Flink入坑指南系列文章,从实际例子入手,一步步引导用户零基础入门实时计算/Flink,并成长为使用Flink的高阶用户。本文属个人原创,仅做技术交流之用,笔者才疏学浅,如有错误,欢迎指正。转载请注明出处,侵权必究。
Flink是什么
这是个很玄妙的问题。在以下网站上做了很专业的介绍。
- Flink官网:https://flink.apache.org/
- Flink中文官网:https://flink-china.org/
如果你是大数据从业人士,简单理解,在功能上:flink>storm=jstorm=spark streaming。玩过大数据的同学对这些系统应该都不陌生。作为流计算领域的后起之秀,flink架构设计先进,ms级延时,支持Exactly once语义等,逐渐受到广大工程师的青睐,有越来越多的公司开始入坑Flink。
如果你是大数据小白,应该怎么理解Flink呢?
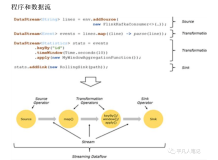
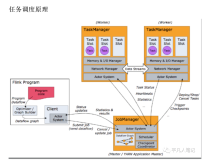
- Flink是个分布式实时计算引擎
- 可以通过SQL/DataStream API来提交Flink作业
- 可以解决低延时/大数量/精确计算的业务需求
还不理解?那么就跟我们的文章一步步来探索吧。
实时计算产品是什么
官方介绍 -- 阿里云实时计算(Alibaba Cloud Realtime Compute)(原阿里云流计算)是一套基于Apache Flink构建的一站式、高性能实时大数据处理平台,广泛应用于流式数据处理、离线数据处理、DataLake计算等场景。
实时计算底层计算引擎用的就是Flink,并且底层Flink版本与开源相比,在SQL解析层以及Runtime层都做了大量优化,SQL支持更完善,性能更优秀。实时计算产品使用的Flink版本中的各项feature会开源,逐步推回社区。
实时计算产品在Ali内部的引擎上,做了产品化包装,开发了一套开发+运维IDE,并且与其他阿里云产品的交互做了大量工作。在核心功能上,实时计算产品=Flink,因此以后系列文章中,用Flink代替产品名称。
本教程适合人群
对Flink有浓厚兴趣,想用Flink解决实际生产中的各种问题。
如果你是:
- 技术小白,不会写SQL。 请移步google/百度,先学习一下SQL的基本知识。
- 有一定技术基础,并且会写SQL。恭喜你,你已经具备了学习Flink的基础知识。
- 大数据从业人员,从本教程中,也可以学到很多原理性知识,从而成长称为优秀的Flink高阶开发人员。
适合场景
Flink能解决什么问题?如果你的场景:
- 流量大:单机搞不定
- 实时性要求高:s/ms级延时
- 计算逻辑复杂:有各种聚合/分组/关联等复杂操作
恭喜你,入坑实时计算/Flink。
也可以参考目前我们收集的用户案例,来判断Flink是否适合你的场景。
如果你有任何Flink使用的优质案例,欢迎投稿,联系我们:点我提问。
如果你不确定Flink是否适合解决你的问题?点我提问。
如果你不确定你的需求在Flink中如何实现?点我提问。
如果你对实时计算产品/Flink有任何问题?点我提问