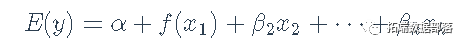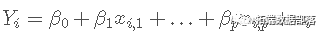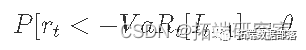热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
未来技术纵横谈:区块链、物联网与虚拟现实的融合与创新
软件体系结构 - 缓存技术(9)缓存穿透
提升Android应用性能的实用技巧
工具变量法(两阶段最小二乘法2SLS)线性模型分析人均食品消费时间序列数据和回归诊断(下)
软件体系结构 - 缓存技术(8)缓存雪崩
软件体系结构 - 缓存技术(7)Redis持久化方法
Python用KShape对时间序列进行聚类和肘方法确定最优聚类数k可视化
软件体系结构 - 缓存技术(6)淘汰策略
基于R语言股票市场收益的统计可视化分析
软件体系结构 - 数据分片(2)一致性哈希分片
Python用机器学习算法进行因果推断与增量、增益模型Uplift Modeling智能营销模型
软件体系结构 - 数据分片(1)哈希分片
R语言中的SOM(自组织映射神经网络)对NBA球员聚类分析
软件体系结构 - 数据分片
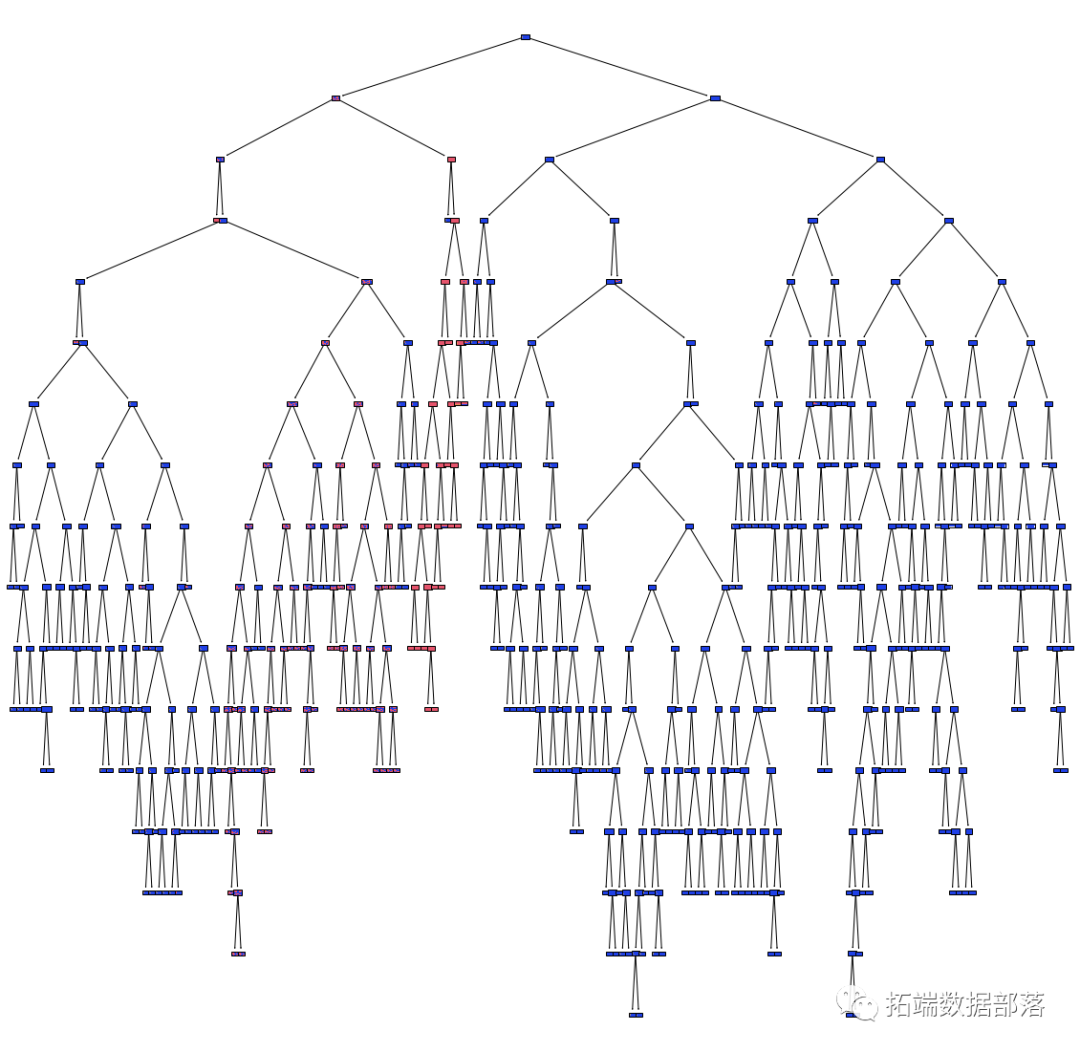
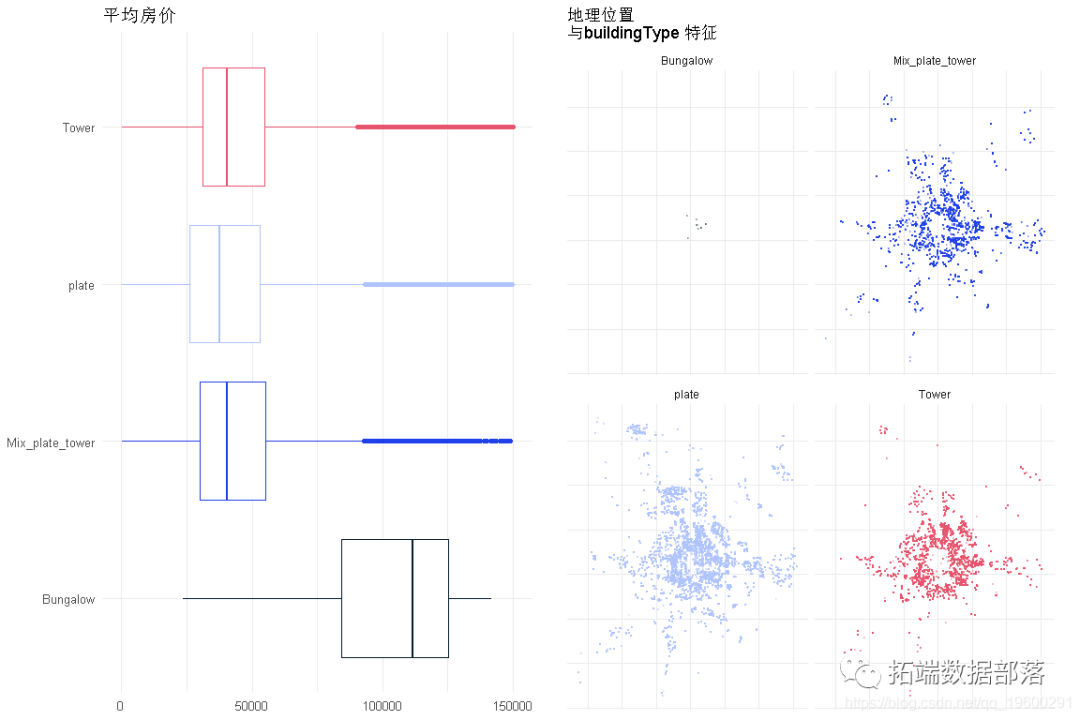
数据分享|Python在Scikit-Learn可视化随机森林中的决策树分析房价数据
软件体系结构 - 缓存技术(5)Redis Cluster
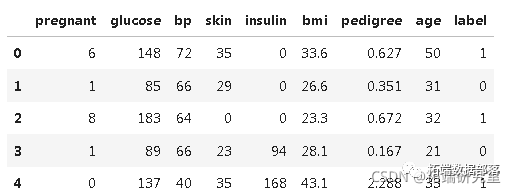
数据分享|PYTHON用决策树分类预测糖尿病和可视化实例
Python用RNN神经网络:LSTM、GRU、回归和ARIMA对COVID19新冠疫情人数时间序列预测
软件体系结构 - 缓存技术(4)Redis分布式存储
