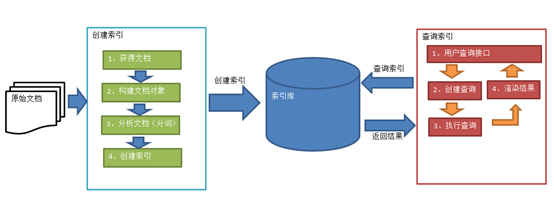
Lucene实现全文检索的流程
① 绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容à采集文档à创建文档à分析文档à索引文档
② 红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面à创建查询à执行搜索,从索引库搜索引擎渲染搜索结果
引入核心依赖
lucene核心及其依赖
<!--lucene-->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>7.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.6.0</version>
</dependency>
中文分词器
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>7.6.0</version>
</dependency>
文件IO操作
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
原始文档
原始文档是指要索引和搜索的内容。原始内容包括互联网上的网页、数据库中的数据、磁盘上的文件等。
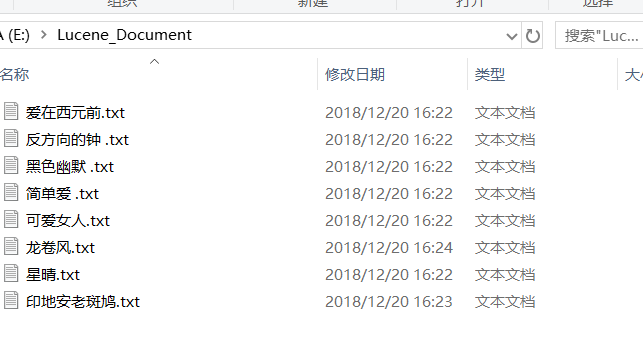
用来测试的原始文档

Field分析
创建索引
对所有文档分析得出的语汇单元进行索引,索引的目的是为了搜索,最终要实现只搜索被索引的语汇单元从而找到Document(文档)。
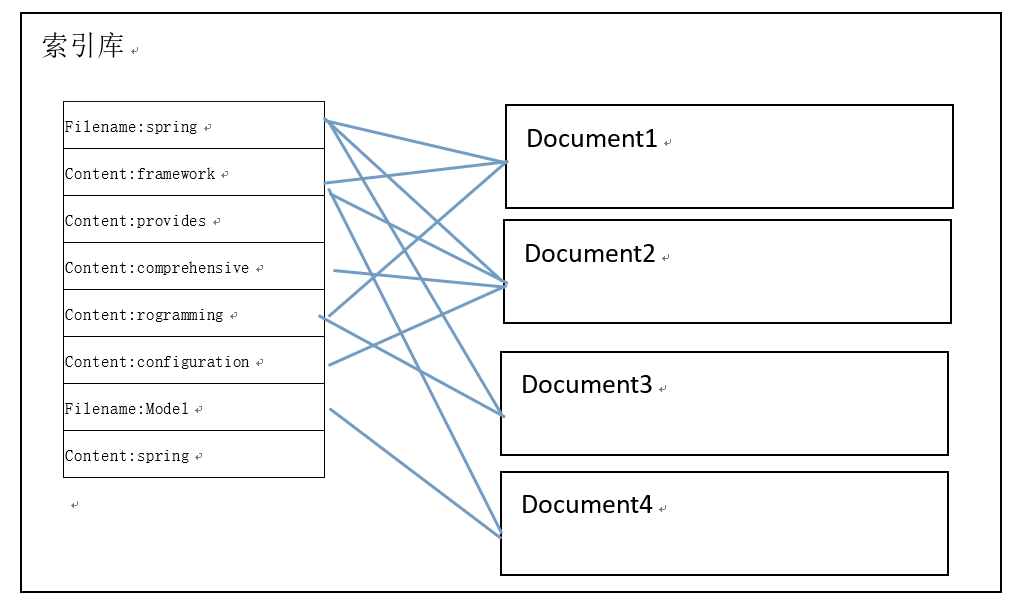
索引库
创建查询
用户输入查询关键字执行搜索之前需要先构建一个查询对象,查询对象中可以指定查询要搜索的Field文档域、查询关键字等,查询对象会生成具体的查询语法,
例如:
语法 “fileName:lucene”表示要搜索Field域的内容为“lucene”的文档
代码示例(创建索引)
//创建索引
@Test
public void luceneCreateIndex() throws Exception{
//指定索引存放的位置
//E:\Lucene_index
Directory directory = FSDirectory.open(Paths.get(new File("E:\\Lucene_index").getPath()));
System.out.println("pathname"+Paths.get(new File("E:\\Lucene_index").getPath()));
//创建一个分词器
// StandardAnalyzer analyzer = new StandardAnalyzer();
// CJKAnalyzer cjkAnalyzer = new CJKAnalyzer();
SmartChineseAnalyzer smartChineseAnalyzer = new SmartChineseAnalyzer();
//创建indexwriterConfig(参数分词器)
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(smartChineseAnalyzer);
//创建indexwrite 对象(文件对象,索引配置对象)
IndexWriter indexWriter = new IndexWriter(directory,indexWriterConfig);
//原始文件
File file = new File("E:\\Lucene_Document");
for (File f: file.listFiles()){
//文件名
String fileName = f.getName();
//文件内容
String fileContent = FileUtils.readFileToString(f,"GBK");
System.out.println(fileContent);
//文件路径
String path = f.getPath();
//文件大小
long fileSize = FileUtils.sizeOf(f);
//创建文件域名
//域的名称 域的内容 是否存储
Field fileNameField = new TextField("fileName", fileName, Field.Store.YES);
Field fileContentField = new TextField("fileContent", fileContent, Field.Store.YES);
Field filePathField = new TextField("filePath", path, Field.Store.YES);
Field fileSizeField = new TextField("fileSize", fileSize+"", Field.Store.YES);
//创建Document 对象
Document indexableFields = new Document();
indexableFields.add(fileNameField);
indexableFields.add(fileContentField);
indexableFields.add(filePathField);
indexableFields.add(fileSizeField);
//创建索引,并写入索引库
indexWriter.addDocument(indexableFields);
}
//关闭indexWriter
indexWriter.close();
}
代码示例(查询索引)
@Test
public void searchIndex() throws IOException {
//指定索引库存放路径
//E:\Lucene_index
Directory directory = FSDirectory.open(Paths.get(new File("E:\\Lucene_index").getPath()));
//创建indexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//创建indexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建查询
Query query = new TermQuery(new Term("fileContent", "可爱"));
//执行查询
//参数一 查询对象 参数二 查询结果返回的最大值
TopDocs topDocs = indexSearcher.search(query, 10);
System.out.println("查询结果的总数"+topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc: topDocs.scoreDocs){
//scoreDoc.doc 属性就是doucumnet对象的id
Document doc = indexSearcher.doc(scoreDoc.doc);
System.out.println(doc.getField("fileName"));
System.out.println(doc.getField("fileContent"));
System.out.println(doc.getField("filePath"));
System.out.println(doc.getField("fileSize"));
}
indexReader.close();
}
Demo示例展示

可爱女人