一、HBase在360的使用情况
从数据来看,360目前共有27个HBase集群,其中在线集群9个,综合集群3个。整个360共有12500个HBase节点,单集群最多有2184个RegionServer。360 的HBase集群共有1885个Table以及719703个Region,而单表最大的Region数为74788。此外,从业务层面来看,360的HBase集群每秒钟大约需要响应3百万次请求。通过这些数据也能够说明,目前对于360而言,无论是HBase集群还是节点,数量都非常庞大,请求量也非常大。而如今,整个360背后的几大重要业务都有HBase的身影,比如360搜索、安全业务以及360金融和IoT等背后都使用了HBase存储数据来支撑业务的快速发展。

针对如此众多的业务场景,360根据业务特点将其分为了三类:
- 第一类业务对响应时间比较敏感,这类一般是在线业务,所使用的方式就是实时存取数据。对于此类业务,一般而言会将其放到线集群之上,在线集群的服务器配置(CPU、内存、带宽等)都会相对更高一些。与此同时,为了保证服务质量,不会在这些集群中跑MR或Spark等计算作业。
- 第二类业务对磁盘容量要求较高,其应用场景一般是定期批量写入大量数据,并周期性地进行离线分析或备份。这类业务会被放到离线集群上,而离线集群一般会配置大硬盘,而CPU、内存配置也会相应低一点。对于此类业务,360的HBase团队也开发了一些MR作业,以帮助业务可以方便的大批量读写、分析HBase中的数据。
- 第三类业务属于第一类和第二类中间地带的情况,这类业务对磁盘容量和响应时间有部分要求,但并不十分敏感,比如监控、缓存溯源、报表等半在线业务。这类业务一般会放到综合集群中,综合集群的配置和在线集群相当,这个集群既可以做在线读写HBase,也可以跑离线分析作业,因此可以充分的利用硬件资源。但这样的缺点也很明显,那就是会出现资源竞争和相互影响的情况。
二、基于HBase实现的功能和改进
二级索引
为了更好地支撑业务,360在HBase0.89-Facebook版本上实现和改进了一些功能。对于HBase而言,其查询方式主要有两种,即get和scan。get查询速度快,但只可以基于RowKey进行查询,虽然可以设计组合字段的RowKey,但不灵活,使用复杂,而且容易造成数据倾斜。scan查询则会消耗大量资源,而且无法保证时效性。为了更好地实现HBase的查询,360在二级索引上做了很多工作。
目前,业界对于二级索引的实现方案大体分为两类:全局二级索引方案和局部二级索引方案,两种方案各有优劣,而360选择了局部二级索引方案。以下图的Test表为例,为CF1:C2列建立了二级索引,此时,在表的同个Region中,除了原来的数据,还会插入索引数据,只不过索引数据存储在一个特殊的INDEX Column Family中。对于索引数据的RowKey而言,以Region的StartKey开头以保证和原始数据在同一个Region中,以真实数据的RowKey结尾,以保证索引数据RowKey的唯一性。索引数据的Value,只是记录了索引RowKey不同部分的长度,以方便反序列化RowKey的各个部分。在进行写数据的时候,可能需要拼出来索引数据然后插入到表中。在读数据的时候,就可以通过StartKey、INDEX name和Value拼出来的scan查询语句将索引数据取出来,获得所需要查询数据的RowKey列表,再去列表中取出真实数据。

对于写方案的具体实现,简单而言就是使用了HBase自带的协处理器,因此可以实现零侵入的二级索引方案。当客户端需要Put数据的时候,协处理器可以在Put之前将二级索引的数据也加入需要传输的对象中,以保证原子性。

对于读方案的具体实现而言,就是需要先创建一个Scanner,再调用Next()方法来读取数据。360的方案支持类SQL写法,所以当客户端收到类SQL请求时,会先进行语法解析,如果语法没问题,则会构造一个scan对象,并请求Region Server来CreateScanner。在Region Server端,则通过协处理器来拦截,并根据请求构造出一个Scanner语法树。

在创建完Scanner之后,下一步就是通过next()方法读取数据。这部分也分为两步,先查询索引数据,然后反序列化出真实数据的RowKey列表,之后使用这个RowKey列表去查询真实数据的Column Family。查询出数据之后,需要检查数据是否有效,然后将数据返回给客户端。对于二级索引的读流程而言,需要先查询索引数据,再查询真实数据,因此需要查询两次。其实,对于此流程而言,也可以继续进行优化,比如把真实数据也序列化到 INDEX family的Value中,这样一来只需要查询一次索引数据即可返回给客户端。

跨集群备份
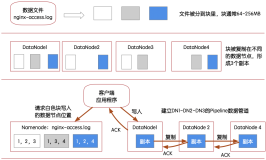
为了实现HBase更高的可用性和方便业务就近访问数据,360的HBase团队开发了跨集群备份功能。TransferTable是一张普通的Hbase表,在这里可以把它当做一个缓存队列,图中其左侧的LogEntryVisitor相当于一个生产者,负责向TransferTable表中写数据,它右边的TransferDaemon相当于一个消费者,负责从TransferTable中读数据并发送到备份集群。这样的生产者-消费者模型就是跨集群备份的核心逻辑。

总结而言,当客户端向UserTable中写数据时,LogEntryVisitor会拦截WAL Append操作,并把这条记录写到TransferTable中,这是同步的过程。为了保证写TransferTable的效率,360 HBase团队开发了类似于Balancer功能,保证每个UserTable Region所在的RegionServer至少有一个TransferRegion,写TransferTable的时候直接调用Put方法即可,避免了不必要的序列化和反序列化操作。然后,TransferDaemon线程不断从TransferTable中扫描数据,并使用多个线程并行发送到远端的备份集群中。
三、HBase2.0 应用实践
如今的HBase和前几年所谈的HBase已经差异很大了,之前的HBase可能仅仅指的是一个Key-Value型的NoSQL数据库,而现在HBase却代表着一个生态,不仅是KV,还有时空、时序、图等组件。所以对于开发组织而言,应该尽早融入生态之中,避免后续的兼容性问题和大量的迁移工作。目前,360的HBase2.0实践中主要有两种应用场景,即对象存储服务和时序服务。

四、问题与解决
在使用HBase2.0时,360所遇到的主要问题就是MOB特性所带来的问题,这个新特性带来了单点Compaction、MOB文件过于集中,以及文件过大不便释放空间等问题。具体的解决方案则如下图所示:

如今,HBase指的不再仅仅是之前所谈及的Key-Value类型的NoSQL数据库,而是代表着一整个HBase生态。作为技术人员,我们应该具备技术前瞻性,勇敢地拥抱生态,并为社区和生态做出贡献。虽然,生态可能并不够成熟,但是挑战必将与机遇并存。