数据分享|Python用Apriori算法关联规则分析亚马逊购买书籍关联推荐客户和网络图可视化
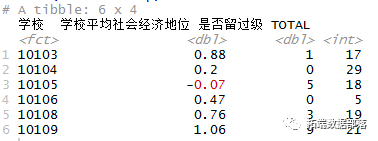
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据(下)
软件体系结构 - 缓存技术(3)Squid
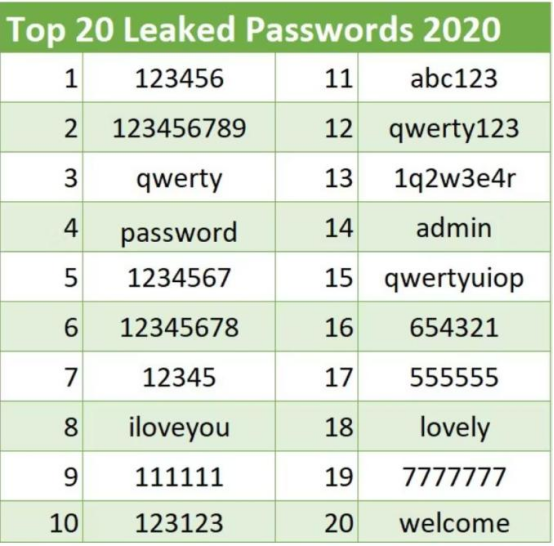
安全小课堂丨什么是暴力破解?如何防止暴力破解
软件体系结构 - 缓存技术(2)Redis
软件体系结构 - 缓存技术(1)MemCache
