1.测试目的
阿里云云服务器(Elastic Compute Service,简称 ECS)是一种简单高效、处理能力可弹性伸缩的计算服务,帮助客户快速构建更稳定、安全的应用,提升运维效率,降低 IT 成本,使您更专注于核心业务创新。而阿里云块存储(Block Storage),是阿里云为云服务器ECS提供的低时延、持久性、高可靠的数据块级随机存储。块存储支持在可用区内自动复制数据,防止意外的硬件故障导致数据不可用,以保护您的业务免于组件故障的威胁。就像对待硬盘一样,客户可以对挂载到ECS实例上的块存储做格式化、创建文件系统等操作,并对数据持久化存储。
对ECS来说,当前阿里云能提供的两种云服务的规格列表参数如下:
表1-1 ECS在专有云和公共云最大规格对比
|
|
最大CPU数 |
最大内存 |
网络带宽 |
最大云盘数量 |
| 专有云(v2) |
16 |
64GB |
万兆网络 |
4 |
| 公共云 |
40 |
224GB |
万兆网络 |
4 |
表1-2. 块存储规格对比
|
|
最大容量 |
最大吞吐量 |
最大IOPS |
最小响应时间 |
| 专有云本地SSD磁盘 |
800GB |
>200MB/s |
12000 |
0.5ms |
| 专有云 普通云盘 |
2000GB |
40MB/s |
数百 |
5ms |
| 专有云 SSD云盘 |
2048GB |
256MB/s |
20000 |
0.5ms |
| 公共云 普通云盘 |
2000GB |
40MB/s |
数百 |
5ms |
| 公共云 高效云盘 |
32768GB |
80MB/s |
3000 |
1ms |
| 公共云 SSD云盘 |
32768GB |
256MB/s |
20000 |
0.5ms |
显然,公共云环境的云资源的计算能力能力高于专有云,而专有云上运行一些对性能要求非常严格,且非常关键的应用,比如Oracle数据库,该如何在阿里云平台上提供对应的资源且保证容量、性能都能满足业务需求呢?我们做了如下测试进行验证。
2. 测试环境
2.1 阿里云资源
我们在阿里云公共云华东1区申请了5台ECS,模拟专有云平台的环境进行测试。兼顾效率和与专有云的环境的兼容匹配,这5台ECS的配置和用途分别是:1台16核CPU 64GB的ECS作为数据库服务器,3台2核8GB外加2个2TB SSD云盘的ECS作为存储服务器,1台2核8GB的ECS作为压力测试服务器。
表2-1.测试环境系统配置
| 编号 |
配置 |
数量 |
用途 |
| 1 |
独占实例,16C 64G,不带系统盘 |
1 |
数据库服务器 |
| 2 |
非独占实例,2C 8G,2TB SSD云盘*2数据盘 |
3 |
存储服务器 |
| 3 |
非独占实例,2C 8G,不带数据盘 |
1 |
压力测试服务器 |
数据库我们做单实例部署,同时因为专有云暂时只有2TB的最大单盘容量,所以我们需要在多台ECS搭建分布式存储系统,为数据库提供超出云平台单台ECS所能挂载的块存储容量。
2.2 大容量存储
