
这个函数用于显示,传入的参数是原始图像和预测的图像。好像都蛮直观的。
虽然每一种编码器都是用了一个类来封装,但是每一个只有应该create方法,返回一个已经训练好的autoencode,所以下面所有的代码都是在create里面。
①单层自编码器
单层自编码器就是之前说的最简单的base autoencode。使用Keras实现。
全部都封装在一个类里面,用类的create函数返回一个已经训练好的autoencode。使用的数据集是mnist数据集。
def create(self):
x_train, x_test = get_dataSets()
encoding_dim = 32
input_img = Input(shape=(784,))
得到数据,隐藏层神经元的数量,入口函数。
encoded = Dense(encoding_dim, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
编码层,最后那个小括号里面(input_img)就是输入的内容了,解码层就是从encoded输入。Dense里面定义的是当前层的神经元,decoded层输出了,自然就是784 = 28 x 28个了。
autoencoder = Model(input=input_img, output=decoded)
encoder = Model(input=input_img, output=encoded)
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(input=encoded_input, output=decoder_layer(encoded_input))
接下来的这几个就是得到完整的模型,使用Keras的Model API来构建。下面的几个就是encoder得到编码层,得到解码层。都很直观。
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test))
return autoencoder, encoder, decoder
之后就是模型的编译,模型的训练了。
最后的效果:
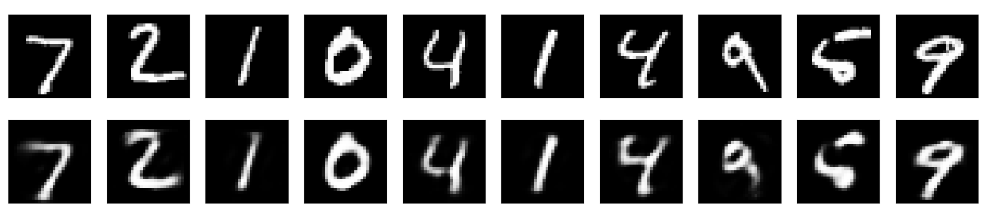
事实上还是可以的,达到了要求。
②多层自编码器
其他差不多一样,就是多了几层。
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(encoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(decoded)
autoencoder = Model(input=input_img, output=decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=1,
batch_size=128,
shuffle=True,
validation_data=(x_test, x_test))
中间那几层得到编码层的那些去掉了。最后看看效果。
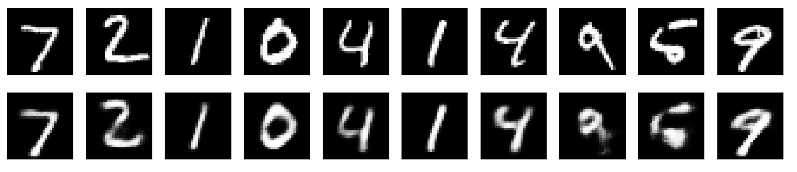
损失函数这些就不放了,因为训练的话是很容易给出的。
③稀疏自编码器
稀疏自编码器一般用来学习特征,以便用于像分类这样的任务。稀疏正则化的自编码器必须反映训练数据集的独特统计特征,而不是简单地充当恒等函数。以这种方式训练,执行附带稀疏惩罚的复制任务可以得到能学习有用特征的模型。使用L1范式惩罚项就好了,但是效果不太好,就不放结果了。
encoded = Dense(encoding_dim, activation='relu',
activity_regularizer=regularizers.l1(10e-5))(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
④卷积自编码器
其实就是卷积神经网络做编码而已。
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test),28, 28, 1))
数据格式要正确,因为是卷积处理了,要按照(个数,长,宽,颜色)排列。
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(16, (3, 3), activation='relu', border_mode='same')(input_img)
x = MaxPooling2D((2, 2), border_mode='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', border_mode='same')(x)
x = MaxPooling2D((2, 2), border_mode='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', border_mode='same')(x)