线性回归和时间序列分析北京房价影响因素可视化案例(下)
软件体系结构 - 缓存技术
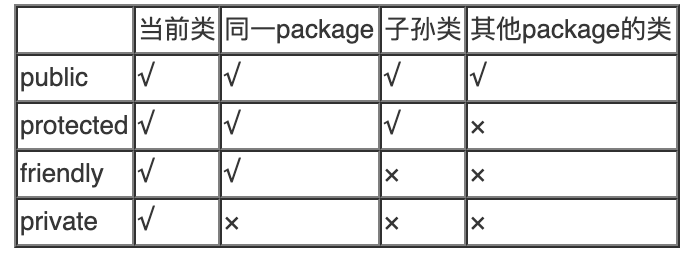
一文搞清楚Java中的包、类、接口
软件体系结构 - 信息系统架构
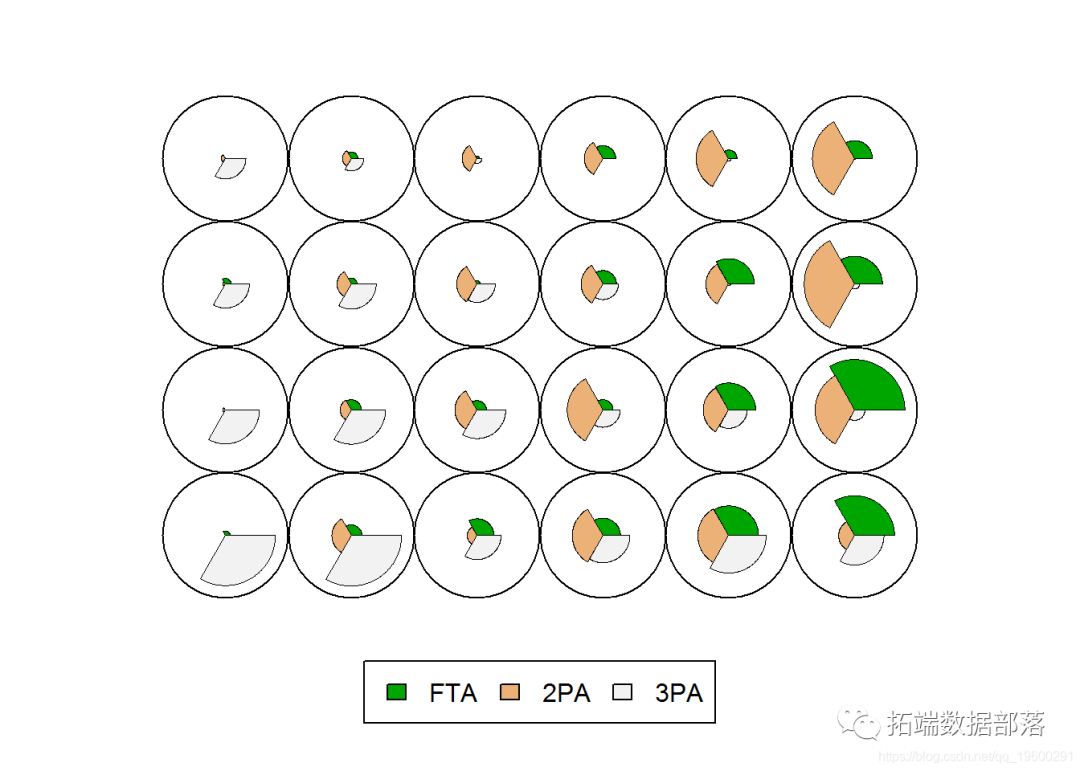
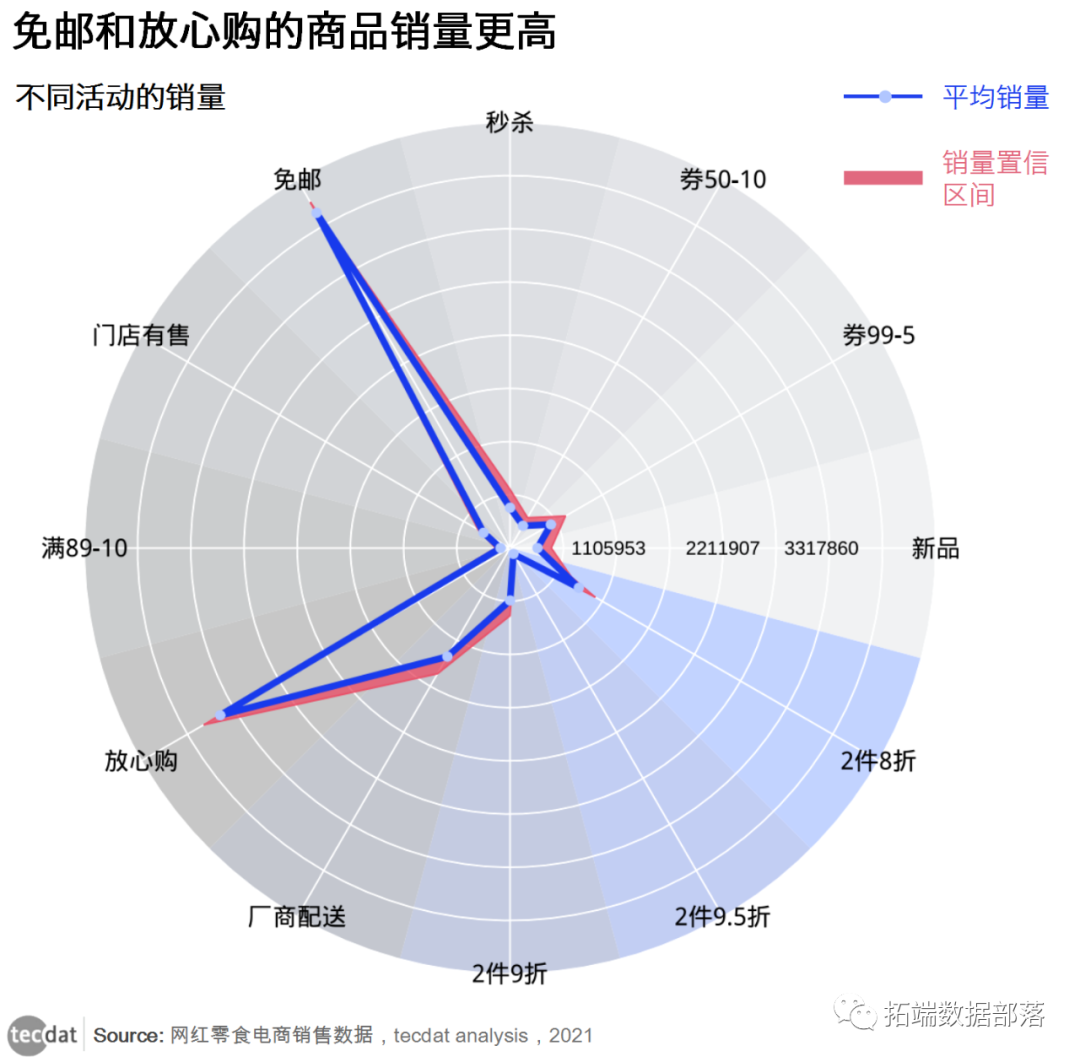
圆堆图circle packing算法可视化分析电商平台网红零食销量采集数据
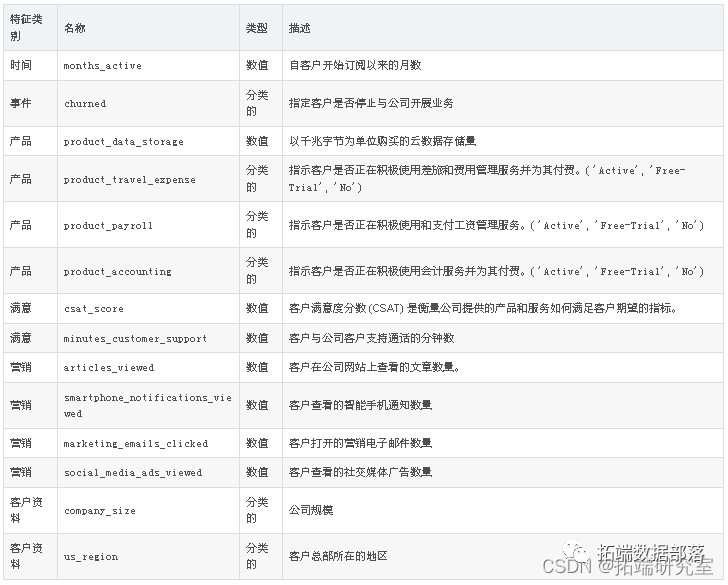