阿里云块存储(云盘)基于盘古分布式文件系统,数据保存3份副本,具有99.9999999%的数据可靠性,且后端全部使用PC服务器,廉价且易维护。阿里云公共云提供单盘32TB的SSD磁盘,单个ECS最大可挂载4个云盘,最终提供客户128TB的高速大容量空间。
glusterfs是一个开源的分布式文件系统,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。
iSCSI是一种基于TCP/IP 的协议,用来建立和管理IP存储设备、主机和客户机等之间的相互连接,并创建存储区域网络(SAN)。SAN 使得SCSI 协议应用于高速数据传输网络成为可能,这种传输以数据块级别(block-level)在多个数据存储网络间进行。
阿里云专有云最新v2版本最大支持2TB的SSD云盘单盘容量,预计会在v3版本开放支持32TB。所以,我们舍弃在公共云上直接使用超过2TB SSD云盘的方案。glusterfs和iSCSI两种开源方案我们也分别进行了测试:两种文件系统都能将分布在多台服务器上的存储资源(磁盘)集中到一台服务器上,存储容量最大支持到PB以上。glusterfs理论上更适合于存放不经常读写的大文件,我们在实测中发现使用gluster搭建的存储稳定性欠佳,数据文件部署在glusterfs中在大规模并发读写下容易导致数据库hang住并频繁报错。而iSCSI则是更成熟的方案,与传统的数据库使用的SAN存储网络更接近。最终,我们选定使用iSCSI方案将3台存储服务器的6个2TB SSD云盘通过网络iSCSI协议共享给数据库服务器,实现12TB大容量存储。
测试方案架构最终确定:
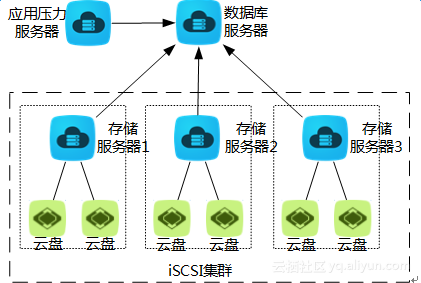
图2-1.测试环境系统架构
2.3 压力模拟
swingbench生成测试数据,然后模拟指定数量的客户端对数据库的并发访问压力,最终记录测试结果。swingbench可以通过多台服务器对同一个数据库同时加压,本测试我们模拟使用1台并发加压。
2.4 基准测试
对于单个SSD云盘直接挂载给ECS来说,其性能在官网已经给出很明确的SLA说明:
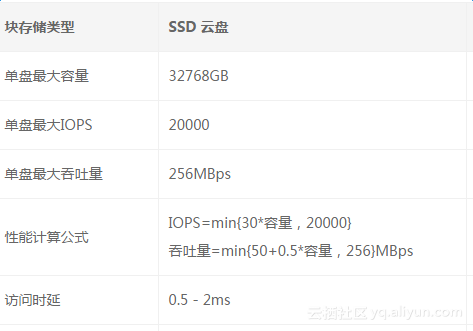
图2-2.SSD云盘性能SLA
但是我们的测试架构中,云盘并不直接挂载给数据库服务器,而是通过iSCSI协议走内网映射给数据库服务器,所以除了云盘的最终性能表现还取决于iSCSI target的内网的带宽。对于外部用户来说,ECS实例的内网带宽根据不同规格是做了相应的限制的,所以我们有必要先做一个基准测试以确认SSD云盘通过iSCSI共享后的性能。
下图2-3是单个存储服务器ECS TCP带宽测试结果,平均大约100MB/s:
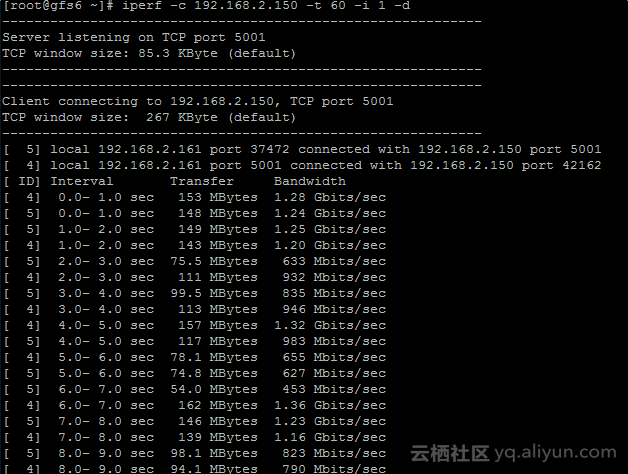
图2-3 存储服务器ECS TCP网络带宽测试结果
基于对单个ECS的TCP网络测试结果,我们在数据库服务器上使用Oracle IO校准工具先后测试挂载2台iSCSI target和3台iSCSI target时得到的存储系统带宽、IOPS的最大值。
