①linear regression
target function的推导
线性回归是一种做拟合的算法:
误差
上面的
可以看做是一个误差,这个误差满足高斯分布,服从均值为0,方差为
的高斯分布,也就是高斯分布。因为求出来的拟合数值不是一定就准确的,肯定会有一些的误差。
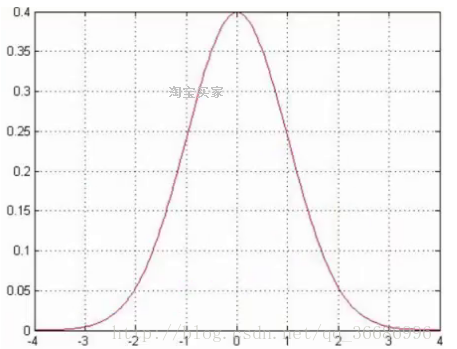
一般误差不会太多,都是在0上下浮动的,所以0附近是最高的概率。
使用linear regression要满足三个条件:
1.独立,每一个样本点之间都要相互独立。
2.同分布,他们的银行是一样的,使用的算法是一样的。
3.误差都服从高斯分布。
由于误差是服从高斯分布的,自然有:
上述式子有:
需要求参数,自然就是最大似然函数:
log化简:
最大化这个似然函数那就是最小化。因为前面都是常数,可以忽略。而这个式子稍微变一下就是最小二乘法了。
最小二乘法:,不用上面化简出来的式子非要加上
是因为求导之后2是可以和0.5抵消的。
目标函数的化简
化简一下:
求极小值,直接就是导数为0即可,所以对求导数即可。
直接令等于0:。
这样就是得到了最终的目标函数,一步就可以到达最终的optimal value。这就是linear regression。所以线性回归是有解析解的,直接一条公式就可以求出来的。注意上面的公式的
是不包含bias偏置值,偏置项就是误差,代入高斯函数推导出来的。
②logistic regression
target function 的推导
首先要提一个函数,sigmoid函数:
这个函数之前被用来做神经网络的激活函数,但是它有一个缺点。
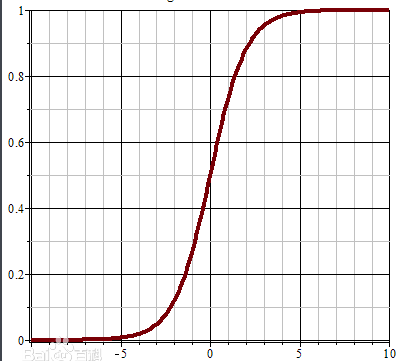
这样的两个的式子对于求导和化简都不好,所以合并一下:
目标函数的化简
最大似然函数,常规操作,给定了数据集找到符合这个数据集的分布一般也就是最大似然函数适合了。所以
log化:
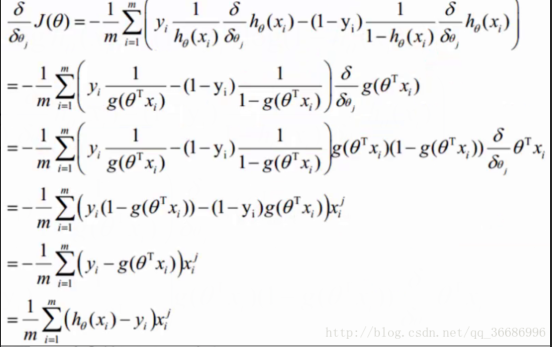
这个方法就梯度下降,问题来了,为什么要用梯度下降?为什么不可以直接等于0呢?
logistics regression没有解析解
如果等于0,就有:
考察一下两个特征两个样本的情况:
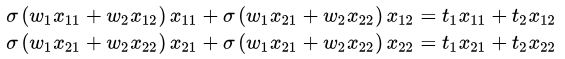
有三个不同的sigmoid函数,两个式子解不了,因为sigmoid函数不是线性的,如果是线性的,那么可以吧提出来,这样就有解了。其实如果sigmoid去掉,仅仅把
那么就和linear regression一样了。所以是没有解析解的,主要的原因就是因为sigmoid函数是一个非线性的函数。
当标签不同的时候另一种函数形式
计算分数函数一样的:
之前了解的preceptron:
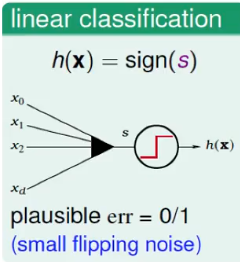
直接把score分数通过一个sign函数即可。0/1错误。
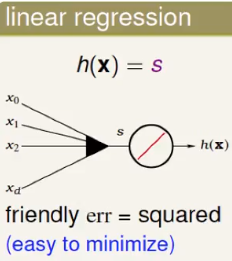
linear regression:
logistic regression:
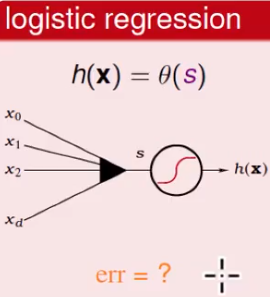
常规操作,就是要找到error function先。按照刚刚的函数分布可以得到:
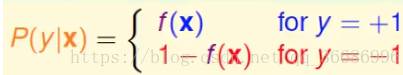
极大似然函数:
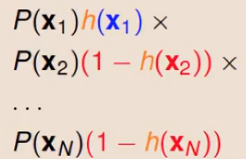
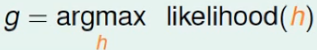
sigmoid函数有一个比较牛逼的性质。
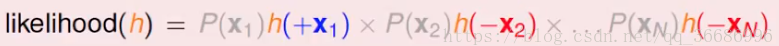
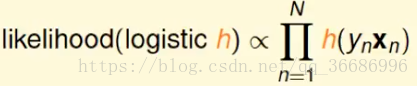
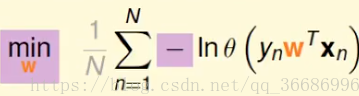
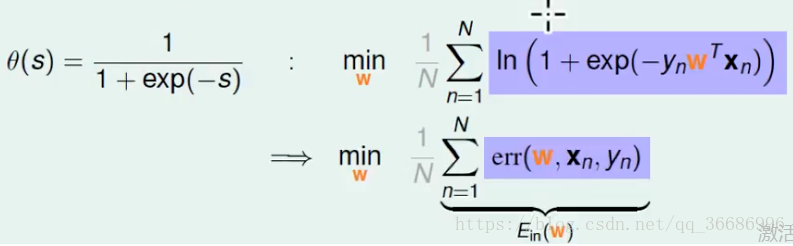
其实这个就是交叉熵函数,和上面推导出的:
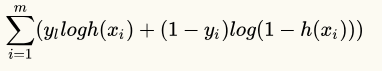
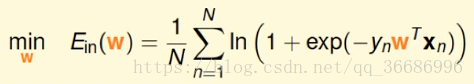
gradient decent,和刚刚的方法是一样的。
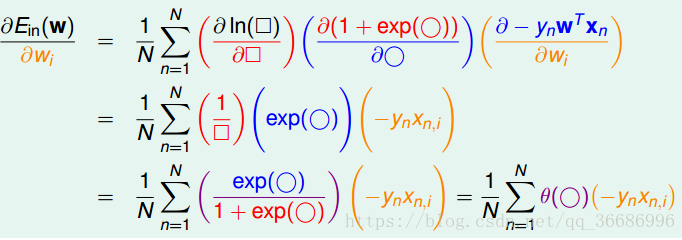
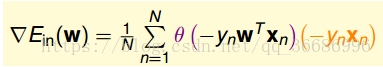
上面的
Stochastic Gradient Descent
随机梯度下降,以往的经验是全部一起做一次更新,如果计算量非常大,那么计算复杂度很高,另外如果是做online learning的时候也不方便,因为这个时候数据不是一个betch的过来了,而是几个几个的了。