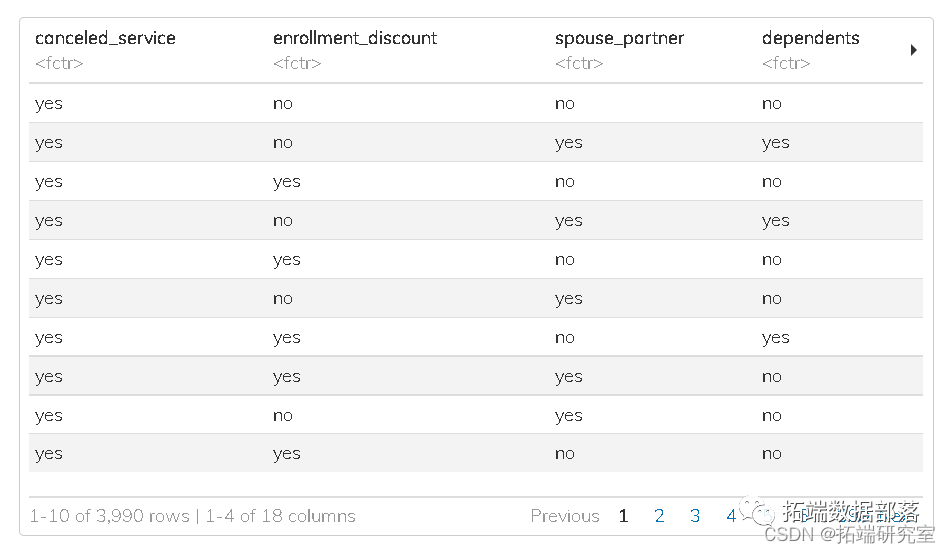
PYTHON条件生存森林模型CONDITIONAL SURVIVAL FOREST分类预测客户流失交叉验证可视化|数据分享
基于Ollama+AnythingLLM轻松打造本地大模型知识库
【视频】主成分分析PCA降维方法和R语言分析葡萄酒可视化实例|数据分享
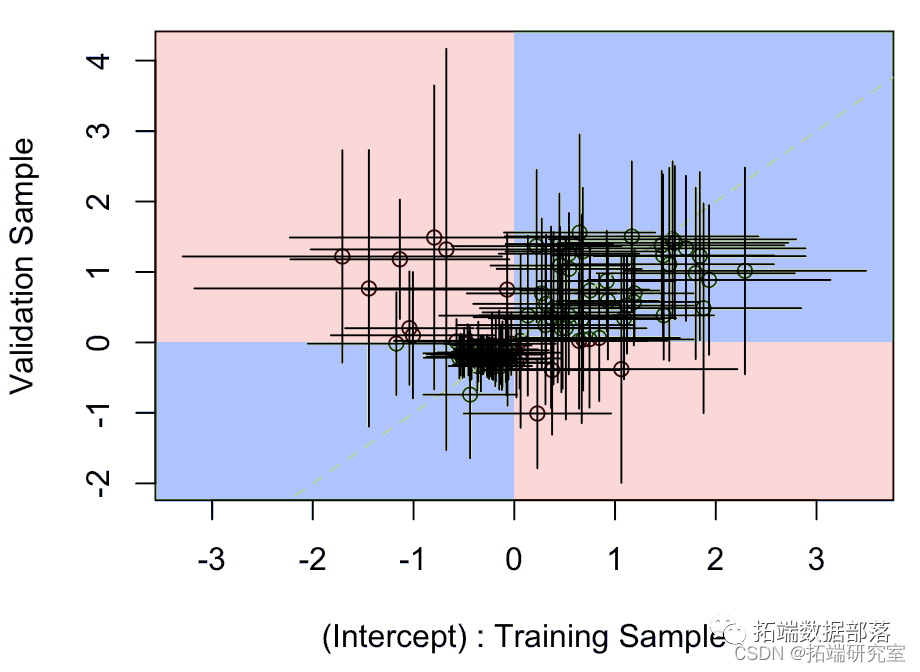
数据分享|R语言逻辑回归Logisitc逐步回归训练与验证样本估计分析心脏病数据参数可视化