当挂载2台iSCSI target时,得到的最大IOPS大约12000,最大带宽195MB/s:

图2-4 2台iSCSI存储服务器的IO校准结果
当我们增加1台iSCSI target接入到数据库服务器后,再次测试,得到的结果如下:
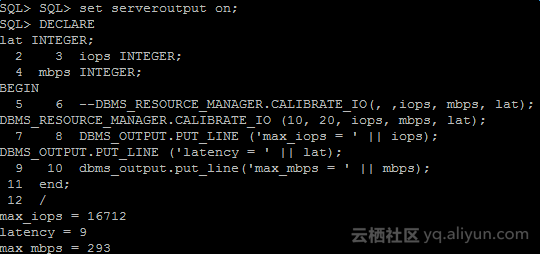
图2-5 3台iSCSI存储服务器的IO校准结果
根据以上两个测试,得出结论:我们实验的环境中,网络瓶颈在非独占式ECS的内网带宽,2CPU 8GB内存的这一规格ECS最大内网带宽大约为100MB/s,16C 64GB内存这一规格独占式ECS实例至少有超过300MB/s的内网带宽。在数据库服务器内网带宽瓶颈到来之前,需要提升Oracle数据库的IO能力,可以横向添加iSCSI target存储服务器。
3 测试模型
Swingbench包含4种基准测试:
l Order Entry 基于Oracle 11g/12c的示例模式“oe”。同时进行了一些修改,不需要安装Sptial模式和Intermedia模式。它可以持续运行,直到磁盘空间耗尽。它引入了少量表上的严重竞争,用于互联和内存的压力测试。它可以通过bin目录中的“oewizard”进行安装。基准测试程序存在纯jdbc版本和pl/sql版本(网络负载更低)。
l Sales History基于Oracle 11g/12c的示例模式“sh”,用于测试针对大表的负载查询的性能。表是只读的,并且大小能够从1GB扩展到1TB。也可以使用自定义模式创建更小或者更大的模式。
l Calling Circle模拟一个在线电信应用的SQL。它需要在每次运行之前生成数据文件,并且从数据库服务器端复制到负载生成器,通常需要1GB到8GB磁盘空间。该基准测试是CPU密集型的。经验表明,对于数据库服务器的每2个CPU,负载生成器至少需要1个CPU。它用于测试CPU和内存,不需要强大的I/O子系统。它可以通过bin目录中的“ccwizard”进行安装。
l Stress Test 针对表的简单随机插入、更新、删除以及查询测试,读写比例为50/50。
我们选用order entry做测试模型,造数据脚本执行比较费时,分别造了100GB数据和1TB数据做两批对比测试。在测试中,我们可以通过灵活调节每类业务操作的比重来平衡数据库的update/insert/select/delete等DML操作。因为测试模型脚本是swingbench已经封装好的,所以我们无法调整任何执行的SQL语句,但是我们对数据库系统本身及相关参数进行了基本优化,比如设定合理的SGA、PGA、log_buffer大小,调整redolog日志为2GB一个,以及session_cached_cursors从50调大到200等。
4.测试数据
100GB数据量由swingbench自动生成,选择创建完整索引,查看各个表的记录数情况参考表4-1。同样,1TB数据则是这些表中数据量的10倍。事实上,我们观察到,对于100GB的数据量,加上索引的使用空间,表空间的使用量达到了150GB以上。
表4-1 100GB下表数据量统计
| 编号 |
表名 |
初始数据量 |
