- 这是一篇自学文章,并未涉及很深的东西,只是自己的一点理解,如果有错,请及时指正谢谢
自我理解
- 自己理解的布隆过滤器,即一个bytes数组,那么这个byte每一位上代表的数字是0和1,那么假如我们将字符串
ss添加进一个文件,然后我们怎么用布隆过滤器来标识一个ss字符串是否已经添加进了文件呢? - 首先我们要将
ss进行hash得到一个数组长度范围内的一个整数值,即bytes数组的下标,然后将此位置上的0更改为1,代表ss被添加进了文件 - 当然有时候如果发生重复的hash值,那么就会造成表示模糊的状况(即假如两个串都是相同hash返回值,造成bytes数组上同一位置被赋值为1的情况),在这时候我们可以采用不同的hash算法来得到多个数组长度范围内的整数值,那么我们将返回的多个整数值所对应的下标都设置为1,这个就好像是MySQL中的联合主键一样,而不至于制造一个模糊的状况
- 推荐一个网站阅读.里面包含了一个非常直观的Bloom过滤器的工作过程,手动点赞,如果你打不开也没关系,我将把这个过程贴到这里,并且附上下载好的网页:工作过程演示
工作过程
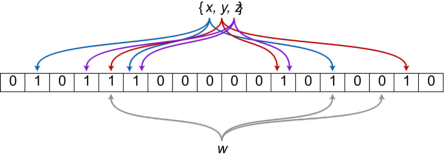
- 刚开始是没有任何位置被标记为1的,如下图

- 然后我们首先将
ss添加进去

- 我们看到这个是利用了三个不同的算法,来返回了三个不同的整数值,然后将数组的不同位置标记了一下,然后我们再将
aa,bb,cc添加进入

- 添加了并标记好后,我们发现
aa与cc的一个整数返回值一样,所以同一个位置被标记了两次,如果这时候只是每个字符串返回一个整数值的话,就会出现上面说的模糊的状态的情况 - 然后我们来查看某个值是否添加进去了,比如我们查
zz,我们知道这个是没有添加进去的

- 我们看到判断的
zz的时候,同样是应用三次算法,返回三个整数值,有一处发生了重叠,而另外两处是没有发生重叠的,只要有一个没有发生重叠也就说明zz是没有添加进去过的 - 我们在查看
aa的添加状态

- 我们发现三次计算的返回值的对应的数组上都被标记过,所以这就说明这个
aa是可能被添加进去过的,那么为什么说是可能呢,虽然算法可能会返回不同的计算值,而且我们利用了"联合的方式"来确保不造成模糊的状态,但是依旧是无法保证一个元素对应一个位置的,还是有可能发生重叠的,虽然概率很小,网上的说法是万分之一 -
这个过滤方法可以说明一个值一定不在这里面又是为什么呢,因为算法是不会出错的,过滤器内被标记的位置都是相同的算法计算得出的,算法并不会中途发生改变,所以这个一个函数式的过程,即输入一个相同的值肯定会返回值对应的相同的结果(即如下一个简单的代码演示的效果,输入1,永远会返回2),所以如果数组内的对应位置没有发生标记行为,那么是肯定没有这个值的
private int getNum(int i){ return i + 1; } - 到这我们就可以看到,对于这个过滤方式来说好算法的地位是相当重要的,算法不局限与hash算法,但是要尽量的将值的返回结果散列开来,尽量保持一个值一个数,这样Bloom过滤才会最准确
- 读到这了,我们就可以总结一下了,这种过滤方式的返回结果是 : 一定不在 or 可能在
- 那么算法的弊端是什么呢? 算法的弊端也就是不能将一个值方便的去除,我们之前从图中看到,不同的字符串的hash返回值可能会返回相同的整数值,所以这个整数值是被多个字符串标记的,当你去除一个字符串的时候,那么其他跟这个字符串发生位置重叠的也将会受到影响
-
过滤器的应用:我们从上面可以看到算法的优势就是相当迅速的判断一个值是否在这里面,这也就可以应用在
- 比如爬虫爬没爬过这个网站?
- 比如HBase里面的应用,来判断rowkey是否在一个region里?
- 比如恶意网站的标记?
- 网上还给出了这种方式的出错概率的推导公式,那么我是有点蒙蔽的看不懂,所以就不在这贴了,附上一个帖子:CSND总结贴
-
Google的包中提供了一个Bloom过滤的实现,我们稍微用一下
- maven
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>27.0.1-jre</version> </dependency>- java
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnel; import com.google.common.hash.Funnels; import java.nio.charset.Charset; public class BloomFilterTest { public static void main(String[] args) { //z字符串的编解码 Charset charset = Charset.forName("UTF8"); //你预计的元素的个数 long expectElementNum = 1000; //你希望的出错率 double expectErrorRate = 0.1; //这有很多类型比如,integerFunnel,doubleFunnel... Funnel funnel = Funnels.stringFunnel(charset); BloomFilter bloomFilter = BloomFilter.create(funnel, expectElementNum, expectErrorRate); bloomFilter.put("aa"); bloomFilter.put("dd"); bloomFilter.put("bb"); bloomFilter.put("cc"); bloomFilter.put("ee"); bloomFilter.put("ff"); bloomFilter.put("gg"); bloomFilter.put("hh"); bloomFilter.put("kk"); bloomFilter.put("ii"); bloomFilter.put("jj"); //测试 : true System.out.println(bloomFilter.test("bb")); } }