encoded = MaxPooling2D((2, 2), border_mode='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', border_mode='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', border_mode='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(16, 3, 3, activation='relu')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, (3, 3), activation='sigmoid', border_mode='same')(x)
encode和decode是两个对应的东西,反着来而已,由于是一个图片一个图片的进来,所以输出就是一个。
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train, epochs=20, batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
return autoencoder
最后就是常规操作了。
这个训练时间有点长,电脑不行没办法。效果:
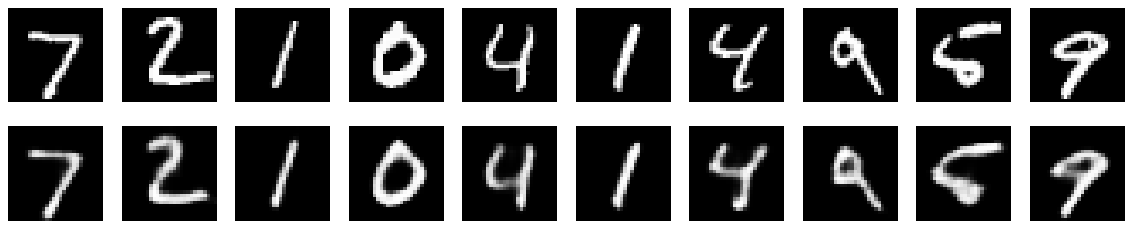

最后损失到了0.10,还是很好的。
⑤去噪编码器
这个是在卷积神经网络的基础上做的。用带噪音的数据来训练。
def get_nosing(noise_factor):
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
noise_factor = noise_factor
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
return x_train, x_train_noisy, x_test, x_test_noisy
pass
时间就是使用高斯分布来得到了。
x_train, x_train_noisy, x_test, x_test_noisy = get_nosing(0.5)
input_img = Input(shape=(28, 28, 1))
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(input_img)
x = MaxPooling2D((2, 2), border_mode='same')(x)
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(x)
encoded = MaxPooling2D((2, 2), border_mode='same')(x)
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(encoded)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(32, 3, 3, activation='relu', border_mode='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(1, 3, 3, activation='sigmoid', border_mode='same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train_noisy, x_train, shuffle=True,epochs=1, batch_size=128,
validation_data=(x_test_noisy, x_test))
return autoencoder


PCA
PCA就不用mnist数据集了,毕竟784维降到2维不是很好看,使用iris数据集。
获取数据那些就不写了,毕竟蛮简单的。
class pca(object):
def fit(self, data_features, y):
data_mean = np.mean(data_features, axis=0)
data_features -= data_mean
cov = np.dot(data_features.T, data_features)
eig_vals, eig_vecs = np.linalg.eig(cov)
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:, i]) for i in range(len(eig_vals))]
a = np.matrix(eig_pairs[0][1]).T
b = np.matrix(eig_pairs[1][1]).T
u = np.hstack((a, b))
data_new = np.dot(data_features, u)
return data_new
def show(self, data_new):
plt.scatter(data_new[:, 0].tolist(), data_new[:, 1].tolist(), c='red')
plt.show()
pass
步骤其实很简单,均值化求特征值排序组合向量基对原数据做乘法。
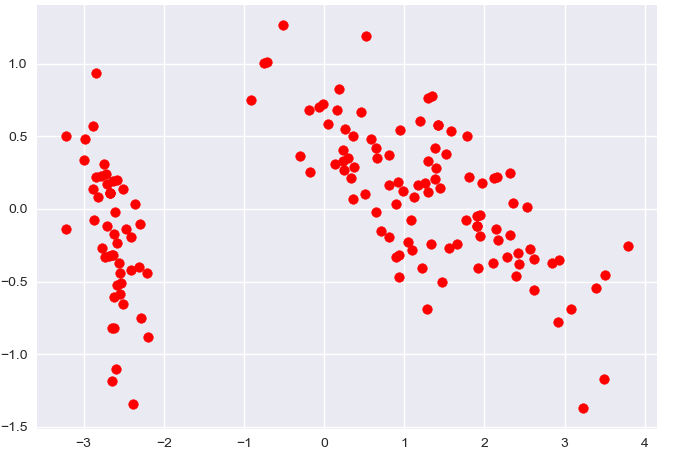
最后降维效果。
最后附上GitHub代码:https://github.com/GreenArrow2017/MachineLearning/tree/master/MachineLearning/Autoencode