| 1 |
logon |
238298400 |
| 2 |
customers |
100000000 |
| 3 |
ADDRESSES |
150000000 |
| 4 |
CARD_DETAILS |
150000000 |
| 5 |
ORDER_ITEMS |
428924688 |
| 6 |
ORDERS |
142979000 |
| 7 |
ORDERENTRY_METADATA |
4 |
| 8 |
PRODUCT_DESCRIPTIONS |
1000 |
| 9 |
PRODUCT_INFORMATION |
1000 |
| 10 |
INVENTORIES |
899927 |
| 11 |
WAREHOUSES |
1000 |
同样,对于1TB的数据量来说,以上表格中的业务表的记录数都是乘以10倍来计算的,参数表数据量则不发生变化。
每一轮测试,我们使用相同的参数,每次只调整模拟并发用户数,模拟用户思考时间为0,每个场景运行至少20分钟,中间收集服务器性能数据、数据库AWR数据和swingbench的结果,最终我们以并发用户数、TPS、QPS、系统IOPS和RT这5大指标来对测试结果进行统计和对比分析。
4.1 读写混合场景
各类操作的比例关系,落到存储上IO读和写的比例大约为7:3,对IO系统来说,主要考验的是IOPS能力。
图4-1 OE模型中读写混合场景各类操作的比例配比
首先,我们把收集到的完成测试数据列成表格。但是这并不直观,如果希望观察到趋势而不太在意数据细节的,我们可以直接看下面的数据对比图。请注意,本文中所有的纵轴都代表并发用户数。
表4-2 读写混合场景测试结果
| 数据量 |
用户数 |
平均TPS |
QPS |
IOPS |
平均RT(ms) |
| 100G |
20 |
259 |
2745 |
1500 |
6 |
| 100G |
50 |
562 |
5957 |
3100 |
7 |
| 100G |
100 |
1258 |
13334 |
5200 |
8 |
| 100G |
200 |
2320 |
24592 |
8000 |
15 |
| 100G |
300 |
2350 |
24910 |
7900 |
50 |
| 1TB |
20 |
236 |
2501 |
2500 |
14 |
| 1TB |
50 |
574 |
6084 |
5600 |
16 |
| 1TB |
100 |
1069 |
11331 |
9800 |
22 |
| 1TB |
200 |
1599 |
16949 |
13000 |
53 |
| 1TB |
300 |
1690 |
17914 |
14500 |
105 |
首先,我们看图4-2,100GB基线数据,随着并发用户数的增长,TPS、QPS以及IOPS都接近线性增长,RT也呈稳步增长趋势。在我们的实验中,当用户数超过200后,TPS的增长接近为0,但是RT出现了激增。这个现象与理论也是匹配的:固定条件下,TPS会随着并发在线用户数的增长而增长,但是当超过某临界值后,TPS增长趋缓,甚至可能会下降。同时,响应时间(RT)在并发用户突破临界值后,也会出现急剧增长。