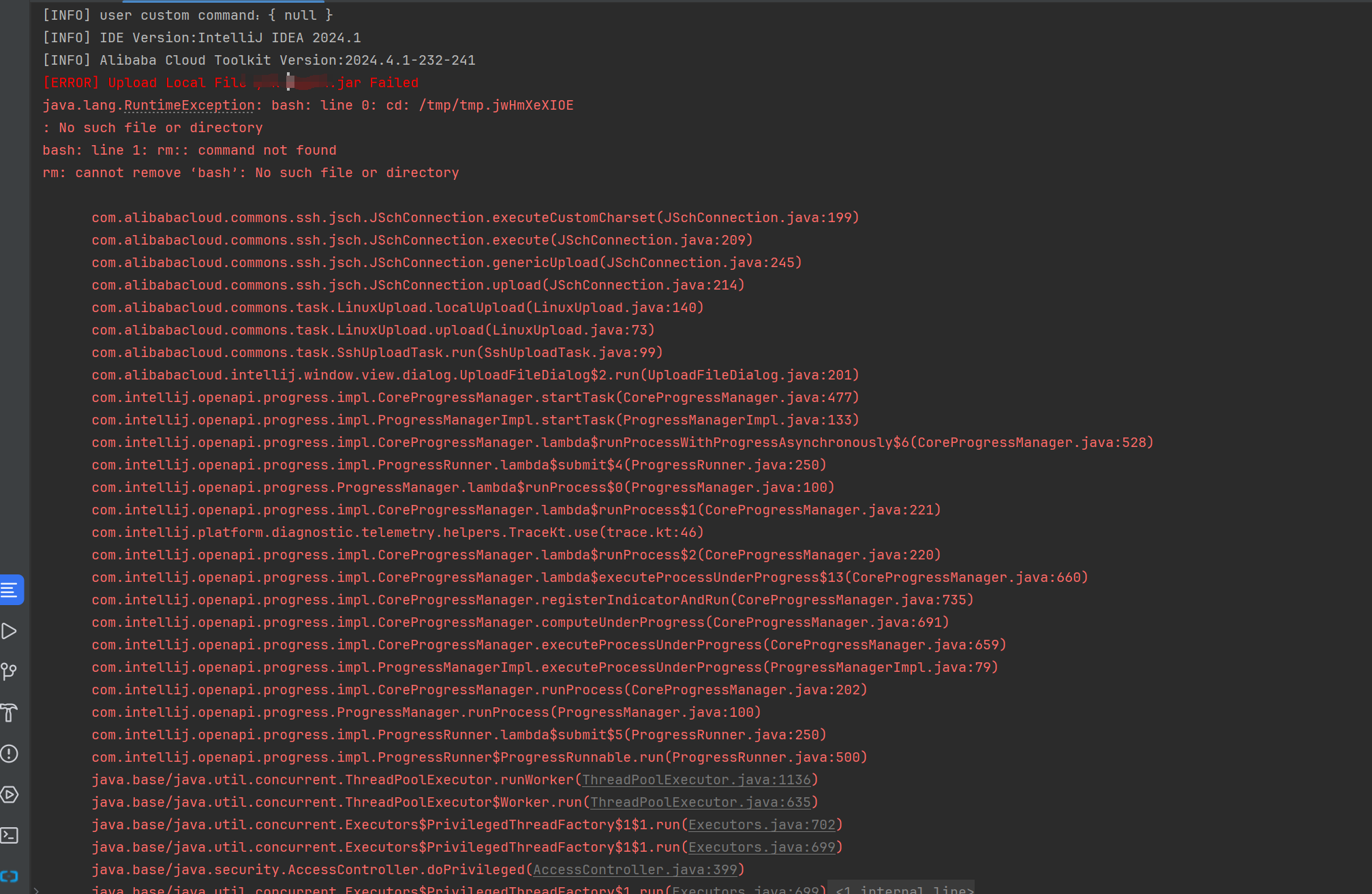
Cloud Toolkit 上传报错
多变量(多元)多项式曲线回归线性模型分析母亲吸烟对新生婴儿体重影响可视化
面试官:请聊一聊String、StringBuilder、StringBuffer三者的区别
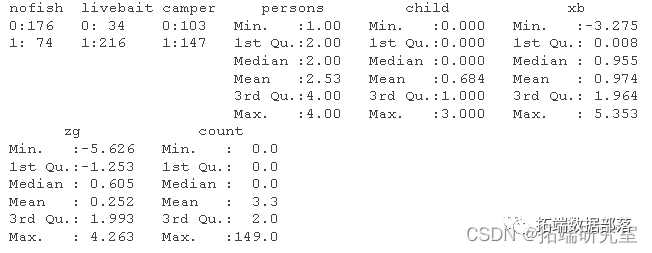
数据分享|R语言零膨胀泊松回归ZERO-INFLATED POISSON(ZIP)模型分析露营钓鱼数据实例估计IRR和OR
Java基础知识整理,驼峰规则、流程控制、自增自减
R语言用GARCH模型波动率建模和预测、回测风险价值 (VaR)分析股市收益率时间序列