优点:简单,如果迭代次数够多的话是可以比得上average true gradient的效果的。
缺点:迭代的方向会不稳定,可能会左拐右拐的。average true gradient是查找的当前一阶导最适合的方向走的,而SGD是直接随机一个方向走。

他和PLA其实很像,而在理解上面其实也是类似,他们都选取一个点进行调整。而SGD ≈ soft PLA,PLA是错了之后才纠正,而SGD会看下你错了多少,错了越多,意味着你的wx越大,所以纠正的越多,是动态可变的,所以也叫做soft PLA。
③线性模型error function的对比
三个比较简单算法:PLA,linear regression,logistic regression。他们勇于分类的时候:

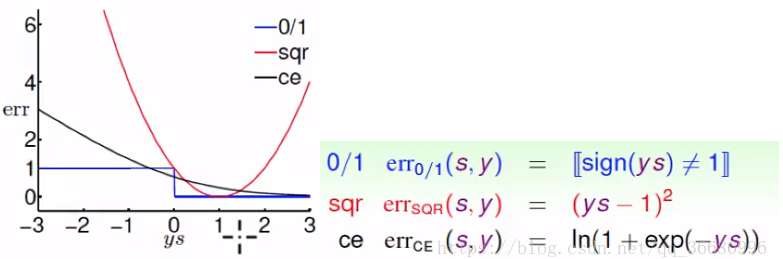
square function对于分类来说其实不太合理的,分类正确了,应该越远越好才对,但是square function是越远错误就越大,是不合理的,logistics就更合理了,错误的越错就越大正确的就小,所以linear regression适合回归而不是分类。
可以看到ce和err0/1是有焦点的,我们乘上一个数字使他相切:

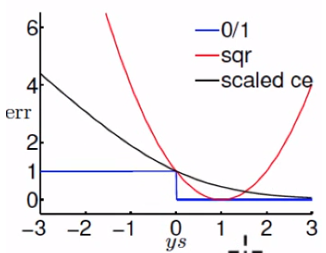

根据VC bound的理论:

所有logistic regression是可以作为分类的,而且他的分类效果要比linear regression好,首先直观理解错误,他比linear regression更合理,其次,他的VC bound比linear regression要小,这就证明了Ein ≈ Eout的概率会更高,泛化能力更强。
④Nonlinear Transformation
对于线性可分的情况来说,几乎是不用对x做什么预处理就可以直接使用模型进行分类,但是如果是对于非线性的模型,上面的方法就有点吃力了,他们都是线性分类,直接在model上改进有点困难,所以在数据上进行处理。

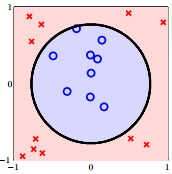
把上面的式子变成我们认识的形式:
于是决策函数:
其实就是把x空间映射到了z空间,然后再z空间解决。x里面是nonlinear的,映射到z可能就会是linear的了,低纬度解决不了的问题拉到高维度解决:

支持向量机也用到了这种思想,核函数就是映射到高维度空间里面然后进行切片操作。
Nolinear Transformation的方法不止一个:

目前我们所讨论的都是过原点的,如果是不过原点的话,那么他们的VC dimension就会增加。比如这种
其实,做法很简单,利用映射变换的思想,通过映射关系,把x域中的最高阶二次的多项式转换为z域中的一次向量,也就是从quardratic hypothesis转换成了perceptrons问题。用z值代替x多项式,其中向量z的个数与x域中x多项式的个数一致(包含常数项)。这样就可以在z域中利用线性分类模型进行分类训练。训练好的线性模型之后,再将z替换为x的多项式就可以了。具体过程如下:
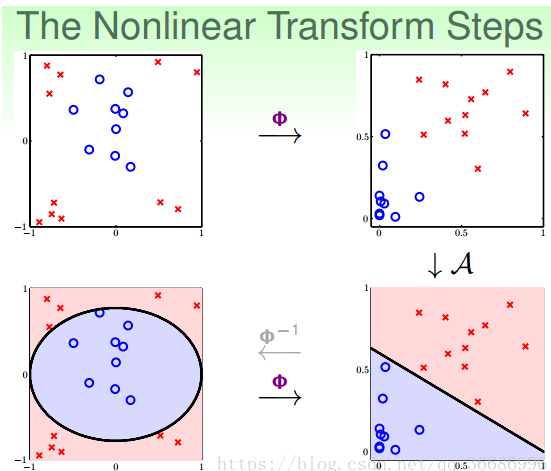
整个过程就是通过映射关系,换个空间去做线性分类,重点包括两个:
特征转换
训练线性模型
Price of Nonlinear Transform
首先,用十二指肠想都知道:
如果是d维的x做二次的扩展,那么有
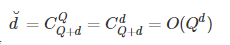