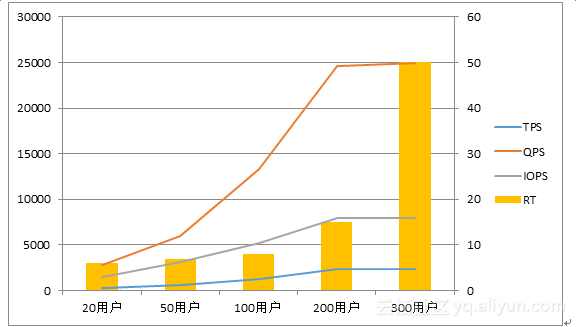
图4-2 100GB数据量性能表现
同样,我们观察图4-3,在1TB基线数据下,我们获得了与图4-1基本类似的性能视图:TPS、QPS、IOPS随着并发用户数上升而上升。并发用户数超过200后,性能提升开始变得不太明显。
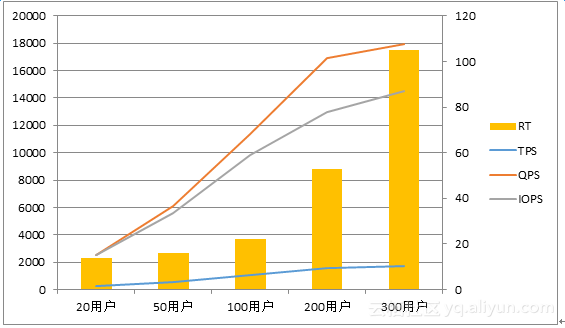
图4-3 1TB数据量性能表现
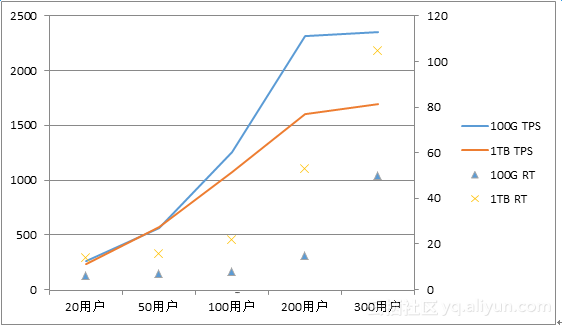
图4-4 100GB和1TB数据TPS与RT对比
我们把两种数据基线的测试结果放到同一个图4-3中来观察,能看到一些存在差异的地方:在相同并发用户数条件下,100GB基线的TPS比1TB基线的要高;相反,1T基线的RT和IOPS比100GB极限的高。这也是很好理解的,更大的数据量意味着表的记录数更多,而数据库的各项操作扫描的数据块也越多,自然IOPS更高,且需要的时间也更长。
读写混合的场景中,我们还有1个问题值得讨论:在基础数据量100G时,当TPS达到极限,为什么IOPS还不到1万?
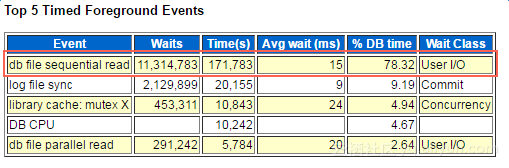
图4-5 100GB基线数据混合场景数据库top5等待事件
这个问题我们对比着1TB基数的数据量来看,在后者的TPS达到上限时,IOPS跑到15000左右,接近了系统的IOPS极限(16712)。同时,我们查询当时的操作系统负载和Oracle AWR报告,发现当时CPU user%大约70%,有20%的wait%,AWR中top5等待事件占比78.32%的排名第一事件为“db file sequential read”。该事件意味着Oracle进程需要访问的数据块不能从SGA直接获取,因此会等待数据块从磁盘(I/O系统)中读到内存SGA中。在SGA不增加且SQL不能调整的情况下,磁盘的性能决定了整体性能。所以我们认为数据库的数据量相对于存储容量越接近,数据扫描时越能充分使用到磁盘的IO能力。当数据量相对小的时候,由于数据分布的原因,数据库整体性能表现将一定程度低于IO系统的整体性能。
4.2 “纯读”场景
所谓“纯读”场景,只有一种类型的业务,即用户浏览商品,因为执行的事务操作,所以依然会有很低比例的写数据库操作。为了方便理解,我们近似地认为落到存储上IO读的比例几乎为100%。
图4-6 OE模型中读写纯读场景各类操作的比例配比
表4-3 纯读场景测试结果
| 数据量 |
用户数 |
平均TPS |
QPS |
IOPS |
平均RT(ms) |
| 100G |
20 |
349 |
2443 |
700 |
2 |
| 100G |
50 |
870 |
6090 |
1350 |
2 |
| 100G |
100 |
1734 |
42630 |
1750 |
2 |
| 100G |
200 |
3367 |
23569 |
1800 |
4 |
| 100G |
300 |