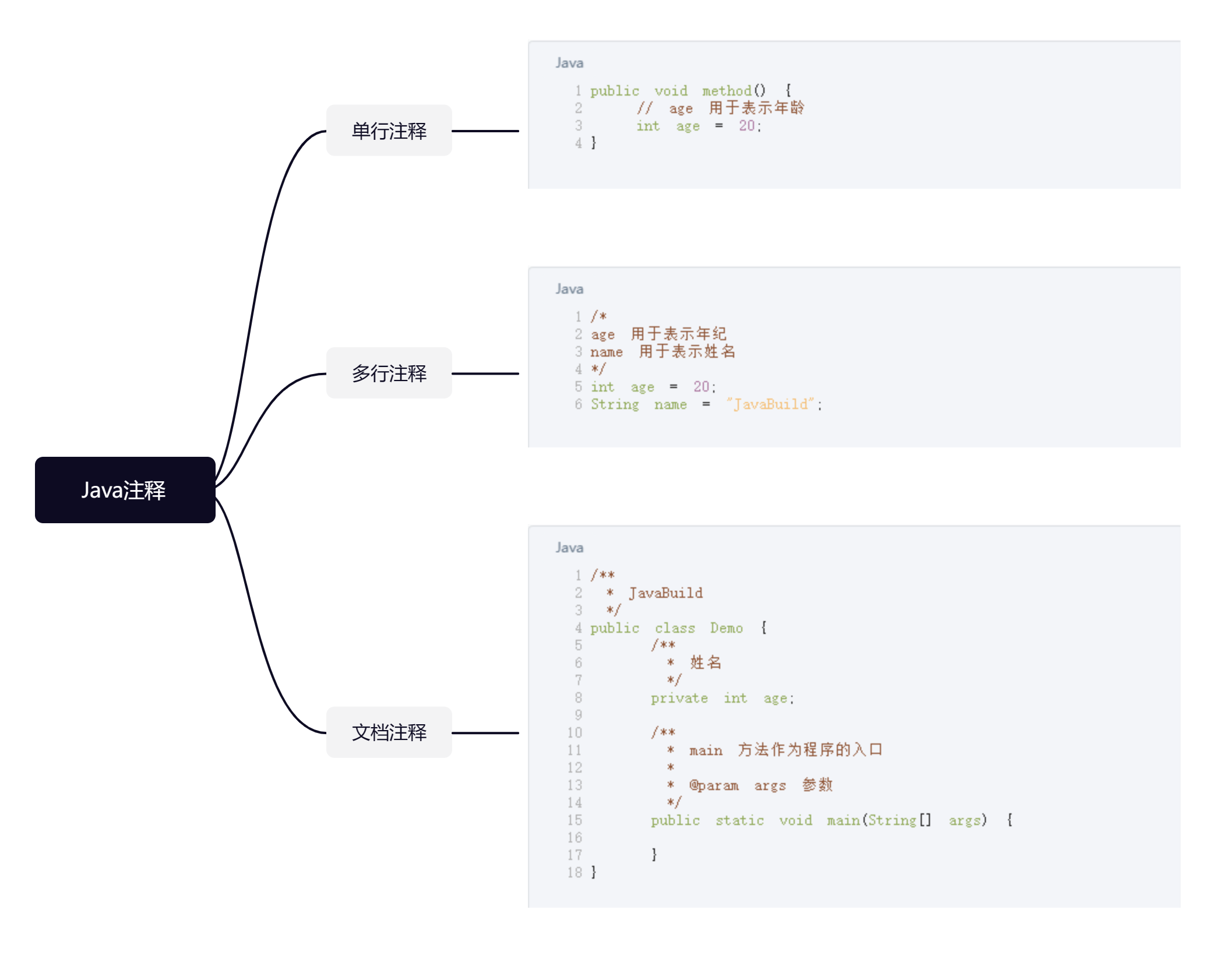
Java基础知识整理,注释、关键字、运算符
数据分享|R语言决策树和随机森林分类电信公司用户流失churn数据和参数调优、ROC曲线可视化
【Flink】Flink的CEP机制
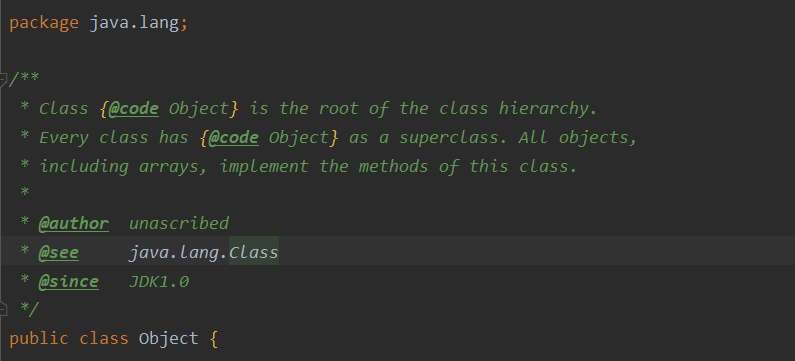
作为所有类的顶层父类,没想到Object的魔力如此之大!
面试官:请谈一谈你对OOP的理解?
【视频】关联规则模型、Apriori算法及R语言挖掘商店交易数据与交互可视化|数据分享