接下来讨论一下x到z多项式的变换:
一维:
二维:
三维:
Q维:
所以这些hypothesis是包含关系的:
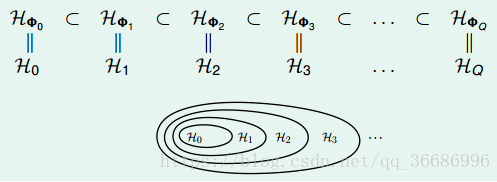
对应上图:
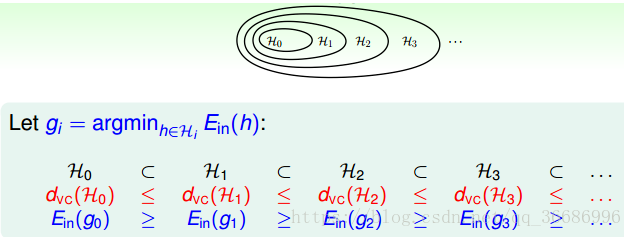
所以一目了然,代价就是
⑤Overfitting and Regularization
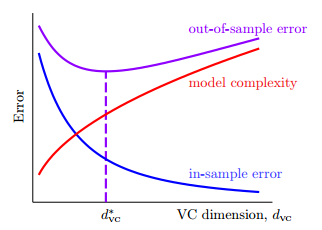
overfiting,过拟合,就是上面所描诉的情况了,和
相差太远了,局部已经不能再代表全局了,主要原因就是模型复杂度太大了,VC bound太大,限制不了
。overfitting就是训练过程中翻车了,原因:①太快了,模型复杂度太大。②近视,看的路太短,样本少。③这路不行,弯弯曲曲的,noise太多,噪音太大。
对应的解决方法其实很多,但主要就是regularization了:
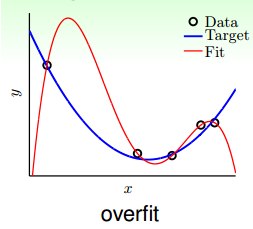
虽然fitting出来的结果完全符合了数据点,但是模型本身没有这么复杂,所以产生了过拟合。
既然模型太复杂了,那么简化一下模型:
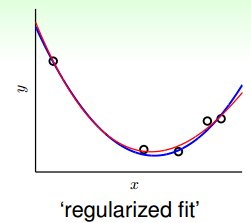
所以过拟合了,我们可以简化复杂度,复杂度的代表系数其实就是VC dimension,也就是W的个数。比如一个十阶的hypothesis:
想简化模型就只需要减少w的个数即可,比如简化成2阶:
刚刚是规定了前面的不为0,现在放宽一下条件,只要3个w不为0就好了,于是有:
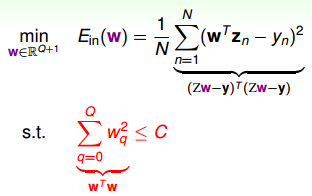
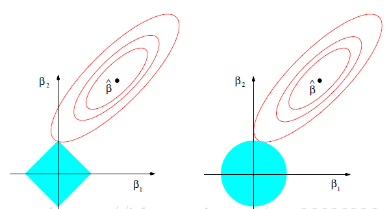
这样就把W限定在了一个以根号C的一个球形里面,两个W才是一个圆,多个w就是立体的球了。

这种线性回归被看成是origin linear regression的进阶版,也叫ridge regression。
上面的公式也可以直接用拉格朗日乘子法推出来:
拉格朗日:
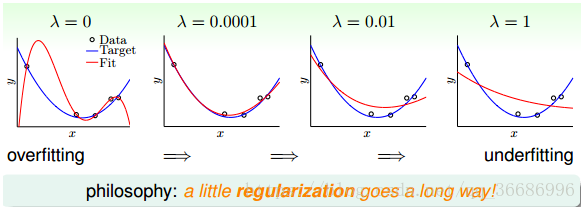
对于regularization的VC 理论解释
正则化出来过后的linear regression就是ridge regression,根据之前的VC bound理论:,其中
是复杂度,
代表的是单个hypothesis的复杂度,而
代表的整个hypothesis set的复杂度,所以
是被包含在
里面的,所以相对来说
,相对来说会和
更加接近。

General Regularizers
两个比较常用的:
ridge:L2范数,
lasso:L1范数,
ridge推导过了,来看看lasso的:
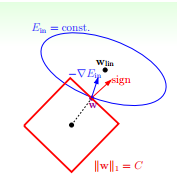
他的正常方向应该是垂直于边界的,红色的sign就是方向,而对于在边界上,只要sign和△Ein不在一条直线上,那么在正方形的边界上就一定有一个类似于刚刚ridge绿色分量的分量存在,如上图,就会向上方移动,而在边角点其实是不可微分的,所以一般结果会聚集在边角的周围,所以得到的是一个稀疏矩阵,一些是0,一些不是零。结果会聚集在顶点周围,优点就是计算很快了。
上图是用直观的理解来解释regularization,前面的是用VC demension来解释,再用数值分析的角度看一下:
比如:方程式①:
5x + 7y = 0.7
7x + 10y = 1
x = 0 , y = 0.1
方程式②:
5x + 7y = 0.69
7x + 10y = 1.01
x = -0.17 y = 0.22
只要有一点微小的扰动,结果就会发生很大的变化,这就是病态矩阵,如果
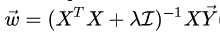
加上一个对角线的值其实就是远离奇异矩阵。
最后再看一个图:
summary
加入正则项是为了避免过拟合,或解进行某种约束,需要解保持某种特性
①L1正则可以保证模型的稀疏性,也就是某些参数等于0,L1正则化是L0正则化的最优凸近似,比L0容易求解,并且也可以实现稀疏的效果,
②L2正则可以保证模型的稳定性,也就是参数的值不会太大或太小.L2范数是各参数的平方和再求平方根,我们让L2范数的正则项最小,可以使W的每个元素都很小,都接近于0。但与L1范数不一样的是,它不会是每个元素为0,而只是接近于0。越小的参数说明模型越简单,越简单的模型越不容易产生过拟合现象。
③在实际使用中,如果特征是高维稀疏的,则使用L1正则;如果特征是低维稠密的,则使用L2正则。
④L2不能控制feature的“个数”,但是能防止模型overfit到某个feature上;相反L1是控制feature“个数”的,并且鼓励模型在少量几个feature上有较大的权重。
总结一下之前学过的,第十八篇博客VC dimension是机器学习的理论保证:

霍夫丁不等式保证了一个hypothesis发生坏事的概率是很小的,Multi霍夫丁不等式保证了这个hypothesis set对于所有的数据集发生的坏事的概率满足的不等式,VC dimension则保证了这个hypothesis set里面发生的坏事的概率是很小的,这就保证了泛化能力:Ein ≈ Eout。
之后介绍了三种线性模型(PLA比较简单,不会再讲了):
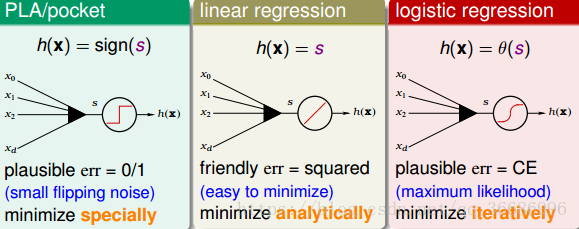
而对于这三种模型,我们又给出了三种工具:

Feature Transform:通过低维不可线性可分转换到高维线性可分来解决Nonlinear的情况。
Regularization:通过增加正则化惩罚项来解决过拟合的问题。
Validation:用于对模型参数的选择,第一次选择:是选择上面模型。第二次选择就是对模型参数的选择了,这就用Validation来帅选。
最后是三个比较常用的锦囊妙计:

⑥logistics regression代码实现
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
def predict(w, x):
h = x * w
h = sigmoid(h)
if h > 0.5:
return int(1)
else:
return int(0)
def sigmoid(x):
return np.longfloat(1.0/(1+np.exp(-x)))
def error_rate(h, label):
m = np.shape(h)[0]
sum_err = 0.0
for i in range(m):
if h[i, 0] > 0 and (1-h[i, 0]) > 0:
sum_err += (label[i, 0] * np.log(h[i, 0]) + (1-label[i, 0])*np.log(1-h[i, 0]))
else:
sum_err += 0
return sum_err/m
def lr_train_bgd(feature, label, maxCycle, alpha, df):
n = np.shape(feature)[1]
m = np.shape(feature)[0]
w = np.mat(np.random.rand(n,1))
i = 0
while True:
i += 1
h = sigmoid(feature * w)
err = label - h
if i % 100== 0:
print('error : ', error_rate(h, label))
d = 0
scores = []
for i in range(m):
score = predict(w, feature[i])
scores.append(score)
if score == label[i]:
d += 1
print('train accuracy : ', (d/m)*100, '%')
if (d/m)*100 >= 90:
for i in range(m):
if df.iloc[i, 2] == 1:
c = 'red'
else:
c = 'blue'
plt.scatter(df.iloc[i, 0], df.iloc[i, 1], c=c)
x = [i for i in range(0, 10)]
plt.plot(np.mat(x).T, np.mat((-w[0]-w[1]*x)/w[2]).T, c = 'blue')
plt.show()
return
w += alpha * feature.T * err
def loadData(filename):
df = pd.read_csv(filename, sep=' ', names=['a', 'b', 'label'])
n, m = df.shape
features = []
labels = []
for i in range(n):
feature = []
feature.append(int(1))
for j in range(1,m):
feature.append(df.iloc[i, j])
if df.iloc[i, m-1] == -1:
labels.append(0)
else:
labels.append(1)
features.append(feature)
for i in range(n):
if df.iloc[i, 2] == 1:
c = 'red'
else:
c = 'blue'
plt.scatter(df.iloc[i, 0], df.iloc[i, 1], c = c)
plt.show()
return np.mat(features), np.mat(labels).T, df
if __name__ == '__main__':
f, t, df = loadData('../Data/testSet.txt')
lr_train_bgd(f, t, 10000, 0.001, df)

Github代码:https://github.com/GreenArrow2017/MachineLearning/tree/master/MachineLearning/Linear%20Model/LogosticRegression