4717 |
33019 |
1400 |
7 |
| 100G |
400 |
5460 |
38220 |
700 |
15 |
| 100G |
500 |
5563 |
38941 |
320 |
31 |
| 1TB |
20 |
344 |
2408 |
1400 |
10 |
| 1TB |
50 |
858 |
6006 |
3100 |
10 |
| 1TB |
100 |
1692 |
11844 |
5000 |
11 |
| 1TB |
200 |
3184 |
22288 |
7200 |
16 |
| 1TB |
300 |
4010 |
28070 |
8000 |
28 |
| 1TB |
400 |
4650 |
32550 |
6000 |
27 |
| 1TB |
500 |
空缺 |
空缺 |
|
空缺 |
我们依然把表格用图形的方式展示:
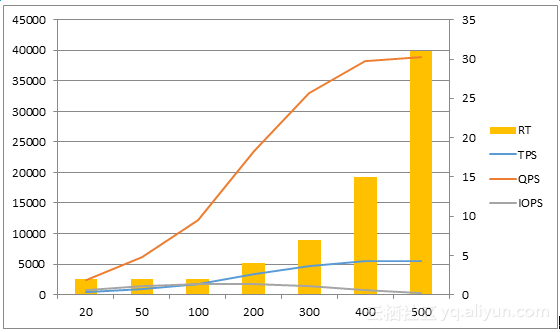
图4-7 100GB数据量性能表现
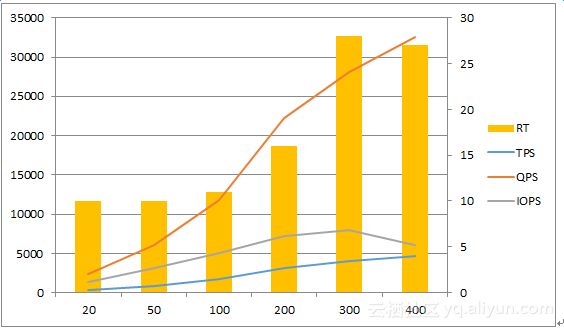
图4-8 1TB数据量性能表现
观察以上图4-7和4-8,纯读场景表现出对并发用户数更好的支持能力,在RT控制在30ms左右时,数据库能支撑500并发用户访问,该场景下并发用户的TPS拐点提升到了300-400这个数值,比混合场景200用户提升了几乎一倍。同时,响应时间也控制在更好的水平,大部分测试案例中RT都在20ms以内,20ms是大多数OLTP系统对数据库响应的最大极限。同时,纯读场景磁盘IOPS也大大低于混合场景,甚至当TPS超过一定数值后,IOPS还表现出了下降的趋势。这个测试结果也是比较好理解的,我们使用的OLTP业务场景进行测试,而纯读的业务主要满足用户的各种查询需求,在一个良好的IT系统中,用户经常需要查询的内容大部分是被各级缓存存储的,最直接的就是数据库的数据缓存,当然也可以将静态数据存放在内存数据库,以获得更好的性能。随着系统测试地不断往下进行,业务需要的数据被越来越多地“预热”到SGA中,所以需要从磁盘读取的数据也随之减少,表现出来就是磁盘物理IOPS的降低。
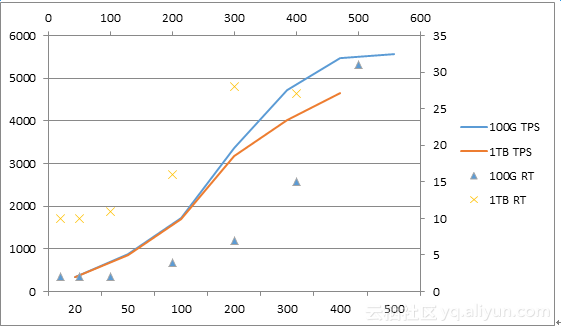
图4-9 100GB和1TB下TPS与RT对比
我们把100GB和1TB两个数据基线的测试结果放到同一个图4-9中进行对比,自然100GB基线的数据表现要好于1TB数据基线的结果。但是在并发用户数比较少时,两种数据基线的TPS性能是非常接近的,这意味着在并发用户数不多的情况下,纯读的业务场景最依赖的是内存的容量,内存容量越大,那就可以缓存越多的数据,系统能支撑越大的业务量。这个结论也与我们的基本认知是一致的。
5.测试结论
5.1 测试结果总结
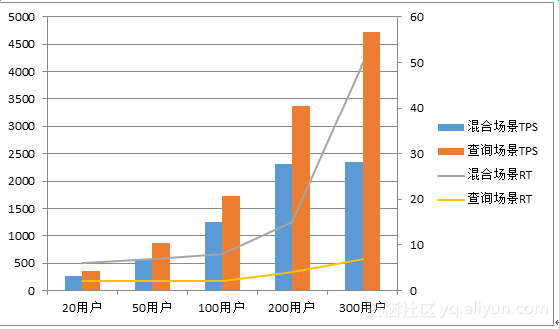
图5-1 100GB数据两种场景的性能结果对比
最后,为了方便读者阅读,我们把所有的数据合并到一张图里5-1再进行观察和总结。我们可以得出如下结论:
l 100GB基线数据,RT允许(≈20ms)的范围内,混合场景最大TPS为2320,最大QPS为24590,此时有200名并发用户;
l 1TB基线数据,RT允许(≈20ms)的范围内,混合场景最大TPS为1069,最大QPS为11330,此时有100名并发用户;
l 100GB基线数据,RT允许(≈10ms)的范围内,查询场景最大TPS为4717,最大QPS为33019,此时有300名并发用户;
l 1TB基线数据,RT允许(≈10ms)的范围内,查询场景最大TPS为1692,最大QPS为11844,此时有100名并发用户;
l 云盘的读性能好于写性能,更适合大规模随机读的业务场景;
l 系统可以通过增加云盘的方式线性提升IO的容量和性能。
5.2 推荐方案
我们对比表5-1三种方式,给出需要在阿里云上自建类似Oracle或DB2这样的传统商业数据库的客户选型和架构方案。
表5-1 三种存储架构技术参数对比
|
|
大容量SSD云盘 |
Glusterfs |
iSCSI |
| 容量 |
128TB每台ECS |
>1PB每台ECS |
>1PB每台ECS |
| 成本 |
低 |
低 |
低 |
| 对ECS性能消耗 |
无 |
低 |
低 |
| 可靠性 |
99.9999999% |
<90% |
>99.9% |
| IOPS |
单盘20000 |
20000 |
20000*磁盘数量,极限值受限于云平台内网带宽 |
| 吞吐量 |
单盘256MB/s |
120~160MB/s |
120MB/s*云盘数量,极限值受限于云平台内网带宽 |
| TPS峰值 |
N/A |
N/A |
4717(受限条件) |
| TPS峰值并发用户 |
N/A |
N/A |
300 |
| TPS峰值响应时间 |
N/A |
N/A |
7ms |
| 限制 |
专有云v2不输出 |
共享云平台内网带宽 |
共享云平台内网带宽 |
l 阿里云支持用户自建商业数据库,为了业务的连续性,建议客户至少搭建HA高可用数据库系统,如果有能力最好搭建具有容灾的数据库系统。客户需要自己解决license和运维问题,目前已有合作伙伴推出运维工具,可以在云市场采购;
l 数据库类应用系统,不要犹豫,请直接使用SSD云盘;
l 公共云上,业务存储容量、IOPS和带宽需求小于单个SSD云盘规格的,直接使用SSD云盘。任意一项不满足的,可以申请最多4个SSD云盘挂载使用;
l 无论是公共云还是专有云,如果出现超出单个ECS能直接挂载的SSD云盘容量和性能的需求,建议使用iSCSI将多个云盘共享给数据库服务器,以横向扩展IO系统的容量和性能。这种架构中,需要提前考虑各个节点间的内网带宽,以免因为内网带宽而导致无法充分发挥云盘的能力;
l 云盘的数据可靠性和可用性都是非常高的,如果需要更高级别的保障,在Oracle数据库中,可以考虑部署RAC集群,以及使用带内部冗余的ASM存储系统,在牺牲一部分性能和容量的前提下带来极高的可靠性和可用性;
l 如果用户对成本比较敏感,需要更精细地计算直接使用大容量SSD云盘和iSCSI分布式存储架构的成本,根据自己的实际需求选用最经济的方案。
